

Google Panda first launched in February 2011 as part of Google’s quest to eliminate black hat SEO tactics and webspam.
At the time, user complaints about the increasing influence of “content farms” had grown rampant.
Along came the Panda algorithm to assign pages a quality classification, used internally and modeled after human quality ratings, which was incorporated as a ranking factor.
Fast forward to 2021, and you can now see how important it was as Google’s first step to focus on quality and user experience.
Here’s everything you need to know about Google Panda – more on why it was launched, what you need to know about the algorithm, and a complete timeline.
Why Google Created Panda
In 2010, the falling quality of Google’s search results and the rise of the “content farm” business model became subjects that were repeatedly making the rounds.
As Google’s Amit Singhal later told Wired at TED, the “Caffeine” update of late 2009, which dramatically sped up Google’s ability to index content rapidly, also introduced “some not so good” content into their index.
Google’s Matt Cutts told Wired this new content issue wasn’t really a spam issue, but one of “What’s the bare minimum that I can do that’s not spam?”
ReadWriteWeb pointed out:
“By the end of [2009], two of these content farms – Demand Media [of eHow infamy] and Answers.com – were firmly established inside the top 20 Web properties in the U.S. as measured by comScore. Demand Media is the epitome of a content farm and by far the largest example of one, pumping out 7,000 pieces of content per day… The company operates based on a simple formula: create a ton of niche, mostly uninspired content targeted to search engines, then make it viral through social software and make lots of money through ads.”
In January 2011, Business Insider published a headline that says it all: Google’s Search Algorithm Has Been Ruined, Time to Move Back to Curation.
In another article, they pointed out:
“Demand [Media] is turning the cleverest trick by running a giant arbitrage of the Google ecosystem. Demand contracts with thousands of freelancers to produce hundreds of thousands of pieces of low-quality content, the topics for which are chosen according to their search value, most of which are driven by Google. Because Google’s algorithm weights prolific and constant content over quality content, Google’s algorithm places Demand content high on their search engine result pages.”
Undoubtedly, headlines like these significantly influenced Google, which responded by developing the Panda algorithm.
Google Panda Update Launches
Panda was first introduced on February 23, 2011.
On February 24, Google published a blog post about the update, and indicated that they “launched a pretty big algorithmic improvement to our ranking – a change that noticeably impacts 11.8% of our queries.”
The expressed purpose of the update was as follows:
“This update is designed to reduce rankings for low-quality sites – sites which are low-value add for users, copy content from other websites or sites that are just not very useful. At the same time, it will provide better rankings for high-quality sites – sites with original content and information such as research, in-depth reports, thoughtful analysis and so on.”
Search Engine Land founder Danny Sullivan originally referred to it as the “Farmer” update. However, Google later revealed that internally it had been referred to as “Panda,” the engineer’s name who came up with the primary algorithm breakthrough.
Analyses by SearchMetrics and SISTRIX (among others) of the “winners and losers” found that sites that were hit the hardest were pretty familiar to anybody who was in the SEO industry at the time.
These sites included wisegeek.com, ezinearticles.com, suite101.com, hubpages.com, buzzle.com, articlebase.com, and so on.
Notably, content farms eHow and wikiHow did better after the update. Later updates would hurt these more “acceptable” content farms as well, with Demand Media losing $6.4 million in the fourth quarter of 2012.
The most readily apparent change in the SEO industry was how heavily it hit “article marketing,” in which SEO practitioners used to publish low-quality articles on sites like ezinearticles.com as a form of link building.
It was also clear that the most heavily hit sites had less attractive designs, more intrusive ads, inflated word counts, low editorial standards, repetitive phrasing, flawed research, and in general didn’t come across as helpful or trustworthy.
What We Know About the Panda Algorithm
When Google discussed the development of the algorithm with Wired, Singhal said that they started by sending test documents to human quality raters who were asked questions like “Would you be comfortable giving this site your credit card? Would you be comfortable giving medicine prescribed by this site to your kids?”
Cutts said the engineer had developed “a rigorous set of questions, everything from. ‘Do you consider this site to be authoritative? Would it be okay if this was in a magazine? Does this site have excessive ads?'”
According to the interview, they then developed the algorithm by comparing various ranking signals against the human quality rankings.
Singhal described it as finding a plane in hyperspace that separates the good sites from the bad.
Singhal later released the following 23 questions as guiding questions the algorithm was based on:
- Would you trust the information presented in this article?
- Is this article written by an expert or enthusiast who knows the topic well, or is it more shallow in nature?
- Does the site have duplicate, overlapping, or redundant articles on the same or similar topics with slightly different keyword variations?
- Would you be comfortable giving your credit card information to this site?
- Does this article have spelling, stylistic, or factual errors?
- Are the topics driven by genuine interests of readers of the site, or does the site generate content by attempting to guess what might rank well in search engines?
