

For a while, it seemed we’d be saying “next year will be the year of voice” annually, as was the case with mobile. Until last year, according to Google’s Annual Global Barometer Study, 2017 became “The Year of the Mobile Majority.”
There’s certainly no shortage of predictions on future voice usage.
In 2016, 20 percent of queries on mobile were voice, as announced at Google I/O 2016.
By 2020, 50 percent of search is expected to be driven by voice according to ComScore.
If Google Trends’ Interest over time on search terms “Google Home” and “Alexa” are any indication, eyes-free-devices just crashed into our lives with a festive bang.
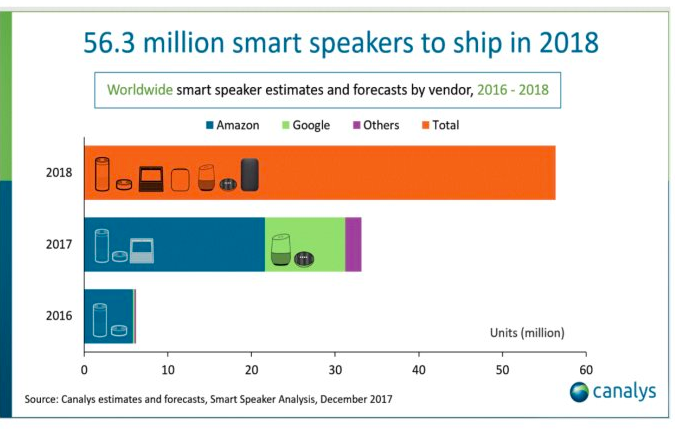
Over 50 million smart speakers are now expected to ship in 2018, according to a Canalys report published on New Year’s Day.

No doubt aggressive holiday period sales strategies from both Amazon and Alphabet (Google’s parent company) to move smart speakers en masse, contributed strongly.
After Amazon reduced prices on Amazon Echo and Echo Dot, Google followed suit, slashing prices on Black Friday on Home and Home Mini smart speakers.
While analysts predict both companies broke even or made a loss, Google Trends interest demonstrated a hockey-stick curve.
‘Seasons Tweetings’
If the objective was to ignite mass device-engagement during seasonal family gatherings, this appears to have worked.
Social media screamed: “Step aside Cluedo, charades, and Monopoly… there’s a new parlor game in town, and it’s called Google Home and Alexa.”
A YouTube video of an 85-year-old Italian grandmother ‘scared’ of “Goo Goo”, as she called it, broke the internet, with over 2 million views so far.
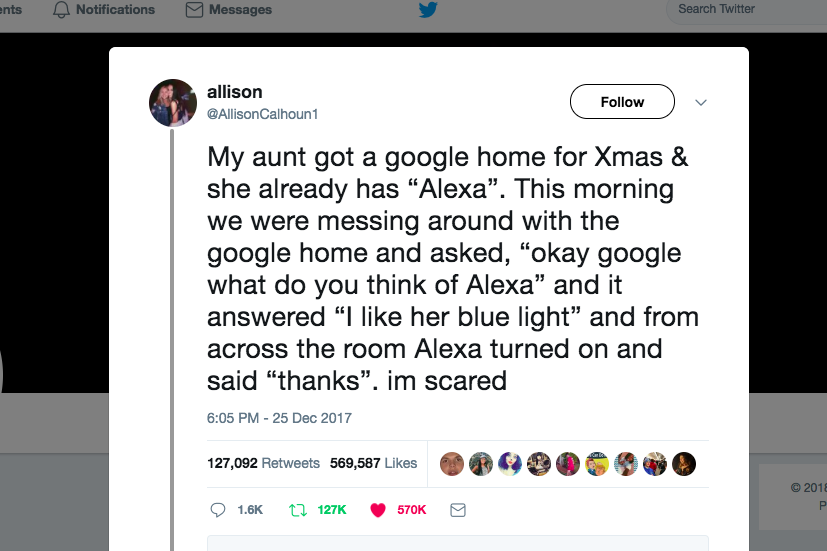
People on Twitter “freaked out” at the “magic” of smart speakers, with one anecdotal tweet going viral at Home and Alexa seemingly communicating spontaneously with each other from across opposite sides of a room.
Bustle claimed an Amazon rep explained the technical reasons behind “the magic” following the tweet sensation. There is no magic. Merely explainable programming, and the automatic triggering of action words (or ‘hot words’) and sequential responses by both devices.
Challenges of Conversational Search & Humans
Machines are predictable; humans less so.
In conversational search, users ask questions in obscure and unpredictable ways. They ask them without context, in many different ways, and ask impossibly unanswerable ones too.
Amit Singhal gave a humorous example in an interview with Guy Kawasaki back in 2013, explaining how users ask questions like “Does my hair make me look bad?”
Unanswerable, unfortunately.
Google has produced a Help Center with instructions on how to trigger different types of assistant responses, but who actually reads instructions when we get a new device?
With Assistant and Home, humans may not say the “action” words needed to trigger smart speakers, such as “play” and “reminder,” and may instead receive recited lists of tracks in response.
Likewise, the understanding and extraction of the right data to meet the query may be carried out unsuccessfully by the search engine.
Voice Recognition Technology Improvements
Google is definitely getting better at voice recognition, with error rates almost on par with those of humans as Google’s Sundar Pichai claims.
My Search Engine Journal colleague Aleh Barysevich discussed this recently. We also know Mary Meeker’s annual Internet Trends report confirmed voice recognition is improving rapidly.
Voice ‘Recognition’ Is Not ‘Understanding’
However, simply because search engines have found a way to recognize voices and words, actually understanding meanings and context to return gold standard spoken answers appropriately still holds challenges.
And Which Answers Are Being Provided?
It’s clear we need to be able to gain sight of some voice query data soon.
Cross-platform, multi-device attribution and assisted conversions need to be measured commercially if we’re triggering answers and providing useful information, and we need to be able to get sight of how far we are from being considered a good result, so we can improve.
There is very little to no visibility currently available, other than we know it’s going on.
Below, Glenn Gabe illustrated some queries appearing in Google Search Console (maybe just for beta testers), but not yet separated from written desktop web and mobile).
