

Google Analytics and Search Console data do not match.
The discrepancy creates the impression that the data is inaccurate in some way.
The reality is that the data is in fact accurate. The discrepancy exists in what is being tracked and how Google chooses to present it.
Google Analytics Versus Search Console
Reconciling Google Analytics and Search Console data can be difficult because the numbers don’t really match.
The reason is because both services are solving different problems. Because of that reason, both services take different approaches to how data is collected and reported.
Purpose Of Google Analytics
The insights provided by Google Analytics are designed to communicate how well a website itself is performing in terms of user engagement metrics (time on page, etc.), reporting conversion-related goals, and showing site visitor activity on the website itself.
Typical reporting includes:
- Analytics can track performance goals such as purchases or lead generation.
- Can provide real-time site traffic data.
- Provides session quality data to show how close traffic is to conversions.
- User behavior on the website.
What’s important to note about the data provided by Google Analytics is that it’s measuring how the site performs (in terms of site visitors).
While Analytics provides feedback about webpage performance, the focus of that report is relative to the site traffic and relative to what the site visitors do.
The Google Analytics overview page reflects the focus on the site visitor:
“Get a deeper understanding of your customers. Google Analytics gives you the free tools you need to analyze data for your business in one place.
Understand your site… users to better evaluate the performance of your marketing, content, products, and more.”
The underlying purpose of Google Analytics is vastly different from Search Console because Search Console is focused on website performance relative to search visibility.
Purpose Of Google Search Console
The insights provided by Search Console are designed to help publishers understand how their websites are performing in Google Search.
Search Console also provides search and indexing data that are useful for troubleshooting problems with search visibility.
On a different level, Search Console provides a way for Google to proactively communicate with publishers about search visibility issues like manual actions (penalties), hacked status, improperly configured structured data, mobile usability issues, and other useful information that helps a publisher maintain ideal search visibility in Google search.
Lastly, Search Console provides a way for publishers to debug localized language issues, set a site-wide country target, disavow inbound links, and other tasks that revolve around improving search visibility.
Google’s Search Console help page lists these data points:
- Confirm that Google can find and crawl your site.
- Fix indexing problems and request re-indexing of new or updated content.
- View Google Search traffic data for your site: how often your site appears in Google Search, which search queries show your site, how often searchers click through for those queries, and more.
- Receive alerts when Google encounters indexing, spam, or other issues on your site.
- Show you which sites link to your website.
- Troubleshoot issues for AMP, mobile usability, and other Search features.
The first reason why Search Console and Analytics data is different is that the purpose of each product is different – they do different things.
Search Console And Analytics Discrepancies Explained
Because both services have different purposes, Google Search Console and Analytics will do things like aggregate data in different ways, and because of that the reports will be different and have the appearance of a discrepancy.
The data is accurate but it’s simply displayed differently.
The following is a list of different reasons why Analytics and Search Console data appear to have discrepancies.