- Does the article provide original content or information, original reporting, original research, or original analysis?
- Does the page provide substantial value when compared to other pages in search results?
- How much is quality control done on content?
- Does the article describe both sides of a story?
- Is the site a recognized authority on its topic?
- Is the content mass-produced by or outsourced to a large number of creators, or spread across a large network of sites, so that individual pages or sites don’t get as much attention or care?
- Was the article edited well, or does it appear sloppy or hastily produced?
- For a health-related query, would you trust information from this site?
- Would you recognize this site as an authoritative source when mentioned by name?
- Does this article provide a complete or comprehensive description of the topic?
- Does this article contain insightful analysis or interesting information that is beyond obvious?
- Is this the sort of page you’d want to bookmark, share with a friend, or recommend?
- Does this article have an excessive amount of ads that distract from or interfere with the main content?
- Would you expect to see this article in a printed magazine, encyclopedia, or book?
- Are the articles short, unsubstantial, or otherwise lacking in helpful specifics?
- Are the pages produced with great care and attention to detail vs. less attention to detail?
- Would users complain when they see pages from this site?
It’s also a good idea to consider what Google’s human quality raters were asked to consider. This quote about low-quality content is significant:
Consider this example: Most students have to write papers for high school or college. Many students take shortcuts to save time and effort by doing one or more of the following:
- Buying papers online or getting someone else to write for them.
- Making things up.
- Writing quickly, with no drafts or editing.
- Filling the report with large pictures or other distracting content.
- Copying the entire report from an encyclopedia or paraphrasing content by changing words or sentence structure here and there.
- Using commonly known facts, for example, “Argentina is a country. People live in Argentina. Argentina has borders.”
- Using a lot of words to communicate only basic ideas or facts, for example, “Pandas eat bamboo. Pandas eat a lot of bamboo. Bamboo is the best food for a Panda bear.”
In March of 2011, SEO By The Sea identified Biswanath Panda as the likely engineer behind the algorithm’s namesake.
In one paper, Biswanath helped the author detail how machine learning algorithms could be used to make accurate classifications about user behavior on landing pages.
While the paper is not about the Panda algorithm, the author, with its namesake’s involvement, and the subject matter, suggests that Panda is also a machine-learning algorithm.
Most in the SEO industry had concluded that Panda works by using machine learning to make accurate predictions about how humans would rate the quality of content. What is less clear is what signals would have been incorporated into the machine learning algorithm to determine which sites were low in quality and which weren’t.
Panda and Google E-A-T:
In 2014 Google introduced E-A-T principles in its search quality guidelines focused on Expertise, Authority, and Trustworthiness.
Since 2018 these principles have become more and more of a focus for marketers.
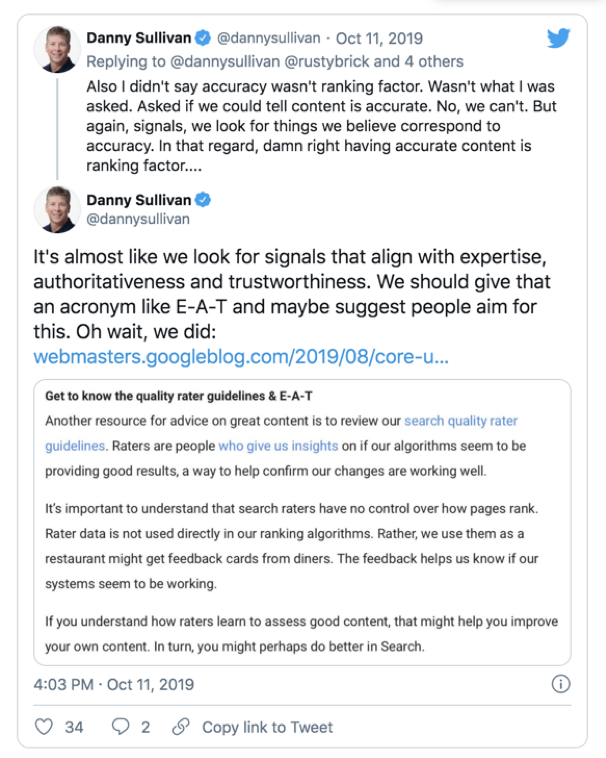
Like Panda, consequent updates and core algorithmic changes focus on the quality of content and the user experience.
And like Panda, the focus is on avoiding:
- Thin and non-informational content.
- Lack of authoritative sources.
- Untrustworthy content and questionable links.
Google Panda Recovery
The path to recovery from Panda can be both straightforward and challenging.
Since Panda boosts the performance of sites with content that it categorizes as having high-quality, the solution is to increase the quality and uniqueness of your content.
While that’s easier said than done, it’s been proven repeatedly that this is exactly what is needed to recover.
