

When used creatively, XPaths can help improve the efficiency of auditing large websites. Consider this another tool in your SEO toolbelt.
There are endless types of information you can unlock with XPaths, which can be used in any category of online business.
Some popular ways to audit large sites with XPaths include:
In this guide, we’ll cover exactly how to perform these audits in detail.
What Are XPaths?
Simply put, XPath is a syntax that uses path expressions to navigate XML documents and identify specified elements.
This is used to find the exact location of any element on a page using the HTML DOM structure.
We can use XPaths to help extract bits of information such as H1 page titles, product descriptions on ecommerce sites, or really anything that’s available on a page.
While this may sound complex to many people, in practice, it’s actually quite easy!
How to Use XPaths in Screaming Frog
In this guide, we’ll be using Screaming Frog to scrape webpages.
Screaming Frog offers custom extraction methods, such as CSS selectors and XPaths.
It’s entirely possible to use other means to scrape webpages, such as Python. However, the Screaming Frog method requires far less coding knowledge.
(Note: I’m not in any way currently affiliated with Screaming Frog, but I highly recommend their software for web scraping.)
Step 1: Identify Your Data Point
Figure out what data point you want to extract.
For example, let’s pretend Search Engine Journal didn’t have author pages and you wanted to extract the author name for each article.
What you’ll do is:
- Right-click on the author name.
- Select Inspect.
- In the dev tools elements panel, you will see your element already highlighted.
- Right-click the highlighted HTML element and go to Copy and select Copy XPath.
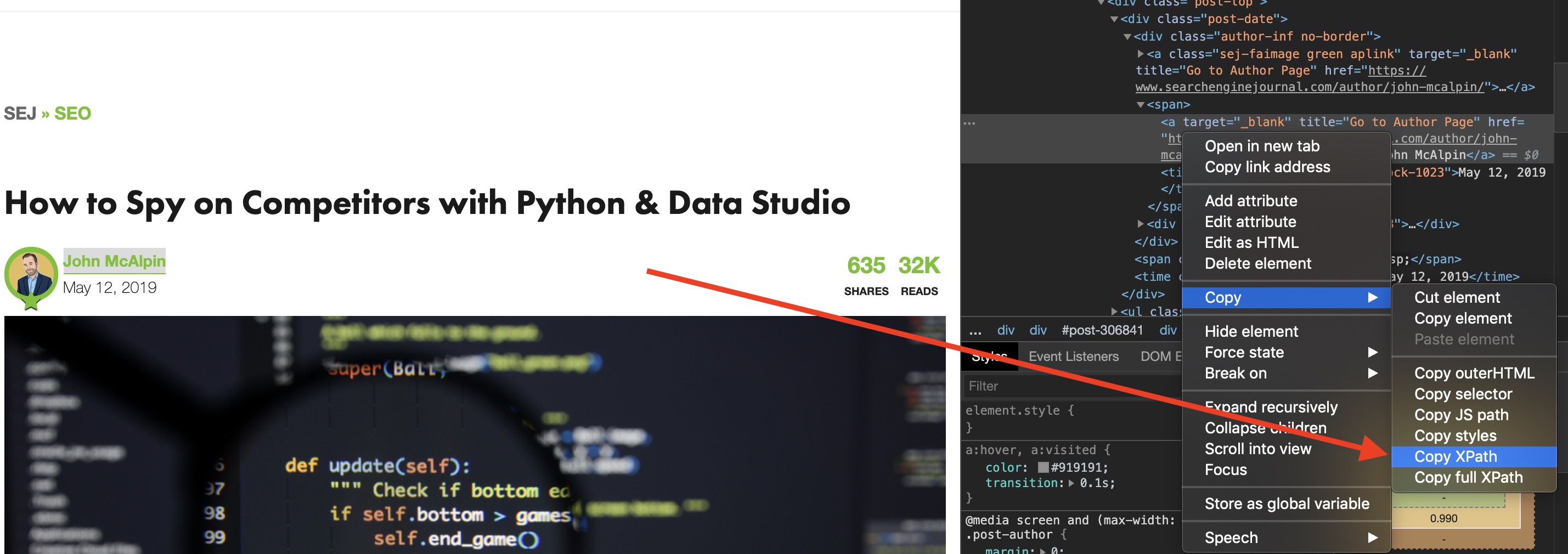
At this point, your computer’s clipboard will have the desired XPath copied.
Step 2: Set up Custom Extraction
In this step, you will need to open Screaming Frog and set up the website you want to crawl. In this instance, I would enter the full Search Engine Journal URL.
