

One surefire way to help clients gain more SEO traffic is to redirect valuable URLs that end up in 404s to equivalent ones.
These URLs generally still get traffic, have valuable external links coming in or both.
One lazy and ineffective approach to map 404 URLs is to redirect all of them to the home page or a dynamic search result. 🤦
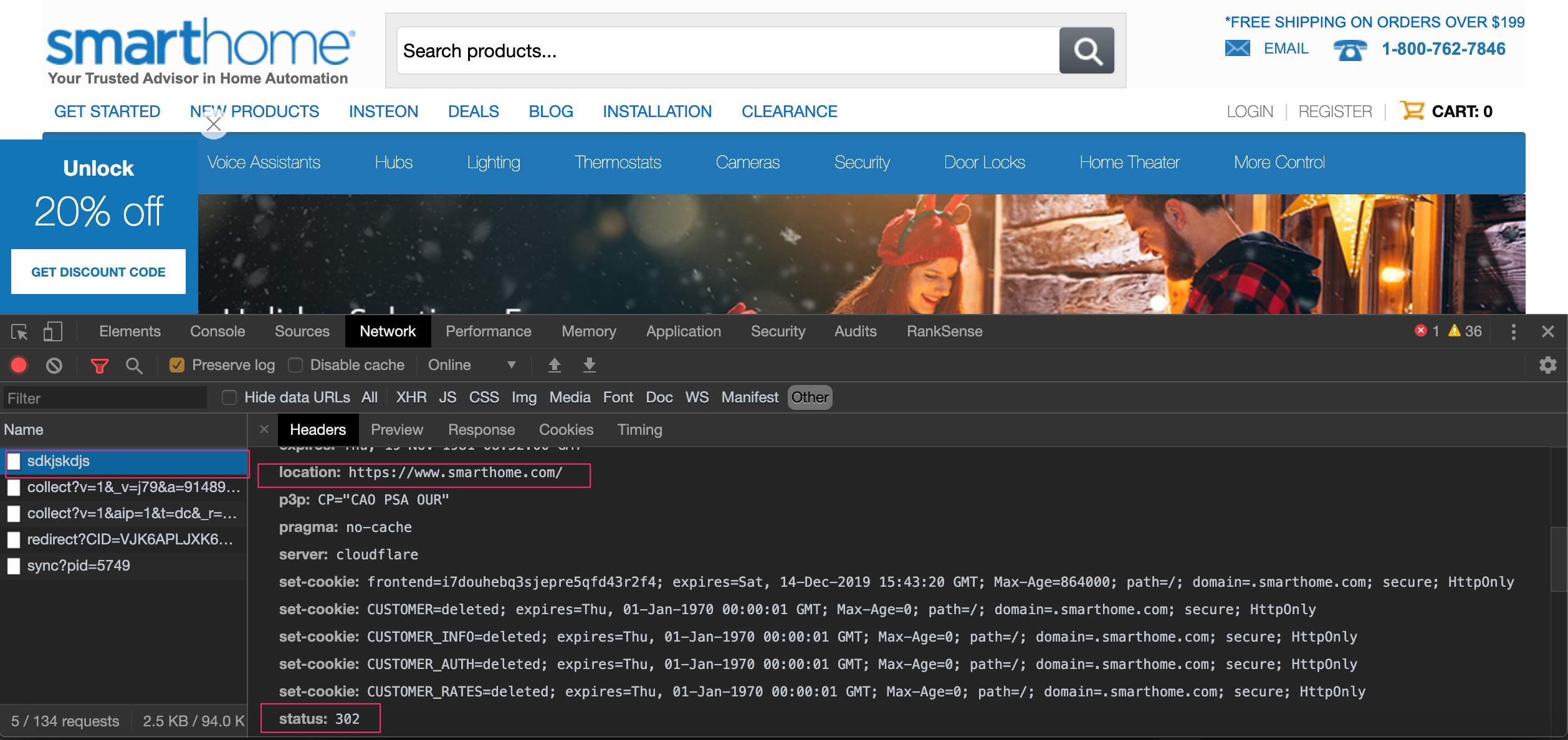
For example, Smarthome 302 redirects non-existing pages to its home page. This type of redirection is generally flagged as soft 404 errors in Google Search Console.
The correct approach is to map each one individually to an equivalent page if such a page exists.
