

In the last few months, Google has announced two systems that are in production in Google search and are also open source. Anybody can see how they work.
- You can guess one of them as the announcement is recent: BERT.
- The second one is their robots.txt parser.
Google open-sourcing parts of Google Search is not something you would have considered possible even a year ago.
As expected, there is no shortage of ultimate guides to optimize your site for BERT. You can’t.
BERT helps Google better understand the intent of some queries and has nothing to do with page content per their announcement.
If you’ve read my deep learning articles, you should not only have a practical understanding of how BERT works but also how to use it for SEO purposes – specifically, for automating intent classification.
Let’s expand this and cover another use case: state of the art text summarization.
We can use automated text summarization to generate meta descriptions that we can populate on pages that don’t have one.
In order to illustrate this powerful technique, I’m going to automatically download and summarize my last article and as usual, I’ll share Python code snippets that you can follow along and adapt to your own site or your clients’.
Here is our plan of action:
- Discuss automated text summarization.
- Learn how to find state-of-the-art (SOTA) code that we can use for summarization.
- Download the text summarization code and prepare the environment.
- Download my last article and scrape just the main content on the page.
- Use abstractive text summarization to generate the text summary.
- Go over the concepts behind PreSumm.
- Discuss some of the limitations.
- Finally, I’ll share resources to learn more and community projects.
Text Summarization to Produce Meta Descriptions
When we have pages rich in content, we can leverage automated text summarization to produce meta descriptions at scale.
There are two primary approaches for text summarization according to the output:
- Extractive: We split the text into sentences and rank them based on how effective they will be as a summary for the whole article. The summary will always contain sentences found in the text.
- Abstractive: We generate potentially novel sentences that capture the essence of the text.
In practice, it is generally a good idea to try both approaches and pick the one that gets the best results for your site.
How to Find State of the Art (SOTA) Code for Text Summarization
My favorite place to find cutting edge code and papers is Papers with Code.
If you browse the State-of-the-Art section, you can find the best performing research for many categories.
If we narrow down our search to Text Summarization, we can find this paper: Text Summarization with Pretrained Encoders, which leverages BERT.
From there, we can conveniently find links to the research paper, and most importantly the code that implements the research.
![]()
It is also a good idea to check the global rankings often in case a superior paper comes up.
Download PreSum & Set up the Environment
Create a notebook in Google Colab to follow the next steps.
The original code found in the researcher’s repository doesn’t make it easy to use the code to generate summaries.
You can feel the pain just by reading this Github issue. 😅
We are going to use a forked version of the repo and some simplified steps that I adapted from this notebook.
Let’s first clone the repository.
!git clone https://github.com/mingchen62/PreSumm.gitThen install the dependencies.
!pip install torch==1.1.0 pytorch_transformers tensorboardX multiprocess pyrougeNext, we need to download the pre-trained models.
Then, we need to uncompress and move them to organized directories.
After this step, we should have the summarization software ready.
Let’s download the article we want to summarize next.
Create a Text File to Summarize
As I mentioned, we will summarize my last post. Let’s download it and clean the HTML so we are only left with the article content.
First, let’s create the directories we need to save our input file and also the results from the summaries.
!mkdir /content/PreSumm/bert_data_test/
!mkdir /content/PreSumm/bert_data/cnndm
%cd /content/PreSumm/bert_data/cnndmNow, let’s download the article and extract the main content. We will use a CSS selector to scrape only the body of the post.
The text output is in one line, we will split it with the next code.
text = text.splitlines(True) #keep newlinesI removed the first line that includes the code for the sponsored ad and the last few lines that include some article meta data.
text = text[1:-5] #remove sponsor code and end meta dataFinally, I can write down the article content to a text file using this code.
with open("python-data-stories.txt", "a") as f:
f.writelines(text)After this, we are ready to move to the summarization step.
Generating the Text Summary
We will generate an abstractive summary, but before we can generate it, we need to modify the file summarize.py.
In order to keep things simple, I created a patch file with the changes that you can download with the following code.
!wget https://gist.githubusercontent.com/hamletbatista/f2741a3a74e4c5cc46ce9547b489ec36/raw/ccab9cc3376901b2f6b0ba0c4bbd03fa48c1b159/summarizer.patchYou can review the changes it is going to make here. Red lines will be removed and green ones will be added.
I borrowed these changes from the notebook linked above, and they enable us to pass files to summarize and see the results.
You can apply the changes using this.