Alan Bleiweiss helped a site recover by assisting them in rewriting content across 100 pages.
WiredSEO helped a site recover from Panda by changing their user-generated content guidelines to encourage more specific, unique bios rather than ones copied from other sites. Users of the site had previously used bios from their other sites. Still, WiredSEO encouraged them to change the bio to ask specific questions, resulting in unique bios that weren’t duplicates.
Google Panda Myths
Panda Isn’t About Duplicate Content
The most pervasive myth about Panda is that it is about duplicate content. John Mueller has clarified that duplicate content is independent of Panda. Google employees have stressed that Panda encourages unique content, but this goes deeper than avoiding duplication. What Panda is looking for is genuinely unique information that provides outstanding value to users.
Mueller likewise told one blogger that removing technical duplicates was actually a very low priority and that they should instead “think about what makes your website different compared to the absolute top site of your niche.”
In 2021, Google’s John Mueller explained that duplicate content is not a negative ranking factor.
Should You Delete Content to Resolve Panda Issues?
In 2017, Google’s Gary Illyes said on Twitter: “We don’t recommend removing content in general for Panda, rather add more HighQ stuff.”
John Mueller said likewise on YouTube:
“Overall, the quality of the site should be significantly improved so we can trust the content. Sometimes what we see with a site like that will have a lot of thin content, maybe there’s content you are aggregating from other sources, maybe there’s user-generated content where people are submitting articles that are kind of low quality, and those are all the things you might want to look at and say what can I do; on the one hand, hand if I want to keep these articles, maybe prevent these from appearing in search. Maybe use a noindex tag for these things.”
Google’s response has always been to either noindex or improve content — never to cut it entirely unless doing so is a move for branding.
In general, deleting content should be a consideration in terms of the overall branding of your site, rather than a move that will remove a Panda penalty.
Panda & User-Generated Content
Panda doesn’t target user-generated content specifically. Although Panda can target user-generated content, it tends to impact sites that produce low-quality content – such as spammy guest posts or forums filled with spam.

Do not remove your user-generated content, whether it is forums, blog comments, or article contributions, simply because you heard it is “bad” or marketed as a “Panda proof” solution. Look at it from a quality perspective instead.
Many high-ranking sites rely on user-generated content – so many sites would lose significant traffic and rankings simply because they removed that type of content. Even comments made on a blog post can cause it to rank and even get a featured snippet.
Word Count Isn’t a Factor
Word count is another aspect of Panda that SEO professionals often misunderstand. Many sites make the mistake of refusing to publish any content unless it is above a certain word count, with 250 words and 350 words often cited. Instead, Google recommends you think about how many words the content needs to be successful for the user.
For example, there are many pages out there with very little main content, yet Google thinks the page is quality enough that it has earned the featured snippet for the query. In one case, the main content was a mere 63 words, and many would have been hard-pressed to write about the topic in a non-spammy way that was 350+ words in length. So you only need enough words to answer the query.
Affiliate Links & Ads Aren’t Directly Targeted
Affiliate sites and “made for AdSense” sites are often hit by Panda more often than other sites, but this isn’t because it specifically targets them. A Google spokesperson told TheSEMPost that
“An extreme example is when a site’s primary function is to funnel users to other sites via ads or affiliate links, the content is widely available on the internet, or it’s hastily produced, and is explicitly constructed to attract visitors from search engines.”
Mueller said, similarly:
“But at the same time, we see a lot of affiliates who are basically just lazy people who copy and paste the feeds that they get and publish them on their websites. And this kind of lower quality content, thin content, is something that’s really hard for us to show in search.”
In other words, these sites are being hit for the same reasons: they fail to provide compelling, unique, engaging content.
Timeline
Panda almost certainly has the most extensive public record of public dates for its associated updates. Part of the reason for this is that Panda was run externally from Google’s core algorithm, and content scores were, as a result, only affected on or near the date of new Panda updates.
This continued until June 11, 2013, when Cutts said at SMX Advanced that, while Panda was not incorporated directly into Google’s core algorithm, its data was updated monthly and rolled out slowly over the course of the month, ending the abrupt industry-wide impacts associated with Panda updates.
Hence Panda mentions disappearing after 2017.
The numbering convention is somewhat confusing.
One would expect core updates to Panda’s algorithm to correspond to 1.0, 2.0, 3.0, and 4.0, but no update is referred to as 3.0, and 3.1 was not, in retrospect, a core update to Panda.
Data refreshes, which updated the search results but not the Panda algorithm itself, were typically numbered as you would expect for software updates (3.2, 3.4, 3.5, and so on). However, there were so many data refreshes for version 3 of the algorithm that, for a time, this naming convention was abandoned, and the industry referred to them simply by the total count of Panda updates (both refreshes and core updates).
