

I’m not going to lie: Conducting an in-depth SEO audit is a major deal.
And, as an SEO consultant, there are a few sweeter words than, “Your audit looks great! When can we bring you onboard?”
Even if you haven’t been actively looking for a new gig, knowing your SEO audit nailed it is a huge ego boost.
But, are you terrified to start? Is this your first SEO audit? Or, maybe you just don’t know where to begin?
Sending a fantastic SEO audit to a potential client puts you in the best possible place.
So take your time. Remember: Your primary goal is to add value to your customer with your site recommendations for both the short-term and the long-term.
In this column, I’ve put together the need-to-know steps for conducting an SEO audit and a little insight into the first phase of my processes when I first get a new client. It’s broken down into sections below. If you feel like you have a good grasp on a particular section, feel free to jump to the next.
When Should I Perform an SEO Audit?
After a potential client sends me an email expressing interest in working together and they answer my survey, we set-up an intro call (Skype or Google Hangouts is preferred).
Before the call, I do my own mini quick SEO audit (I invest at least one hour to manually researching) based on their survey answers to become familiar with their market landscape. It’s like dating someone you’ve never met.
You’re obviously going to stalk them on Facebook, Twitter, Instagram, and all other channels that are public #soIcreep.
Here’s an example of what my survey looks like:
Here are some key questions you’ll want to ask the client during the first meeting:
- What are your overall business goals? What are your channel goals (PR, social, etc.)?
- Who is your target audience?
- Do you have any business partnerships?
- How often is the website updated? Do you have a web developer or an IT department?
- Have you ever worked with an SEO consultant before? Or, had any SEO work done previously?
Sujan Patel also has some great recommendations on questions to ask a new SEO client.
After the call, if I feel we’re a good match, I’ll send over my formal proposal and contract (thank you HelloSign for making this an easy process for me!).
To begin, I always like to offer my clients the first month as a trial period to make sure we vibe.
This gives both the client and I a chance to become friends first before dating. During this month, I’ll take my time to conduct an in-depth SEO audit.
These SEO audits can take me anywhere from 40 hours to 60 hours depending on the size of the website. These audits are bucketed into three separate parts and presented with Google Slides.
- Technical: Crawl errors, indexing, hosting, etc.
- Content: Keyword research, competitor analysis, content maps, meta data, etc.
- Links: Backlink profile analysis, growth tactics, etc.
After that first month, if the client likes my work, we’ll begin implementing the recommendations from the SEO audit. And going forward, I’ll perform a mini-audit monthly and an in-depth audit quarterly.
To recap, I perform an SEO audit for my clients:
- First month.
- Monthly (mini-audit).
- Quarterly (in-depth audit).
What You Need from a Client Before an SEO Audit
When a client and I start working together, I’ll share a Google Doc with them requesting a list of passwords and vendors.
This includes:
- Google Analytics access and any third-party analytics tools.
- Google and Bing ads.
- Webmaster tools.
- Website backend access.
- Social media accounts.
- List of vendors.
- List of internal team members (including any work they outsource).
Tools for SEO Audit
Before you begin your SEO audit, here’s a recap of the tools I use:
- Screaming Frog.
- Integrity (for Mac users) and Xenu Sleuth (for PC users).
- SEO Browser.
- Wayback Machine.
- Moz.
- BuzzSumo.
- DeepCrawl.
- Copyscape.
- Google Tag Manager.
- Google Tag Manager Chrome Extension.
- Annie Cushing’s Campaign Tagging Guide.
- Google Analytics (if given access).
- Google Search Console (if given access).
- Bing Webmaster Tools (if given access).
- You Get Signal.
- Pingdom.
- PageSpeed Tool.
- Sublime Text.
Conducting a Technical SEO Audit
Tools needed for technical SEO audit:
- Screaming Frog.
- DeepCrawl.
- Copyscape.
- Integrity for Mac (or Xenu Sleuth for PC users).
- Google Analytics (if given access).
- Google Search Console (if given access).
- Bing Webmaster Tools (if given access).
Step 1: Add Site to DeepCrawl and Screaming Frog
Tools:
- DeepCrawl.
- Copyscape.
- Screaming Frog.
- Google Analytics.
- Integrity.
- Google Tag Manager.
- Google Analytics code.
What to Look for When Using DeepCrawl
The first thing I do is add my client’s site to DeepCrawl. Depending on the size of your client’s site, the crawl may take a day or two to get the results back.
Once you get your DeepCrawl results back, here are the things I look for:
Duplicate Content
Check out the “Duplicate Pages” report to locate duplicate content.
If duplicate content is identified, I’ll make this a top priority in my recommendations to the client to rewrite these pages, and in the meantime, I’ll add the <meta name=”robots” content=”noindex, nofollow”> tag to the duplicate pages.
Common duplicate content errors you’ll discover:
- Duplicate meta titles and meta descriptions.
- Duplicate body content from tag pages (I’ll use Copyscape to help determine if something is being plagiarized).
- Two domains (ex: yourwebsite.co, yourwebsite.com).
- Subdomains (ex: jobs.yourwebsite.com).
- Similar content on a different domain.
- Improperly implemented pagination pages (see below.)
How to fix:
- Add the canonical tag on your pages to let Google know what you want your preferred URL to be.
- Disallow incorrect URLs in the robots.txt.
- Rewrite content (including body copy and metadata).
Here’s an example of a duplicate content issue I had with a client of mine. As you can see below, they had URL parameters without the canonical tag.
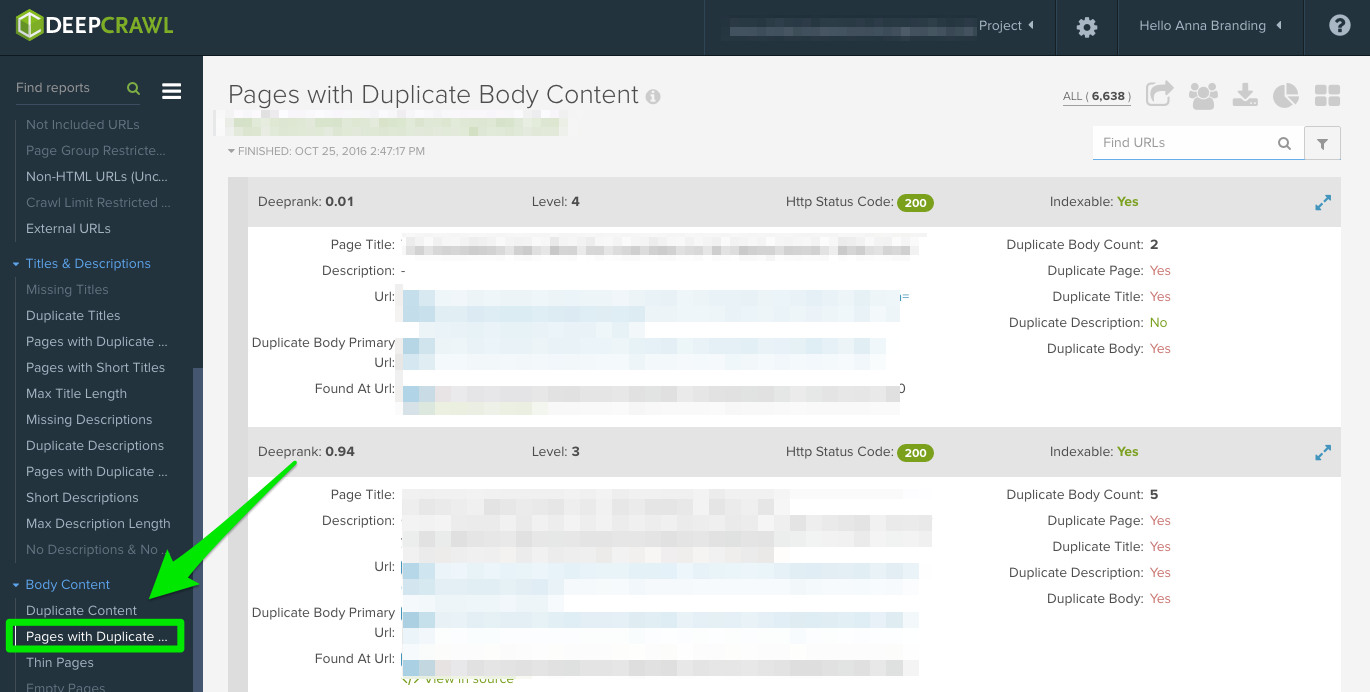
These are the steps I took to fix the issue:
- I fixed any 301 redirect issues.
- Added a canonical tag to the page I want Google to crawl.
- Update the Google Search Console parameter settings to exclude any parameters that don’t generate unique content.
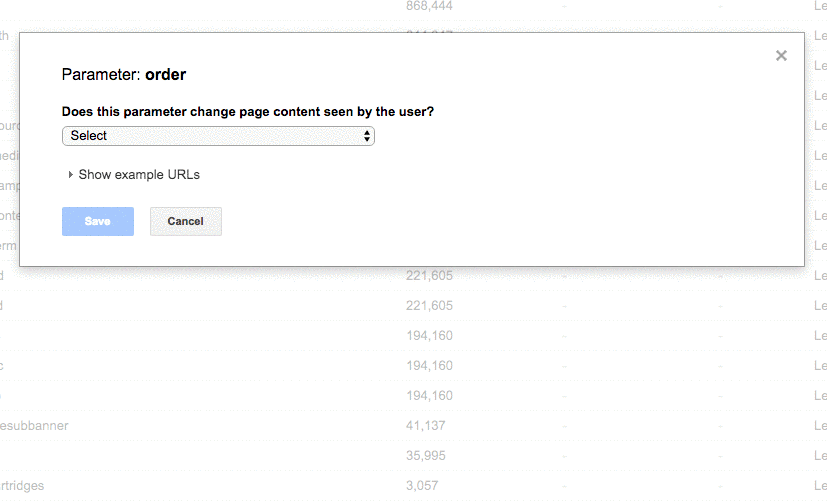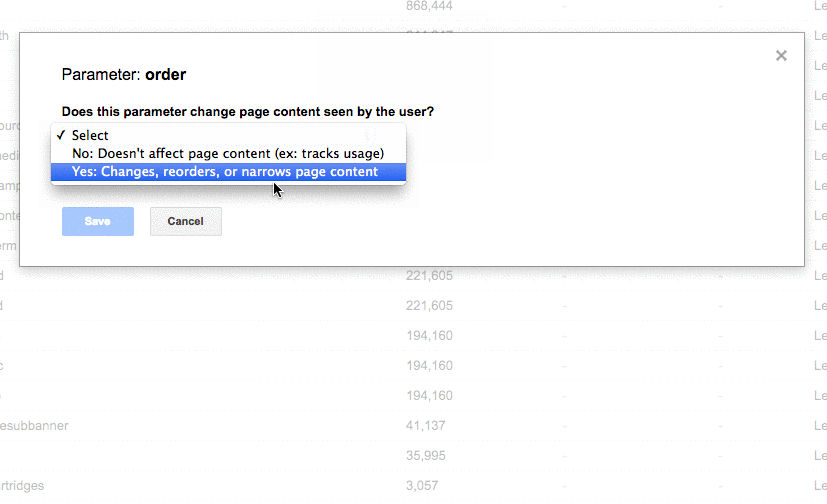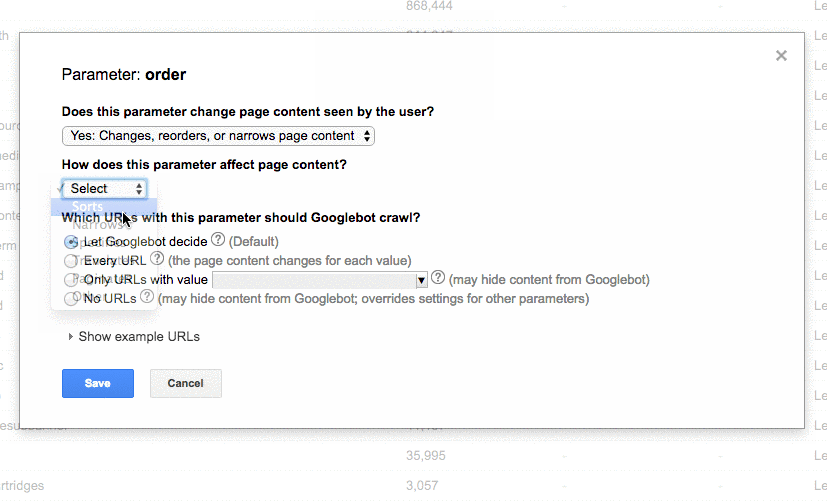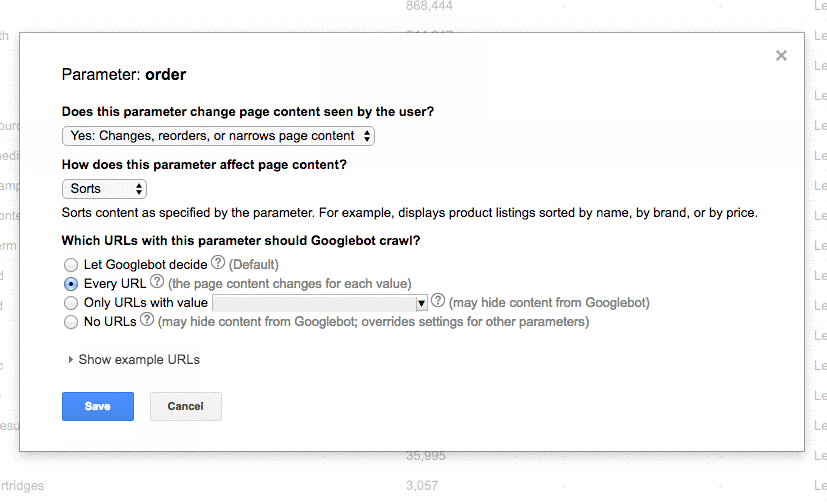
- Added the disallow function to the robots.txt to the incorrect URLs to improve crawl budget.
Pagination
There are two reports to check out:
- First Pages: To find out what pages are using pagination, review the “First Pages” report. Then, you can manually review the pages using this on the site to discover if pagination is implemented correctly.
- Unlinked Pagination Pages: To find out if pagination is working correctly, the “Unlinked Pagination Pages” report will tell you if the rel=”next” and rel=”prev” are linking to the previous and next pages.
In this example below, I was able to find that a client had reciprocal pagination tags using DeepCrawl:
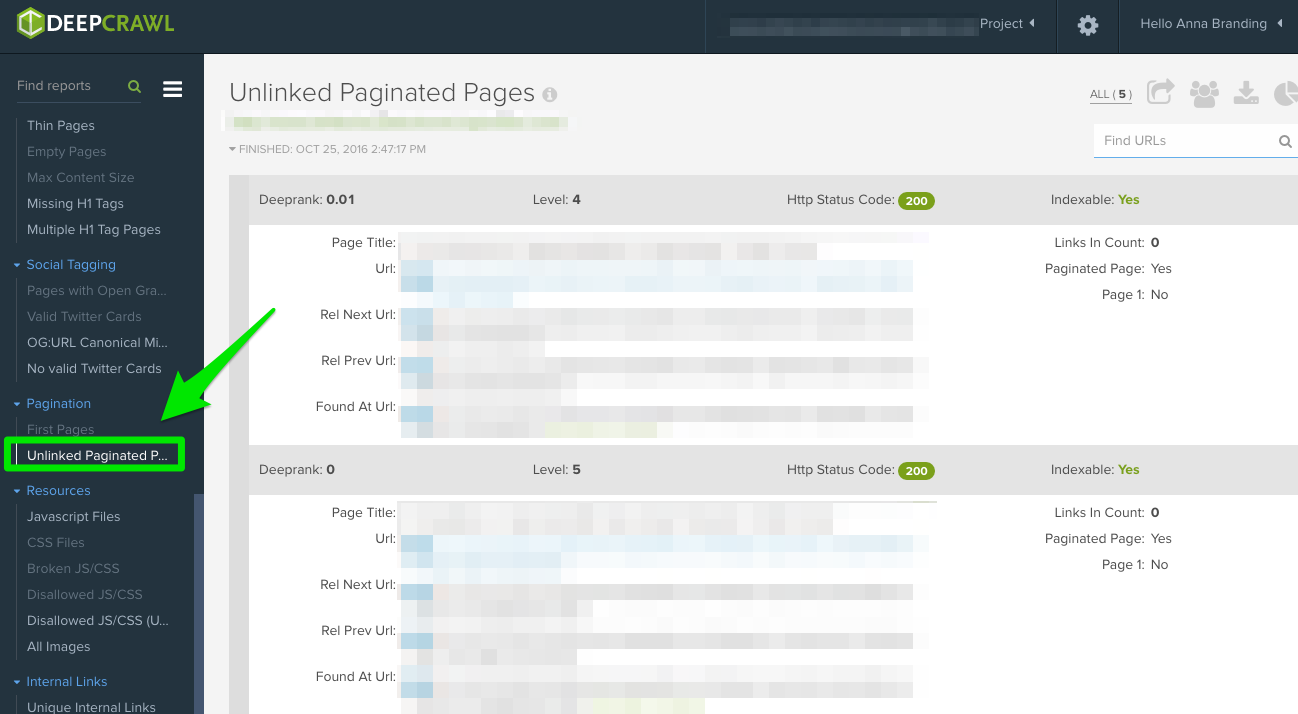
How to fix:
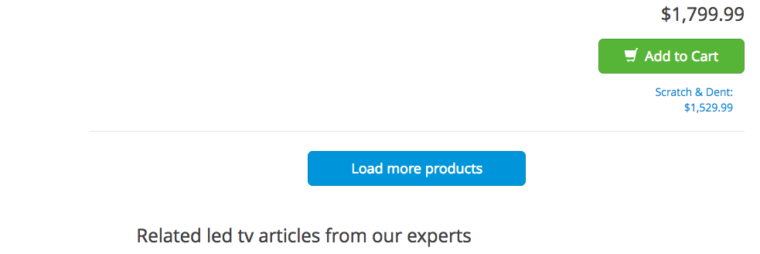
- If you have a “view all” or a “load more” page, add rel=”canonical” tag. Here’s an example from Crutchfield:
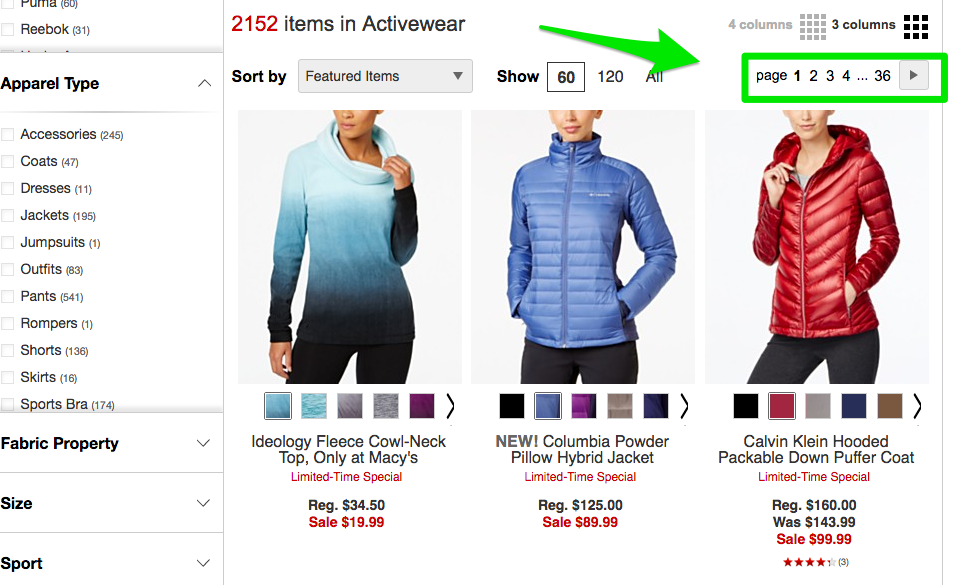
- If you have all your pages on separate pages, then add the standard rel=”next” and rel=”prev” markup. Here’s an example from Macy’s:
- If you’re using infinite scrolling, add the equivalent paginated page URL in your javascript. Here’s an example from American Eagle.