!patch < summarizer.patchWe have one final preparatory step. The next code downloads some tokenizers needed by the summarizer.
import nltk
nltk.download('punkt')Finally, let’s generate our summary with the following code.
#CNN_DM abstractive
%cd /content/PreSumm/src
!python summarizer.py -task abs -mode test -test_from /content/PreSumm/models/CNN_DailyMail_Abstractive/model_step_148000.pt -batch_size 32 -test_batch_size 500 -bert_data_path ../bert_data/cnndm -log_file ../logs/val_abs_bert_cnndm -report_rouge False -sep_optim true -use_interval true -visible_gpus -1 -max_pos 512 -max_src_nsents 100 -max_length 200 -alpha 0.95 -min_length 50 -result_path ../results/abs_bert_cnndm_sampleHere is what the partial output looks like.
Now, let’s review our results.
!ls -l /content/PreSumm/resultsThis should show.
Here is the candidate summary.
!head /content/PreSumm/results/abs_bert_cnndm_sample.148000.candidate[UNK] [UNK] [UNK] : there are many emotional and powerful stories hidden in gobs of data just waiting to be found<q>she says the campaign was so effective that it won a number of awards , including the cannes lions grand prix for creative data collection<q>[UNK] : we are going to rebuild a popular data visualization from the subreddit data is beautiful
Some tokens like [UNK] and <q> require explanation. [UNK] represents a word out of the BERT vocabulary. You can ignore these. <q> is a sentence separator.
How PreSumm Works
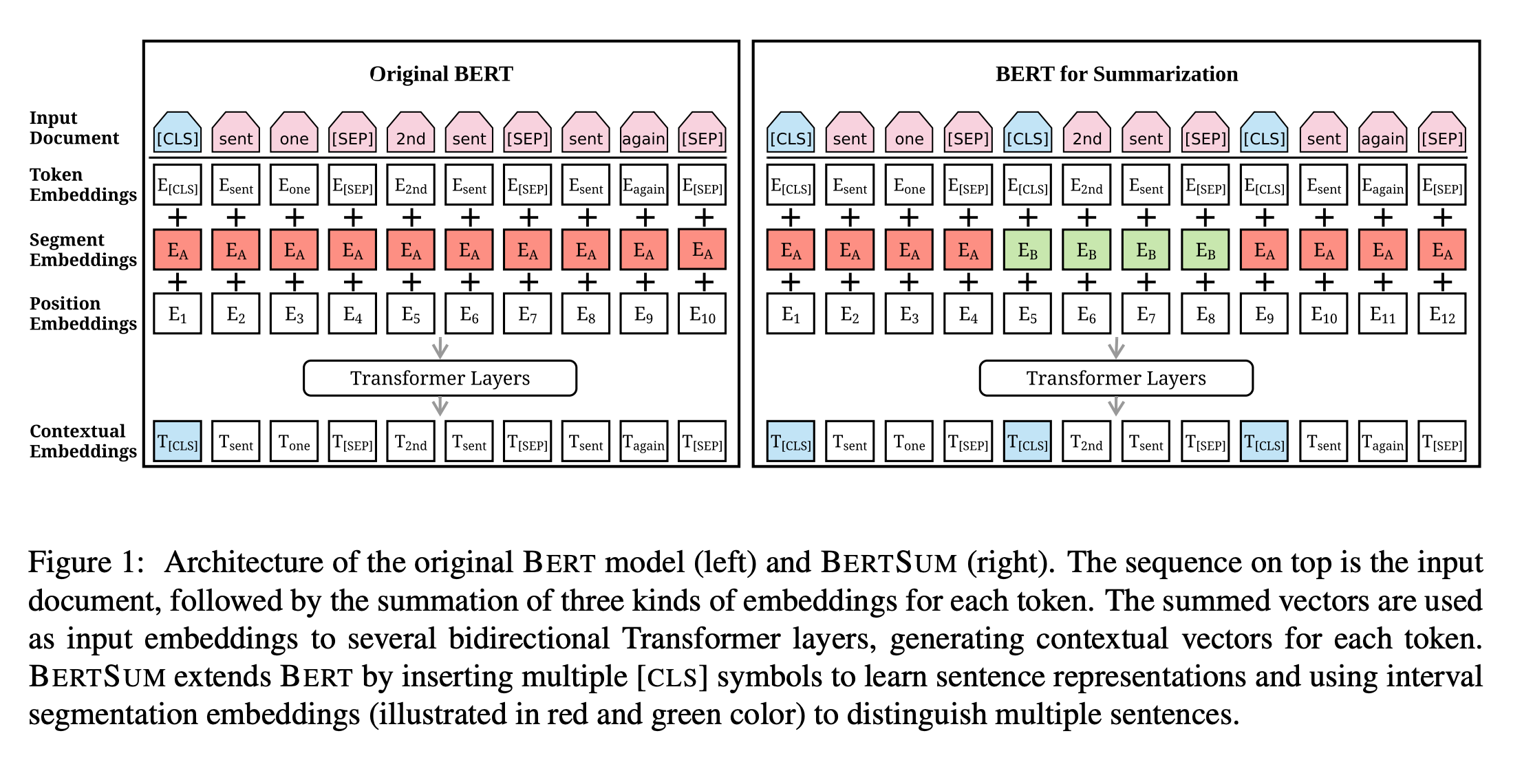
Most traditional extractive text summarization techniques rely on copying parts of the text that are determined to be good to include in the summary.
