
Do you find yourself doing the same repetitive SEO tasks each day or facing challenges where there are not tools that can help you?
If so, it might be time for you to learn Python.
An initial investment of time and sweat will pay off in significantly increased productivity.
While I’m writing this article primarily for SEO professionals who are new to programming, I hope that it’ll be useful to those who already have a background in software or Python, but who are looking for an easy-to-scan reference to use in data analysis projects.
Table of Contents
- Python fundamentals
- Data extraction
- Basic analysis
- Saving and exporting results
- Resources to learn more
Python Fundamentals
Python is easy to learn and I recommend you spend an afternoon walking over the official tutorial. I’m going to focus on practical applications for SEO.
When writing Python programs, you can decide between Python 2 or Python 3. It is better to write new programs in Python 3, but it is possible your system might come with Python 2 already installed, particularly if you use a Mac. Please also install Python 3 to be able to use this cheat sheet.
You can check your Python version using:
$python --version
Using Virtual Environments
When you complete your work, it is important to make sure other people in the community can reproduce your results. They will need to be able to install the same third-party libraries that you use, often using the exact same versions.
Python encourages creating virtual environments for this.
If your system comes with Python 2, please download and install Python 3 using the Anaconda distribution and run these steps in your command line.
$sudo easy_install pip $sudo pip install virtualenv $mkdir seowork $virtualenv -p python3 seowork
If you are already using Python 3, please run these alternative steps in your command line:
$mkdir seowork $python3 -m venv seowork
The next steps allow work in any Python version and allow you to use the virtual environments.
$cd seowork $source bin/activate (seowork)$deactivate
When you deactivate the environment, you are back to your command line, and the libraries you installed in the environment won’t work.
Useful Libraries for Data Analysis
Whenever I start a data analysis project, I like to have at a minimum the following libraries installed:
Most of them come included in the Anaconda distribution. Let’s add them to our virtual environment.
(seowork)$pip3 install requests (seowork)$pip3 install matplotlib (seowork)$pip3 install requests-html (seowork)$pip3 install pandas
You can import them at the beginning of your code like this:
import requests from requests_html import HTMLSession import pandas as pd
As you require more third-party libraries in your programs, you need an easy way to keep track of them and help others set up your scripts easily.
You can export all the libraries (and their version numbers) installed in your virtual environment using:
(seowork)$pip3 freeze > requirements.txt
When you share this file with your project, anybody else from the community can install all required libraries using this simple command in their own virtual environment:
(peer-seowork)$pip3 install -r requirements.txt
Using Jupyter Notebooks
When doing data analysis, I prefer to use Jupyter notebooks as they provide a more convenient environment than the command line. You can inspect the data you are working with and write your programs in an exploratory manner.
(seowork)$pip3 install jupyter
Then you can run the notebook using:
(seowork)$jupyter notebook
You will get the URL to open in your browser.
Alternatively, you can use Google Colaboratory which is part of GoogleDocs and requires no setup.
String Formatting
You will spend a lot of time in your programs preparing strings for input into different functions. Sometimes, you need to combine data from different sources, or convert from one format to another.
Say you want to programmatically fetch Google Analytics data. You can build an API URL using Google Analytics Query Explorer, and replace the parameter values to the API with placeholders using brackets. For example:
api_uri = "https://www.googleapis.com/analytics/v3/data/ga?ids={gaid}&"\
"start-date={start}&end-date={end}&metrics={metrics}&"\
"dimensions={dimensions}&segment={segment}&access_token={token}&"\
"max-results={max_results}"
{gaid} is the Google account, i.e., “ga:12345678”
{start} is the start date, i.e., “2017-06-01”
{end} is the end date, i.e., “2018-06-30”
{metrics} is for the list of numeric parameters, i.e., “ga:users”, “ga:newUsers”
{dimensions} is the list of categorical parameters, i.e., “ga:landingPagePath”, “ga:date”
{segment} is the marketing segments. For SEO we want Organic Search, which is “gaid::-5”
{token} is the security access token you get from Google Analytics Query Explorer. It expires after an hour, and you need to run the query again (while authenticated) to get a new one.
{max_results} is the maximum number of results to get back up to 10,000 rows.
You can define Python variables to hold all these parameters. For example:
gaid = "ga:12345678" start = "2017-06-01" end = "2018-06-30"
This allows you to fetch data from multiple websites or data ranges fairly easily.
Finally, you can combine the parameters with the API URL to produce a valid API request to call.
api_uri = api_uri.format( gaid=gaid, start=start, end=end, metrics=metrics, dimensions=dimensions, segment=segment, token=token, max_results=max_results )
Python will replace each place holder with its corresponding value from the variables we are passing.
String Encoding
Encoding is another common string manipulation technique. Many APIs require strings formatted in a certain way.
