

Often I find myself focusing on specific strategies to perform specific functions.
How do I write compelling copy to rank on voice search?
What structured data produces easy wins?
Things like that.
These important questions are often covered here on Search Engine Journal in very useful articles.
But it’s important to not just understand what tactics might be working to help you rank. You need to understand how it works.
Understanding the structure that the strategy is functioning in is paramount to understanding not just why that strategy is working, but how and what it’s trying to accomplish.
Previously, we discussed how search engines crawl and index information.
This chapter will explore the basics of how search algorithms work.
What Is an Algorithm? A Recipe
If you ask Google what an algorithm is, you’ll discover that the engine itself (and pretty much everyone else) defines it as “a process or set of rules to be followed in calculations or other problem-solving operations, especially by a computer.”
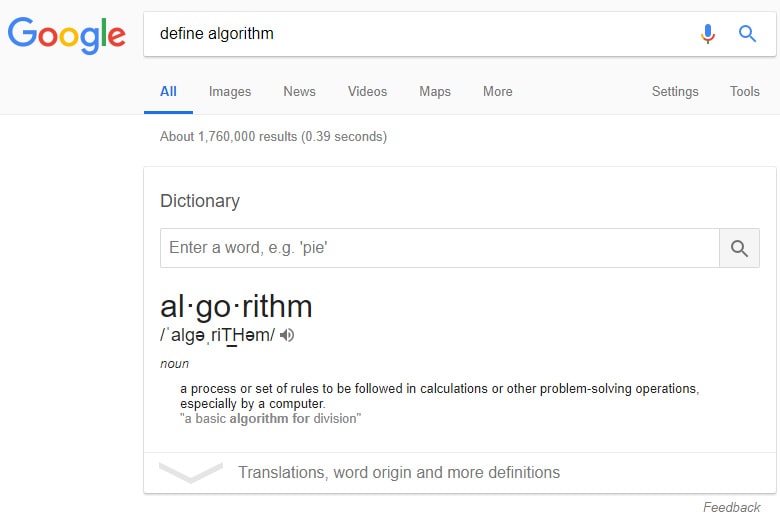
If you take anything from this definition, it’s critical to understand what it is not in our context here.
An algorithm is not a formula.
To wrap our heads around the difference, why it’s important, and what each does, let’s consider for a moment the meal I might place on my dinner plate tonight.
We’ll go with a favorite of mine:
- Roast beef
- Horseradish
- Yorkshire pudding
- Green beans
- Mashed potatoes
- Gravy
(That’s right, we Canadians eat more than poutine and maple syrup, though both are awesome though probably not together.)
The roast beef needs to be seasoned and cooked perfectly.
The seasoning combined with the roast would be an example of a formula – how much of each thing is necessary to produce a product.
A second formula used would be the amount of time and at what temperature the roast should be cooked, given its weight. The same would occur for each item on the list.
At a very basic level, we would have 12 formulas (6 items x 2 – one for measurements and the other for cooking time and duration based on volume) making an algorithm set with the goal of creating one of Dave’s favorite meals.
We aren’t even including the various formulas and algorithms required to produce the ingredients themselves, such as raising a cow or growing potatoes.
Let’s add one more formula though – a formula to consider the amount of different foods I would want on my plate.
So, we now have an algorithm to accomplish this very important task. Fantastic!
Now we just need to personalize that algorithm so that the rest of my family also enjoys their meal.
We need to consider that each person is different and will want different amounts of each ingredient and may want different seasonings.
So, we add a formula for each person. Alright.

An Algorithm of Algorithms
What the heck do a search algorithm and a dinner table have in common?
A lot more than you think.
Let’s look at just a few of the core characteristics of a website for comparison. (“Few” meaning nowhere near everything. Like not even close.)
- URLs
- Content
- Internal links
- External links
- Images
- Speed
As we witnessed with our dinner algorithm, each of these areas is divided further using different formulas and, in fact, different sub-algorithms.
It might be better if we think of it not as an algorithm, but as algorithms.

It’s also important to keep in mind that, while there are many algorithms and countless formulas at play, there is still an algorithm.
Its job is to determine how these others are weighted to produce the final results we see on the SERP.
So, it is perfectly legitimate to recognize that there is some type of algorithm at the top – the one algorithm to rule them all, so to speak – but always recognize that there are countless other algorithms and generally they’re the algorithms we think about when we’re considering how they impact search results.
Now, back to our analogy.
We have a plethora of different characteristics of a website being rated just as we have a number of food elements to end up on our dinner plate.
To produce the desired result, we have to have a large number of formulas and sub-algorithms to create each element on the plate and master algorithm to determine the quantity and placement of each element.
Sound familiar?
When we’re thinking of “Google’s algorithm” what we’re actually referring to is a massive collection of algorithms and formulas, each set to fulfill one specific function and gathered together by a lead or, dare I say, “core” algorithm to place the results.
So, we have:
- Algorithms like Panda to assist Google in judging, filtering, penalizing and rewarding content based on specific characteristics, and that algorithm likely included a myriad of other algorithms within in.
- The Penguin algorithm to judge links and address spam there. But this algorithm certainly requires data from other pre-existing algorithms that are responsible for valuing links and likely some new algorithms tasked with understanding common link spam characteristics so the larger Penguin algorithm could do its job.
- Task-specific algorithms.
- Organizing algorithms.
- Algorithms responsible for collecting all the data and putting it into a context that produces the desired result, a SERP that users will find useful.
So there we have it. That’s how search algorithms work at their core.