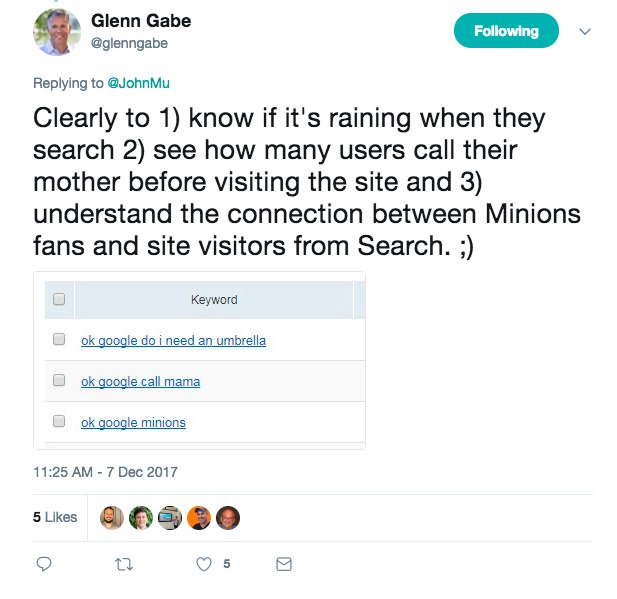
However, as Barysevich mentioned, Google’s John Mueller reached out in early December to the SEO community via Twitter on potential data use cases in Google Search Console. Hopefully, this is a sign something useful is forthcoming for SEOs.

Lots of Questions
One thing is for sure. Search engine users ask a LOT of questions.
According to Google’s recently released annual Global ‘Year in Search’, in 2017 we asked “how?” more than anything else:
No surprise then that a huge amount of industry and academic research in mining and analyzing community question and answer text is underway, with a selection of papers from one of the main Information Retrieval conferences Web Search and Data Mining Conference (WSDM) a small illustration:
Google’s Voice Search & Assistant Raters Guidelines
Something which is useful in helping us understand what is considered a good spoken result is the Voice Search and Assistant Quality Raters Guidelines, published in December 2017. The guide is for human raters to mark the quality of voice query and Assistant action word results as an important part of the search quality feedback loop.
Here’s an example of what failure looks like for voice search as per the Google Raters Guidelines:
Proposition: [will it rain this evening?]
Response: “I’m not sure how to help with that.”
Suggested Rating: Fails to Meet
Rater Guidelines Further Commentary: The device failed to answer the query. No users would be satisfied with this response.
I haven’t been able to find any figures on this but it would be interesting to know how often Google Home or Assistant on mobile says “I’m sorry I can’t help you with that” or “I don’t understand” as a percentage of total voice queries (particularly on smart speakers outside of action words and responses).
I did reach out to Google’s John Mueller on Twitter to ask if there were any figures available, but he didn’t answer.

Unsurprisingly so.
I don’t imagine any search engine would want users to know they cannot respond with an answer to meet informational need (i.e., when the response was “I’m sorry, I can’t help with that” or “I don’t understand”), regardless of spoken or written word. It could almost be akin to search engine embarrassment in URL based search when a user clicks and gets an incorrect result.
As an aside, Rob May on Twitter also commented the figures would be unlikely to be available for the same reasons mentioned above.
In the raters guide, examples are provided of what “good” looks like, too, with suggested ratings on attributes of length, formulation and elocution, in addition to whether informational satisfaction was achieved, and some further explanatory commentary.
This is what the raters guide says on each of these attributes:
- Information Satisfaction: The content of the answer should meet the information needs of the user.
- Length: When a displayed answer is too long, users can quickly scan it visually and locate the relevant information. For voice answers, that is not possible. It is much more important to ensure that we provide a helpful amount of information, hopefully not too much or too little. Some of our previous work is currently in use for identifying the most relevant fragments of answers.
- Formulation: It is much easier to understand a badly formulated written answer than an ungrammatical spoken answer, so more care has to be placed in ensuring grammatical correctness.
- Elocution: Spoken answers must have proper pronunciation and prosody. Improvements in text-to-speech generation, such as WaveNet and Tacotron 2, are quickly reducing the gap with human performance.
From the examples provided in the guide, SEO pros can also get an idea of the type of response considered a high-quality one.
Spoiler: It’s one which meets informational needs, in short answers, grammatically correct (syntactically well-formed), and with accurate pronunciation.
Seems straightforward, but there is more insight we can gain to help us cater for voice search.
Note ‘Some of Our Previous Work’
You’ll notice “Some of our previous work” is briefly referred to on the subject of “length” and how Google is handling that for voice search and assistant.
The work is “Sentence Compression by Deletion with LSTMs”.
It is an important piece of work, which Wired explains as “they’ve learned to take a long sentence or paragraph from a relevant page on the web and extract the upshot — the information you’re looking for.” Only the most relevant bits are used from the content or the Knowledge Graph in voice search results.

One of the key researchers behind it is Enrique Alfonseca, part of the Google Research Team in Zurich. Alfonseca is well-placed as an authority on the subject matter of conversational search and natural language processing, with several published papers.
European Summer School on Information Retrieval 2017
Last summer, I attended a lecture by Alfonseca. He was one of a mix of industry and academic researchers from the likes of Facebook, Yahoo, and Bloomberg during the biennial European International Summer School in Information Retrieval (ESSIR).
Alfonseca’s lecture gave insight into some of the current challenges faced by Google in providing gold standard (the best in information retrieval terms), high-quality results for conversational search users.

There is some cross-over between the raters guidelines and what we know already about voice search. However, the main focus and key points in Enrique’s lecture overall may give further insight to reinforce and supplement.
Alfonseca in his closing words made the point that better ranking for the conversational search was needed because the user tends to focus on a single response.
This was also discussed in a Voicebot podcast interview with Brad Abrams, a Google Assistant Product Manager, who said at best only 2-3 answers will be returned. So, there can be only one, or two, or three.
One thing is for sure. We need all the information we can get to compete.
Some Key Takeaways from the Lecture
- Better ranking needed because the user tends to focus on a single answer.
- A rambled answer at the end is the worst possible scenario.
- There is not yet a good way to read an answer from a table.
- Knowledge Graph entities (schema) first, web text next.
- Better query understanding is needed, in context.
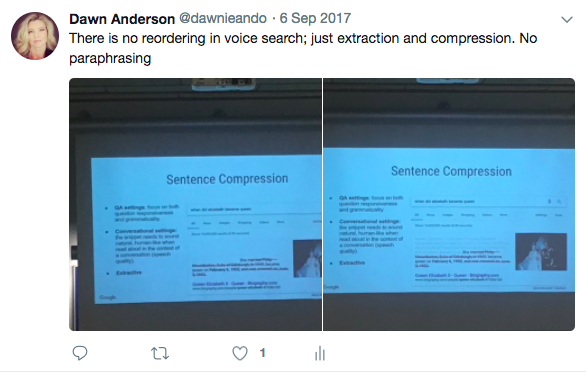
- There is no re-ordering in voice search – no paraphrasing – just extraction and compression.
