

Optimizing your website for traffic, revenue, and conversion is one of the most essential parts of SEO.
In 2021, success means going beyond having a neat and glossy design that sometimes can be a hindrance in terms of how search engines view and crawl your website.
Conventional flat site structures are always popular.
But last year Google’s John Muller, in a Webmaster Hangout, did hint a hierarchical site architecture could provide Google better indicators on:
- What the pages on your website mean.
- How each page is related and connected.
With differences in design and website structure principles, a designer and an SEO pro’s opinions can vary considerably.
Striking a balance between a visually aesthetic website for customers and a structure architected for search engine visibility should be the ultimate goal.
And having an organized website structure is incredibly essential for SEO.
Without creating something that makes logical sense, your other SEO, content, and even design efforts may be for nothing.
A good website structure should have a significant impact on SEO traffic and conversion.
It should also help your whole organization engage better with users and create an experience aligned with your business goals, product, and service structure.
In this article, I share some key points to consider as to how website structure affects SEO.
1. Site Crawlability
Site crawlability is one of the most important factors when it comes to website structure.
Crawlability refers to a search engine’s ability to crawl through your website’s entire text content to figure out what your website is all about.
Part of this process is navigating through subpages and particular topics to understand the website as a whole.
A webpage has to take a visitor someplace else within the website, from one page to another, to be considered crawlable.
Search engine robots are responsible for website crawling.
An important tenet of good website crawlability is that there are no dead ends while crawling through your website.
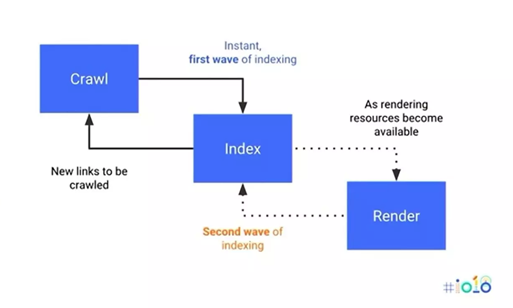
Make a concerted effort to include internal links on every page, which creates a bridge from one part of your website to another.
Breadcrumbs, schema, and structured data formats all help here.
Ensure you know and track your Google crawl budget, too.
2. URL Structure
One of the essential factors relating to how website structure affects SEO comes back to the URL structure.
URLs are also the building blocks of an effective site hierarchy, passing equity through your domain and directing users to their desired destinations.
The best URL structures should be easy to read by a user and a search engine and contain target queries, so they are content-rich.
Effective structures replicate logic across your whole website and submitting an XML sitemap to search engines with all of the most important URLs you want to rank for also helps.
Try to keep URLs simple and don’t over complicate them with too many parameters.
3. HTTP, HTTPs, HTTP2
HTTPS ensures your website security, and as Google continues to make it part of the user experience having a secure site can also help boost your rankings.
This is why more than 50% of websites worldwide are using HTTPS already.
Switching to HTTPS has multiple benefits in addition to better rankings.
- Better user experience.
- Protection of your users’ information.
- AMP implementation – only viable with HTTPS.
- PPC campaign effectiveness.
- Improved data in Google Analytics.
As of November 2020, Google will start crawling some sites over HTTP/2.
4. Internal Linking
The basics of proper navigation dictate that users should get from one page to another without any difficulties.
If your website is large and has many pages, the challenge is making these pages accessible with only a few clicks, using navigation alone.
Usability experts suggest that it should only take three clicks to find any given page, but use this advice as a guideline instead of a rule.
Internal linking helps users and search engines discover a page, and much like a messaging house build helps provide a flow between content and pages.
Pages that are not linked are harder for search engines to crawl.
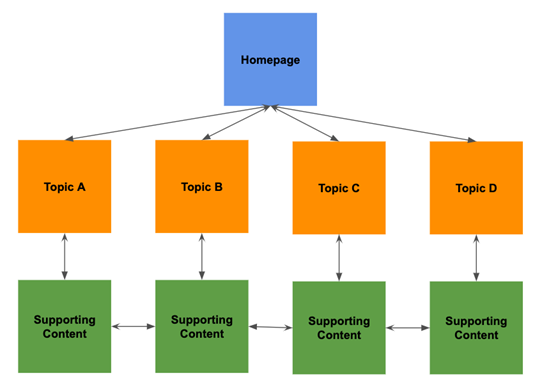
Categorize and organize links in a way that won’t wreck your website structure.
Internal linking works by using keywords within your content and linking them to another relevant piece of content on your website.
