

SEO has changed over the last few years.
A lot.
With advancements to algorithms and the introduction of machine learning to search, SEO has become harder to perfect.
So how do you remain (or become) successful today?
Here are six enterprise SEO tactics and strategies that work.
1. Boost Rankings of Keywords Within Striking Distance
Targeting keywords that rank in striking distance (i.e., keywords that rank in positions 11 to 20) are low-hanging fruit and provide quick wins to improve your performance.
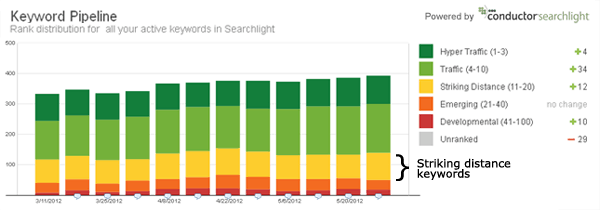
The process of finding striking distance keywords is easy:
- Enter your domain in Ahrefs.
- Go to organic keywords and click on the flag (i.e., U.S., or wherever you’re targeting).
- Click on position and enter in 11 to 20 and filter your keywords that rank in striking distance.
Why Should Brands Do This
It’s a lot easier to move keywords that are close to Page 1 to the first page.
Targeting keywords that rank in striking distance is the easiest way to find the best opportunities.
The Benefits
- Incremental traffic.
- Potential lift in conversions.
- Better visibility.
Results
We increased traffic by 15% from a keyword in three months for one of our hospitality clients by moving the keyword from position 11 to position 6.
By optimizing the title, content, building links, and getting some social endorsements to landing pages that rank for these keywords, you may be able to increase your visibility onto Page 1 – and eventually into one of the top three positions over time.
Once you get your clients or your site to the top 3, the site will have more incremental traffic and conversions and be more visible in the ultra-competitive SERPs.
2. Expand Your Content
Once you find keywords that rank in striking distance and your site is relevant for those keywords, you can expand the current content to meet end user intent and make it more relevant and useful for your users.
This is especially important if you have thin or empty pages (pages with little to no content).
The process of finding thin pages and expanding the content is easy.
- Enter your domain in DeepCrawl.
- Go to the Content section and click on content > body content > thin pages.
- Grab the URL and paste it in Ahrefs and see what keywords the page is ranking for and find the position. If the keyword is ranking in striking distance and is relevant and important, review the page, and expand the content to cover more topics, answer more questions, etc.
Why Should Brands Do This
Low-quality pages and thin content are increasingly hard to rank in Google, thanks to numerous algorithmic updates.
While not impossible, it’s hard to rank thin content for keywords where there is lots of competition.
Brands need to give users high-quality content.
There are two dangers of publishing content with little to no value. It:
- Won’t rank well in search engines.
- Will result in a bad experience for users.
If you want to make your site rank, give users useful and meaningful content that they can consume and find helpful.
In other words: stop selling and start helping.
The Benefits
- Good user experience.
- Higher domain authority.
- Better engagement metrics.
- Better visibility and more traffic.
Results
We increased traffic on a page for one of our B2B clients by 25% in 6 months and also increased the number of keywords ranking from 1 to 15 by expanding the content to cover off on new topics and increasing the amount of content on the page from 100 to 1,200 words.
Here’s an example of a site that has thin content and received a manual action from Google.
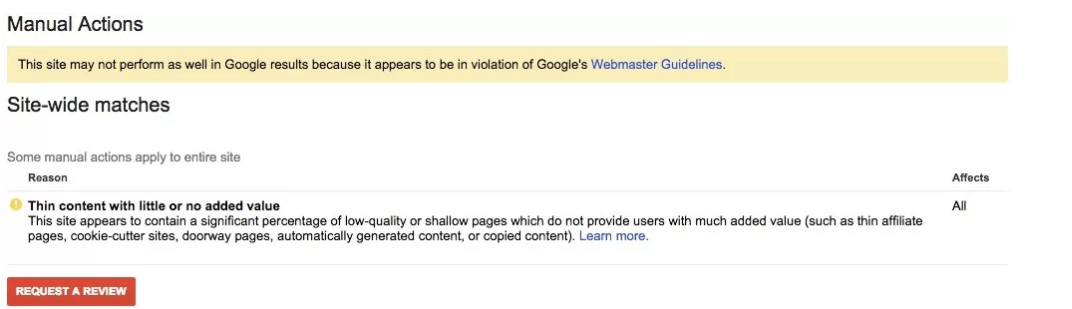
There are some easy fixes to clean up thin or empty pages:
- Add the noindex meta tag to those pages and block them in the robots.txt file so Google won’t crawl the pages.