- Multi-turn conversations are still challenging.
- Linguists are manually building lexicons versus automation.
Clearly there are some differences in voice search when compared with keyboard based or desktop written search.
Further Exploration of the Key Lecture Points
We can look at each of the lecture points in a little more detail and draw some thoughts:
Rambled Answer at the End Is the Worst Possible Scenario
This looks at the length attribute and some formulation and presentation and pretty much ties in with the raters guidelines. It emphasizes need to answer the question early in a document, paragraph, or sentence.
The raters guide has a focus on short answers being key, too.
Alfonseca explained: “In voice search, a rambled answer at the end is the worst possible scenario. Reads ok but but it sounds awful on voice.”
Presumably, this is aside from not returning an answer at all, which is a complete failure.
This indicates the need for a second separate strategy for voice search, in addition to desktop and keyboard search.
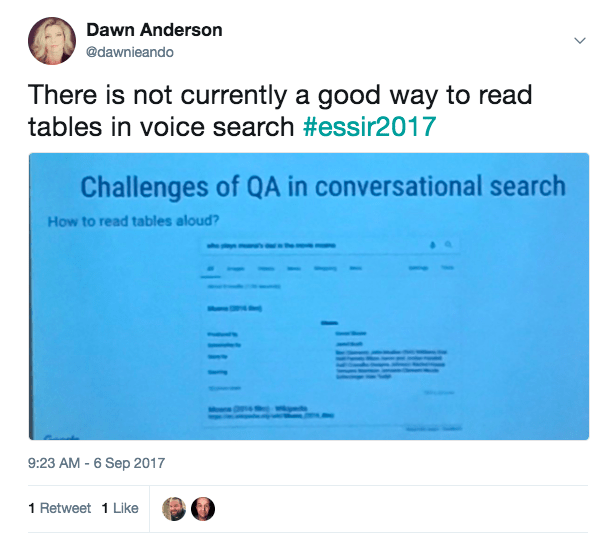
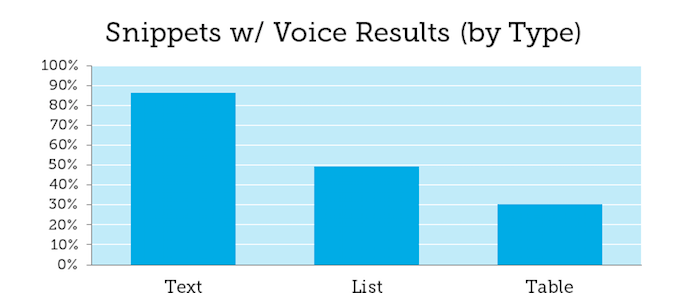
 There Is Not a Good Way to Read Tables in Voice Search
There Is Not a Good Way to Read Tables in Voice Search
“There is not currently a good way to read tables in voice search,” Alfonseca shared.
This is important because we know that in featured snippets tables provide strong structure and presentation via tabular data and may perform well, whereas, because of the difficulty in translating these to well-formulated sentences, they may perform far less well in voice search.
Pete Meyers from Moz did a voice search study of 1,000 questions recently and found only 30 percent of the answers were returned from tables in featured snippets. Meyers theorized the reason may be tabular data is not easy to read from, and Alfonseca confirms this here.
 Knowledge Graph Entities First, Web Text Second and Better Query Understanding Is Needed, in Context
Knowledge Graph Entities First, Web Text Second and Better Query Understanding Is Needed, in Context
I’m going to look at these two points together because one strikes me as being very related and important to the other.
Knowledge Graph Entities First, Web Text Second
Google’s Inside Search voice search webpage tells us:
“Voice search on desktop and the Google app use the power of the Knowledge Graph to deliver exactly the information you need, exactly when you need it.”
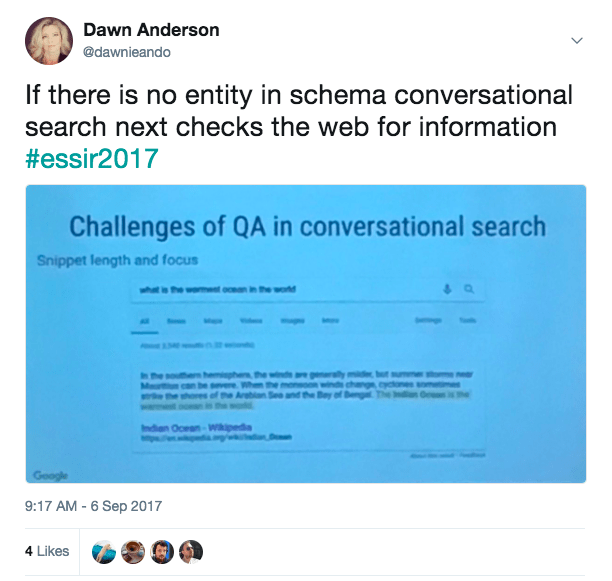
More recently, Google shared in their December Webmaster blog post Evaluation of Speech for Google the contents of the voice response are sometimes sourced from the web. One presumes this means beyond the “power of the Knowledge Graph” spoken of in the voice search section of Inside Search.
Coupled with Alfonseca’s lecture it would not be amiss to consider that quite a lot of remaining answers come from normal webpages aside from the Knowledge Graph.
Alfonseca shared with us the Knowledge Graph (schema) is checked first for entities when providing answers in conversational search, but when there is no entity in the Knowledge Graph, conversation search seeks answers from the web.
Presumably much of this ties in with answers appearing in featured snippets, however, Meyers flagged up there are some answers whose source did not share featured snippets. He found only 71 percent of featured snippets mapped to answers in his study of 1,000 questions with Google Home.
We know there are several types of data which could be extracted for conversational search from the web:
- Structured data (tables and data stored in databases)
- Semi-structured data (XML, JSON, meta headings [h1-h6])
- Semantically-enriched data (marked up schema, entities)
- Unstuctured data (normal web text copy)
If voice search answers are extracted from unstructured data in normal webpages in addition to the better formed featured snippets and entities, this could be where things get messy and lacking in context.