The advantages of consciously using internal links for SEO are numerous:
- Internal linking allows search engines to find other pages through keyword-rich anchors.
- Internal links decrease page depth.
- Internal linking gives users an easier way to access other content, resulting in a better user experience.
- Search engines give greater value to internal links regarding ranking on search engine results pages (SERPs).
Frequently, people will link back to old content through the use of internal links.
However, most people rarely do the reverse – going back through old content to link to newer content.
Close the loop by making sure both pieces are connected through the use of internal links.
5. Key Content & Keywords
Content and keyword research are fundamental parts of SEO and should be an essential part of how you build and structure your website from the get-go.
Ensuring this is done ensures your understanding of your target audience, search behavior, and competitive topics are built into your website structure and layout.
The best websites ensure they have provided a great user and a great search engine friendly experience by ensuring their website’s most crucial content is central to the structure and is of the highest quality.
6. Duplicate Content
Duplicate content is harmful to SEO because Google interprets it as spam.
A focus on high-quality and unique content on the SERP clearly defines how your website must be structured for ideal SEO.
Google’s Search Console is a useful tool for finding and eliminating duplicate content on your website.
It may be possible to repost duplicate content on LinkedIn or Medium but do so with caution.
As a more general rule, don’t post duplicate content on your website or anyone else’s.
7. Navigation & User Experience
The usability standards that today’s websites are held to are much stricter than in the early days of the Internet.
If a visitor comes across a poorly built website, they will avoid interacting with it further.
Additionally, nobody wants to waste their time on a website where they’re unsure what to do next.
If a visitor can’t figure out how to find the information they’re after they will seek it out on a competitor’s website.
And bad user experience hurts SEO.
How searchers interact with a website is interpreted by Google for future search results.
Click-through rate, time spent on site, and bounce rate are all signaling factors to Google’s algorithm.
Statistics indicating a positive experience validates the search results to Google.
Statistics showing a negative experience tells Google the page may not be the most relevant or useful for that query, and Google will adjust the search results accordingly.
The basics of providing a good user experience include:
- Aligning click-through with expectations.
- Making desired information easy to find.
- Ensuring that navigation makes sense to the point of intuitiveness.
Run some tests with unbiased visitors to determine just how usable your website actually is and ensure you determine how real users are interacting with your website.
8. Core Web Vitals & User Experience
Core Web Vitals are part of Google’s page experience update, and when optimizing images, in particular, they could impact rank.
The shift in emphasis on CLS (Cumulative Layout Shift) and the measurement of content and visual content load jumps is something website builders, designers, and SEO pros – together – should be working on.
Core Web Vitals could become one of the ranking factors in 2021, and at the moment, less than 15% of sites meet benchmark standards.
Google has given website owners and SEO professionals a heads up to prepare for this update, so now is an excellent time to take action in advance.
9. Mobile
Often associated with design, ensuring your website is structured for mobile viewers coming from different devices is now an essential part of a website build.
The amount of work involved can depend on your developer resources, IT expertise, and business models – especially if your site is ecommerce related.

On the Google Search Central blog, Google suggests that going mobile will likely cost time and money if you had not considered this when you built your website.
This is especially the case for sites built with flash or that use old ecommerce platforms.
10. Speed & Performance
If your website build and structure does not favor a fast user experience, then your SEO and bottom-line results will nosedive.
Slow site and page speeds, unresponsive pages, and anything that “takes time” for the user damages all the hard work done by developers, content creators, and SEO pros.
A one-second delay in page load time can mean fewer page views and traffic and a significant drop in conversions, all alongside a miserable user.
Ensure that you are liaising with your designers and IT departments to choose the right mobile design and website structure – for example, responsive web design – and identify all the pros and cons to avoid high costs and costly mistakes.
Conclusion
For best SEO results, ensure your website is structured in the most appropriate and hierarchical format for your users and your business.
Make sure it is architected for search readability.
Engage with your website designers at the time of build, not after.
Even at the beginning stages of a website’s conceptualization, it’s essential to plan ahead for content to come.
It’s not hard to see how website structure affects SEO.
Ensure that you align your website architecture and design so your SEO efforts begin well and end well!
More Resources:
- Could This Be The Google Navboost Patent?
- The 11 Most Important Parts of SEO You Need to Get Right
- What Is Website Taxonomy (a.k.a. URL Taxonomy)
- Advanced Technical SEO: A Complete Guide
Image Credits
All screenshots taken by author, November 2020