Why Search Algorithms Use Entities
One of the areas of search that’s getting some decent attention lately, though which is under-emphasized, is the idea of entities.
For context, an entity is defined by Google as:
“A thing or concept that is singular, unique, well-defined and distinguishable.”
So, in our dinner analogy, there’s me. I’m an entity.
Each member of my family is also their own entity. In fact, my family unit is an entity unto itself.
By that token, the roast and each ingredient that goes into it are also their own entities.
So is the Yorkshire pudding and so is the flour that went into making it.
Google sees the world as a collection of entities. Here’s why:
At my dinner table, I have four individual entities that would have the state “eating” and a host of entities being consumed.
Classifying us all in this way has a lot of benefits to Google over simply assessing our activities as a series of words.
Each eating entity can now have assigned to them the entities that are on their plate (roast beef, horseradish, green beans, mashed potatoes, Yorkshire pudding but no gravy for entity xyz1234567890).
Google uses this type of classification to judge a website.
Think of each entity sitting at the table as a page.
The global entity that represents us all (let’s call this entity “Davies”) would be about “roast beef dinner,” but each individual entity representing an individual (or page in our analogy) is different.
In this way, Google can easily classify and judge the interconnectedness of websites and the world at large.
Basically, search engines aren’t responsible to just judge one website – they must rank them all.
The entity “Davies” is seen to be about “roast beef dinner” but the entity next door (let’s call this entity “Robinsons”) is about “stir fry.”
Now if an outside entity known as “Moocher” wanted to determine where to eat, the options can be ranked to Moocher based on their preferences or query.
Where (in my opinion) the real value in entities lies is in what happens the day after. We have some leftovers.
By processing the entity “roast beef” with a different formula and adding the entities bread, cheese, and onions, we have:

How Search Algorithms Use Entities
OK, it may not seem obvious how important this is in understanding search algorithms and how entities work in this way.
While understanding how Google seeing what a website is about as a whole has obvious value, you may be asking why it’s relevant for Google to understand that my roast beef and beef dip are related and in fact – are drawn from the same core entity.
Let’s consider instead Google understanding that a webpage is about roast beef. Let’s also consider that another page links to it and that page is about beef dip.
In this scenario, it’s incredibly important that Google knows that roast beef and beef dip are drawn from the same core entity.
They can assign relevance to this link based on the connectedness of these entities.
Before the idea of entities entered search, engines were left to assign relevance based on word proximity, density, and other easily misinterpreted and manipulated elements.
Entities are far more difficult to manipulate.
Either a page is about an entity or it’s not.
Through crawling the web and mapping common ways that entities relate, search engines can predict which relationships should carry the greatest weight.
So, How Do Search Algorithms Work?
Alright, we’ve covered a lot of ground and you’re probably getting hungry. You want some takeaways.
Context Matters
It’s important to understand how algorithms function to apply context to what you’re experiencing/reading.
When you hear of an algorithm update, it’s important to know that what is being updated is likely a small piece of a very large puzzle.
Knowing this assists in interpreting which aspects of a site or the world are being adjusted in an update and how that adjustment fits into the large objective of the engine.
Entities Are Super Important
Further, it’s critical moving forward to understand that entities:
- Play a massive role in search algorithms today.
- Have their own algorithms.
- Will play an ever-increasing role over time.
Knowing this will help you understand not just what content is valuable (how close are those entities you’re writing about?) but also which links are likely to be judged more favorably.
And that’s just to name a couple of advantages.
It’s All About User Intent
Search algorithms work as a large collection of other algorithms and formulas, each with its own purpose and task, to produce results a user will be satisfied with.
In fact, there are algorithms in place to monitor just this aspect of the results and make adjustments where ranking pages are deemed not to satisfy user intent based on how users interact with it.
Included in this are algorithms designed specifically to understand entities and how entities relate to each other in order to provide relevancy and context to the other algorithms.
Image Credits
Featured Image: Paulo Bobita
Define Algorithm Screenshot: Taken by author
Clock On Chalkboard: Adobe Stock & Adobe Stock
Google Algorithm Lesson: Adobe Stock
But Wait There’s More: Adobe Stock
Beef Dip: Adobe Stock