There are a number of problems with unstructured data in webpages. Such as:
- Unstructured data is loose and fuzzy. It is difficult to understand what it is about for a machine, although humans may well be able to understand it well.
- It’s almost devoid of hierarchical or topical structure or form. Made worse if no well-structured website section and topically related pages to inherit relatedness.
- Volume is an issue. There’s a huge amount of it.
- It’s noisy and sparse of categorization into topics and content type.
Here’s Where Relatedness & Disambiguation Matter a Lot
Disambiguation is still an issue and more contextual understanding is vital. In his closing words, Alfonseca highlighted one of the challenges is “better query understanding is needed, in context.”
While we know the context of the user (contextual search such as location, surrounding objects, past search history, etc.) is a part of this, there is also the important issue of disambiguation in both query interpretation and in word disambiguation in text when identifying the most relevant answers and sources to return.
It isn’t just user context which matters in search, but the ontological context of text, site sections and co-occurrence of words together which adds semantic value for search engines to understand and disambiguate meaning.
This also applies to all aspects of search (aside from voice), but this may be even more important (and difficult) for voice search than written keyboard based search.
Words which could have multiple meanings and people say things that mean the same in many ways, but also too, maybe because only extracted snippets (fragments) of information are taken from a page, with irrelevant function words deleted, rather than the page as a whole analyzed.
There is an argument that the surrounding contextual words and relatedness to a topic for voice search will be more important than ever to add weight relevance prior to extraction and deletion.
It’s important to note here that Alfonseca is also a researcher behind a number of published papers on similarity and relatedness in natural language processing.
An important work he co-authored is “A Study on Similarity and Relatedness Using Distributional and Wordnet-Based Approaches” (Agirre, E., Alfonseca, E., Hall, K., Kravalova, J., Paşca, M. and Soroa, A., 2009).
 What Is Relatedness?
What Is Relatedness?
Words without semantic context mean nothing.
“Relatedness” gives search engines further hints on context to content to increase relevance to a topic, reinforced further via co-occurrence vectors and common linked words which appear in documents or document collections together.
It’s important to note relatedness in this sense is not referring to relations in entities (predicates) but as a way of disambiguating meaning in a large body of text-based information (a collection of webpages, site section, subdomain, domain, or even group of sites).
Relatedness is much more loose in nature than the clearly linked and connected entity relations and can be fuzzy (weak) or strong.
Relatedness is derived from Firthian linguistics, so named after John Firth who championed the notion of semantic context-awareness in linguistics and followed the aged context-principle of Frege…”never … ask for the meaning of a word in isolation, but only in the context of a proposition” (Frege [1884/1980] )
Firth is widely associated with disambiguation in linguistics, relatedness, and the phrase:
“You shall know a word by the company it keeps.”
If we could equate this with you can understand the meaning of the word when there is more than one meaning by what other words live near it or have words which it shares with others in the same text collections, its co-occurrence vectors.
For example, an ambiguous word might be jaguar.
Understanding whether a body of text is referring to a jaguar (cat) or a jaguar (car), is via co-occurrence vectors (words that are likely to share the same company).
To refer back to Firth’s notion; “What company does that word keep?”
For instance, a jaguar (cat) would be highly likely to appear in pages which are about cat food, dogs, kittens, puppies, fur, tigers, zoos, safari, cats and felines, legs or animals versus a jaguar (car) and would likely appear with text which is about roads, automobiles, vehicles, speed, wheels, garages and so forth.
For example, here we can see that “car” has five different meanings:

As humans, we would likely know which car was being referred to immediately.
The challenge is for machines to also understand the context of text to understand whether ‘car’ means a cable car, rail car, railway car, gondola, and so forth when understanding queries or returning results from loose and messy unstructured data such as a large body of text, with very few topical hints to guide.
This understanding is still challenging for voice search (and often in normal search too), but appears particularly problematic for voice. It is early days after all.
Paraphrasing: There Is None with Voice Search
With written words in featured snippets and knowledge panels, paraphrasing occurs.
Alfonseca gave the example below, which showed paraphrasing used in a written format in featured snippets.
But with voice search, Alfonseca told us, “There is no reordering in voice search; just extraction and compression. No paraphrasing.”

This is important because in order to paraphrase one must know the full meaning of the question and the answer to return it in different words (often fewer), but with the same meaning.
You cannot do this accurately unless a contextual understanding is there. This further emphasizes the lack of contextual understanding behind voice search.
This may also contribute to why there are still questions or propositions that are not yet answered in voice search.
It isn’t because the answer isn’t there, it’s because it was asked in the wrong way, or was not understood.
This is catered for in written desktop or mobile search because there are a number of query modifying techniques in place to expand or relax the query and rewrite in order to provide some answers, or a collection of at least competing answers.
It is unclear whether this is a limitation of voice search or is intended because no answer would be better than the wrong answer when there can be so few results returned, versus the 10 blues links which can be refined by users further in desktop search.
This means you need to be pretty much on the money with providing the specific answer in the right way because words will be deleted but not added (query expansion) or reordered (query rewriting).
As an aside, in the Twitter chat which followed my request about unanswerable queries to John Mueller, Glenn Gabe mentioned he’d been doing some testing of questions on Google Home, which illustrated these types of differences between voice and normal web search.
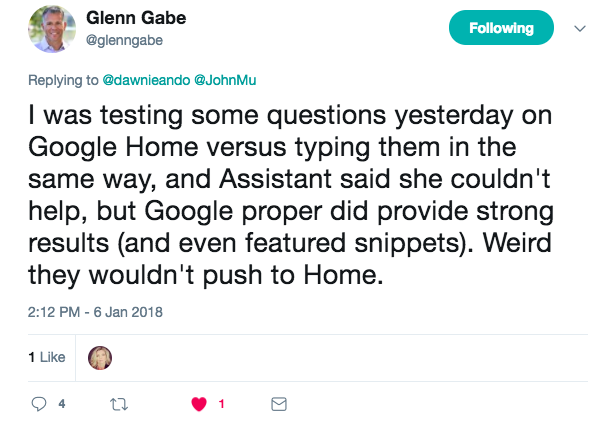
The normal query interpretation system in information retrieval might look something like this, and there are several transformations which take place. (This was not supplied by Alfonseca but was a slide from one of the other lecturers at ESSIR. However, it is widely known in information retrieval.)