- Add high-quality, relevant, and useful content to the pages to satisfy multiple intents (i.e., 600 words or more).
- Remove the page and let the page result in a 404-response code (or 301 redirect it to better, relevant content).
3. Be a Content-Producing Machine
Content is extremely important for SEO, especially early-stage content “awareness.”
Nearly every consumer journey starts with a problem and informational (not transactional) search.
If brands and agencies want to be successful and win in the SERPs, they must continue to develop high-quality content based on intent for all stages of the user journey.
Most SEO pros will run out of things to do for their clients if they had them for several years, but you can never stop developing content.
A blog is a great way to add content to capture early to mid-stage and even transactional content.
Most people ask what kind of content they should create.
The answer?
All types.
Let’s stop thinking of content as only text.
Content can also be in the form of images and videos.
Video content and answer box are perfect content types.
Let’s look at an example for [how to plant grass seed]:
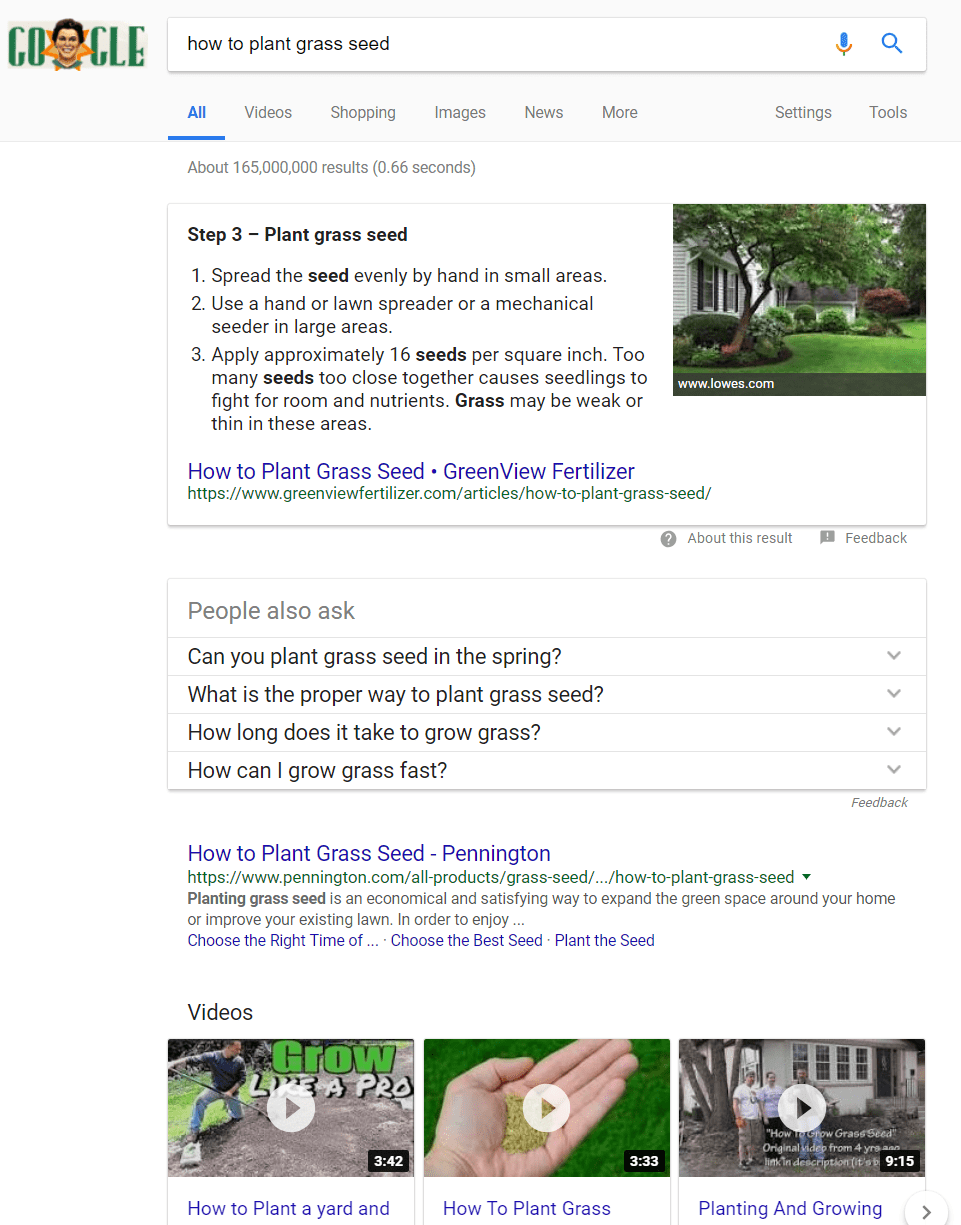
The video and rich results cover off well on this intent and take up prime real estate.