Max Redirections
Review the “Max Redirections” report to see all the pages that redirect more than 4 times. John Mueller mentioned in 2015 that Google can stop following redirects if there are more than five.
While some people refer to these crawl errors as eating up the “crawl budget,” Gary Illyes refers to this as “host load.” It’s important to make sure your pages render properly because you want your host load to be used efficiently.
Here’s a brief overview of the response codes you might see:
- 301 – These are the majority of the codes you’ll see throughout your research. 301 redirects are okay as long as there are only one redirect and no redirect loop.
- 302 – These codes are okay, but if left longer than 3 months or so, I would manually change them to 301s so that they are permanent. This is an error code I’ll see often with ecommerce sites when a product is out of stock.
- 400 – Users can’t get to the page.
- 403 – Users are unauthorized to access the page.
- 404 – The page is not found (usually meaning the client deleted a page without a 301 redirect).
- 500 – Internal server error that you’ll need to connect with the web development team to determine the cause.
How to fix:
- Remove any internal links pointing to old 404 pages and update them with the redirected page internal link.
- Undo the redirect chains by removing the middle redirects. For example, if redirect A goes to redirect B, C, and D, then you’ll want to undo redirects B and C. The final result will be a redirect A to D.
- There is also a way to do this in Screaming Frog and Google Search Console below if you’re using that version.
What to Look for When Using Screaming Frog
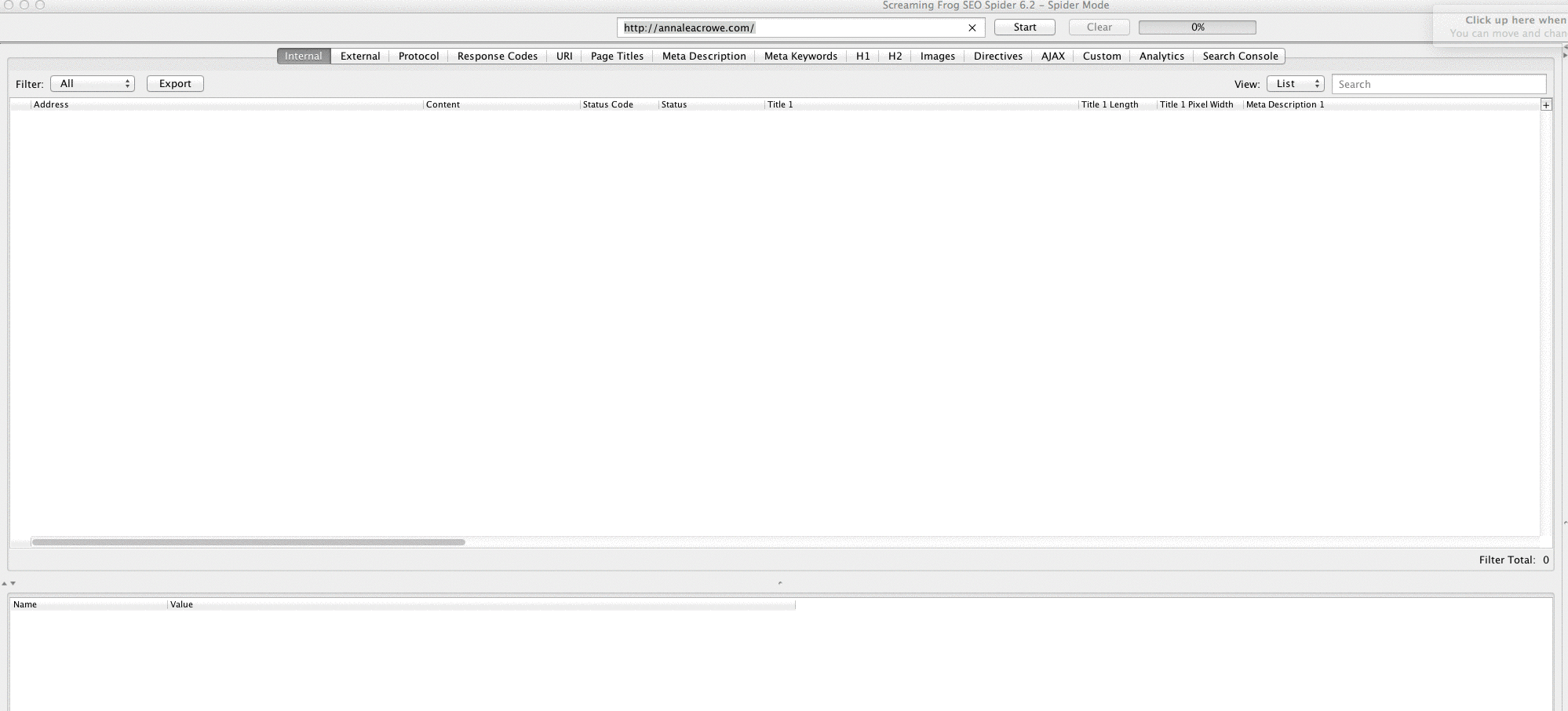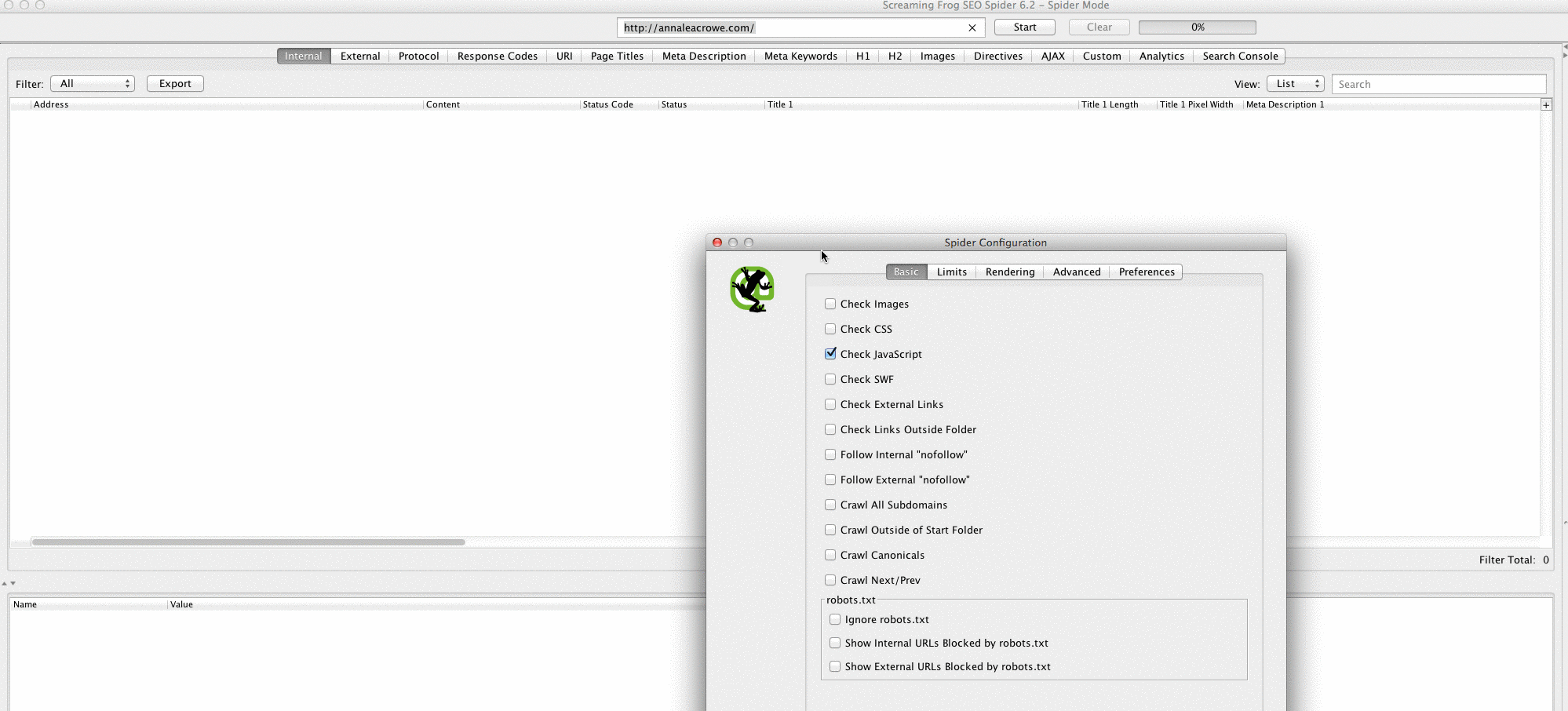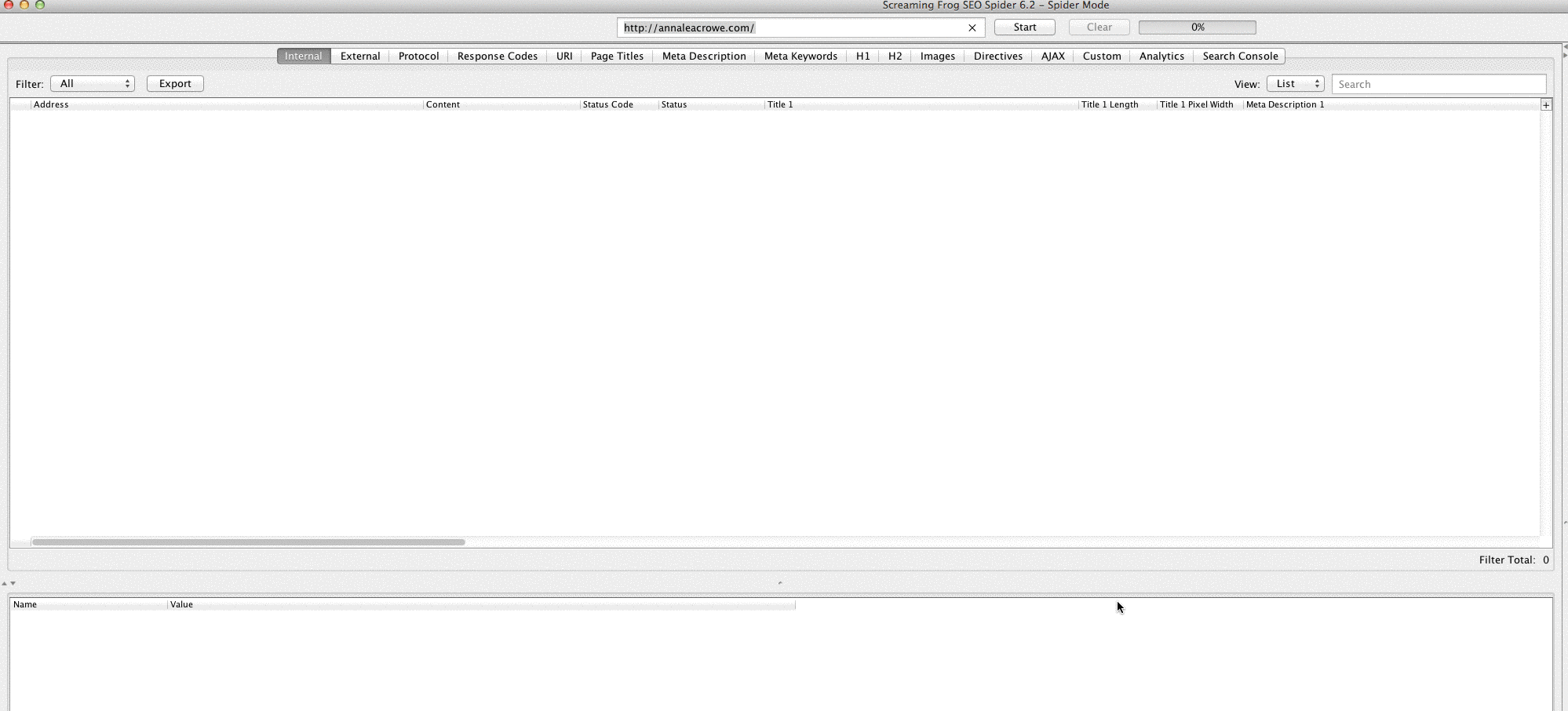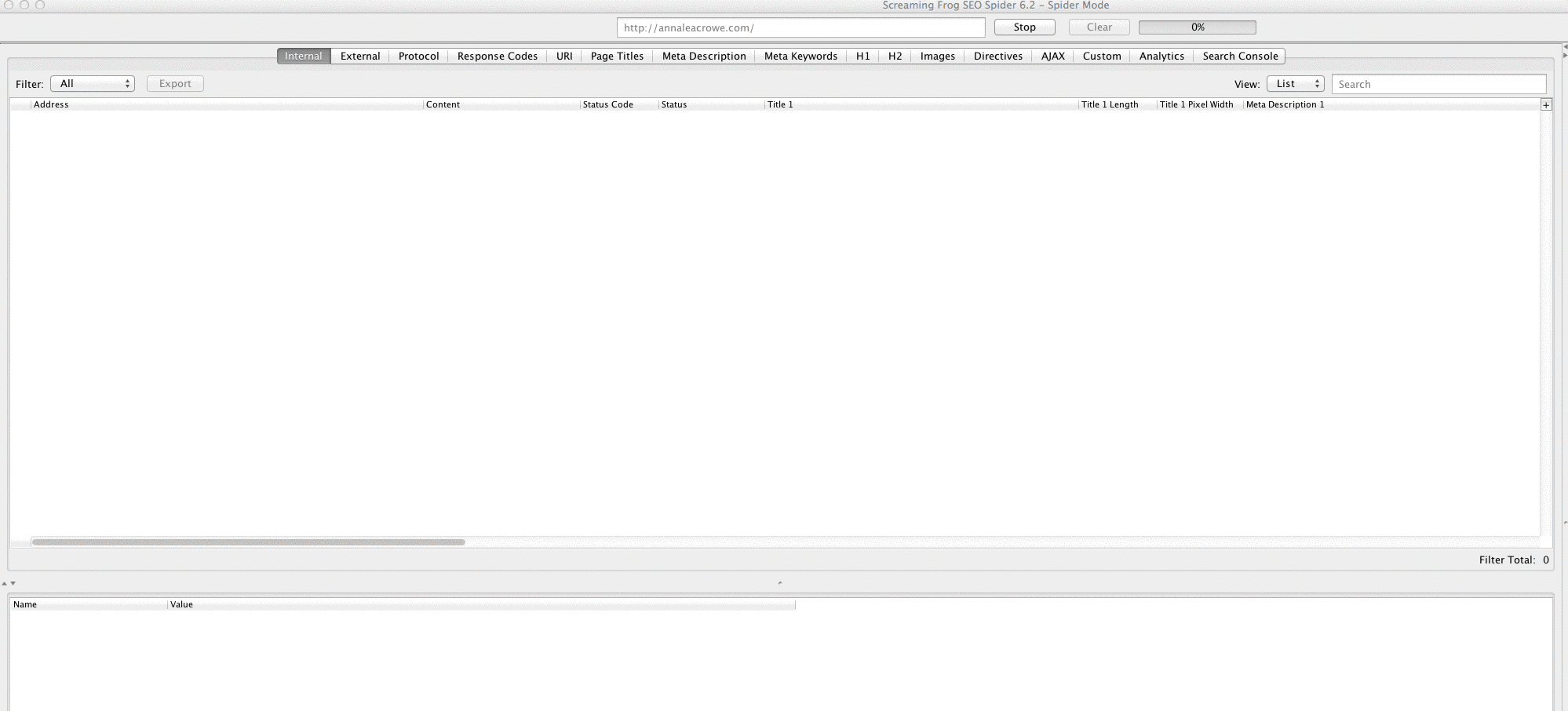
The second thing I do when I get a new client site is to add their URL to Screaming Frog.
Depending on the size of your client’s site, I may configure the settings to crawl specific areas of the site at a time.