However, this process can be very tedious, time-consuming, and expensive if you need to do it manually.
Oftentimes, you need to rely on the default internal search engine of the site, which is rarely any good.
In this column, we will learn how to automate this valuable technique using a neural matching approach.
Here is our plan of action:
- We will collect two lists of URLs to map: one with the 404 URLs and one with the website’s canonical URLs.
- We will convert the URLs to phrases to prepare them for our neural matching process.
- We will use a Universal Sentence Encoder approach that leverages neural networks.
- I will explain some of the advanced concepts that make this possible.
- I will also share community projects and resources to learn more.
Downloading URL Sets
There are many ways to get 404 URLs. You could run a website crawl, download 404s from Google or Bing Search Consoles, etc.
One of my favorite places to get 404 URLs, is the Ahrefs Broken Backlinks tool because it filters 404s to pages with external links.
Google Search Console will likely have far more 404s to map, though. If you rather map all 404s and have more than one thousand to download, you might want to consider using our Cloudflare app which has no such limits.
You can export up to 100,000 URLs or as many as you have when you connect it to Google Drive.
Next, you need a set of all valid website URLs, preferably canonical URLs.
One simple way to get such a list is to download the XML sitemap URLs.
If your client doesn’t have XML sitemaps, you can perform a traditional SEO crawl to get the URLs.
If you prefer code, you can find some you can adapt from my article on XML sitemaps.
Uploading the URL Sets to Google Drive
There are different ways to access files from Google Colaboratory, including uploading them directly from your hard drive. My favorite option lately is to upload them to Google Drive and access them from Colab.
If you get a shareable link from Google Drive, you can use the code below to download the files to your Google Colab environment.
#!pip install gdown
#https://pypi.org/project/gdown/
import gdown
canonical_urls="Google Drive link to the canonicals URLs set"
error_urls="Google Drive link to the 404 URLs set"
gdown.download(canonical_urls, output="canonicals-urls.csv", quiet=False)
gdown.download(error_urls, output="404-urls.csv", quiet=False)If your files need to remain private, the following code might be a better option.
from google.colab import drive
drive.mount("/drive")
%cd '/drive/My Drive/'
!cp canonicals-urls.csv 404-urls.csv /contentConverting URL Paths to Phrases
We could try to match the pages using their content, but 404 pages don’t have content you could use for matching purposes.
Patrick Stox has shared a clever approach using the Wayback Machine. In practice, his technique works for sites that have good coverage, which is the case if they are popular. However, for many sites that we work with, this hasn’t been as effective as we would want.
A key idea that has worked well for us is to match 404 pages with relevant pages on the site by leveraging the rich information present in most URLs.
This approach is very simple and works really well in practice. The notable exception is when sites choose terrible URLs, say they only include numbers.
We follow two simple steps:
- Get just the path of the URLs.
- Convert slashes, underscores, and hyphens to spaces to make extract the text in the URLs.
Here is the code for that:
import pandas as pd
#load URL sets to data frames
df_404s = pd.read_csv("404-urls.csv")
df_canonicals = pd.read_csv("canonical-urls.csv")
import re
#replace / - _ and .html with spaces
df_404s["phrase"] = df_404s["404 url"].apply(lambda x: re.sub(r"[/_-]|\.html", " ", x))
df_canonicals["phrase"] = df_canonicals["canonical url"].apply(lambda x: re.sub(r"[/_-]|\.html", " ", x))Here is what the transformation looks like.


The Universal Sentence Encoder
Now we are going to get to the fun part! We are going to leverage deep learning for another powerful use case: Semantic Textual Similarity (STS). We will leverage STS to match URLs by the phrases included in them.
Please feel free to refer to my previous deep learning articles to get caught up in the concepts we will revisit here.
For our matching task, we will leverage Google’s Universal Sentence Encoder.
From their description:
“The Universal Sentence Encoder (USE) encodes text into high-dimensional vectors that can be used for text classification, semantic similarity, clustering and other natural language tasks.
The model is trained and optimized for greater-than-word length text, such as sentences, phrases or short paragraphs. It is trained on a variety of data sources and a variety of tasks with the aim of dynamically accommodating a wide variety of natural language understanding tasks. The input is variable length English text and the output is a 512 dimensional vector. We apply this model to the STS benchmark for semantic similarity, and the results can be seen in the example notebook made available. The universal-sentence-encoder model is trained with a deep averaging network (DAN) encoder.”