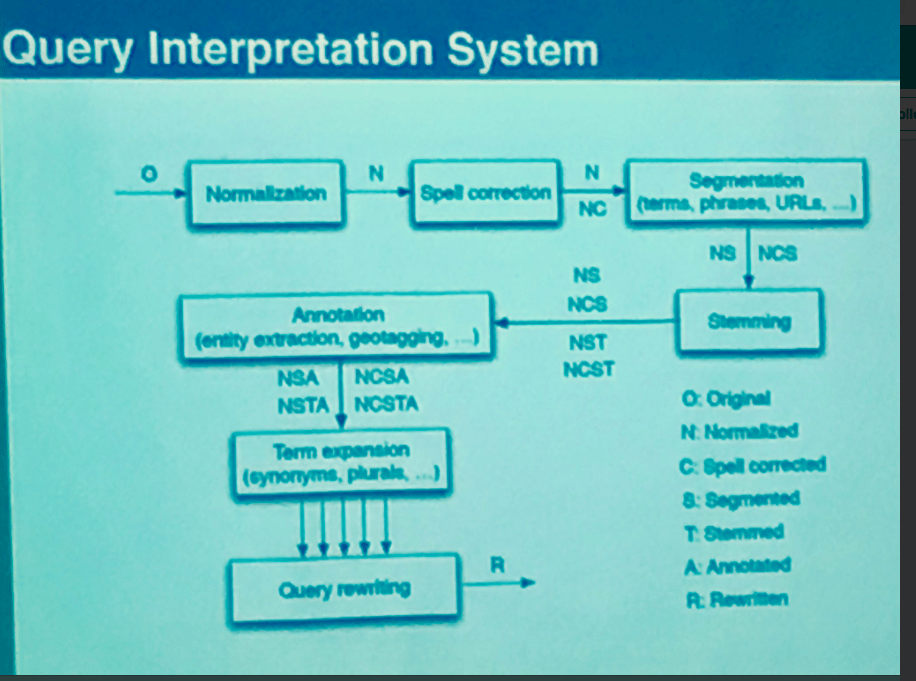
You will see query rewriting is a key part of the written format query manipulation process in information retrieval. Not to be confused with query refining which refers to users further refining initial queries as they re-submit more specific terms en route to completing their informational needs task.
And here is a typical query rewriting example from IR:

If some or all of these transformations are not present in voice search currently this could be limiting.
One example of this is grammar and spelling.
The “Sentence Compression by Deletion with LSTMs” work referred to as “our other work” in the guidelines, appears to sacrifice by removing syntactic function words still used with other compression techniques to avoid grammatical errors or spelling mistakes.
The Raters Guidelines say:
Formulation: it is much easier to understand a badly formulated written answer than an ungrammatical spoken answer, so more care has to be placed in ensuring grammatical correctness.
Grammar matters with spoken conversational voice search more so than written form.
In written form, Google has confirmed grammar does not impact SEO and rankings. However, this may not apply to featured snippets. It certainly matters to voice search.
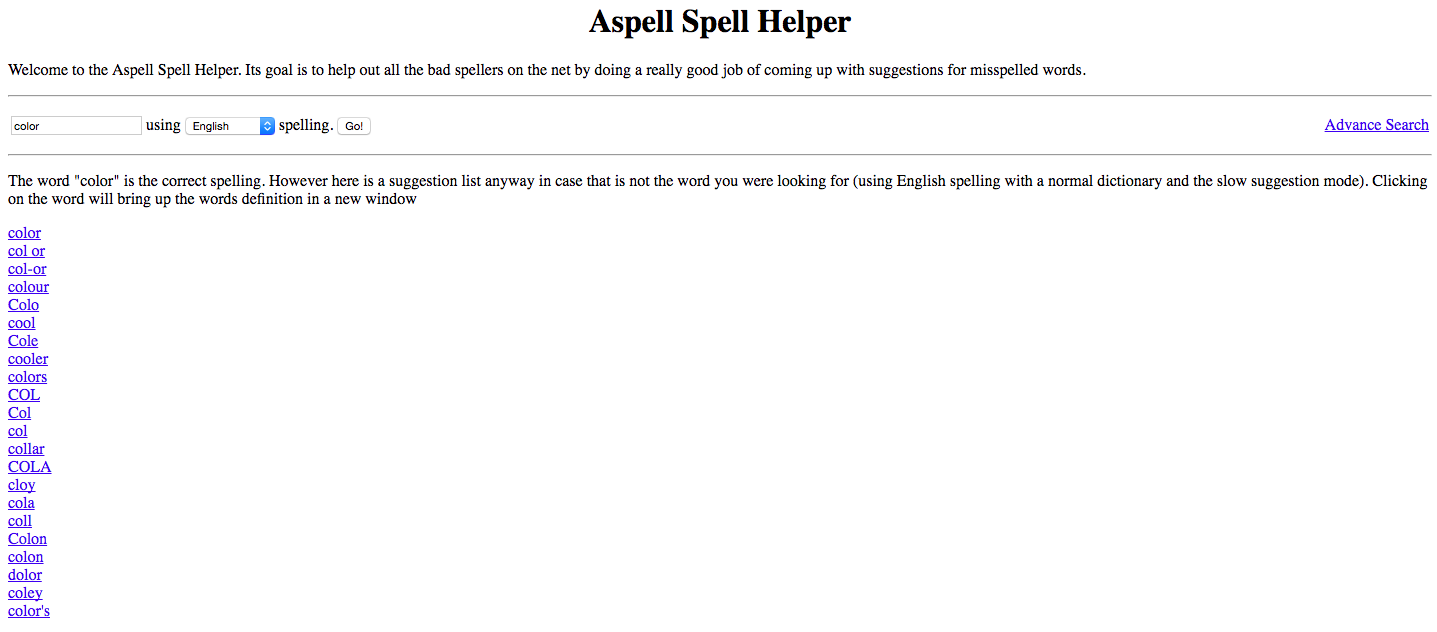
Phonetic algorithms are likely used in written search to identify words that sound similar, even if their spelling differs in written form such as the Soundex algorithm or similar variation of phonetic algorithms (such as the more modern “double metaphone algorithm,” which is in part driven by the Aspell spell helper), or various phonetic algorithms for internationalization.
Here is an example from the Aspell Spell Helper:
 Multi-Turn Conversations
Multi-Turn Conversations
Alfonseca explained “multi-turn” conversations are still challenging. Single turn is when one question is asked and one (or maybe two ) answers are returned to that single question or proposition. Multi-turn relates to more than one sequential question.
One problematic area is where multi-turn questions likely refer to questions which subsequently rely on pro-nouns instead of naming entities in further questioning.