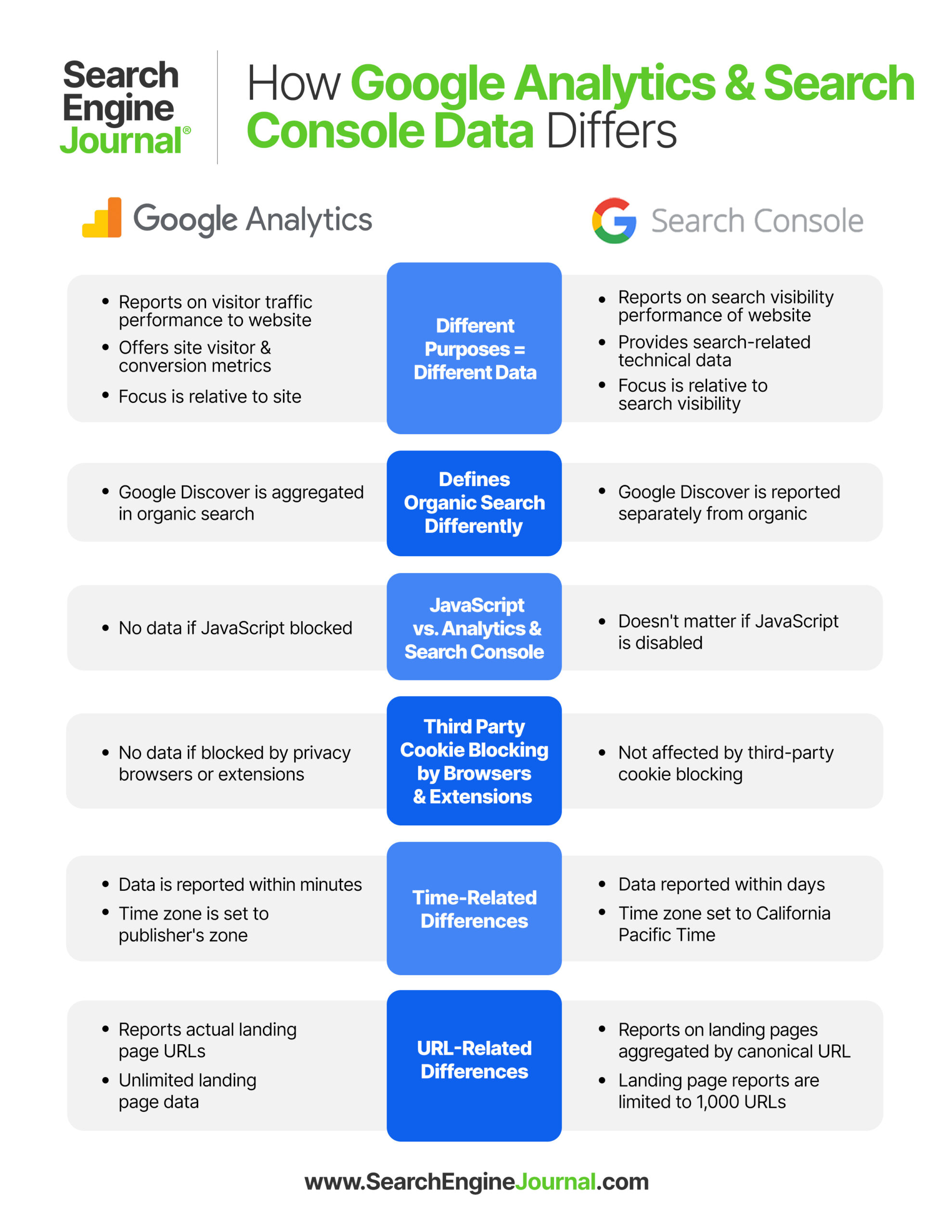 Image created by Paulo Bobita/Search Engine Journal, June 2022
Image created by Paulo Bobita/Search Engine Journal, June 2022Definition Of Search Is Different
A major cause of the discrepancy between Google Analytics and Search Console is that they both measure search traffic differently.
What Analytics calls search traffic is different from what Search Console calls search traffic.
Google Analytics folds the Google Discover data into the category of Search.
That means that when you analyze organic search-related traffic in Analytics, it’s not just the traffic from the Google search box, it can also include traffic from Google Discover.
Google Search Console, however, splits the traffic from Google Discover and the organic search results, showing a report for Google Discover traffic on its own.
Search Console And Analytics Versus JavaScript
Google Analytics will only report data collected from site visitors who have JavaScript activated on their browser.
Search Console collects data regardless if JavaScript is enabled in a browser or not.
Google Analytics Is Blocked From Collecting Data
Another reason why Search Console and Analytics won’t match is because Analytics tracking is increasingly blocked online.
Google Analytics cannot collect data from privacy-focused browsers and extensions that block analytics.
For example, DuckDuckGo’s browser extension and Mozilla’s Firefox browser both block Google Analytics from loading.
Search Console data is not blocked, so this is another way that more or different data might collect in Search Console and deviate from what’s collected in Google Analytics.
Time Delay Discrepancies
Another reason why traffic data reporting is different between Search Console and Google Analytics is because Search Console data is delayed by several days, whereas Analytics can report the data within seconds.