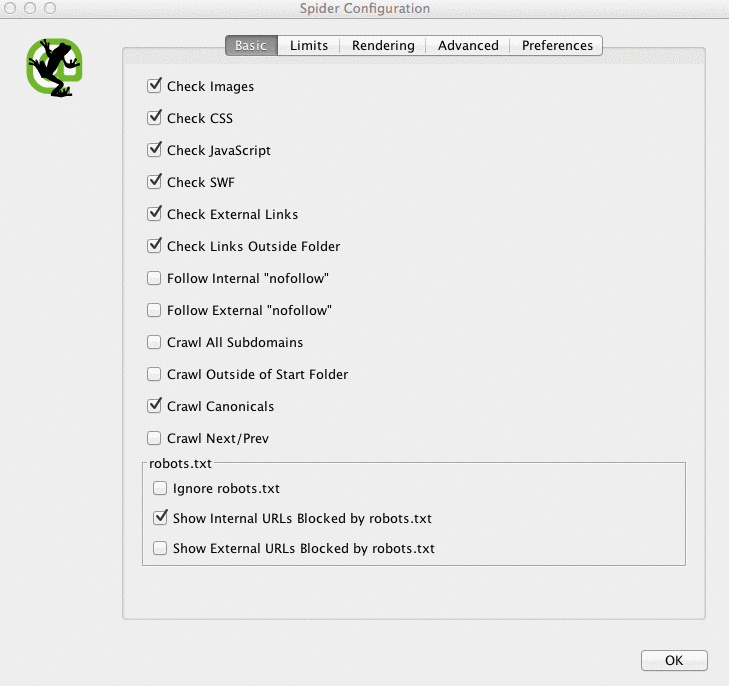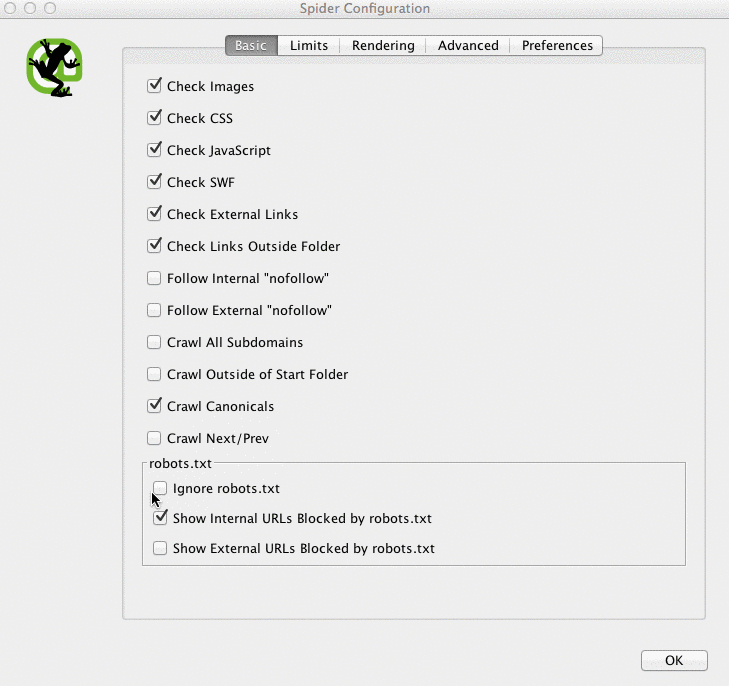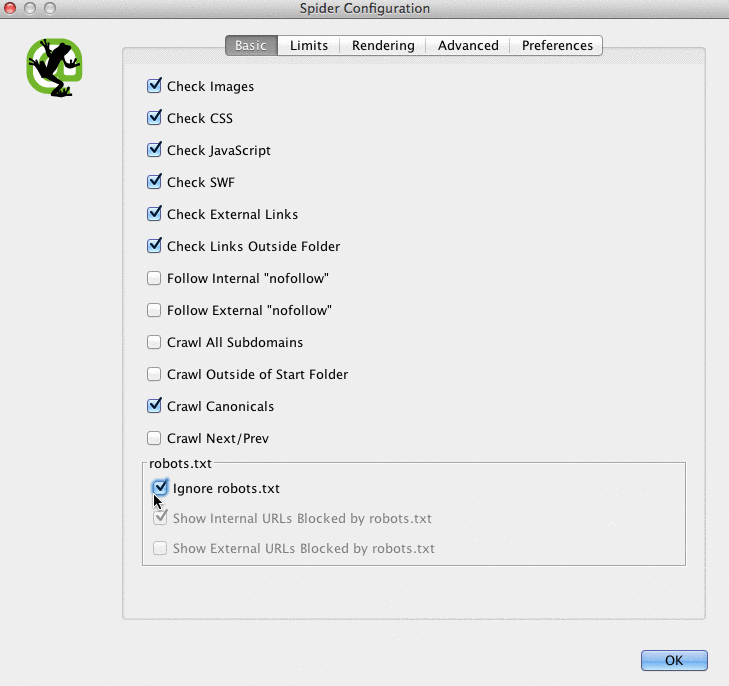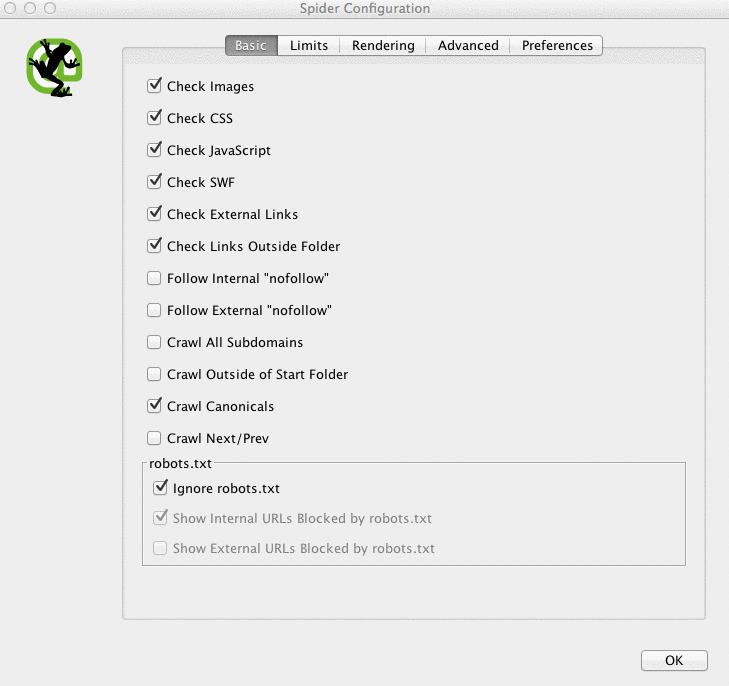
Here is what my Screaming Frog spider configurations look like:
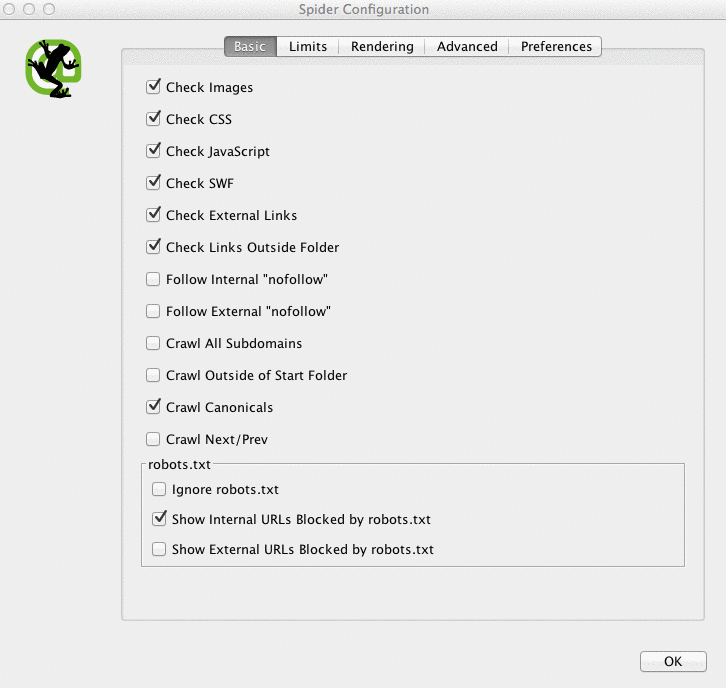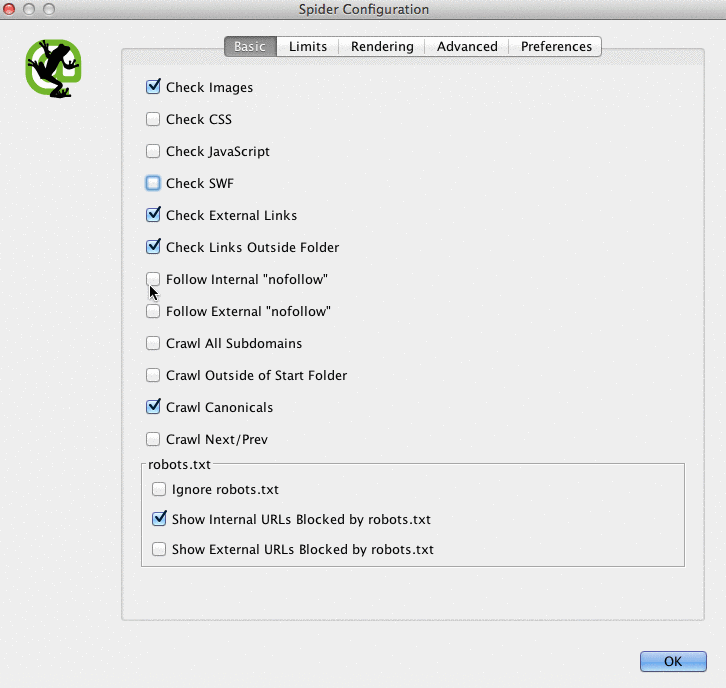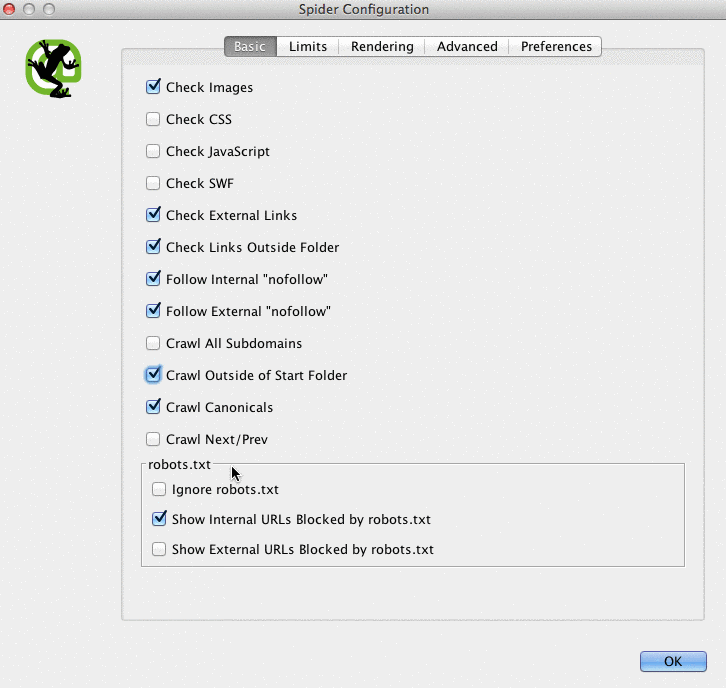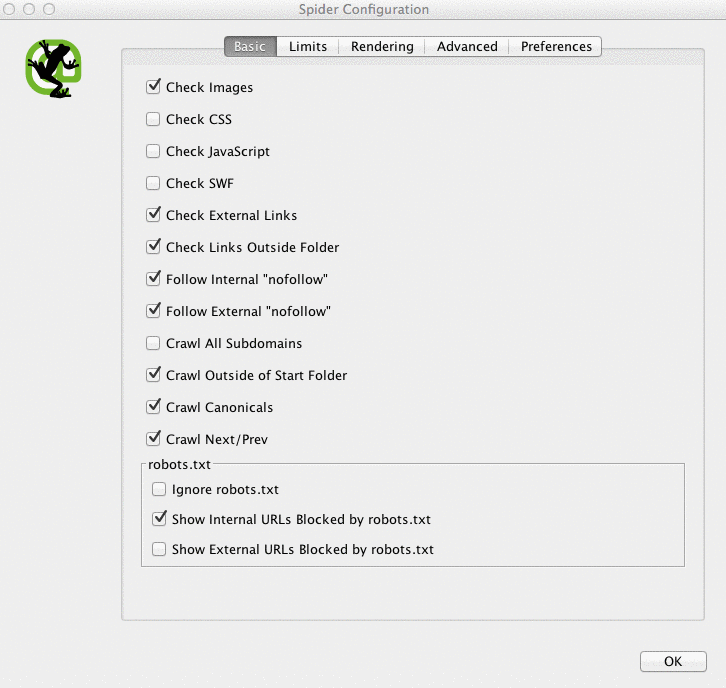
You can do this in your spider settings or by excluding areas of the site.
Once you get your Screaming Frog results back, here are the things I look for:
Google Analytics Code
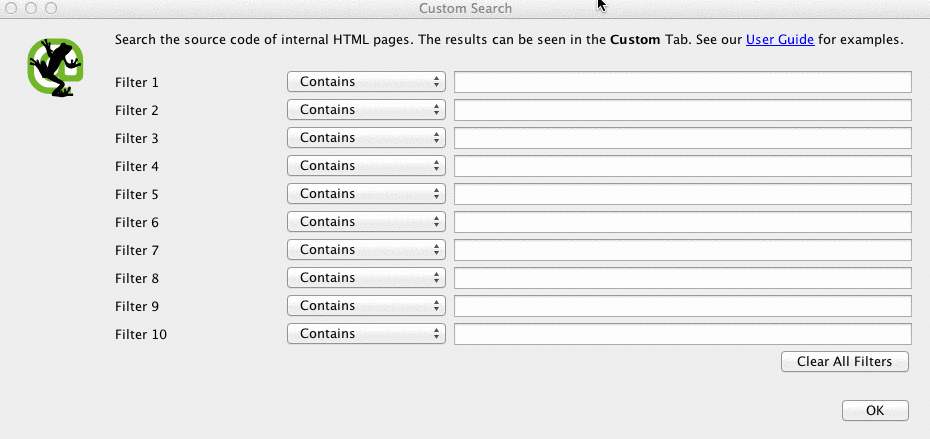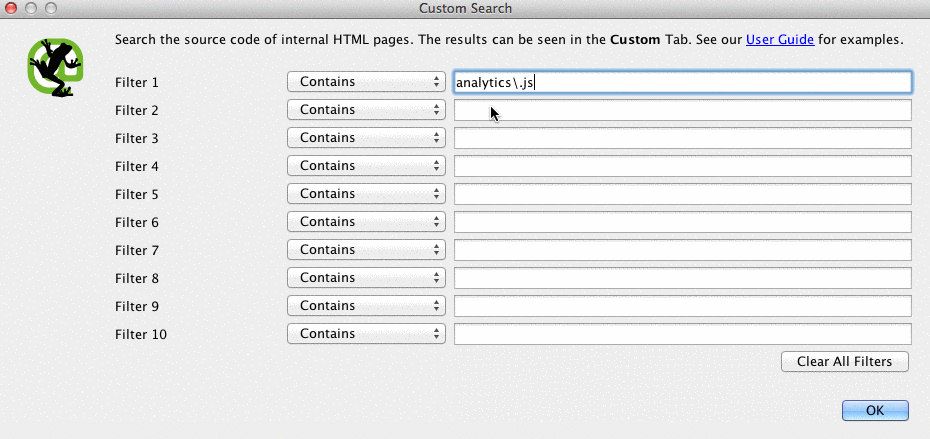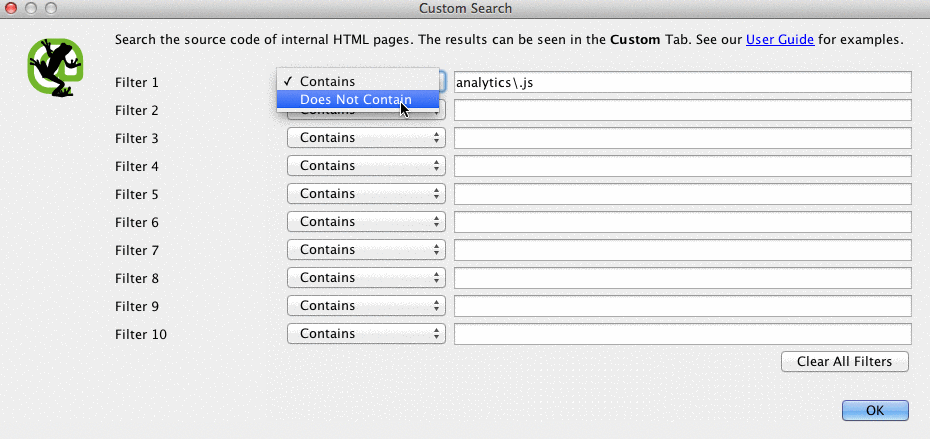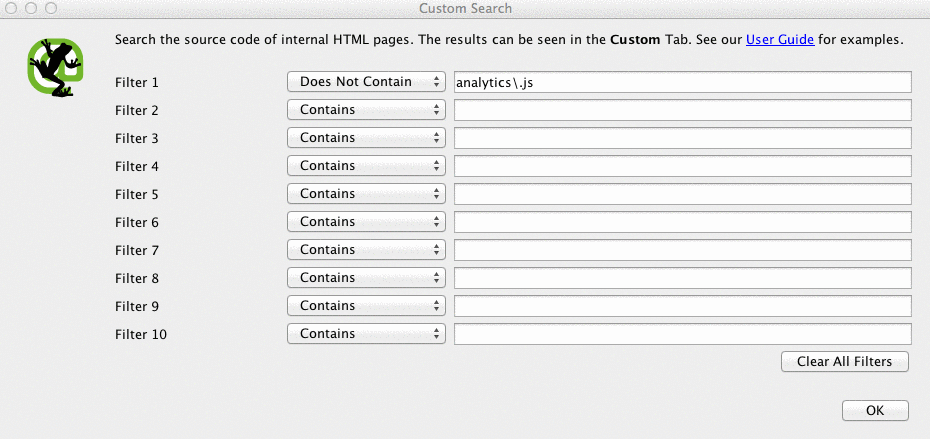
Screaming Frog can help you identify what pages are missing the Google Analytics code (UA-1234568-9). To find the missing Google Analytics code, follow these steps:
- Go to Configuration in the navigation bar, then Custom.
- Add analytics\.js to Filter 1, then change the drop-down to Does not contain.
How to fix:
- Contact your client’s developers and ask them to add the code to the specific pages that it’s missing.
- For more Google Analytics information, skip ahead to that Google Analytics section below.
Google Tag Manager
Screaming Frog can also help you find out what pages are missing the Google Tag Manager snippet with similar steps:
- Go to the Configuration tab in the navigation bar, then Custom.
- Add <iframe src-“//www.googletagmanager.com/ with Does not contain selected in the Filter.
How to fix:
- Head over to Google Tag Manager to see if there are any errors and update where needed.
- Share the code with your client’s developer’s to see if they can add it back to the site.
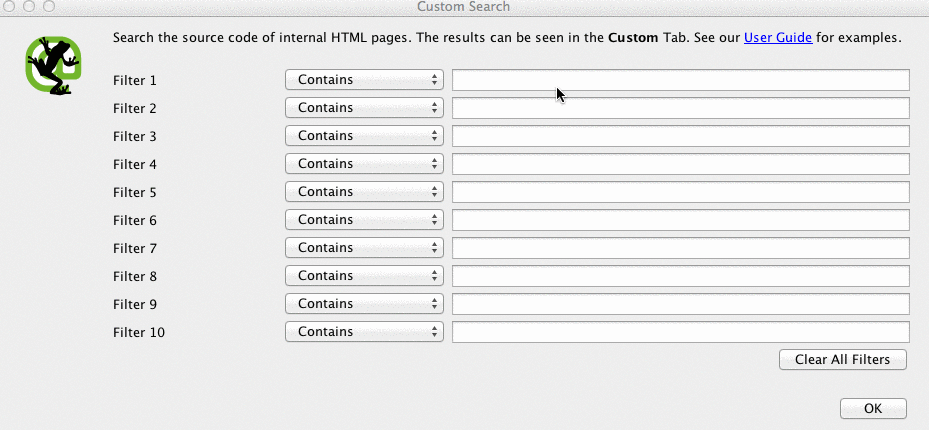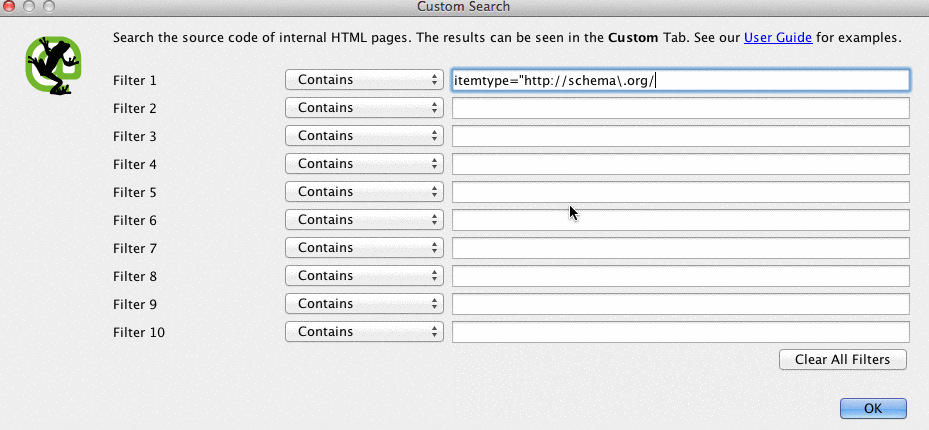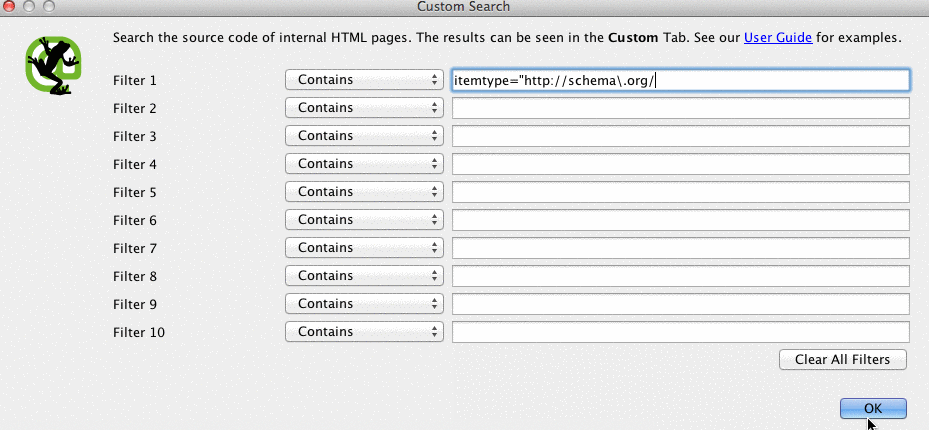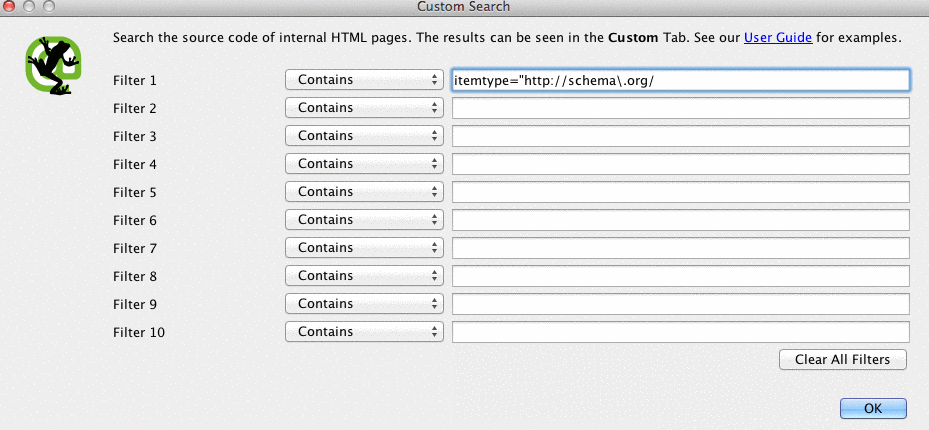
Schema
You’ll also want to check if your client’s site is using schema markup on their site. Schema or structured data helps search engines understand what a page is on the site.