Even after getting a handle on this naming convention, it still isn’t entirely clear whether all of the minor Panda updates were just data refreshes or if some of them incorporated new signals as well.

Regardless, the timeline of Panda updates is, at least, well known and is as follows:
- 1.0: February 23, 2011. The first iteration of a then-unnamed algorithm update was introduced (12 percent of queries were impacted), shocking the search engine optimization industry and many big players and effectively ending the “content farm” business model as it existed at the time.
- 2.0 (#2): April 11, 2011. The first update to the core Panda algorithm. This update incorporated additional signals, such as sites that Google users had blocked.
- 2.1 (#3): May 9, 2011. The industry-first called this Panda 3.0, but Google clarified that it was just a data refresh, as would be true of the 2.x updates to come.
- 2.2 (#4): June 21, 2011
- 2.3 (#5): July 23, 2011
- 2.4 (#6) International: August 12, 2011. Panda was rolled out internationally for all English-speaking countries and non-English speaking countries except for Japan, China, and Korea.
- 2.5 (#7) and Panda-Related Flux: September 28, 2011. Following this update, on October 5, 2011, Cutts announced to “expect some Panda-related flux in the next few weeks.” Confirmed flux dates were October 3 and October 13.
- 3.0 (#8): October 19, 2011. Google added some new signals into the Panda algorithm and also recalculated how the algorithm impacted websites.
- 3.1 (#9): November 18, 2011. Google announced a minor refresh, impacting less than 1 percent of searches.
- 3.2 (#10): January 18, 2012. Google confirmed a data refresh occurred on this date.
- 3.3 (#11): February 23, 2012. A data refresh.
- 3.4 (#12): March 23, 2012
- 3.5 (#13): April 19, 2012
- 3.6 (#14): April 27, 2012
- 3.7 (#15): June 8, 2012. A data refresh that ranking tools suggest was more heavy-hitting than other recent updates.
- 3.8 (#16): June 25, 2012
- 3.9 (#17): July 24, 2012
- 3.9.1 (#18): August 20, 2012. A relatively minor update that marked the beginning of a new naming convention assigned by the industry.
- 3.9.2 (#19): September 18, 2012
- #20: September 27, 2012. A relatively large Panda update also marked the beginning of yet another naming convention. The industry recognized the awkwardness of the 9.x.x naming convention and recognized that updates to what they called Panda 3.0 could continue to occur for a very long time.
- #21: November 5, 2012
- #22: November 21: 2012
- #23: December 21, 2012. A slightly more impactful data refresh.
- #24: January 22, 2013
- #25: March 14, 2013. This update was pre-announced, and tools suggest it occurred on roughly this day. Cutts seemed to suggest that this would be the final update before Panda would be incorporated directly into the Google algorithm. However, it later became clear that this wasn’t quite what was happening.
- “Dance”: June 11, 2013. This is not the date of an update. Still, the day Cutts clarified Panda wasn’t going to be incorporated directly into the algorithm, but rather that it would update monthly with much slower rollouts, rather than the abrupt data refreshes of the past.
- “Recovery”: July 18, 2013. This update appears to have been a tweak to correct some overly harsh Panda activity.
- 4.0 (#26): May 19, 2014. A major Panda update (impacting 7.5 percent of queries) occurred on this date. Most in the industry believe that this was an update to the Panda algorithm, not just a data refresh, especially in light of Cutts’ statements about slow rollouts.
- 4.1 (#27): September 23, 2014. Another major update (impacting 3 to 5 percent of queries) included some changes to the Panda algorithm. Due to the slow rollouts, the exact date is unclear, but the announcement was made on September 25.
- 4.2 (#28): July 17, 2015. Google announced a Panda refresh that would take months to roll out. Due to the slow nature of the rollout, it’s unclear how substantial the impact was or precisely when it occurred. It was the final confirmed Panda update.
- Core Algorithm Incorporation: January 11, 2016. Google confirmed that Panda had been incorporated into the core Google algorithm, evidently as part of the slow July 17, 2015 rollout. In other words, Panda is no longer a filter applied to the Google algorithm after it does its work but is incorporated as another of its core ranking signals. It has been clarified, however, that this doesn’t mean the Panda classifier acts in real-time.
Panda Today: 2021

Panda is now firmly embedded in Google’s machine learning algorithms, and as a result, Panda-related updates won’t be seen as standalone.
With Panda becoming a part of Google’s core algorithm, we no longer see separate Panda updates. Core algorithm updates – especially those that have a focus on quality and content – are ‘Panda’ related in theory.
Moving Forward
In 2021, you should keep the core concepts of Panda top of mind.
Avoid black hat tactics and spam links and focus on quality content for the user and their experience. Google’s use of machine learning and technology continues to adhere to these principles.
The name Panda may not appear, but the Panda principles are still relevant today.