An example might be:
- “What time is it in London?”
- “What’s the weather like there?”
In this instance, “there” would relate to London. This relies on the device remembering the previous question and mapping that across to the second question and to the pro-noun “there.”
Anaphoric & Cataphoric Resolution
A major part of the challenges here may relate to issues with something called anaphoric and cataphoric resolution (a known challenge in linguistics), and we can even see examples in the raters guide which seem to refer to these issues when named entities are taken out of context.
Some of the examples provided give instances similar to anaphora and cataphora when a person is referred to out of context, or with pronouns such as her, him, they, she, after or before their name has been declared later on in a sentence or paragraph. When we add multiple people into these answers this becomes even more problematic in multi-turn questions.
For clarity, I have added a little bit more supporting information to explain anaphora and cataphora.
Where we can we should try to avoid pronouns in the short answers we target at voice search.
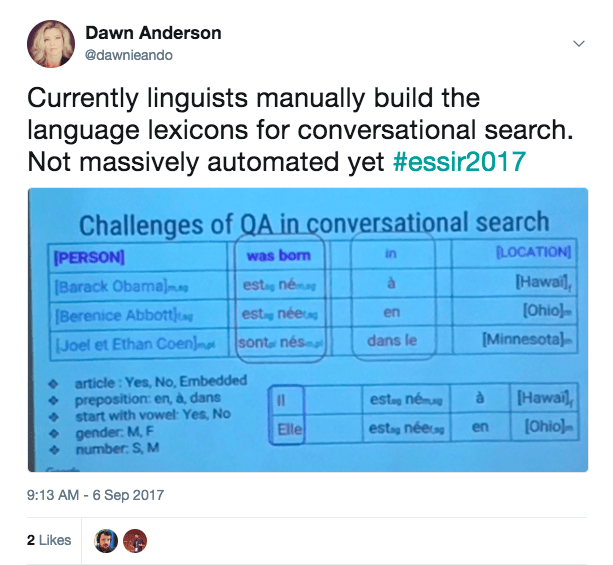
Building of Language Lexicons
Alfonseca confirmed the language lexicon building is not massively automated yet.
Currently, linguists manually build the language lexicons, tagging up the data (likely using part of speech (POS) tagging or named entity (NE) tagging, which identifies words in a body of text as nouns, adjectives, plural-nouns, verbs, pronouns, and so forth) for conversational search.
In an interview with Wired on the subject, Dave Orr, Google Product Manager on conversational search and Google Assistant, also confirms this manual process and the training of neural nets by human Ph.D. linguists using handcrafted data. Wired reports Google refers to this massive team as ‘Pygmalion’.
Google also, again, refers to the work in this interview from their ‘Evaluation of speech for Google as “explicit linguistic knowledge and deep learning solutions.”
As an aside, Orr answers some interesting questions on Quora on the classification of data and neural networks. You should follow him on there.
 Layers of Understanding and Generation
Layers of Understanding and Generation
In addition to these main lecture points, Enrique shared with us examples of the different layers of understanding and generation involved in conversational search, and actions when integrated with Google assistant.
Here is one example he shared which seeks to understand two sequential conversational queries, and then set a reminder for when the Manchester City game is.
Notice, the question “Who is Manchester city playing and when?” was not asked, but the answer was created anyway. We can see this is a combination of entities and text extraction.

When we take this, and combine it with the information from the raters guide and the research paper on Sentence Compression by Deletion with LSTMs, we can possibly draw a picture:
Entities from the Knowledge Graph are searched, and (when Knowledge Graph entities do not exist, or when additional information is needed), extractions of fragments of relevant web text (nouns, verbs, adjectives, pro-nouns) are sought.
Irrelevant words are deleted from the query and the text extractions in webpages for voice search in the index, to aid with sentence compression, and only extract important parts.
By deletion this means words which add no semantic value or are not entities. These may be ‘function words’; for example, pro-nouns, rather than ‘content words’ which are nouns, verbs, adjectives and plural-nouns. ‘Function words’ are often only present in any event to make pages syntactically correct in written form , and are less needed for voice search. ‘Content words’ add semantic meaning when coupled with other ‘content words’ or entities. Semantic meaning adds value, aiding with word-disambiguation, and a greater understanding of the topic.
This process is the “Sentence Compression by Deletion with LSTMs” which turns words (tokens) into a series of ones and zero’s (binary true or false) in “our other work” referred to in the raters guide. It is a simple binary decision of yes or no; true or false, whether the word will be kept, so accuracy is important. The difference appears to be with this deletion and compression algorithm there is not the same dependency upon POS (part of speech) tagging or NE (named entity) tagging to differentiate between relevant and irrelevant words.
A Few More Random Thoughts for Discussion
Does Page Length Normalization Apply to Voice Search?
Page length normalization is a type of penalty (but not in the penalty sense of manual actions or algorithmic suppressions like Penguin and Panda).
A huge page would by its nature rank for anything if it were big enough. To dampen this effect, page length normalization is thought to be implemented in information retrieval to reduce the ranking advantage of longer pages and provide a more level playing field so that the attribute “page length” does not provide an unfair advantage.
As Amit Singhal summarized in his paper on pivoted page length:
“Automatic information retrieval systems have to deal with documents of varying lengths in a text collection. Document length normalization is used to fairly retrieve documents of all lengths.”
In written text, ranking a full written page competes with another full written page, therefore, necessitating the “level playing field” dampener between long and shorter pages (bodies of text), whereas in voice search it is merely a single answer fragment that is extracted.
Page length normalization is arguably less relevant for voice search, because only the most important snippets are extracted and compressed, with the unimportant parts deleted.
Or maybe I am wrong? As I say, these are points for discussion.
How Can SEO Pros Seek to Utilize This Combined Information?
Answer All the Questions, in the Right Way, and Answer with Comprehensive Brevity
It goes without saying that we want to answer all the questions, but it’s key to identify not just the questions, but as many long tailed ways they are asked by our audience, along with propositions too.
It’s not just answering the questions though, it’s the way we answer them.
Voice Queries May Be Longer but Keep Answers Short and Sweet
Voice queries are longer than desktop queries. But it’s important to have brevity and target short sentences for much longer tailed conversational search.
We talk much faster than we type – and we talk a lot.
Ensure the sentences are short and concise and the answer is at the beginning of the page, paragraph, or sentence.
Summarize at the top of the page with a TL;DR, table of contents, executive summary, or a short bulleted list of key points. Add longer form content expanding upon the answer if appropriate to target keyboard based search.