To check for schema markup in Screaming Frog, follow these steps:
- Go to the Configuration tab in the navigation bar, then Custom.
- Add itemtype=”http://schema.\.org/ with ‘Contain’ selected in the Filter.
 Indexing
Indexing
You want to determine how many pages are being indexed for your client, follow this in Screaming Frog:
- After your site is done loading in Screaming Frog, go to Directives > Filter > Index to review if there are any missing pieces of code.
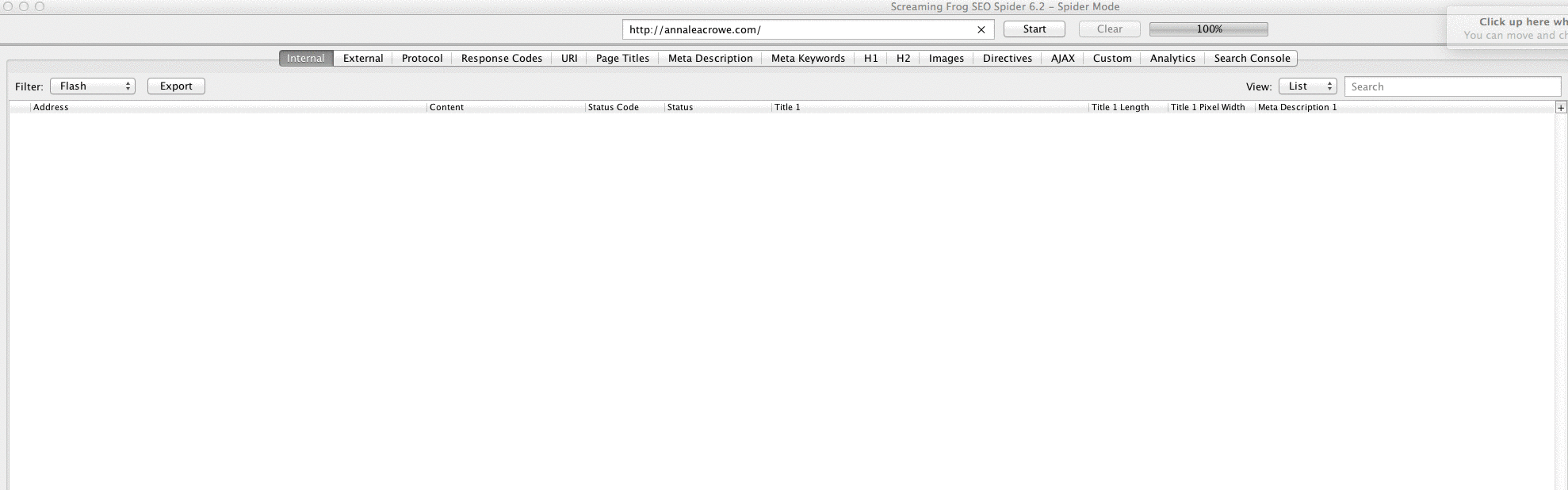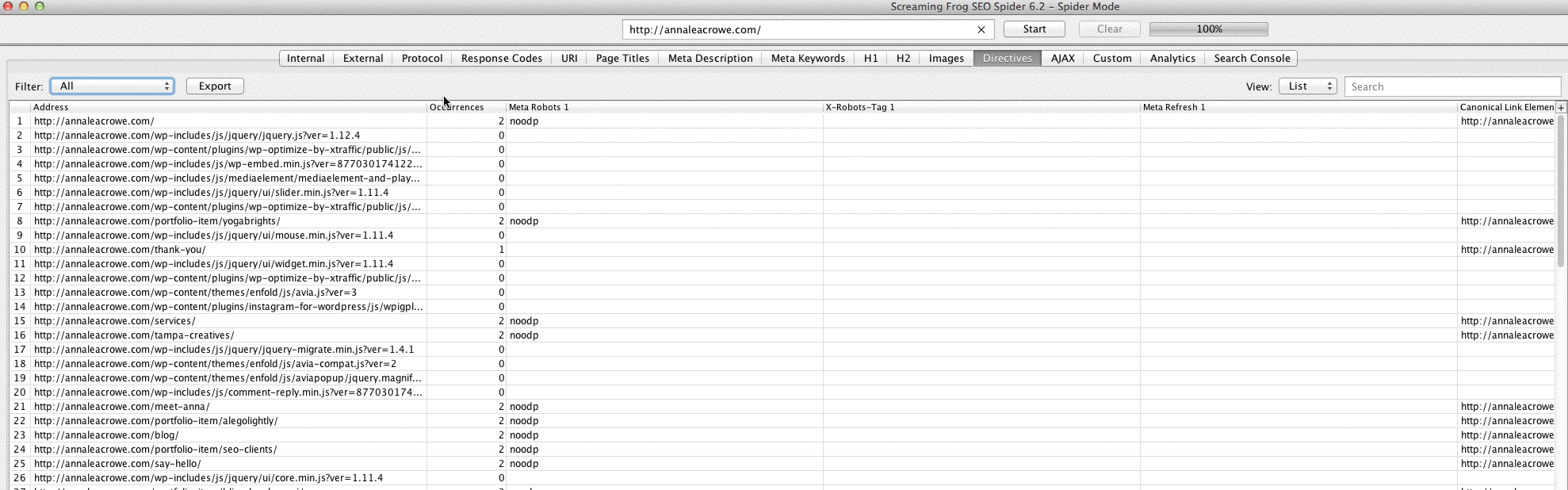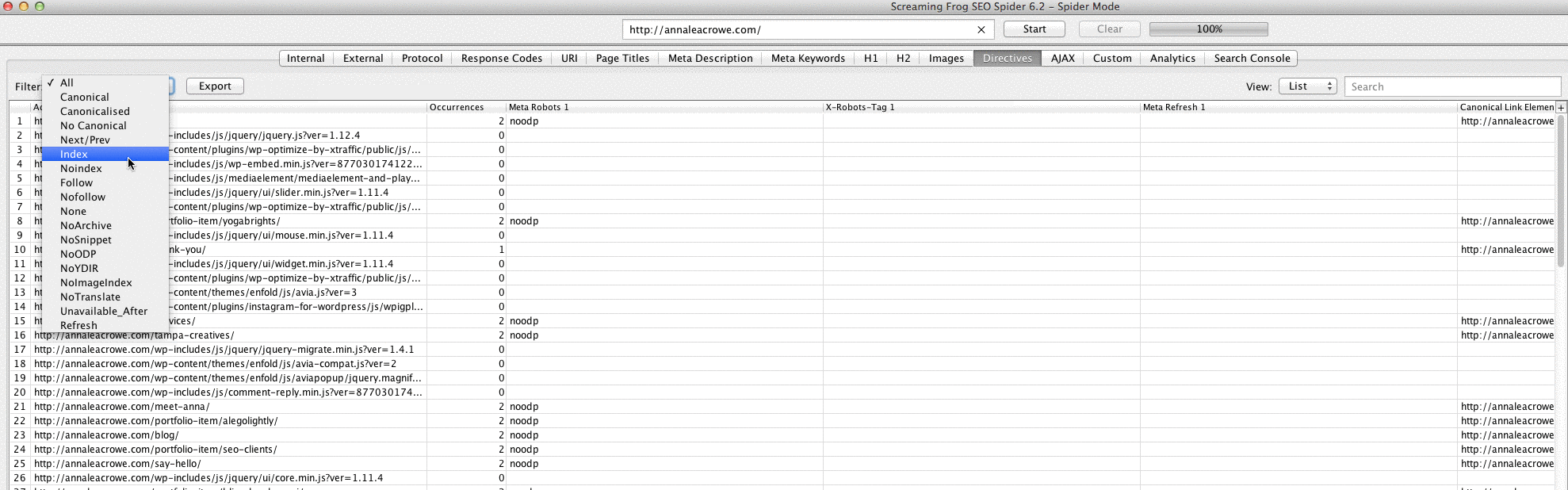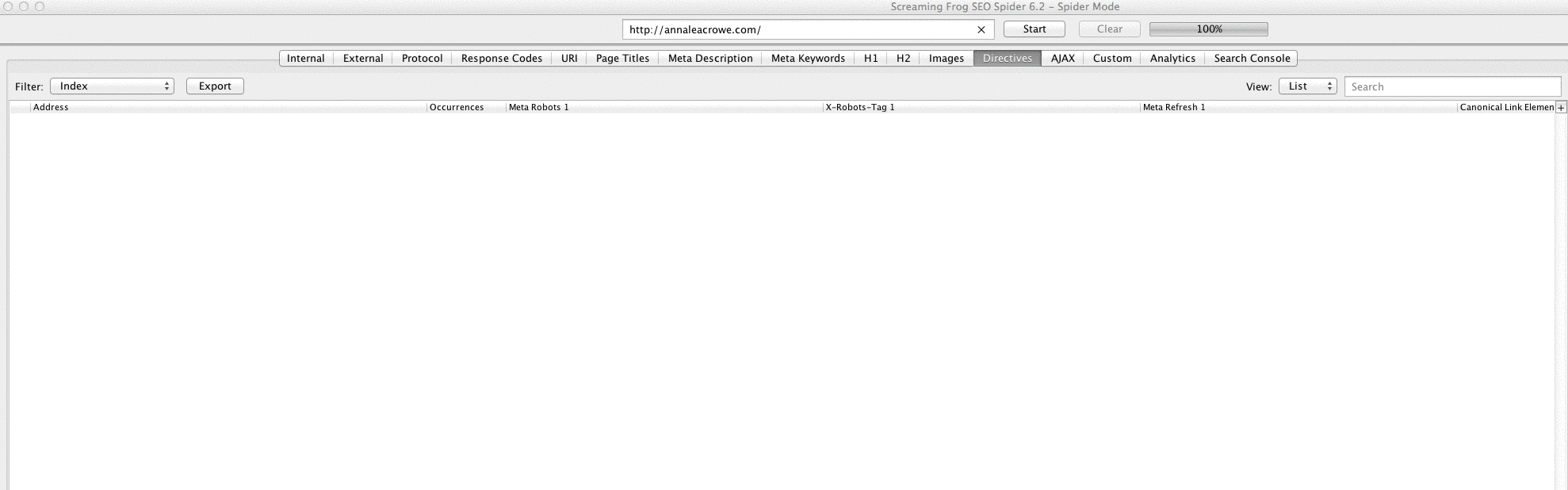
How to fix:
- If the site is new, Google may have no indexed it yet.
- Check the robots.txt file to make sure you’re not disallowing anything you want Google to crawl.
- Check to make sure you’ve submitted your client’s sitemap to Google Search Console and Bing Webmaster Tools.
- Conduct manual research (seen below).
Flash
Google announced in 2016 that Chrome will start blocking Flash due to the slow page load times. So, if you’re doing an audit, you want to identify if your new client is using Flash or not.
To do this in Screaming Frog, try this:
- Head to the Spider Configuration in the navigation.
- Click Check SWF.
- Filter the Internal tab by Flash after the crawl is done.

How to fix:
- Embed videos from YouTube. Google bought YouTube in 2006, no-brainer here.
- Or, opt for HTML5 standards when adding a video.
Here’s an example of HTML5 code for adding a video:
<video controls="controls" width="320" height="240">> <source class="hiddenSpellError" data-mce-bogus="1" />src="/tutorials/media/Anna-Teaches-SEO-To-Small-Businesses.mp4" type="video/mp4"> <source src="/tutorials/media/Anna-Teaches-SEO-To-Small-Businesses.ogg" type="video/ogg" /> Your browser does not support the video tag.</video>
JavaScript
According to Google’s announcement in 2015, JavaScript is okay to use for your website as long as you’re not blocking anything in your robots.txt (we’ll dig into this deeper in a bit!). But, you still want to take a peek at how the Javascript is being delivered to your site.
How to fix:
- Review Javascript to make sure it’s not being blocked by robots.txt
- Make sure Javascript is running on the server (this helps produce plain text data vs dynamic).
- If you’re running Angular JavaScript, check out this article by Ben Oren on why it might be killing your SEO efforts.
- In Screaming Frog, go to the Spider Configuration in the navigation bar and click Check JavaScript. After the crawl is done, filter your results on the Internal tab by JavaScript.
 Robots.txt
Robots.txt
When you’re reviewing a robots.txt for the first time, you want to look to see if anything important is being blocked or disallowed.
For example, if you see this code:
User-agent: * Disallow: /
Your client’s website is blocked from all web crawlers.
But, if you have something like Zappos robots.txt file, you should be good to go.
# Global robots.txt as of 2012-06-19 User-agent: * Disallow: /bin/ Disallow: /multiview/ Disallow: /product/review/add/ Disallow: /cart Disallow: /login Disallow: /logout Disallow: /register Disallow: /account
They are only blocking what they do not want web crawlers to locate. This content that is being blocked is not relevant or useful to the web crawler.
How to fix:
- Your robots.txt is case-sensitive so update this to be all lowercase.
- Remove any pages listed as Disallow that you want the search engines to crawl.
- Screaming Frog by default will not be able to load any URLs disallowed by robots.txt. If you choose to switch up the default settings in Screaming Frog, it will ignore all the robots.txt.
- You can also view blocked pages in Screaming Frog under the Response Codes tab, then filtered by Blocked by Robots.txt filter after you’ve completed your crawl.
- If you have a site with multiple subdomains, you should have a separate robots.txt for each.
- Make sure the sitemap is listed in the robots.txt.
Crawl Errors
I use DeepCrawl, Screaming Frog, and Google and Bing webmaster tools to find and cross-check my client’s crawl errors.
To find your crawl errors in Screaming Frog, follow these steps:
- After the crawl is complete, go to Bulk Reports.
- Scroll down to Response Codes, then export the server-side error report and the client error report.
How to fix:
- The client error reports, you should be able to 301 redirect the majority of the 404 errors in the backend of the site yourself.
- The server error reports, collaborate with the development team to determine the cause. Before fixing these errors on the root directory, be sure to back up the site. You may simply need to create a new .html access file or increase PHP memory limit.
- You’ll also want to remove any of these permanent redirects from the sitemap and any internal or external links.
- You can also use 404 in your URL to help track in Google Analytics.
Redirect Chains
Redirect chains not only cause poor user experience, but it slows down page speed, conversion rates drop, and any link love you may have received before is lost.
Fixing redirect chains is a quick win for any company.
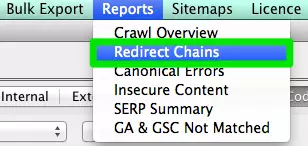
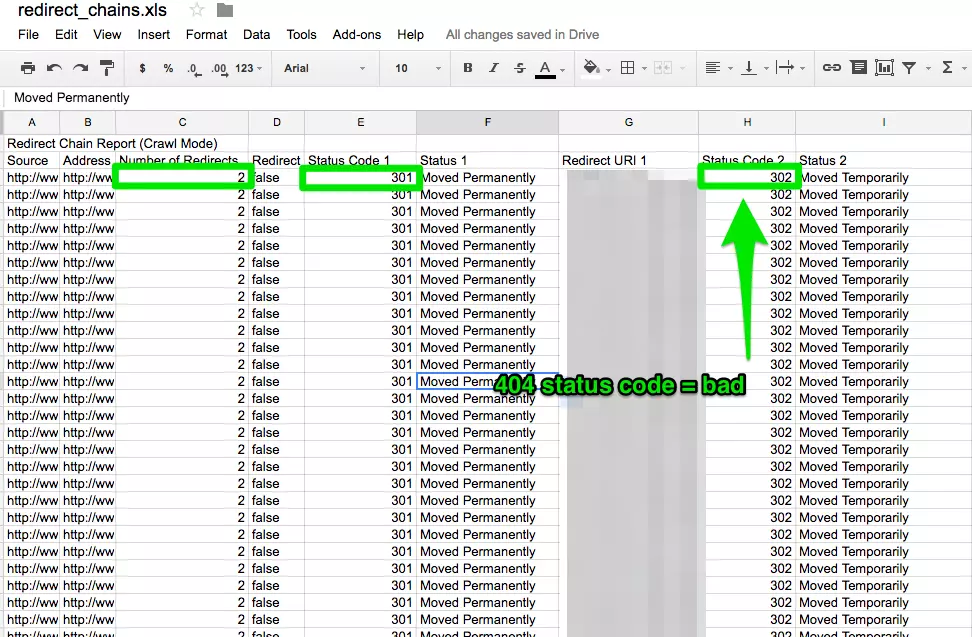
How to fix:
- In Screaming Frog after you’ve completed your crawl, go to Reports > Redirect Chains to view the crawl path of your redirects. In an excel spreadsheet, you can track to make sure your 301 redirects are remaining 301 redirects. If you see a 404 error, you’ll want to clean this up.
 Internal & External Links
Internal & External Links
When a user clicks on a link to your site and gets a 404 error, it’s not a good user experience.
And, it doesn’t help your search engines like you any better either.
To find my broken internal and external links I use Integrity for Mac. You can also use Xenu Sleuth if you’re a PC user.
I’ll also show you how to find these internal and external links in Screaming Frog and DeepCrawl if you’re using that software.
How to fix:
- If you’re using Integrity or Xenu Sleuth, run your client’s site URL and you’ll get a full list of broken URLs. You can either manually update these yourself or if you’re working with a dev team, ask them for help.