- Go to Configuration > Custom > Extraction
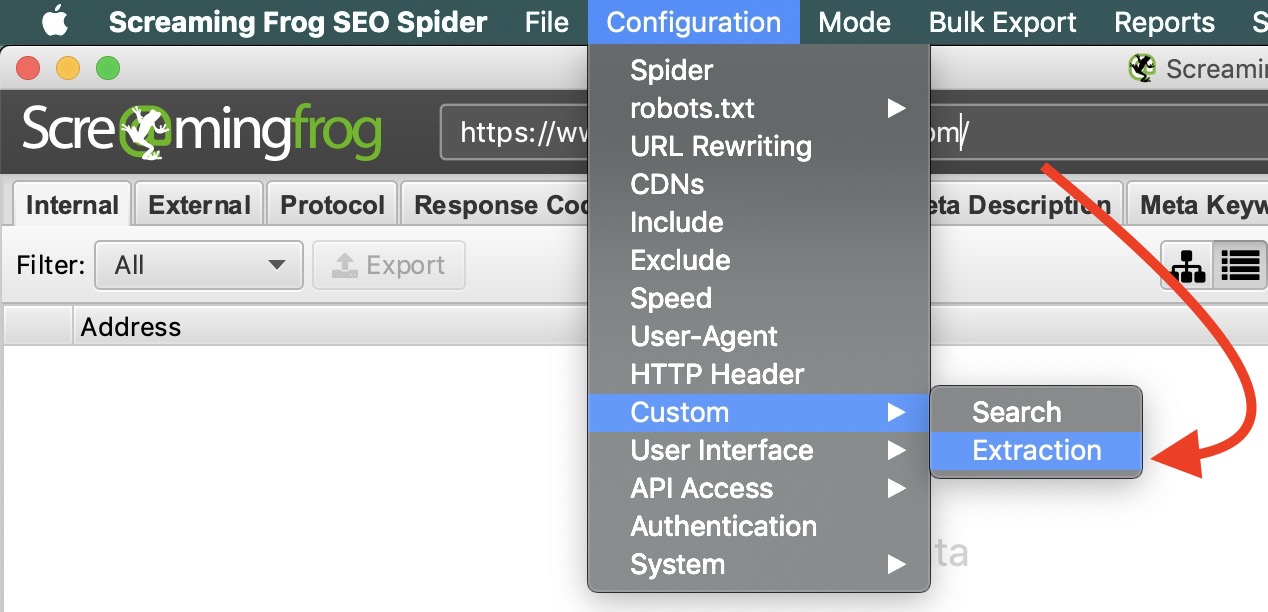
- This will bring up the Custom Extraction configuration window. There are a lot of options here, but if you’re looking to simply extract text, match your configuration to the screenshot below.

Step 3: Run Crawl & Export
At this point, you should be all set to run your crawl. You’ll notice that your custom extraction is the second to last column on the right.
When analyzing crawls in bulk, it makes sense to export your crawl into an Excel format. This will allow you to apply a variety of filters, pivot tables, charts, and anything your heart desires.
3 Creative Ways XPaths Help Scale Your Audits
Now that we know how to run an XPath crawl, the possibilities are endless!
We have access to all of the answers, now we just need to find the right questions.
- What are some aspects of your audit that could be automated?
- Are there common elements in your content silos that can be extracted for auditing?
- What are the most important elements on your pages?
The exact problems you’re trying to solve may vary by industry or site type. Below are some unique situations where XPaths can make your SEO life easier.
1. Using XPaths with Redirect Maps
Recently, I had to redesign a site that required a new URL structure. The former pages all had parameters as the URL slug instead of the page name.
This made creating a redirect map for hundreds of pages a complete nightmare!
So I thought to myself, “How can I easily identify each page at scale?”
After analyzing the various page templates, I came to the conclusion that the actual title of the page looked like an H1 but was actually just large paragraph text. This meant that I couldn’t just get the standard H1 data from Screaming Frog.
However, XPaths would allow me to copy the exact location for each page title and extract it in my web scraping report.
In this case I was able to extract the page title for all of the old URLs and match them with the new URLs through the VLOOKUP function in Excel. This automated most of the redirect map work for me.
With any automated work, you may have to perform some spot checking for accuracy.
2. Auditing Ecommerce Sites with XPaths
Auditing Ecommerce sites can be one of the more challenging types of SEO auditing. There are many more factors to consider, such as JavaScript rendering and other dynamic elements.
Sometimes, stakeholders will need product level audits on an ad hoc basis. Sometimes this covers just categories of products, but sometimes it may be the entire site.
Using the XPath extraction method we learned earlier in this article, we can extract all types of data including:
- Product name
- Product description
- Price
- Review data
- Image URLs
- Product Category
- And much more
This can help identify products that may be lacking valuable information within your ecommerce site.
The cool thing about Screaming Frog is that you can extract multiple data points to stretch your audits even further.
3. Auditing Blogs with XPaths
This is a more common method for using XPaths. Screaming Frog allows you to set parameters to crawl specific subfolders of sites, such as blogs.
However, using XPaths, we can go beyond simple meta data and grab valuable insights to help identify content gap opportunities.
Categories & Tags
One of the most common ways SEO professionals use XPaths for blog auditing is scraping categories and tags.
This is important because it helps us group related blogs together, which can help us identify content cannibalization and gaps.
This is typically the first step in any blog audit.
Keywords
This step is a bit more Excel-focused and advanced. How this works, is you set up an XPath extraction to pull the body copy out of each blog.
Fair warning, this may drastically increase your crawl time.
Whenever you export this crawl into Excel, you will get all of the body text in one cell. I highly recommend that you disable text wrapping, or your spreadsheet will look terrifying.
Next, in the column to the right of your extracted body copy, enter the following formula:
=ISNUMBER(SEARCH("keyword",A1))
In this formula, A1 equals the cell of the body copy.
To scale your efforts, you can have your “keyword” equal the cell that contains your category or tag. However, you may consider adding multiple columns of keywords to get a more accurate and robust picture of your blogging performance.
This formula will present a TRUE/FALSE Boolean value. You can use this to quickly identify keyword opportunities and cannibalization in your blogs.
Author
We’ve already covered this example, but it’s worth noting that this is still an important element to pull from your articles.
When you blend your blog export data with performance data from Google Analytics and Search Console, you can start to determine which authors generate the best performance.
To do this, sort your blogs by author and start tracking average data sets including:
- Impressions – Search Console
- Clicks – Search Console
- Sessions – Analytics
- Bounce Rate – Analytics
- Conversions – Analytics
- Assisted Conversions – Analytics
Share Your Creative XPath Tips
Do you have some creative auditing methods that involve XPaths? Share this article on Twitter or tag me @seocounseling and let me know what I missed!
More Resources:
- The Ultimate SEO Audit Checklist
- Free SEO Site Audit Tools
- 6 Actions You Must Take After an SEO Audit
Image Credits
All screenshots taken by author, October 2019