Create an On-Site Customer Support Center or at the Least an FAQ Section
Not only will this help to answer all the many frequently answered questions your audience have, but with some smart internal linking via site sections you can add relatedness cues and hints to other sections.
Adding a support center also has additional benefits from a CRM (customer relationship management) perspective because you’ll likely reduce costs on customer service and also have fewer disgruntled customers.
The rich corpus of text within the section will again add many semantic cues to the whole thematic body of the site, which should also help with ‘relatedness’ again and direct answers for both spoken word and appearance in answer boxes.
WordPress has a particularly straightforward plugin called DW Question and Answer.
Even Better – Co-Create Answers with Audience Members
Co-creation of question and answer content with key members of your user base or audience again has a dual role to play for both SEO and growth of advocacy over time. Plus, there’s argument your users will be less likely to formulate over-optimized “written for SEO” spammy answers to questions, instead writing more naturally.
As an added benefit, on the customer loyalty ladder, co-creation with audience members as partners in projects is considered one of the highest levels achievable.

Become a Stalker: Know Your Audience, Know Them Well & Simulate Their Conversations
Unless your audience is a technical one, or you’re offering a technical product or service offering, it’s highly likely they’ll speak in technical terms.
Ensure you write content in the language they’re likely to talk in and watch out for grammatical errors and pronunciation.
Grammatical errors and misspellings in text based written form on webpages are dealt with by algorithms to correct them.
Soundex, for example, and other phonetic algorithms may be used. In voice search the text appears to be pronounced exactly as it is written to spelling and grammar matter much more.
Mine forum comments, customer service data, live chat and email data where possible to get a feel for what your niche audience talks about.
Carry out interviews with your audience. Hold panel discussions.
Add a customer feedback survey on site and collect questions and answers there too. Tools like Data Miner provide a free solution to take to forums where your community gathers.
At a high level, use Google Analytics audience demographics to get a high view of who your visitors are, then drill down by affinity groups and interests.
Naturally, a competitor analysis on larger sites display advertising provides more insight into possible communities your audience hangs out in. Hang around there, identifying typical pain points and solutions they seek in natural conversation, and the language they use in doing so.
There is even psychographic audience assessment software such as Crystal Knows, which builds personality maps of prospects.
Use Word Clouds to Visualize Important Key Supporting Textual Themes
Carry out keyword research, related queries, mine customer service, email and live chat data, and from the collated data build simple word clouds to highlight the most prominent pain points and audience micro-topics.
Find out What Questions Come Next: Multi-Turn Questions & Query-Refinement
Anticipate the next question or informational need.
- What does your audience ask next, and at what stage in their user search journey, and how do they ask it?
- What are the typical sequential questions which follow each other?
Think about user tasks and the steps taken to achieve those tasks when searching. We know that Google talks of this Berry Picking, or foraging search behavior as micro-moments, but we need to get more granular than this and understand what all the user tasks are around search queries and anticipate them.
Anaphoric and Cataphoric Resolution
Remember to consider anaphora and cataphora. Remember, this is particularly exasperated when we introduce multiple characters to a body of text.
Avoid he’s, she’s, they’s, and theirs where possible, referring instead to the entity or named person, to avoid issues with anaphoric and cataphoric resolution, retaining linguistic context as often as you can, unless it reads ridiculously.
Then you may need to consider a separate short section on the page focusing on voice and avoiding anaphora and cataphora. Make a clear connection in question answering and proposition meeting which entity or instance is referred to.
Query-Refinement
Query-refinement (via ‘People also asked’) in search results provides us with some strong clues as to what comes next from typical users.
There are some interesting papers in information retrieval which discuss how ‘categories’ of query options are provided there to sniff out what people are really looking for next and provide groups of query types to present to users and draw out search intent in their berry-picking search behavior.
In the example below we can see the types of queries can be categorized as tools and further informational content:

Find out What People Use Voice Search For
Back in 2014, Google produced a report which provides insight into what people use voice search for.
Even though the figures will be out of date you will get some ideas around the tasks people carry out with voice search.

Get Consistently Local, Understand Local Type Queries and Intent
Mobile intent is very different to desktop. Be aware of this.
Even as far back as 2014 over 50 percent of search on mobile had local intent, and that was before the 2017 Global Year of the Mobile Majority.
Realize voice searches on mobile are likely to be far more locally driven than on eyes-free home devices. Eyes-free devices will differ again from desktop and on-the-go mobile.
Understand which queries are typical to which device type, in which scenario and typical audience media type consumption preferences.
The way you formulate pages will need to be adapted to, and carer for these different devices and user behavior (text vs. written words).
People will say different things at different times on different types of devices and in different scenarios. People still want to be able to consume information in different ways and we know there are seven learning styles (visual, verbal, physical, aural, logical, social leaners and solitary learners). We each have our preferences or partial preferences with a mix of styles dependent upon scenarios or even our mood at the time.
Be consistent in the data you can control online. Ensure you claim and optimize (not over-optimize), all possible opportunities across Google My Business and Google Maps to own local.
Focus on Building Entities, Earning Featured Snippets & Implementing Schema
Given the Knowledge Graph and Schema is the first place to look for answers to voice search it certainly strengthens the business case for adding schema wherever you can on your site to mark up entities, predicates, and relationships where possible.
We need to ensure we provide structure around data and avoid the unstructured mess of standard webpage text wherever possible. More than ever voice search means this is vital.
My good friend and an awesome SEO, Mike, mentioned the speakable schema to me recently, which has some possibilities worth exploring for voice search.
It also goes without saying we should implement HowTo schema, given in 2017 users asked “How” more than anything else.
Remember Structure and ‘Relatedness’ Matters ‘a Lot’
Add meaning with relatedness to avoid being “fuzzy” in your unstructured content. Add semi-structured data as often as you can to support the largely unstructured text mass in webpages and ‘noise’.
Related content is not just there for humans but to add strong semantic cues. Be as granular as you can with this for stronger disambiguation. It goes without saying categorizing and subcategorizing to build strong “relatedness” has never been more important.
Dealing with the Tabular Data Issue
For now, it seems wise for voice search to have both a table and solid text answers accompanying answers.
Conclusion
While we are still gathering information on how to best handle voice search, what is clear is the strategy we need to employ will have many differences to those involved in competing in written form search.
We may even need a whole new strategy to target the types of answers and formulations needed to win. Semantic understanding is still an issue.