People always ask, “what performs better, short-form, or long form-content?” (Long-form content is defined as content that is over 1,000-1,200 words.)
Numerous correlation studies support the idea that long-form content performs the best in the SERPs. Users engage more with content that is longer and more valuable.
However, if you create content that is short, resourceful, and satisfies or provides value to the user and their intent, that might work as well.
Depending on your audience, it is best to test and see what works better for your users to provide them with the best experience.
Finally, when creating content, we need to stop thinking that we need to create content that is targeting one or two keywords.
You’re either going to be relevant for certain topics and keywords based on the user’s search intent, or you aren’t.
We need to create content with the following in mind:
- Write content that answers users’ questions.
- Create unique, specific, high-quality, and original content that provides users with a good experience.
- Review and analyze the competitive landscape for any topic or query. Determine the level of content quality needed to rank in search and to engage your target audience and use that as a guide to know what to shoot for.
- Create content that is engaging by adding images, facts, or lists.
- Be useful and informative. Create content that your users will get some benefit from. For example, if they have a problem, the content will help them solve the problem either through a product or an answer.
4. Featured Snippet Optimization
Having a featured snippet strategy can help your site show up in Google’s rich results.
The featured snippet is not only tied to the answer for voice search, it appears before the organic results, which could give you maximum exposure and traffic because it is above the fold.
How to Rank for Featured Snippets
To show up as a featured snippet, you must:
- Address the users’ queries first in the content, specifically in an H1.
- Then optimize the answer in a format preferred by users.
Is your content directly answering users’ queries about the topic?
If not, then update your content to make sure it answers the user’s question.
You can use tools like SEMrush to find out if there is an opportunity that your query generates a featured snippet.
Be sure to use lists, tables, and paragraphs with proper structured data markup.
Tips to Show up as Featured Snippets
- Target keywords that already have a featured snippet.
- Answer the question clearly, quickly, and in under 100 words.
- Make sure you’re using factual and accurate information that users will find useful.
- Include numbered lists, tables, or graphs.
- Make sure one article answers many similar questions.
- Don’t give all the information away. Give users a reason to want to go to your site to learn more.
- Test it using Google’s rich result tool.
- Use headers to break up content.
- Don’t forget to include high-quality images and videos and use voice transcripts for videos to help show for video snippets.
5. Internal & External Linking
Most SEO pros forget about the power of internal linking.
If you have pages of related content that can link to one another, you should take advantage of it.
Internal links connect your content and give Google and other search engines a good idea of the structure of your website and let them find important pages that offer more value.
The good thing about internal linking is that you can control what pages it links to and you can also control the anchor text that links to another page.
Getting links from external and related sites with high authority are still important to improve your organic performance, but as always, continue to focus on quality rather than quantity.
Also, be sure to use social to distribute your content to get more high-quality links and endorsements for your content.
6. Using Structured Data
Structured data is important to dress up and decorate your content since it helps Google understand your content better.
This will increase the chances of your content showing up in the rich results, and getting higher click-through rates, traffic, and more.
While we’re in the age of automation, there are also some tasks and strategies that can be automated that can free up our time and allow us to spend more time on strategy, sales, and client communications.
Summary
The search engines’ algorithms are getting smarter and the war to rank on Page 1 is getting more competitive all the time.
But with the right tactics and strategies, you can get to the top of the search engines in time.
While there are more strategies (e.g., page speed optimization) that can improve your organic performance but were not mentioned in this post, these are the six tactics that still work based on my experience working with enterprise brands.
These are worth testing out on your own sites or with your clients.
Image Credits
Featured Image: Paulo Bobita
All screenshots taken by author