We are using this approach because it is more powerful than naive textual matching. The USE allows matching pages/phrases with equivalent meaning, even if it is not exactly written in the same way. You can even match phrases when they are written in different languages.
Here is an example code snippet of what it looks like in action:
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder/3")
embeddings = embed([
"The quick brown fox jumps over the lazy dog.",
"I am a sentence for which I would like to get its embedding"])["outputs"]
print embeddings
# The following are example embedding output of 512 dimensions per sentence
# Embedding for: The quick brown fox jumps over the lazy dog.
# [-0.03133016 -0.06338634 -0.01607501, ...]
# Embedding for: I am a sentence for which I would like to get its embedding.
# [0.05080863 -0.0165243 0.01573782, ...]Basically, USE allows us to encode full sentences in a virtual space (remember the GPS analogy I covered in my first deep learning article?) so that similar phrases are close and completely different ones are far apart.
You can use the USE to solve a variety of natural language problems. For our specific problem, the most appropriate task is semantic textual similarity.
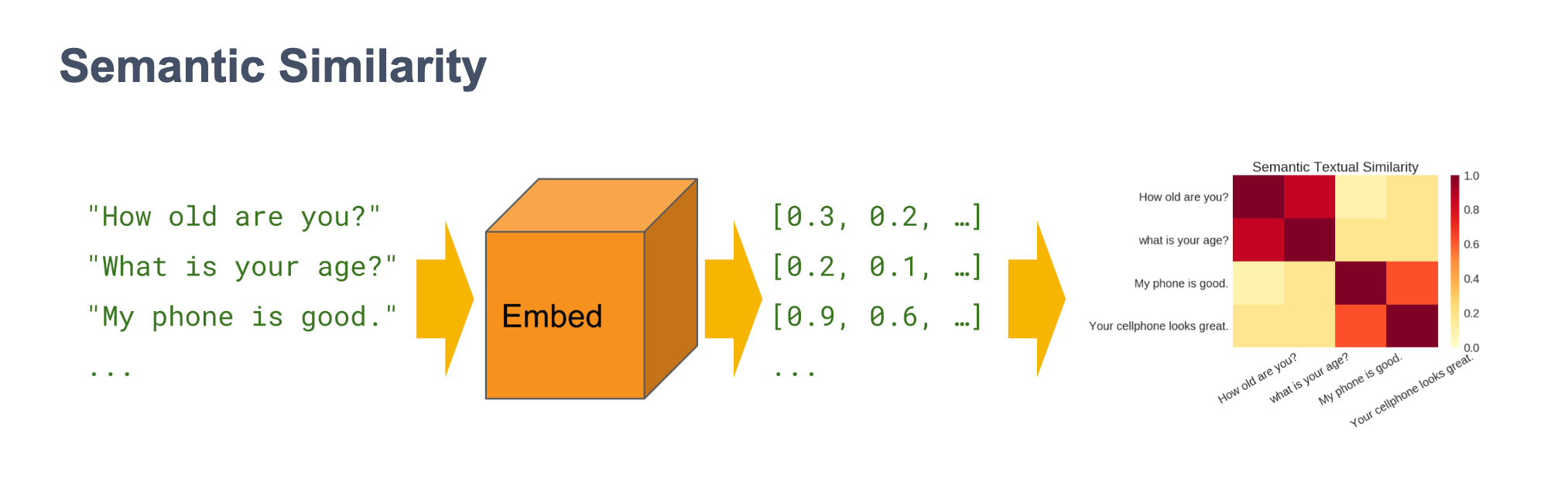
When we use semantic similarity, we want to match sentences that mean exactly the same but might be phrased differently.
Let’s get started.
Please go to the USE page and click to open the example Google Colab notebook.
Use the File menu to save a copy in your Google Drive. Change the Runtime Type to GPU.
Then click on the Runtime menu to Run all Cells.
When you scroll down through the notebook, you can find this interesting visualization almost close to the end.

This is a heatmap matrix showing the most similar phrases in hot red.
You can see how the phrases about phones, weather, health, and age get clustered together. This is a very powerful tool!
Preparing our Phrase Corpus
Now, we let’s add some custom code to the notebook to leverage this technique with the phrases we generated from the URLs we uploaded before.