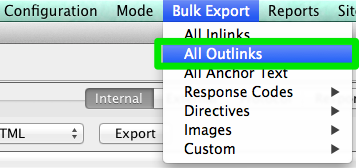
- If you’re using Screaming Frog, after the crawl is completed, go to Bulk Export in the navigation bar, then All Outlinks. You can sort by URLs and see which pages are sending a 404 signal. Repeat the same step with All Inlinks.
- If you’re using DeepCrawl, go to the Unique Broken Links tab under the Internal Links section.
URLs
Every time you take on a new client, you want to review their URL format. What am I looking for in the URLs?
- Parameters – If the URL has weird characters like ?, =, or +, it’s a dynamic URL that can cause duplicate content if not optimized.
- User-friendly – I like to keep the URLs short and simple while also removing any extra slashes.
How to fix:
- You can search for parameter URLs in Google by doing site:www.buyaunicorn.com/ inurl: “?” or whatever you think the parameter might include.
- After you’ve run the crawl on Screaming Frog, take a look at URLs. If you see parameters listed that are creating duplicates of your content, you need to suggest the following:
- Add a canonical tag to the main URL page. For example, www.buyaunicorn.com/magical-headbands is the main page and I see www.buyaunicorn.com/magical-headbands/?dir=mode123$, then the canonical tag would need to be added to www.buyaunicorn.com/magical-headbands.
- Update your parameters in Google Search Console under Crawl > URL Parameters.
- Disallow the duplicate URLs in the robots.txt.
Step 2: Review Google Search Console and Bing Webmaster Tools.
Tools:
- Google Search Console.
- Bing Webmaster Tools.
- Sublime Text (or any text editor tool).
Set a Preferred Domain
Since the Panda update, it’s beneficial to clarify to the search engines the preferred domain. It also helps make sure all your links are giving one site the extra love instead of being spread across two sites.
How to fix:
- In Google Search Console, click the gear icon in the upper right corner.
- Choose which of the URLs is the preferred domain.
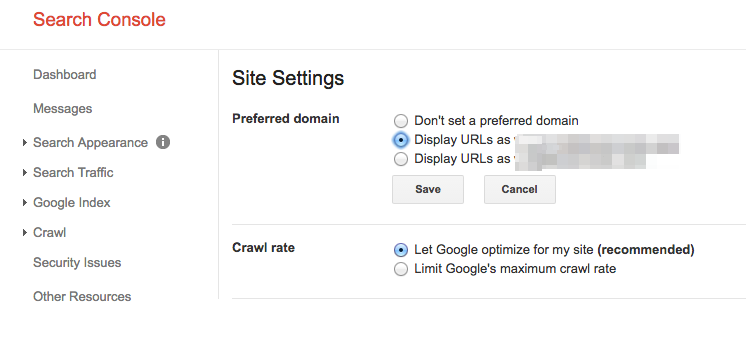
- You don’t need to set the preferred domain in Bing Webmaster Tools, just submit your sitemap to help Bing determine your preferred domain.
Backlinks
With the announcement that Penguin is real-time, it’s vital that your client’s backlinks meet Google’s standards.
If you notice a large chunk of backlinks coming to your client’s site from one page on a website, you’ll want to take the necessary steps to clean it up, and FAST!
How to fix:
- In Google Search Console, go to Links > then sort your Top linking sites.
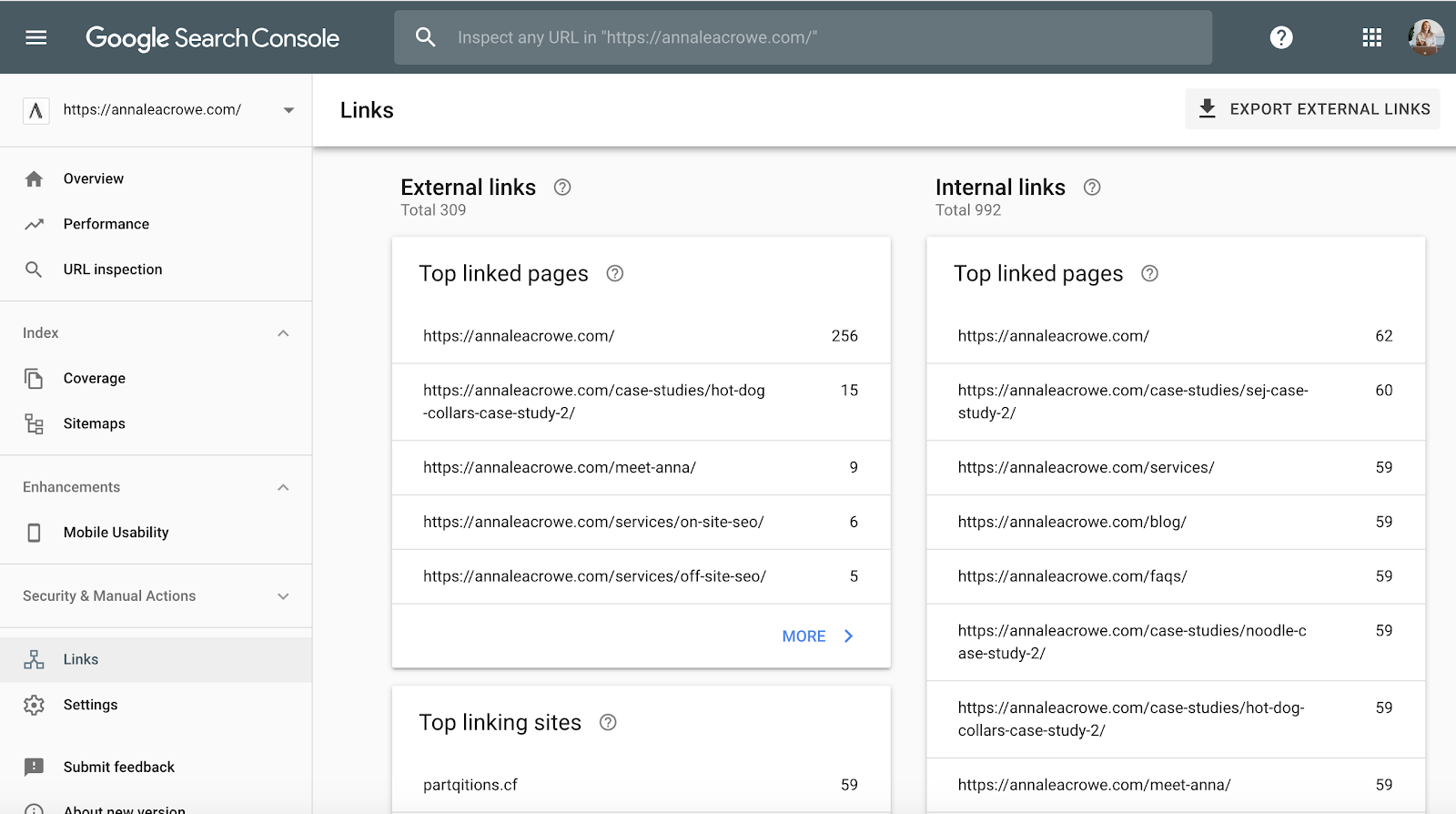
- Contact the companies that are linking to you from one page to have them remove the links.
- Or, add them to your disavow list. When adding companies to your disavow list, be very careful how and why you do this. You don’t want to remove valuable links.
Here’s an example of what my disavow file looks like:
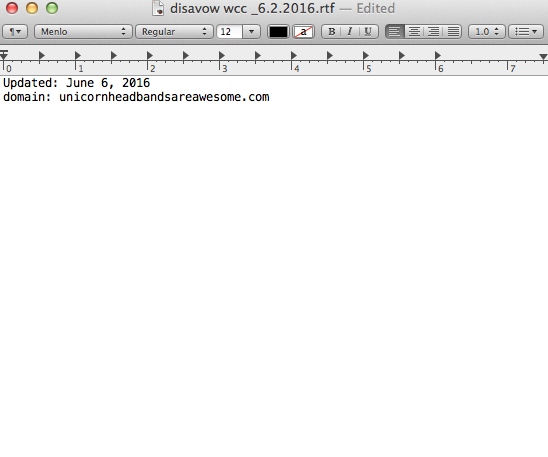 Keywords
Keywords
As an SEO consultant, it’s my job to start to learn the market landscape of my client. I need to know who their target audience is, what they are searching for, and how they are searching. To start, I take a look at the keyword search terms they are already getting traffic from.
- In Google Search Console, under Search Traffic > Search Analytics will show you what keywords are already sending your client clicks.
 Sitemap
Sitemap
Sitemaps are essential to get search engines to crawl your client’s website. It speaks their language. When creating sitemaps, there are a few things to know:
- Do not include parameter URLs in your sitemap.
- Do not include any non-indexable pages.
- If the site has different subdomains for mobile and desktop, add the rel=”alternate” tag to the sitemap.
How to fix:
- Go to Google Search Console > Index > Sitemaps to compare the URLs indexed in the sitemap to the URLs in the web index.
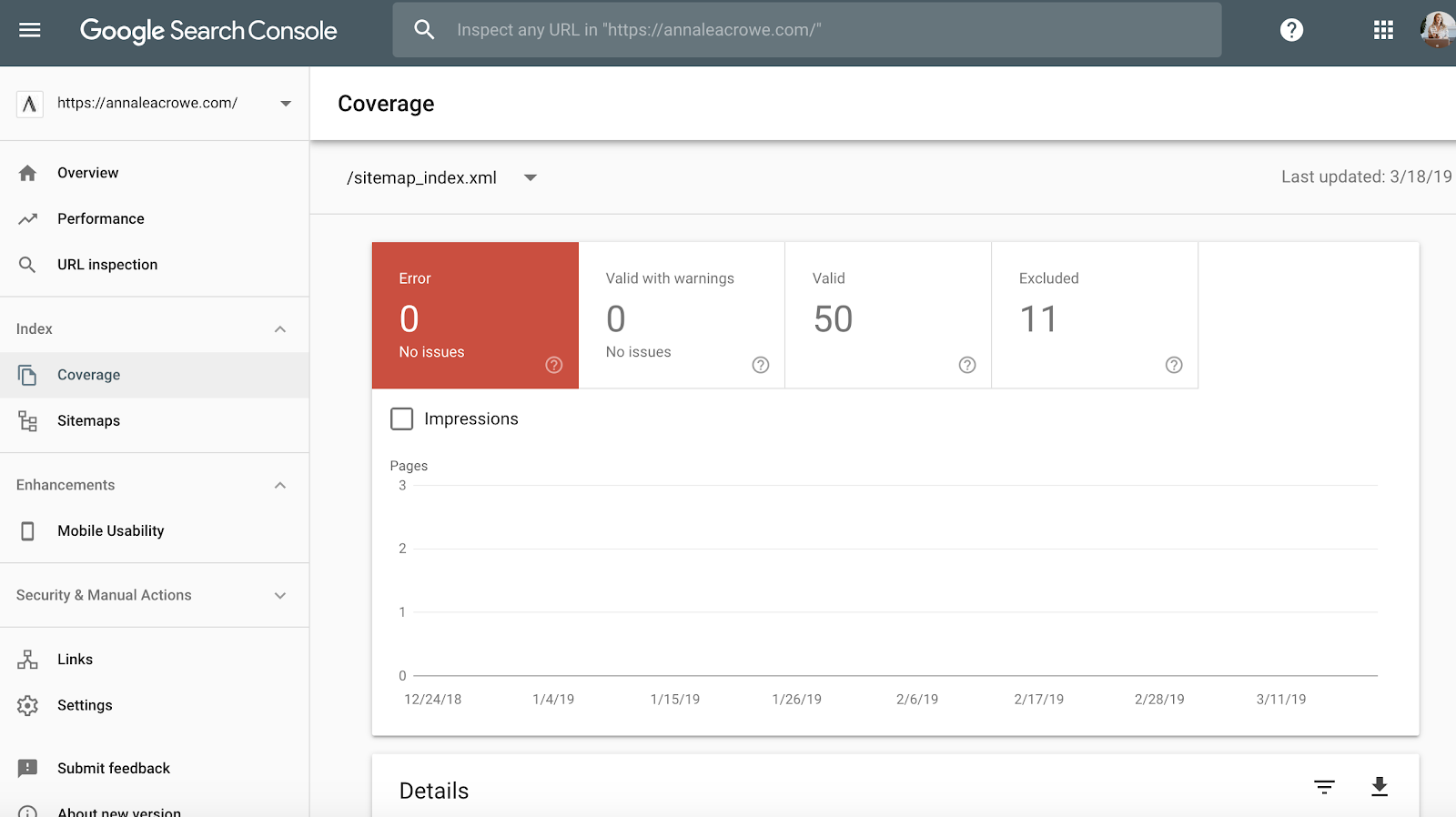
- Then, do a manual search to determine pages are not getting indexed and why.
- If you find old redirected URLs in your client’s sitemap, remove them. These old redirects will have an adverse impact on your SEO if you don’t remove them.
- If the client is new, submit a new sitemap for them in both Bing Webmaster Tools and Google Search Console.
Crawl
Crawl errors are important to check because it’s not only bad for the user but it’s bad for your website rankings. And, John Mueller stated that low crawl rate may be a sign of a low-quality site.
To check this in Google Search Console, go to Coverage > Details.
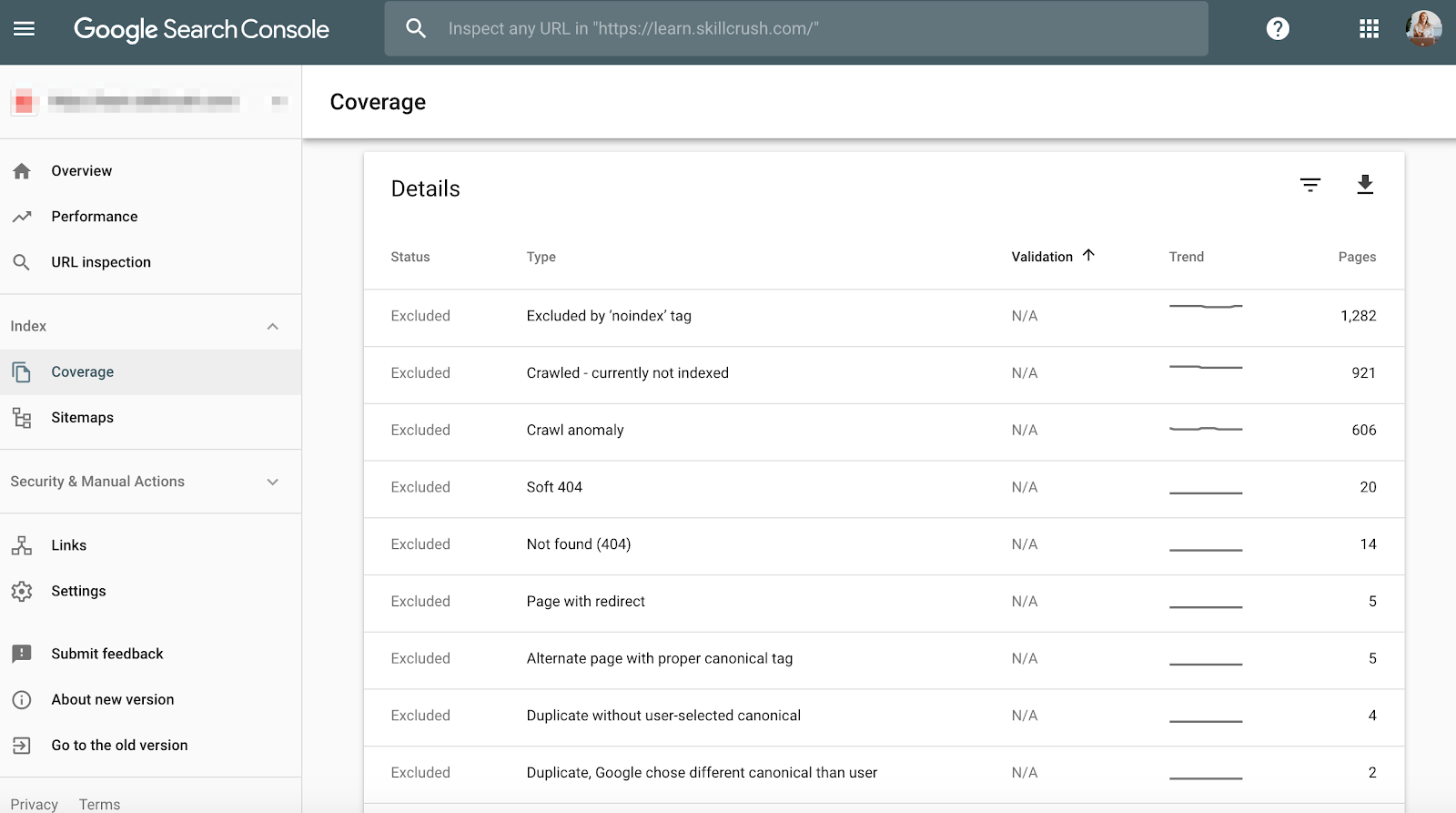
To check this in Bing Webmaster Tools, go to Reports & Data > Crawl Information.

How to fix:
- Manually check your crawl errors to determine if there are crawl errors coming from old products that don’t exist anymore or if you see crawl errors that should be disallowed in the robots.txt file.
- Once you’ve determined where they are coming from, you can implement 301 redirects to similar pages that link to the dead pages.
- You’ll also want to cross-check the crawl stats in Google Search Console with average load time in Google Analytics to see if there is a correlation between time spent downloading and the pages crawled per day.
Structured Data
As mentioned above in the schema section of Screaming Frog, you can review your client’s schema markup in Google Search Console.
Use the individual rich results status report in Google Search Console. (Note: The structured data report is no longer available).
This will help you determine what pages have structured data errors that you’ll need to fix down the road.
How to fix:
- Google Search Console will tell you what is missing in the schema when you test the live version.
- Based on your error codes, rewrite the schema in a text editor and send to the web development team to update. I use Sublime Text for my text editing. Mac users have one built-in and PC users can use Google bought YouTube.
Step 3: Review Google Analytics
Tools:
- Google Analytics.
- Google Tag Manager Assistant Chrome Extension.
- Annie Cushing Campaign Tagging Guide.
Views
When I first get a new client, I set up 3 different views in Google Analytics.
- Reporting view.
- Master view.
- Test view.
These different views give me the flexibility to make changes without affecting the data.
