

Welcome back to another week for the geeks.
It was fairly quiet out there as far as Google search patents go, but I did see a couple worth sharing over the last few weeks.
So, let’s get into it.
Latest Google Patents of Interest
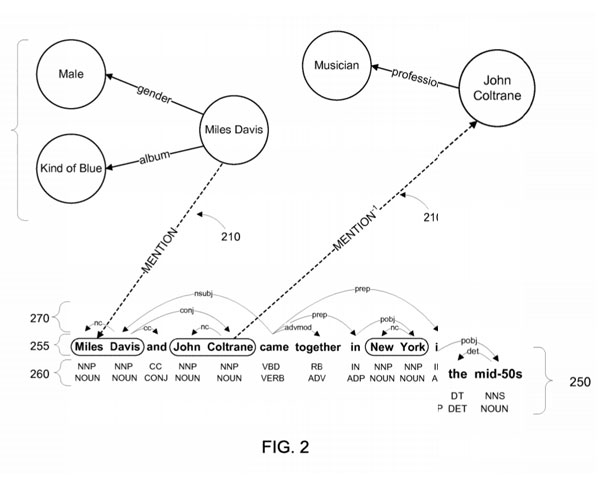
Querying a data graph using natural language queries
- Filed: March 13, 2013
- Awarded: October 20, 2020
Abstract
“Implementations include systems and methods for querying a data graph. An example method includes receiving a machine learning module trained to produce a model with multiple features for a query, each feature representing a path in a data graph. The method also includes receiving a search query that includes a first search term, mapping the search query to the query, and mapping the first search term to a first entity in the data graph. The method may also include identifying a second entity in the data graph using the first entity and at least one of the multiple weighted features, and providing information relating to the second entity in a response to the search query. Some implementations may also include training the machine learning module by, for example, generating positive and negative training examples from an answer to a query.”
Dave’s Notes
It’s interesting that this was filed back in 2013.
Why?
Because it deals with semantic elements, graphs, and entities.
A lot of SEO pros back then had no clue what that stuff was as it was rarely talked about.
In fact, to this day a lot of SEO folks don’t really “get” how Google deals with semantics.
Hell, recently I still see them talking about archaic approaches such as LSI.
To say a lot of the organic search profession is well and truly behind when it comes to how search actually works these days.
The core of this patent is discussing how in the past a lot of entity relations and graph data were actually cobbled together manually (Can you imagine?) and they were seeking to more automate this with machine learning.
Again, this is 2013, my friends.
It shouldn’t be a talking point over the last few years… but it has been.
Anyway, let’s look at some points of interest.
Notable
“(…) in a data graph, entities, such as people, places, things, concepts, etc., may be stored as nodes and the edges between nodes may indicate the relationship between the nodes. In such a data graph, the nodes “Maryland” and “United States” may be linked by the edges of “in country” and/or “has state.” “
“The knowledge extracted from the text and the data graph is used as input to train a machine learning algorithm to predict tuples for the data graph. The trained machine learning algorithm may produce multiple weighted features for a given relationship, each feature representing an inference about how two entities might be related. “
“Some implementations allow natural language queries to be answered from the data graph. In such implementations, the machine learning module can be trained to map features to queries, and the features being used to provide possible query results. The training may involve using positive examples from search records or from query results obtained from a document-based search engine. The trained machine learning module may produce multiple weighted features, where each feature represents one possible query answer, represented by a path in the data graph. ”
Search and retrieval of structured information cards
- Filed: October 26, 2020
- Awarded: November 3, 2020
Abstract
“Methods, systems, apparatus, including computer programs encoded on computer storage medium, to facilitate identification of additional trigger-terms for a structured information card. In one aspect, the method includes actions of accessing data associated with a template for presenting structured information, wherein the accessed data references (i) a label term and (ii) a value. Other actions may include obtaining a candidate label term, identifying one or more entities that are associated with the label term, identifying one or more of the entities that are associated with the candidate label term, and for each particular entity of the one or more entities that are associated with the candidate label term, associating, with the candidate label term, (i) a label term that is associated with the particular entity, and (ii) the value associated with the label term.”
Dave’s Notes
Nothing really earth-shattering here, but does give us a sense of how information cards, entities, knowledge bases, and structured data can play together.
For me, it’s one more example of how SEO has changed over the years and is far more than what seemingly meets-the-eye with practitioners and publishers in the biz.
Notable
“(…) a card trigger-term identification unit is provided that can identify additional trigger-terms for a structured information card. The card trigger-term identification unit allows the grammar of one or more structured information cards to be tuned, over time, by evaluating candidate terms for potential inclusion in the grammar of a structured information card.”
“For example, assume the grammar for a “Movie” structured information card includes the terms “movie time,” “movie ticket confirmation,” and “ticket confirmation number.” The card trigger-term identification unit may analyze the terms associated with the grammar of the “Movie” structured information card and one or candidate queries, and identify an additional trigger-term for the “Movie” structured information card such as the trigger-term “movie ticket.” Accordingly, subsequent queries that are received that include the terms such as “movie time”, “movie ticket,” or both will trigger the display of a “Movie” structured information card in response to such queries.”
That’s about it for this week folks.
As always, never forget the depth of how search engines work and constantly keep pushing the boundaries with your learning and strategies.
See you next week!
More Resources:
- 3 Latest Google Patents of Interest – October 13, 2020
- A Rundown of Google Patents from the First Half of 2020
- A Personalized Entity Repository in the Knowledge Graph
Image Credits
Featured Image: Created by author, November 2020
In-Post Images: USPTO