This approach while effective for many use cases, is rather limiting as it could be the case that there are no sentences useful to summarize the text.
In my previous deep learning articles, I compared a traditional/naive text matching approach with looking up business by their name in a street.
Yes, it works, but it is rather limiting when you compare it with what a GPS system allows you to do.
I explained the power of using embeddings relies on the fact that they operate like coordinates in space. When you use coordinates, as you do in the GPS system, it doesn’t matter how you name the thing (or what language you use to name it), it is still the same place.
BERT has the extra advantage that the same word can have completely different coordinates depending on the context. For example, the word “Washington” in Washington State and George Washington Bridge, means completely different things and would be encoded differently.
But, the most powerful advantage of BERT and similar systems is that the NLP tasks are not learned from scratch, they start from a pre-trained language model.
In other words, the model at least understands the nuances of the language like how to organize subjects, adverbs, prepositions, etc. before it is fined-tune on a specific task like answering questions.
The PreSumm researchers list three main contributions from their work in summarization:
- They adapted BERT neural architecture to easily learn full sentence representations. Think word embeddings for sentences so you can easily identify similar ones.
- They show clear benefits of leveraging pre-trained language models for summarization tasks. See my comments on why that is beneficial
- Their models can be used as building blocks for better summarization models.
PreSumm Limitations
This tweet highlights one of the clear limitations of PreSumm and similar systems that rely on pre-trained models. Their writing style is heavily influenced by the data used to train them.
PreSumm is trained on CNN and DailyMail articles. The summaries are not particularly good when used to generate summaries of fiction novel book chapters.
PreSumm: Text Summarization With Pretrained Encoders
"state-of-the-art results across the board in both extractive and abstractive settings"
abs: https://t.co/oNV5YmLC6n
(barebones) Colab: https://t.co/5K7UXUH7SLYou can really tell summarizers are trained on news datasets… pic.twitter.com/hsLVs3du2f
— Jonathan Fly 👾 (@jonathanfly) September 2, 2019
For now, the solution appears to be to retrain the model using datasets in your domain.
Resources to Learn More & Community Projects
This is a great primer on classical text summarization.
I covered text summarization a couple of months ago during a DeepCrawl webinar. At that time the PreSumm researchers released an earlier version of their work focused only on extractive text summarization. They called it BERTSum.
I had most of the same ideas, but it is interesting to see how fast they improved their work to cover both abstractive and extractive approaches. Plus achieve state of the art performance in both categories.
Amazing progress.
Talking about progress, the Python SEO community continues to blow me away with the cool new projects everybody is working on and releasing each month.
Here are some notable examples. Please feel free to clone their repositories, see what you can improve or adapt to your needs, and send your improvements back!
Bubbles: https://t.co/q1T7s0TW94
Extract Search Console data and displays it with Bokeh (by urls, by section with regex and by topic with TF-IDF clusterization). Finally it shows a table of opportunities that you can download (urls with high positions and low CTR) pic.twitter.com/CImGVkayVI— Natzir Turrado (@natzir9) October 29, 2019
este? https://t.co/1q7UaEstbi
— Natzir Turrado (@natzir9) October 29, 2019
Building a little crawler + monitoring content changes. Taking wayyy longer than expected, hopefully can share soonish!😅 pic.twitter.com/7hYewZsEBR
— Charly Wargnier 🇪🇺 (@DataChaz) October 29, 2019
More Resources:
- Google BERT Update – What it Means
- Automated Intent Classification Using Deep Learning
- Automated Intent Classification Using Deep Learning (Part 2)
Image Credits
All screenshots taken by author, October 2019
In-Post Image: Text Summarization with Pretrained Encoders