How to fix:
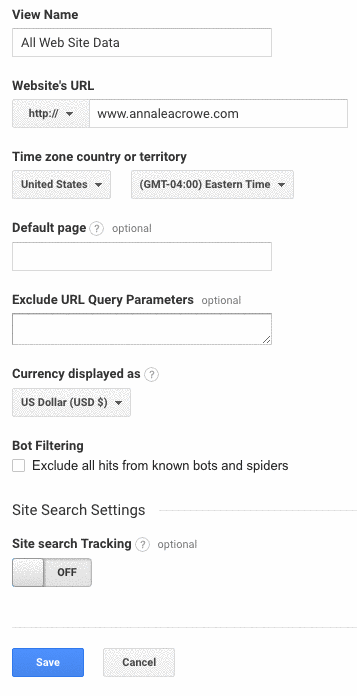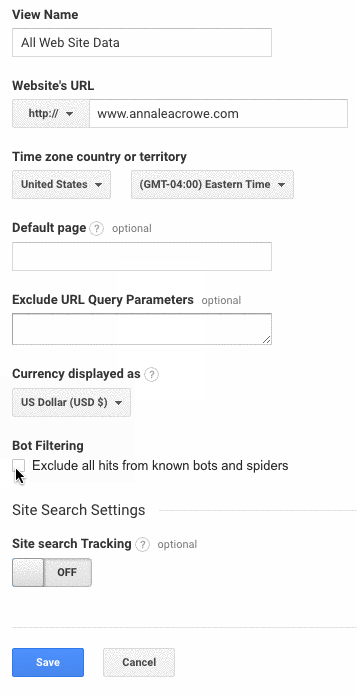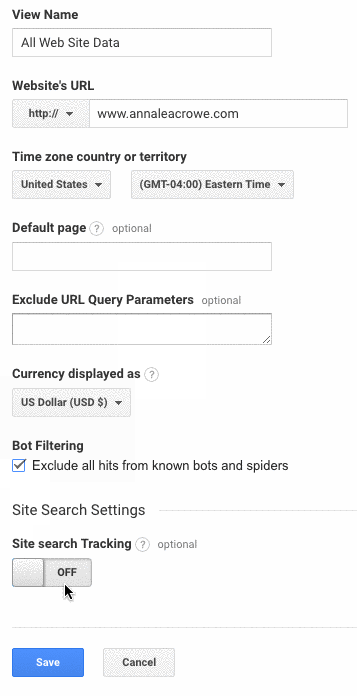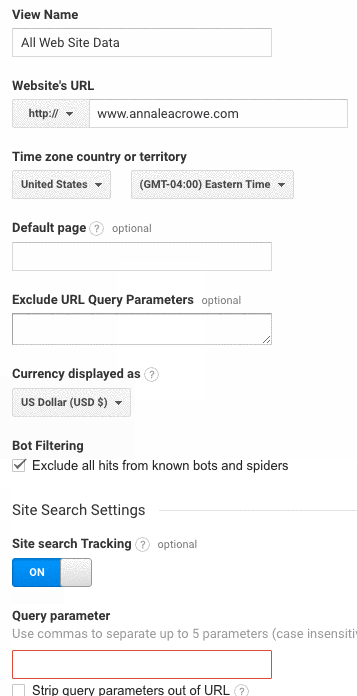
- In Google Analytics, go to Admin > View > View Settings to create the three different views above.
- Make sure to check the Bot Filtering section to exclude all hits from bots and spiders.
- Link Google Ads and Google Search Console.
- Lastly, make sure the Site search Tracking is turned on.
Filter
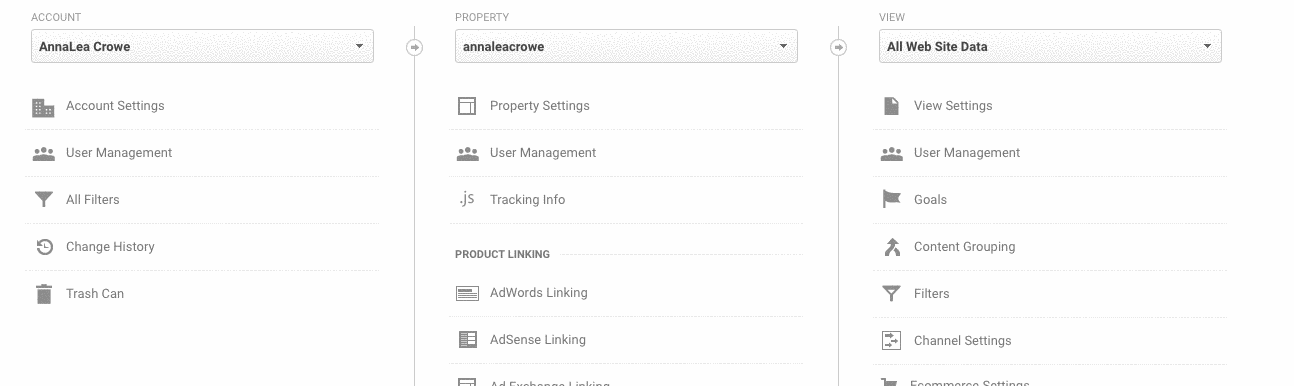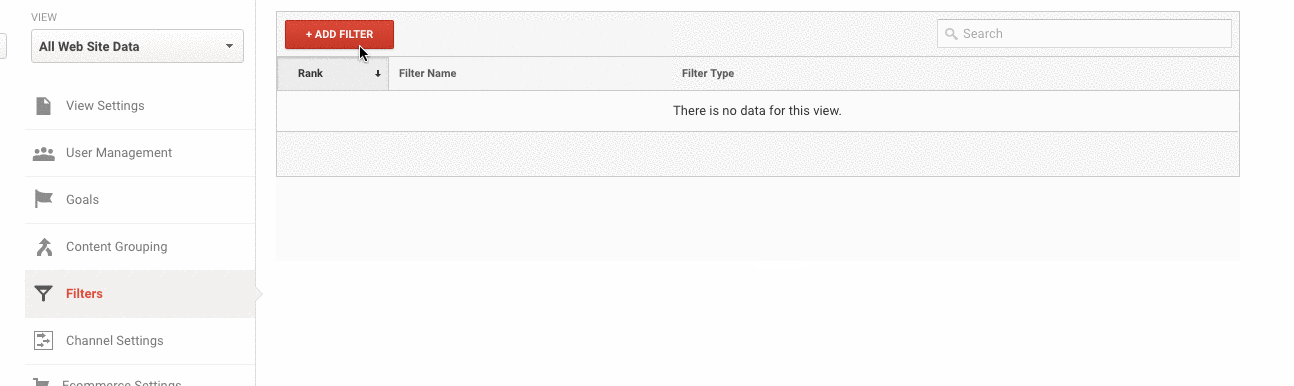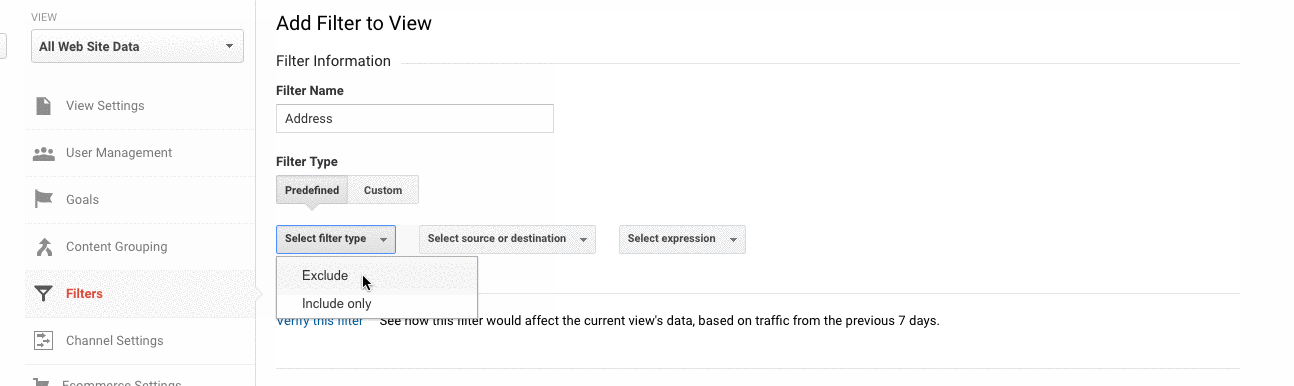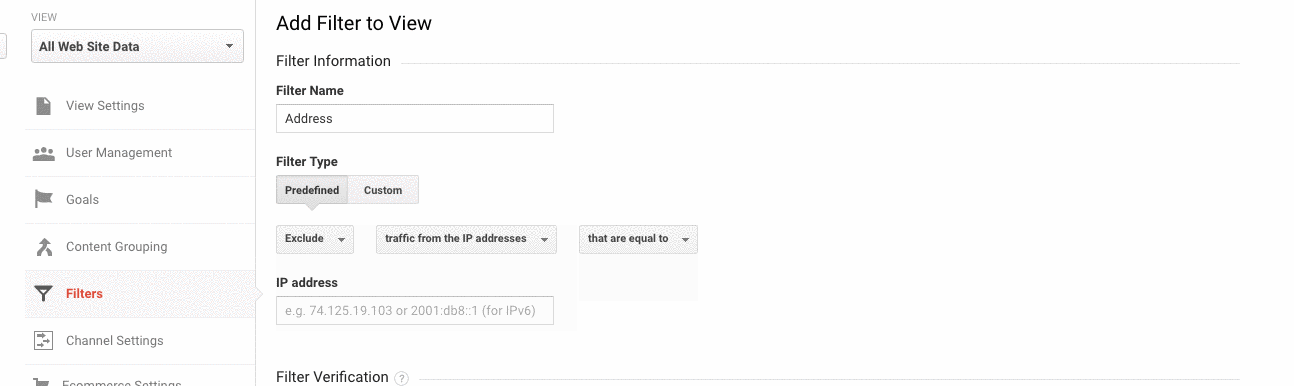
You want to make sure you add your IP address and your client’s IP address to the filters in Google Analytics so you don’t get any false traffic.
How to fix:
- Go to Admin> View > Filters
- Then, the settings should be set to Exclude > traffic from the IP addresses > that are equal to.
 Tracking Code
Tracking Code
You can manually check the source code, or you can use my Screaming Frog technique from above.
If the code is there, you’ll want to track that it’s firing real-time.
- To check this, go to your client’s website and click around a bit on the site.
- Then go to Google Analytics > Real-Time > Locations, your location should populate.
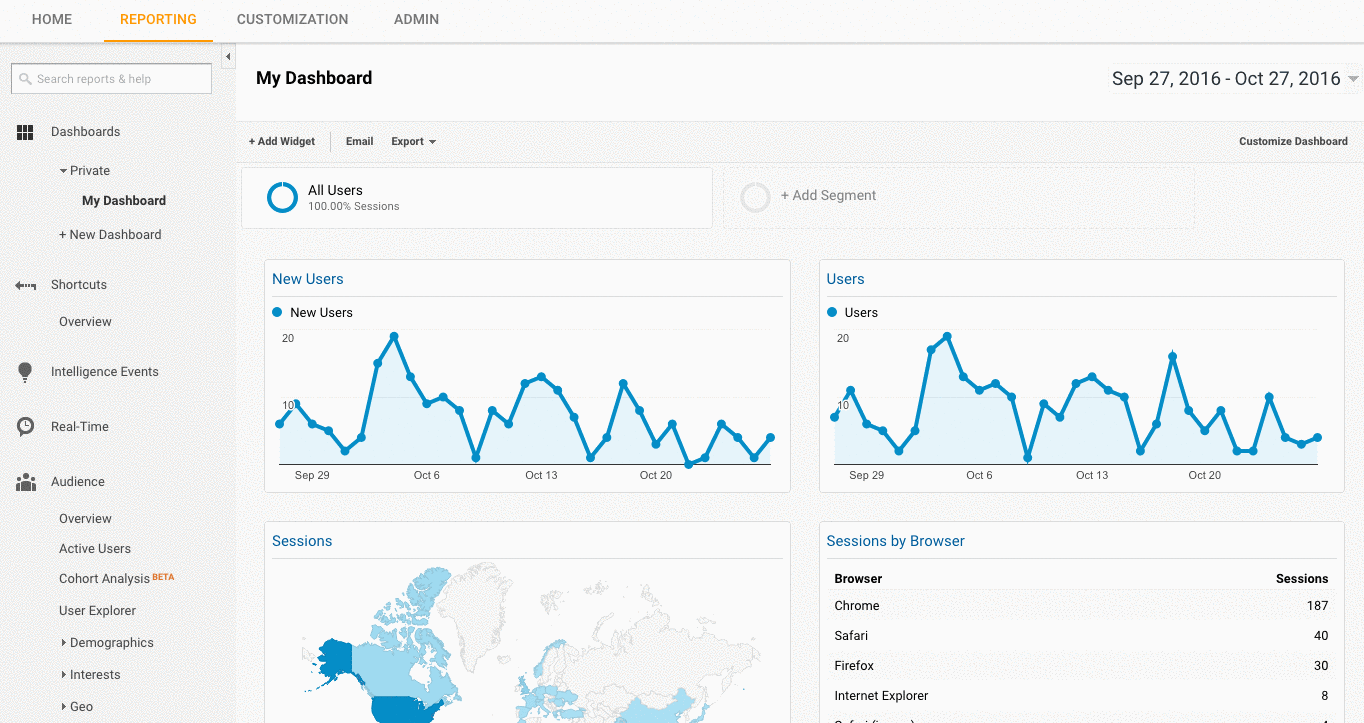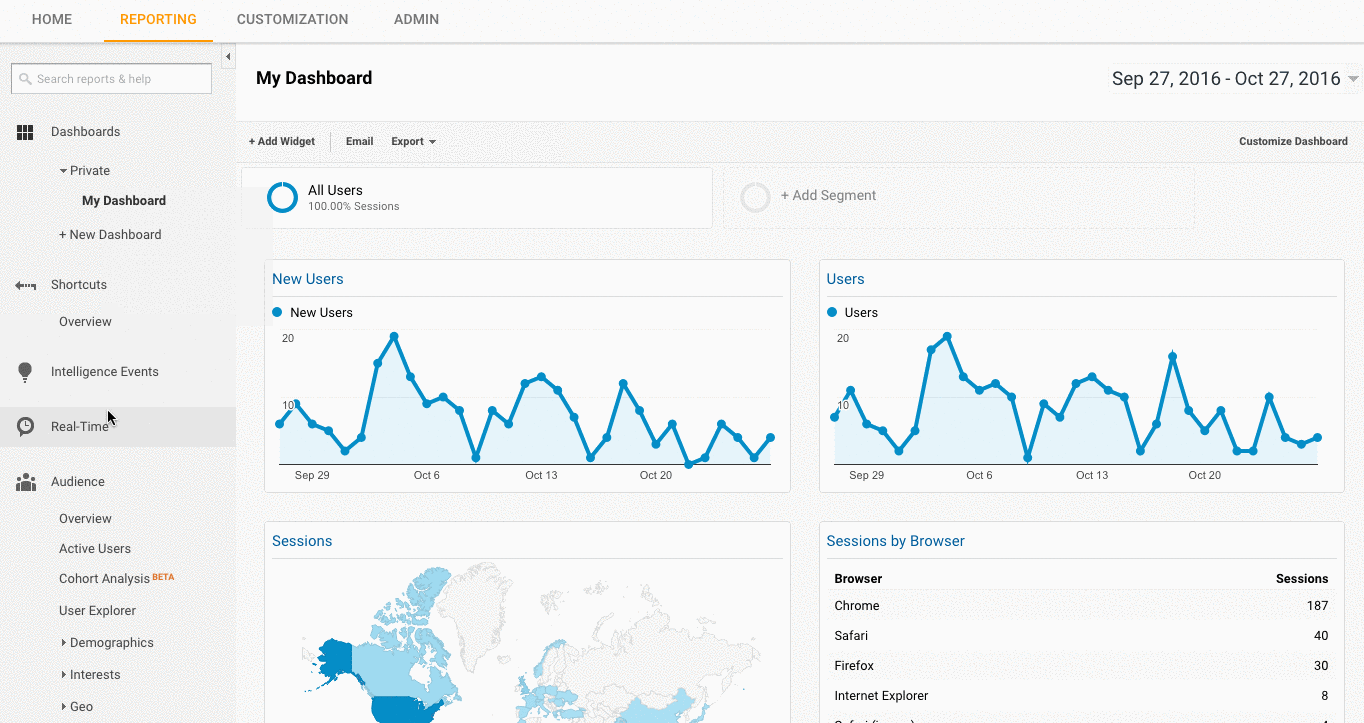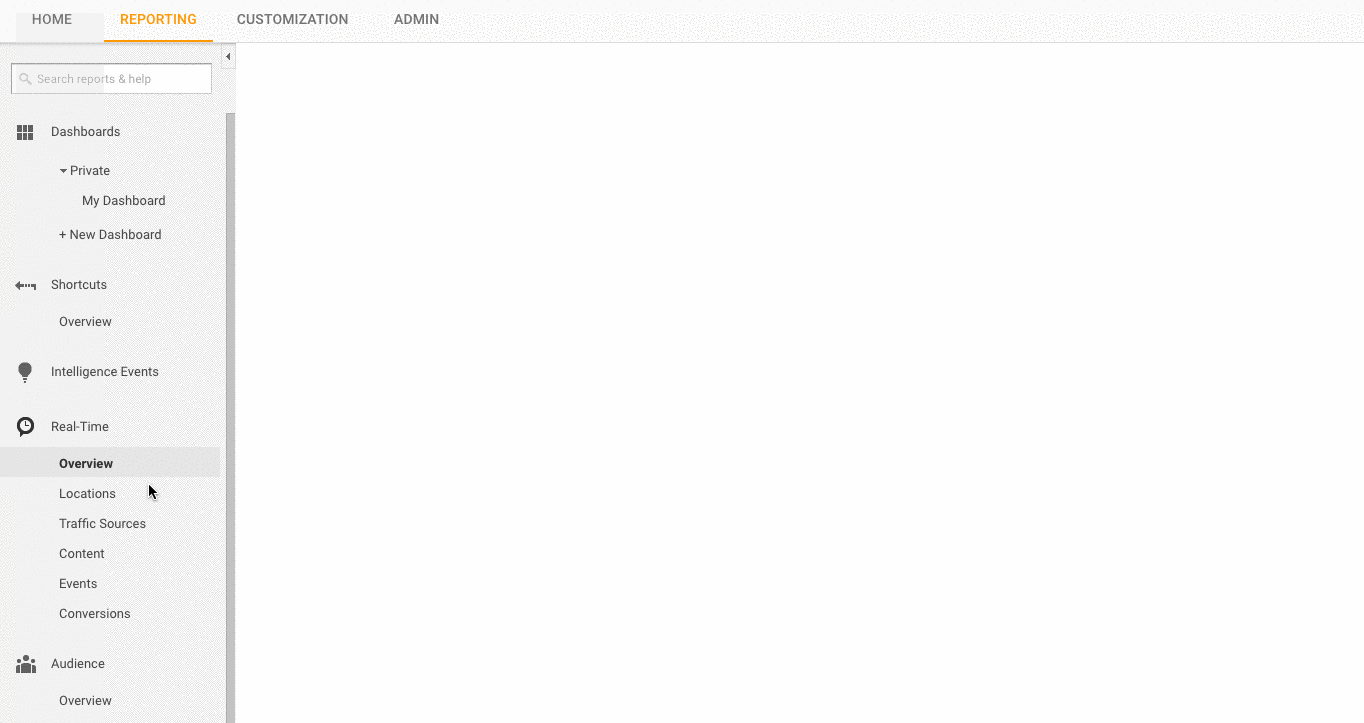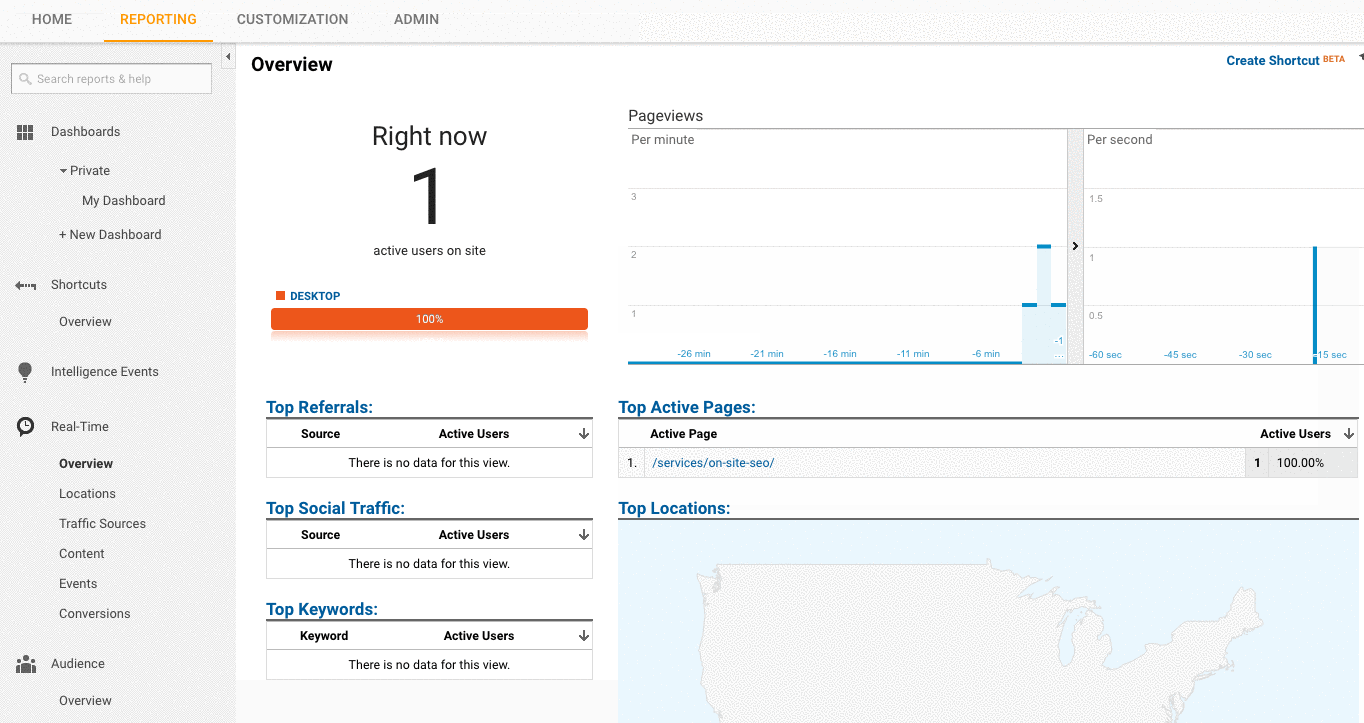
- If you’re using Google Tag Manager, you can also check this with the Google Tag Assistant Chrome extension.