# Here we combine both lists into a single set of unique phrases
messages = set(df_404s["phrase"].to_list() + df_canonicals["phrase"].to_list())
messages = list(messages)[:-1]
similarity_input_placeholder = tf.placeholder(tf.string, shape=(None))
similarity_message_encodings = embed(similarity_input_placeholder)
with tf.Session() as session:
session.run(tf.global_variables_initializer())
session.run(tf.tables_initializer())
# We are truncating the messages list to 15 to simplify the visualization
run_and_plot(session, similarity_input_placeholder, messages[:15],
similarity_message_encodings)These simple code changes help us cluster our own URLs/phrases. Here is what our own visualization looks like.

The products in our example set of URLs are very similar, so as a result of this, there are a lot more red squares than yellow.
When results are this close, we generate a top 5 list for each match and give them to one of our team members to review manually and select the best match. This approach still cuts a lot of manual time.
Calculating Similarity Suggestions
The heat map above, while a great visual, won’t help us get actual suggestions for each 404 URL We are going to create a custom function for this.
import heapq
TOP_N = 5
BEST_ONLY = False
THRESHOLD_PROBABILITY = 0.65
def get_similarity_suggestion(phrase, no_percentage=False):
graph = tf.Graph()
with tf.compat.v1.Session(graph = graph) as session:
embed = hub.Module(module_url)
similarity_input_placeholder = tf.compat.v1.placeholder(tf.string, shape=(None))
similarity_message_encodings = embed(similarity_input_placeholder)
session.run(tf.compat.v1.global_variables_initializer())
session.run(tf.compat.v1.tables_initializer())
to_find_embeddings = session.run(similarity_message_encodings, feed_dict={similarity_input_placeholder: [phrase]})
result = np.inner(message_embeddings, to_find_embeddings)
top_N_indexes = heapq.nlargest(TOP_N, range(len(result)), result.take)
if BEST_ONLY:
top_N_indexes = [index for index in top_N_indexes if result[index] > THRESHOLD_PROBABILITY]
to_return = list()
for i in top_N_indexes:
matched = df_404s.iloc[i]
if no_percentage:
to_return.append(matched['phrase'])
else:
to_return.append([str(matched['phrase']), '%.2f' % float(result[i]*100), i])
return to_return
#Here we test one of the 404 phrases
test_phrase = df_404s["phrase"].iloc[0] # -> ' shop by collection wonderland rainbow'
results = get_similarity_suggestion(test_phrase, no_percentage=False)
print(results)
# This is what the suggested matches looks like.
#[[' shop by collection wonderland rainbow', '21.87', 0],
# [' catalog gold earrings gold cascade earrings p 200 ', '16.33', 1],
# [' shop by collection silver rain silver jewelry 1 ', '1.48', 2]]
#You can iterate this line over all 404 urls to get the top matching suggestions for each url.
#Please try this as a homework exercise
#
#results = get_similarity_suggestion(test_phrase, no_percentage=False)Here we have a bit of TensorFlow code where we pass an encoded phrase to the USE model and get the embeddings of the closest matches. It requires some explanation.
This code passes the encoded phrase to the USE and get’s back all the matching embeddings.
to_find_embeddings = session.run(similarity_message_encodings, feed_dict={similarity_input_placeholder: [phrase]})
As the embeddings are simply vectors, it is possible to find the closest ones by computing the dot product.
result = np.inner(message_embeddings, to_find_embeddings)
The dot product is one of the techniques you can use to measure the distance between two vectors.
You might want to check this Wikipedia article to learn more about how it works.
The remainder of the code limits the matches to the top 5.
Community Projects & Resources to Learn More
This past month, I’ve been absolutely blown away by the projects shared by the community.
First, let me give a big shoutout to Kristin Tynski who improved upon my intent classification work to come up with a faster, better and cheaper technique.
Dan Leibson from LocalSEOGuide shared a script that automates keyword categorization built using BigQuery, Python, and Posgres.
Hülya Çoban put together an amazing machine learning model to predict page speed scores.
More Resources:
- How to Use BERT to Generate Meta Descriptions at Scale
- How to Generate Text from Images with Python
- How to Use Python to Analyze SEO Data: A Reference Guide
Image Credits
Semantic Similarity Image: TensorFlow Hub
All screenshots taken by author, December 2019