The delay in Search Console reporting could cause the data to be incomplete at the time of viewing.
Search Console Omits Certain Queries
Search Console protects the privacy of users, and because of that, the Search Console Performance report will omit data from certain kinds of queries.
A Google search console help page explains:
“To protect user privacy, the Performance report doesn’t show all data.
For example, we might not track some queries that are made a very small number of times or those that contain personal or sensitive information.
Some processing of our source data might cause these stats to differ from stats listed in other sources (for example, to eliminate duplicates).
However, these changes should not be significant.”
Anonymized Queries Totals In Performance Report
The data in the Performance report won’t match the organic traffic data in Analytics for previously mentioned reasons, and anonymized queries is another reason why Search Console performance data is further distanced from data reported in Analytics.
Google Search Console omits what it calls very rare search queries for privacy reasons.
Anonymized queries are included in totals but not included when filtered in the Performance report.
Google’s Search Console support page states:
“Very rare queries (called anonymized queries) are not shown in these results to protect the privacy of the user making the query.
Anonymized queries are always omitted from the table. Anonymized queries are included in chart totals unless you filter by query (either queries containing or queries not containing a given string).
If your site has a significant number of anonymized queries, you may see a significant discrepancy between the total versus (count of queries containing some_string + count of queries not containing some_string).
This is because the anonymized queries are omitted whenever a filter is applied.”
Time Zone Differences
Google Analytics reports day and month level data according to the publisher’s time zone.
The publisher’s time zone is set in the Analytics view settings where the preferred time zone can be set for the website.
Google Search Console reports data according to Pacific Daylight Time (PDT), which is the California time zone, regardless of what country or time zone a website is set for.
What this creates is a situation where Search Console is assigning data to one time zone, and Google Analytics is assigning data to a different time zone (when the site time zone is outside of California).
This is going to make a big difference in how the data is reported because it virtually guarantees that daily and monthly traffic data will never match between Search Console and Analytics.
According to the Google Analytics page for editing view settings:
“Time zone country or territory: The country or territory and the time zone you want to use as the day boundary for your reports, regardless of where the data originates.
For example, if you choose United States, Los Angeles Time, then the beginning and end of each day is calculated based on Los Angeles Time, even if the hit comes from New York, London, or Moscow.
If you choose a time zone that honors Daylight Savings Time, Analytics automatically adjusts for the changes.
If you do not want Analytics to adjust for Daylight Savings time, then you can use Greenwich Mean Time instead of your local time zone.”
Landing Page URL Differences
Landing pages in Search Console are aggregated to a certain extent while landing page URLs are not aggregated in Analytics.
Google’s support page explains it like this:
“Landing Page dimension: Search Console aggregates its data under canonical URLs (learn more), whereas Analytics uses the actual landing page URL.
This distinction will impact reports that include the landing page dimension including Landing Pages and Devices/Countries (when Landing Page is added as a secondary dimension).
For example, Impressions and Click metrics for web, mobile web, and AMP URLs could be aggregated… under a canonical URL…”
Search Console Data Is Limited
Another important difference between data reporting between Search Console and Google Analytics is that Search Console is limited to reporting data for up to 1,000 URLs for landing pages.
Google Analytics does not have that limitation and can report on more landing pages than 1,000 URLs.
A Google Analytics support page explains the differences:
“Number of URLs recorded per site per day:
Search Console records up to 1,000 URLs for landing pages.
Analytics does not observe the 1,000-URL limit, and can include more landing pages.”
Data Differences In Search Console and Analytics
There are data discrepancies between what Search Console and Analytics measure and report.
The reasons for the differences range from what time zone traffic events are attributed to how landing pages are aggregated.
The fact that there are differences between the reported numbers in Search Console and Analytics is not a sign that there is a problem with the data.
These are two different products that report data in different ways and that’s all it is.
More Resources:
- Google Search Console: A Complete Guide for SEOs
- Get to Know Google Analytics 4: A Complete Guide
- A Guide to Essential SEO Tools for Agencies
Featured Image: StockStyle/Shutterstock