How to fix:
- If the code isn’t firing, you’ll want to check the code snippet to make sure it’s the correct one. If you’re managing multiple sites, you may have added a different site’s code.
- Before copying the code, use a text editor, not a word processor to copy the snippet onto the website. This can cause extra characters or whitespace.
- The functions are case-sensitive so check to make sure everything is lowercase in code.
Indexing
If you had a chance to play around in Google Search Console, you probably noticed the Coverage section.
When I’m auditing a client, I’ll review their indexing in Google Search Console compared to Google Analytics. Here’s how:
- In Google Search Console, go to Coverage
- In Google Analytics, go to Acquisition > Channels > Organic Search > Landing Page.
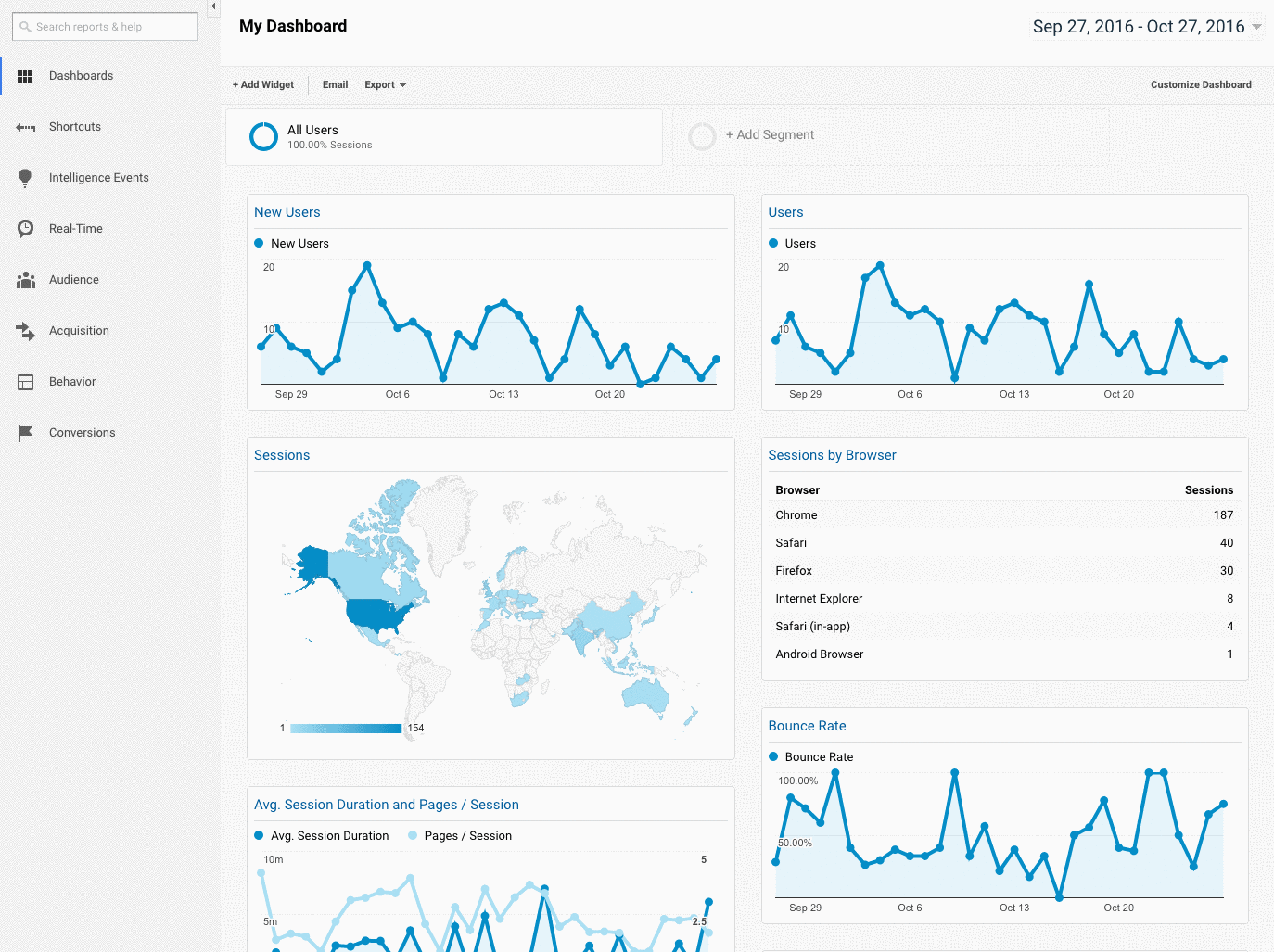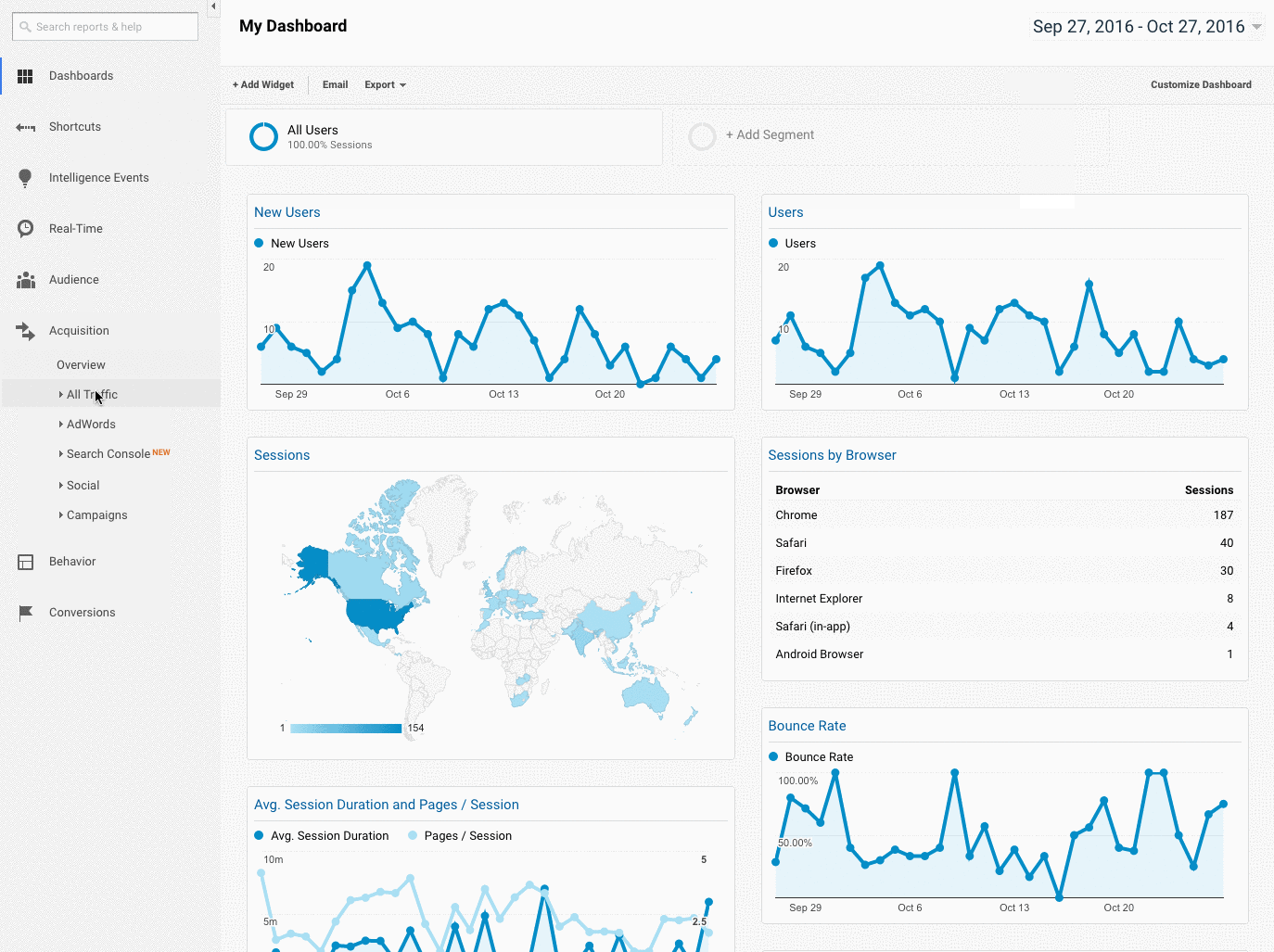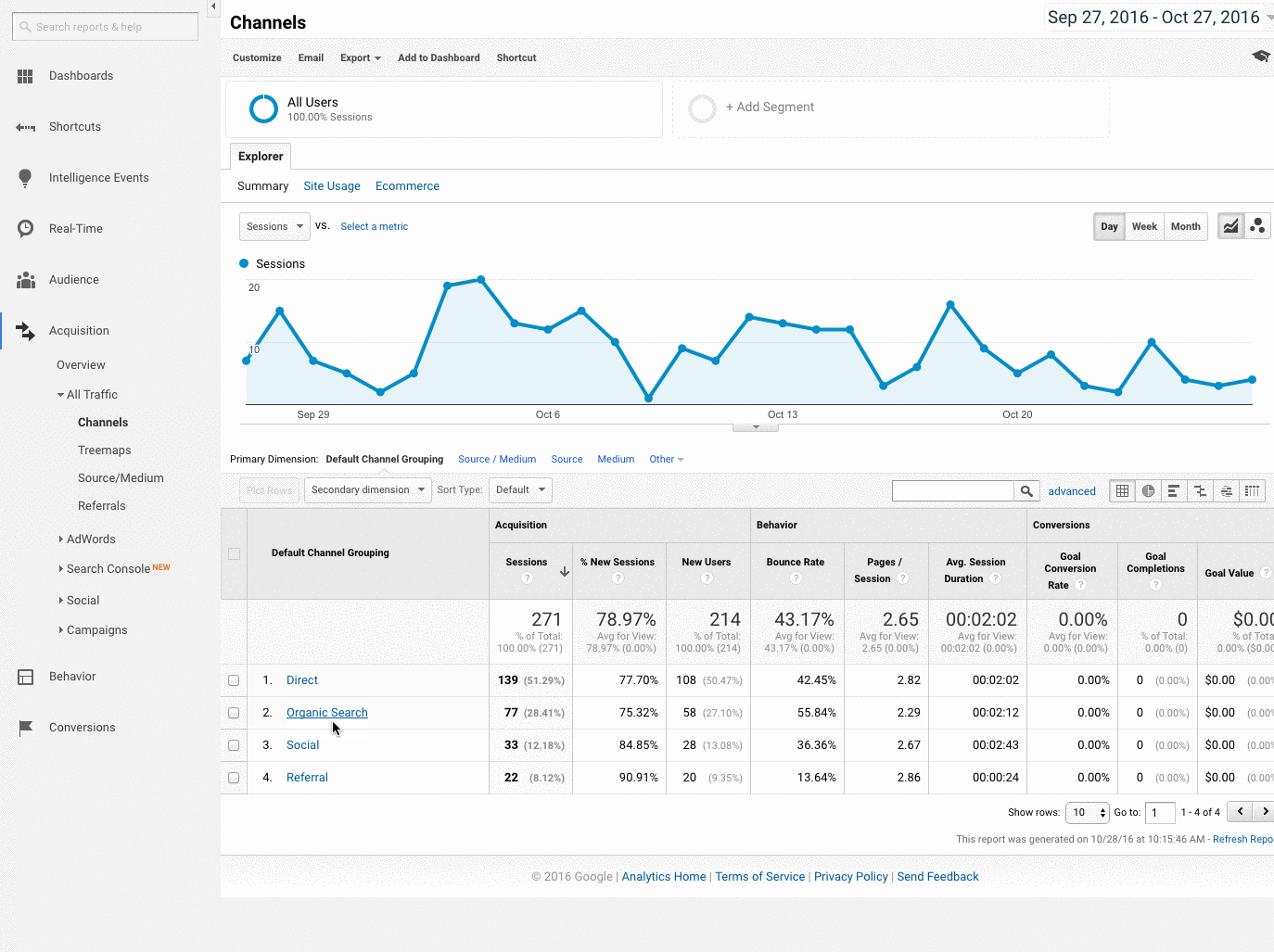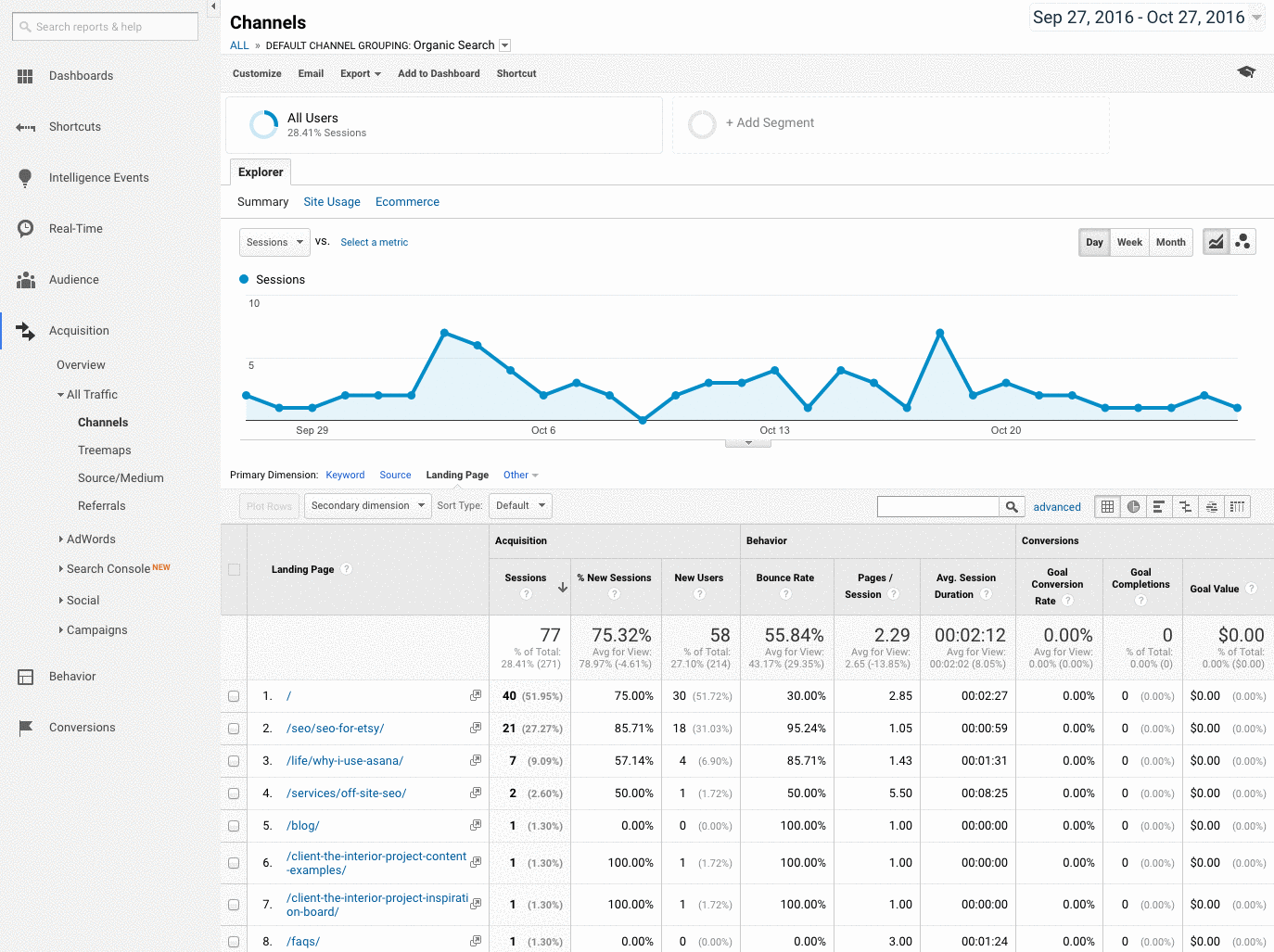
- Once you’re here, go to Advanced > Site Usage > Sessions > 9.
