

As SEOs, we’re obsessed with how Google’s algorithms work. Well, it turns out they work together.
In a recent Webmaster Central Google Hangout John Mueller revealed that Google’s various algorithms share data. Mueller’s exact quote was:
“With regards to connections with other quality algorithms, in general we try to keep these algorithms as separated as possible so that each of these quality algorithms has its own data set to work on.
One thing that does happen though is that sometimes quality information from one algorithm is used in other algorithms where when it comes to understanding like how we should be treating this website. So for example, if we think this website is generally lower quality then that could flow into other things like, maybe maybe like, crawling and indexing speed something like.”
You can hear it straight from the horse’s mouth here:
This got me thinking about how Google’s algorithms work together now, how they will work together moving forward, and how this understanding can help you optimize your websites for the future.
An interesting coincidence to note: I’m currently working with a client in the microservices space. I won’t get too far technically into what microservices are, but I will discuss briefly how understanding them – and Google’s actions in the space – can help you wrap your brain around what’s going on with Google’s algorithms.
My Problem With Microservices
When I first started working with our client I had a heck of a time wrapping my brain around microservices and how they functioned.
At its core, it’s a simple idea – rather than building one big program you build a bunch of smaller ones that all work together.
But how does this work? How does this get structured?
The solution is near and dear to this nerd’s heart – and will help us understand how algorithms work together.
And, for context, when I say “nerd,” I mean this kind of nerd:

The Solution Is … Borg
I kid you not. Google actually has a product called Borg. Google uses Borg to manage groups of applications designed to perform a specific function.
More common in the microservices space, however, is a system called Kubernetes. It basically does the same thing but isn’t proprietary to Google.
To give you an idea of where this ties together, Kubernetes was built by some ex-Googlers who’d worked with Borg and was code named Project 7 (after 7 of 9, the Borg-turned-human of “Star Trek” fame). I don’t think it’s a coincidence that the name starts with “Kube”.
Quite honestly, it was as soon as I was able to visualize this way of systems working together that I was able to wrap my brain around microservices. Each system sitting inside a container (think: Borg cube) and setup such that data is shared between them when necessary but where a failure in one does not cascade to the others any more than the destruction of a Borg cube impacts the hive.
Microalgorithms
This is how we must think of the new world order of algorithms.
Once upon a time the Google algorithm was a fairly basic formula (by today’s standards) reliant on fairly basic data. Backlinks, keyword densities, anchor text – collect a bit of data in these core areas, manually adjust their weighting to improve the results and you were done (for 4 to 6 weeks until the next Dance … errr … update).
Google had no need for a Borg approach at that time. But that time is over.
Google’s system has gotten far more complex. Where redundancy alone was once enough to keep the system healthy, today it won’t suffice.
What is needed today is a system of independent algorithms that produce a whole that is beyond the sum of its parts. Specialized algorithms like Panda adding in factors that could not be built into one of the other algorithms and more, that is adjustable and pushable without accidentally impacting something else.
The way that I personally visualize Google’s algorithm at this stage is as a collection of Borg cubes, each representing an algorithm and each with a number of workers inside dedicated to the mission at hand be that the task of determining the crawl budget for a site to looking for link spam signals to rendering or judging page layout, etc.
Like the Borg of “Star Trek” fame there is a queen, a central control that can say, “I am the Borg.” Where once the queen was the core algorithm and all data fed to it and produced a result, we see this now converting to a system of control rather than a system of judgment.
What we’re hearing presently from John is that these “Borg Cubes” communicate with each other independent of their queen. This means that each “Cube” is not simply fulfilling its duty and reporting what it finds for processing but they are communicating with each other and adjusting how they are treating and concluding from said data without the need for that adjustment to be judged.
The queen is evolving from a collector of data and producer of results into a mechanism that controls the way the various algorithms interact to produce the desired outcome.
Presently this is likely limited to fairly basic areas as John mentions. Things like spam in one area triggering a reduction in crawl budget in another. Predictable and controllable but this can’t last much longer.
Why Should You Care?
As we saw in an article a couple months ago on the dramatic changes present and coming in the organic search space AI and machine learning are dramatically changing the landscape. The devices people are using are also changing. Even how users are viewed, and how they are catered to, will cause massive upheaval in how search algorithms function.
So, you may be asking, what’s the difference whether the rankings are taken from a single formula, a network of algorithms that feed results back into a complex formula, or a network of algorithms that all communicate with each other?
It’s a good question with a simple answer in the form of a rhetorical question:
When a team is preparing for a big game do they rely on watching what their opponent is doing that day or do they study their capabilities to prepare themselves for whatever may come?
Anyone who’s played any level of sports past grade school gym knows the answer to this – and anyone who’s been in SEO for more than a year-or-two knows it applies here as well.
Knowing what Google is doing today is nice, but we really need to wrap our brains around what Google is capable of and what they’re likely moving toward.
Back To Our Borg Analogy
Let’s look now at how all of this works with Google. Let’s begin with a quick breakdown of the what the two main structures look and act like:
Old / Semi-Current Structure
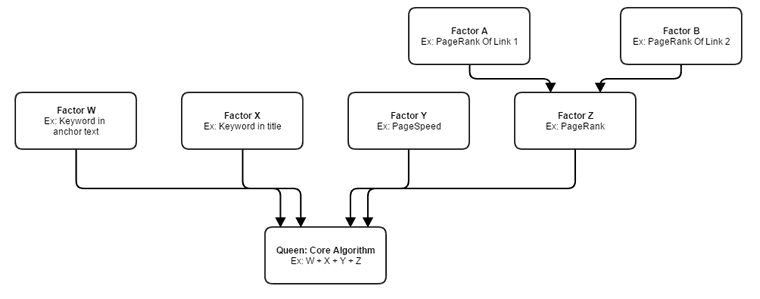
Notwithstanding the limited use of the algorithms communicating between each other presently this is fundamentally an example of how the system works (albeit in a very very limited fashion).
Signals are weighted. Some of these signals are directly addressed by the core algorithm (like W, X, and Y) and others are algorithms which produce a final product that is then fed into the core algorithm (PageRank in this example).
But let’s look at what’s likely on the horizon.
Upcoming Structure
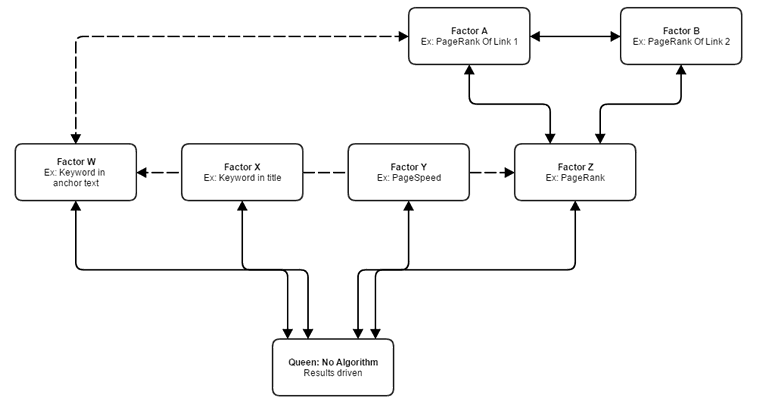
This is a simplistic visualization, but I hope it gets the point across about the likely future of Google’s algorithms. This matches closely with what we’re seeing and hearing from Google.
Notice that the queen is no longer a specific algorithm, but rather a set of results-driven directives. This is a necessary setup in a world with John Giannandrea at the helm of Google search and machine learning and AI taking increasingly larger roles in determining the search results.
A core algorithm is too slow and static when compared with a system built around only desired outcomes which is the obvious end goal for Google (to have a system designed around a result and not a pre-conceived idea of a formula).
You’ll also notice that the communication between different ranking signals also exists.
Areas that can improve on their own data by knowing the data of other nodes will do so. Think of it as a Borg collective sharing information related to a task at hand but ignoring information from cubes on unrelated tasks.
You could also view it like a well-run company where different divisions need to know what others are doing but not everything. The marketing department, for example, will need to know if the engineers will have a new product ready for launch on a set date but not need to know if the janitorial staff got paid that day.
So What?!
Why does any of this matter? Who cares if it’s a Borg collective or …

I do. And you should, too.
Understanding that the various systems work and communicate together as Mueller has discussed will dramatically help you when you’re troubleshooting problems or trying to understand rankings.
No longer will we be able to look to one area in isolation when there is a problem. From what we’re hearing now we may see the impact in one area from issues in another, but if I’m right (and I’m pretty sure I am) this trend will be amplified dramatically.
We’re heading toward a world where there is essentially only one factor that matters: Does the page you want to rank for a query match the user’s intent? Is it the best resource?
It is through the communication between different areas of the algorithm that the shift can take place from a queen that simply is an algorithm built to process data and produce a result to an environment where the queen is programmed only with the desired outcome (or to create her own based on business objectives) and only responsible for understanding what signals indicate the best outcome has been met and send instructions to the other Borg cubes (read: ranking factors) on what they should be looking for.
We’re truly entering a brave new SEO world. The significant progress Google is making in machine learning and AI is pushing it forward at an amazing if not alarming rate. I predict we’re looking at a full transformation in the next two or three years and a rapid move from here to there.
We can try to fight it. We can just stick to our old strategies of simple cause-and-effect.
Or we can evolve. We can view the more holistic whole that is coming about.
Regardless of what we would personally like: Resistance is futile. (Sorry – you just knew I had to end on that!)