We need to be aware of the issues behind this, which the likes of anaphoric and cataphoric resolution can create, and bear in mind there is no paraphrasing currently in voice search, so you need to answer all the questions and answer them in the right way.
Focus on ensuring strong relatedness to ensure a lot of context is passed throughout your site in this environment. For tabular data, we need to target both written and verbal search.
Hopefully, over coming months we will get sight of more voice search data so we can find more ways to improve and maybe be “the one.”
Further Information
Example of Sentence Compression
The sentence compression technology used to pull out the most important fragments within the sentences in text to answer a query is built on top of the linguistic analysis functionality of machine learning algorithms Parsey McParseface, designed to explain the functional role of each word in a sentence.
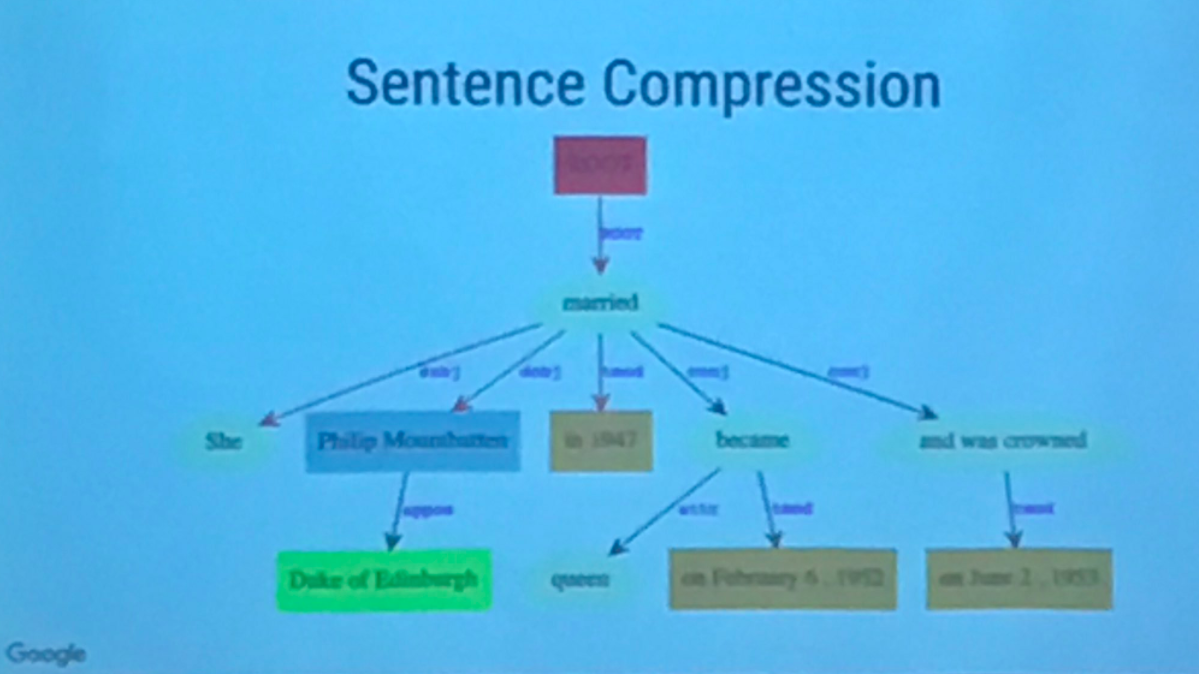

The example Alfonseca provided was:
“She married Philip Mountbatten, Duke of Edinburgh, in 1947, became queen on February 6, 1952.”
where the following underlined words are kept and the others are discarded:
“She married [Philip Mountbatten], [Duke of Edinburgh], in 1947, became queen on February 6, 1952.”
This would likely answer a sequential question around when Queen Elizabeth became Queen of England when also connected via other more structured data / entity relation of [capital city of england].
The sentence is compressed with everything between “She” and “became queen on February 6, 1952” omitted.
Sentence Compression by Deletion with LSTMs
Sentence Compression by Deletion with LSTMs appears to be exceptional because it does not totally rely on Part of Speech (POS) tags or Named Entity (NE) recognizer tags to differentiate between words which are relevant and those which are irrelevant in order to extract relevant words (tokens) and delete those which are not.
To clarify, POS tagging is mostly used in bodies of text to identify content words such a nouns, verbs, adjectives, pronouns, and so forth, which provide further semantic understanding as part of word disambiguation. Whereas, NE recognizer tags are described as by Stanford as:
“Named Entity Recognition (NER) labels sequences of words in a text which are the names of things, such as person and company names, or gene and protein names.”
Function words help to provide clear structuring of sentences but do not provide more information or added value to help with word-disambiguation. They are merely there to make the sentence read better.
Examples of these are pronouns, determiners, prepositions and conjunctions. These make for more enjoyable reading and are essential to text sounding natural, but are not ‘knowledge-providing’ types of words. Examples are “in”, “and”, “to”, “the”, “therefore”, “whereby”, and so forth.
Therefore, naturally compressing the sentence by simply cutting down the words to only useful ones, with a simple yes or no binary decision.
The technology uses long short-term memory (LSTM) units (or blocks), which are a building unit for layers of a recurrent neural network (RNN)
Here are some other examples of general sentence compression.
Anaphoric & Cataphoric Resolution
What Is Anaphora?
A search of “anaphora” provides a reasonable explanation:
“In grammar, anaphora is the use of a word referring back to a word used earlier in a text or conversation, to avoid repetition, for example, the pronouns he, she, it and they and the verb do in I like it and do they.”
This problem may be particularly prevalent in sequential multi-turn conversations.
We are not provided with information on whether the human raters ask sequential multi-turn questions, or query propositions, but as we know from Alfonseca’s lecture, this is still a problematic area, so we can presume this is will require human rater feedback to seek gold standard answers over time.
May refer to multi-chaining of anaphora and cataphora for example:
An example might be:
- Who is the president of the United States
- Where was he born?
- Where did he live before he was president?
- Who is he married to?
- What are his children called?
- When he married Michelle where did [they] get married? – ‘They’ here may be where things get very problematic because we have introduced another person and they are both referred to with a pronoun of they.
Examples of anaphora
- The student studied really hard for her test.
- The student saw herself in the mirror.
- John studied really hard for his test.
Examples of cataphora
- Because she studied really hard, Nancy aced her test.
Here are more anaphora & cataphora examples.
Image Credits
Screenshots taken by author, January 2018