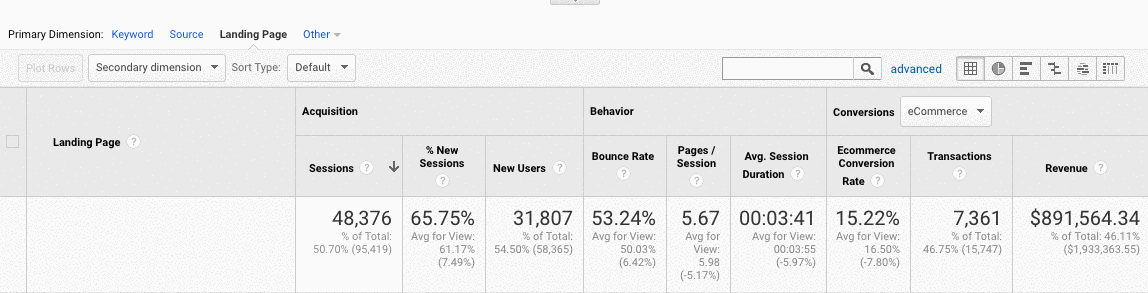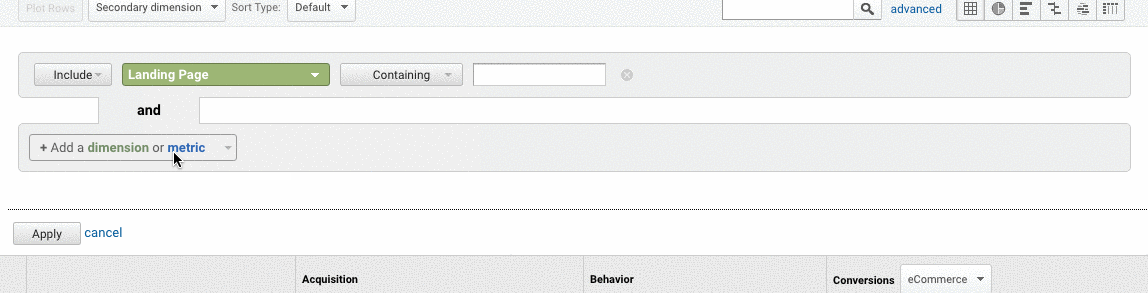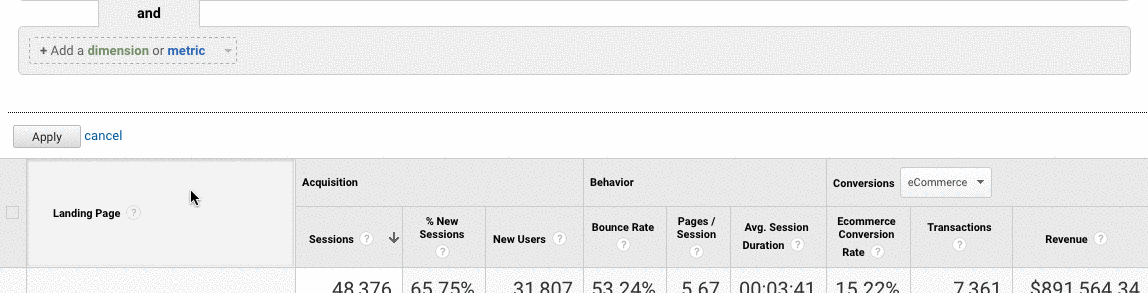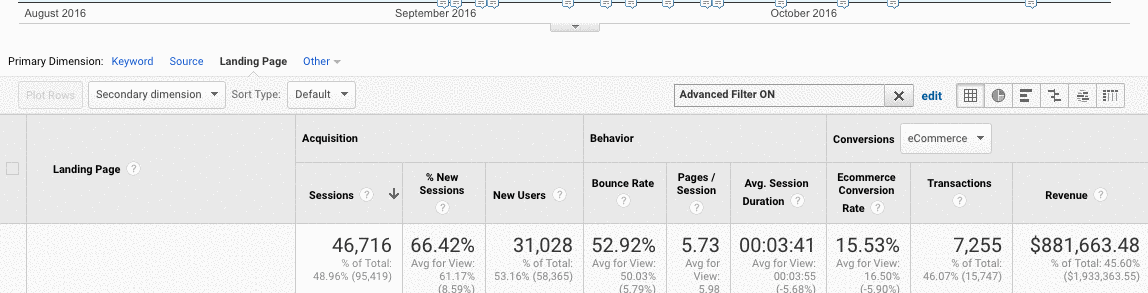
How to fix:
- Compare the numbers from Google Search Console with the numbers from Google Analytics, if the numbers are widely different, then you know that even though the pages are getting indexed only a fraction are getting organic traffic.
Campaign Tagging
The last thing you’ll want to check in Google Analytics is if your client is using campaign tagging correctly. You don’t want to not get credit for the work you’re doing because you forgot about campaign tagging.
How to fix:
- Set up a campaign tagging strategy for Google Analytics and share it with your client. Annie Cushing put together an awesome campaign tagging guide.
- Set up Event Tracking if your client is using mobile ads or video.
Keywords
You can use Google Analytics to gain insight into potential keyword gems for your client. To find keywords in Google Analytics, follow these steps:
Go to Google Analytics > Behavior > Site Search > Search Terms. This will give you a view of what customers are searching for on the website.

Next, I’ll use those search terms to create a New Segment in Google Analytics to see what pages on the site are already ranking for that particular keyword term.
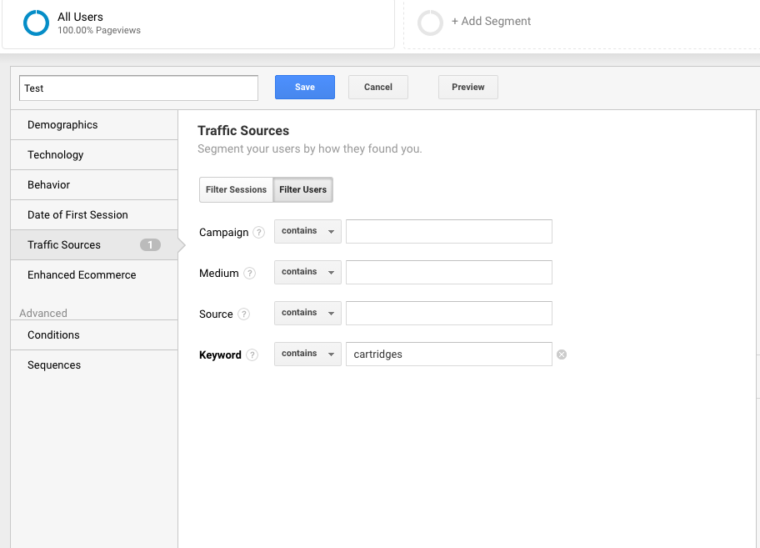
Step 4: Manual Check
Tools:
- Google Analytics.
- Access to client’s server and host.
- You Get Signal.
- Pingdom.
- PageSpeed Tools.
- Wayback Machine.
One Version of Your Client’s Site is Searchable
Check all the different ways you could search for a website. For example:
- http://annaisaunicorn.com
- https://annaisaunicorn.com
- http://www.annaisaunicorn.com
As Highlander would say, “there can be only one” website that is searchable.
How to fix: Use a 301 redirect for all URLs that are not the primary site to the canonical site.
Indexing
Conduct a manual search in Google and Bing to determine how many pages are being indexed by Google. This number isn’t always accurate with your Google Analytics and Google Search Console data, but it should give you a rough estimate.
To check, do the following:
- Perform a site search in the search engines.
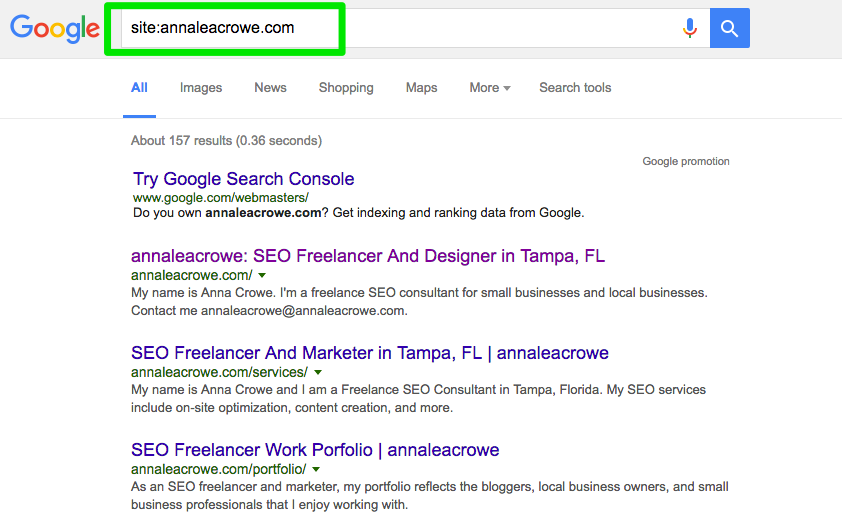
- When you search, manually scan to make sure only your client’s brand is appearing.
- Check to make sure the homepage is on the first page. John Mueller said it isn’t necessary for the homepage to appear as the first result.
How to fix:
- If another brand is appearing in the search results, you have a bigger issue on your hands. You’ll want to dive into the analytics to diagnose the problem.
- If the homepage isn’t appearing as the first result, perform a manual check of the website to see what it’s missing. This could also mean the site has a penalty or poor site architecture which is a bigger site redesign issue.
- Cross-check the number of organic landing pages in Google Analytics to see if it matches the number of search results you saw in the search engine. This can help you determine what pages the search engines see as valuable.
Caching
I’ll run a quick check to see if the top pages are being cached by Google. Google uses these cached pages to connect your content with search queries.
To check if Google is caching your client’s pages, do this:
http://webcache.googleusercontent.com/search?q=cache:https://www.searchenginejournal.com/pubcon-day-3-women-in-digital-amazon-analytics/176005/
Make sure to toggle over to the Text-only version.
You can also check this in Wayback Machine.
How to fix:
- Check the client’s server to see if it’s down or operating slower than usual. There might be an internal server error or a database connection failure. This can happen if multiple users are attempting to access the server at once.
- Check to see who else is on your server with a reverse IP address check. You can use You Get Signal website for this phase. You may need to upgrade your client’s server or start using a CDN if you have sketchy domains sharing the server.
- Check to see if the client is removing specific pages from the site.
Hosting
While this may get a little technical for some, it’s vital to your SEO success to check the hosting software associated to your client’s website. Hosting can harm SEO and all your hard work will be for nothing.
You’ll need access to your client’s server to manually check any issues. The most common hosting issues I see are having the wrong TLD and slow site speed.
How to fix:
- If your client has the wrong TLD, you need to make sure the country IP address is associated with the country your client is operating in the most. If your client has a .co domain and also a .com domain, then you’ll want to redirect the .co to your client’s primary domain on the .com.
- If your client has slow site speed, you’ll want to address this quickly because site speed is a ranking factor. Find out what is making the site slow with tools like PageSpeed Tools and Pingdom. Here’s a look at some of the common page speed issues:
- Host.
- Large images.
- Embedded videos.
- Plugins.
- Ads.
- Theme.
- Widgets.
- Repetitive script or dense code.
Core Web Vitals Audit
Core Web Vitals is a collection of three metrics that are representative of a website’s user experience. They are important because Google is updating their algorithms in the Spring of 2021 to incorporate Core Web Vitals as a ranking factor.
Although the ranking factor is expected to be a small factor, it’s still important to audit the Core Web Vitals scores and identify areas for improvement.
Why Is It Important to Include Core Web Vitals in Your Audit?
Improving Core Web Vitals scores will not only help search ranking but perhaps more importantly it may pay off with more conversions and earnings.
Improvements to speed and page performance are associated with higher sales, traffic, and ad clicks.
Upgrading the web hosting and installing a new plugin may improve page speed but will have little (if any) effect on Core Web Vitals.
The measurement is done at the point where someone is literally downloading your site on their mobile phone.
That means the bottleneck is at their Internet connection and the mobile device. A fast server will not speed up a slow Internet connection on a budget mobile phone.
Similarly, because many of the solutions involve changing the code in a template or the core files of the content management system itself, a page speed plugin will be of very little use.
There are many resources to help understand solutions. But most solutions require the assistance of a developer who feels comfortable updating and changing core files in your content management system.
Fixing Core Web Vitals issues can be difficult. WordPress, Drupal, and other content management systems (CMS) were not built to score well for Core Web Vitals.
It is important to note that the process for improving Core Web Vitals involves changing the coding at the core of WordPress and other CMS.
Essentially, improving Core Web Vitals requires making a website do something that it was never intended to do when the developers created a theme or CMS.
The purpose of a Core Web Vitals audit is to identify what needs fixing and handing that information over to a developer who can then make the necessary changes.
What Are Core Web Vitals?
Core Web Vitals are consist of three metrics that collectively identify how fast the most important part of your page loads, how fast a user can interact with the page (example: click a button), and how fast it takes for the web page to become stable without page elements shifting around.
There are:
- Largest Contentful Paint (LCP).
- First Input Delay (FID).
- Cumulative Layout Shift (CLS).
There are two kinds of scores for the Core Web Vitals:
- Lab data.
- Field data.
Lab Data
Lab data is what is generated when you run a page through Google Lighthouse or in PageSpeed Insights.
Lab data consists of scores generated through a simulated device and Internet connection. The purpose is to give the person working on the site an idea of what parts of the Core Web Vitals need improvement.
The value of a tool like PageSpeed Insights is that it identifies specific code and page elements that are causing a page to score poorly.
Field Data
Field Data are actual Core Web Vitals scores that have been collected by Google Chrome browser for the Chrome User Experience Report (also known as CrUX).
The Field data is available in Google Search Console under the Enhancements tab via the link labeled Core Web Vitals (field data can be accessed via this link, too) https://search.google.com/search-console/core-web-vitals.
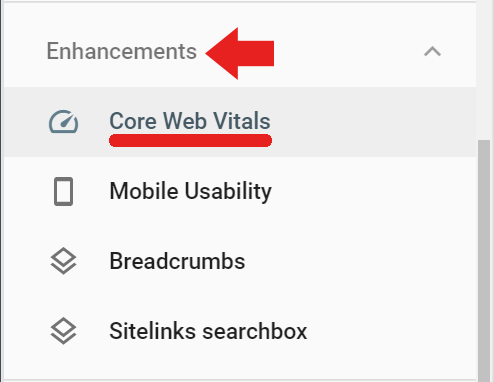
The field data reported in Google Search Console comes from visited pages that have had a minimum amount of visits and measurements. If Google doesn’t receive enough scores then Google Search Console will not report that score.
Screaming Frog for Core Web Vitals Audit
Screaming Frog version 14.2 now has the ability to display a pass or fail Core Web Vitals assessment. You need to connect Screaming Frog to the PageSpeed Insights API (get an API key here) via a key.
To register your Page Speed Insights API key with Screaming Frog, first navigate to Configuration > API Access > PageSpeed Insights
There, you will see a place to enter your API key and connect it to the service.
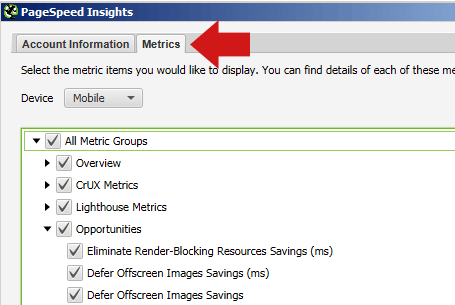
In the same PageSpeed Insights popup, you can also select the Metrics tab and tick off the boxes indicating what metrics you’d like to have reported.
Be sure to select Mobile for the device as that’s the metric that matters for ranking purposes.
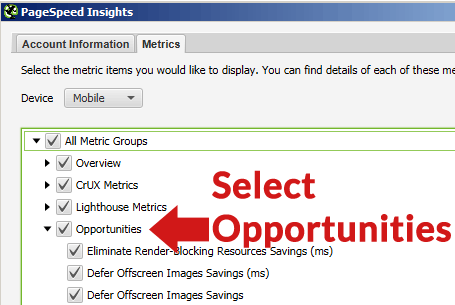
If you select the Opportunities tab, after the crawl Screaming Frog will show you a list of different kinds of improvements (like defer offscreen images, remove unused CSS, etc.).
 Note Before Crawling
Note Before Crawling
There is generally no need to crawl an entire site and produce an exhaustive page-by-page accounting of what’s wrong with every single page of the website.
Before crawling, you may want to consider crawling a representative set of pages. To do this, first select a group of pages that represent the types of pages common to each section or category of the website. Create a spreadsheet, text file list, or manually paste the URLs in using the Upload tab in Screaming Frog.
Most sites contained pages and posts created with similar page structure and content. For example, all the pages in a “news” category are going to be fairly similar, pages in a “reviews” category are also going to be similar to each other.
You can save time by crawling a representative group of pages in order to identify issues common across individual categories as well as problems common to all pages sitewide that need fixing.
Because of those similarities, the issues discovered are going to be similar. It may only be necessary to crawl a handful of representative pages from each type of category in order to identify what kinds of issues are specific to each of those sections.
The kinds of things that are being fixed are typically sitewide issues that are common across the entire site, like unused CSS that is loaded from every page or Cumulative Layout Shift caused by an ad unit located in the left-hand area of the web pages.
Because modern websites are templated, the fixes will happen at the template level or with custom coding in the stylesheet, etc.
Crawl the Site With Screaming Frog
Once the URLs are fully crawled, you can click on the PageSpeed tab and read all the recommendations and view the pass/fail notations for the various metrics.
Zoom In on URL Opportunities
A useful feature in the Screaming Frog Core Web Vitals Audit is the ability to select a URL from the list of URLs in the top pane and then see the opportunities for improvement in the bottom pane of the Screaming Frog display screen.
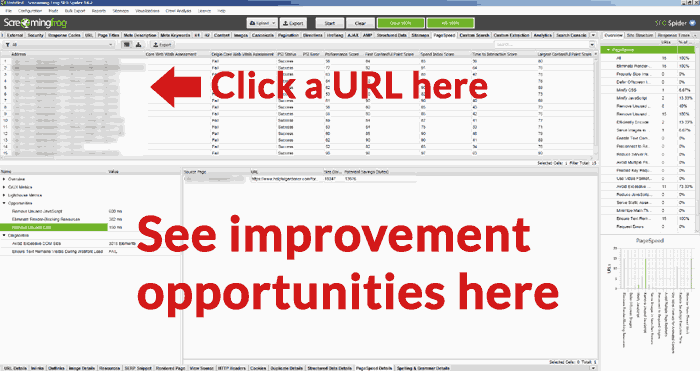
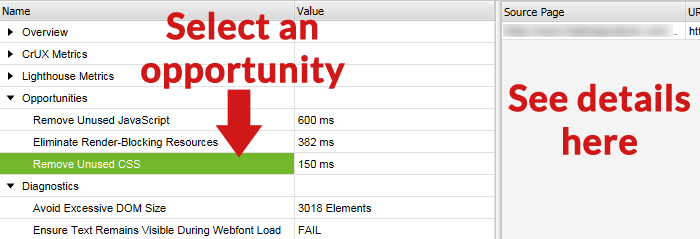
Below is a screenshot of the bottom screen, with an opportunity selected and the details of that improvement opportunity in the right-hand pane.
Official Google Tool
Google has published a tool that can provide an audit. It’s located here: https://web.dev/measure/
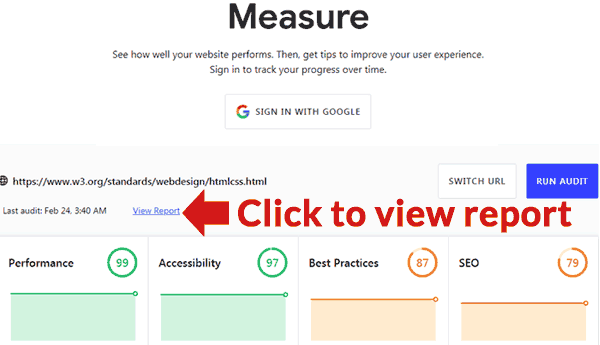
Insert a URL for an overview of the page performance. If you’re signed in Google will track the page for you over time. Clicking the View Report link will open a new page containing a report detailing what is wrong and links to guides that show how to fix each problem.
Image Credits
Featured Image: Paulo Bobita
All screenshots taken by author