For example, if one of your parameters is an absolute URL, you need to encode it before you insert it into the API string with placeholders.
from urllib import parse url="https://www.searchenginejournal.com/" parse.quote(url)
The output will look like this: ‘https%3A//www.searchenginejournal.com/’ which would be safe to pass to an API request.
Another example: say you want to generate title tags that include an ampersand (&) or angle brackets (<, >). Those need to be escaped to avoid confusing HTML parsers.
import html title= "SEO <News & Tutorials>" html.escape(title)
The output will look like this:
'SEO <News & Tutorials>'
Similarly, if you read data that is encoded, you can revert it back.
html.unescape(escaped_title)
The output will read again like the original.
Date Formatting
It is very common to analyze time series data, and the date and time stamp values can come in many different formats. Python supports converting from dates to strings and back.
For example, after we get results from the Google Analytics API, we might want to parse the dates into datetime objects. This will make it easy to sort them or convert them from one string format to another.
from datetime import datetime
dt = datetime.strptime('Jan 5 2018 6:33PM', '%b %d %Y %I:%M%p')
Here %b, %d, etc are directives supported by strptime (used when reading dates) and strftime (used when writing them). You can find the full reference here.
Making API Requests
Now that we know how to format strings and build correct API requests, let see how we actually perform such requests.
r = requests.get(api_uri)
We can check the response to make sure we have valid data.
print(r.status_code) print(r.headers['content-type'])
You should see a 200 status code. The content type of most APIs is generally JSON.
When you are checking redirect chains, you can use the redirect history parameter to see the full chain.
print(r.history)
In order to get the final URL, use:
print(r.url)
Data Extraction
A big part of your work is procuring the data you need to perform your analysis. The data will be available from different sources and formats. Let’s explore the most common.
Reading from JSON
Most APIs will return results in JSON format. We need to parse the data in this format into Python dictionaries. You can use the standard JSON library to do this.
import json
json_response = '{"website_name": "Search Engine Journal", "website_url":"https://www.searchenginejournal.com/"}'
parsed_response = json.loads(json_response)
Now you can easily access any data you need. For example:
print(parsed_response["website_name"])
The output would be:
"Search Engine Journal"
When you use the requests library to perform API calls, you don’t need to do this. The response object provides a convenient property for this.
parsed_response=r.json()
Reading from HTML Pages
Most of the data we need for SEO is going to be on client websites. While there is no shortage of awesome SEO crawlers, it is important to learn how to crawl yourself to do fancy stuff like automatically grouping pages by page types.
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.searchenginejournal.com/')
You can get all absolute links using this:
print(r.html.absolute_links)
The partial output would look like this:
{'https://jobs.searchenginejournal.com/', 'https://www.searchenginejournal.com/what-i-learned-about-seo-this-year/281301/', …}
Next, let’s fetch some common SEO tags using XPATHs:
Page Title
r.html.xpath('//title/text()')
The output is:
['Search Engine Journal - SEO, Search Marketing News and Tutorials']
Meta Description
r.html.xpath("//meta[@name='description']/@content")
Please note that I changed the style of quotes from single to double or I’d get an coding error.
The output is:
['Search Engine Journal is dedicated to producing the latest search news, the best guides and how-tos for the SEO and marketer community.']
Canonical
r.html.xpath("//link[@rel='canonical']/@href")
The output is:
['https://www.searchenginejournal.com/']
AMP URL
r.html.xpath("//link[@rel='amphtml']/@href")
Search Engine Journal doesn’t have an AMP URL.
Meta Robots
r.html.xpath("//meta[@name='ROBOTS']/@content")
The output is:
['NOODP']
H1s
r.html.xpath("//h1")
The Search Engine Journal home page doesn’t have h1s.
HREFLANG Attribute Values
r.html.xpath("//link[@rel='alternate']/@hreflang")
Search Engine Journal doesn’t have hreflang attributes.
Google Site Verification
r.html.xpath("//meta[@name='google-site-verification']/@content")
The output is:
['NcZlh5TFoRGYNheLXgxcx9gbVcKCsHDFnrRyEUkQswY', 'd0L0giSu_RtW_hg8i6GRzu68N3d4e7nmPlZNA9sCc5s', 'S-Orml3wOAaAplwsb19igpEZzRibTtnctYrg46pGTzA']
JavaScript Rendering
If the page you are analyzing needs JavaScript rendering, you only need to add an extra line of code to support this.
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://www.searchenginejournal.com/')
r.html.render()
The first time you run render() will take a while because Chromium will be downloaded. Rendering Javascript is much slower than without rendering.
Reading from XHR requests
As rendering JavaScript is slow and time consuming, you can use this alternative approach for websites that load JavaScript content using AJAX requests.
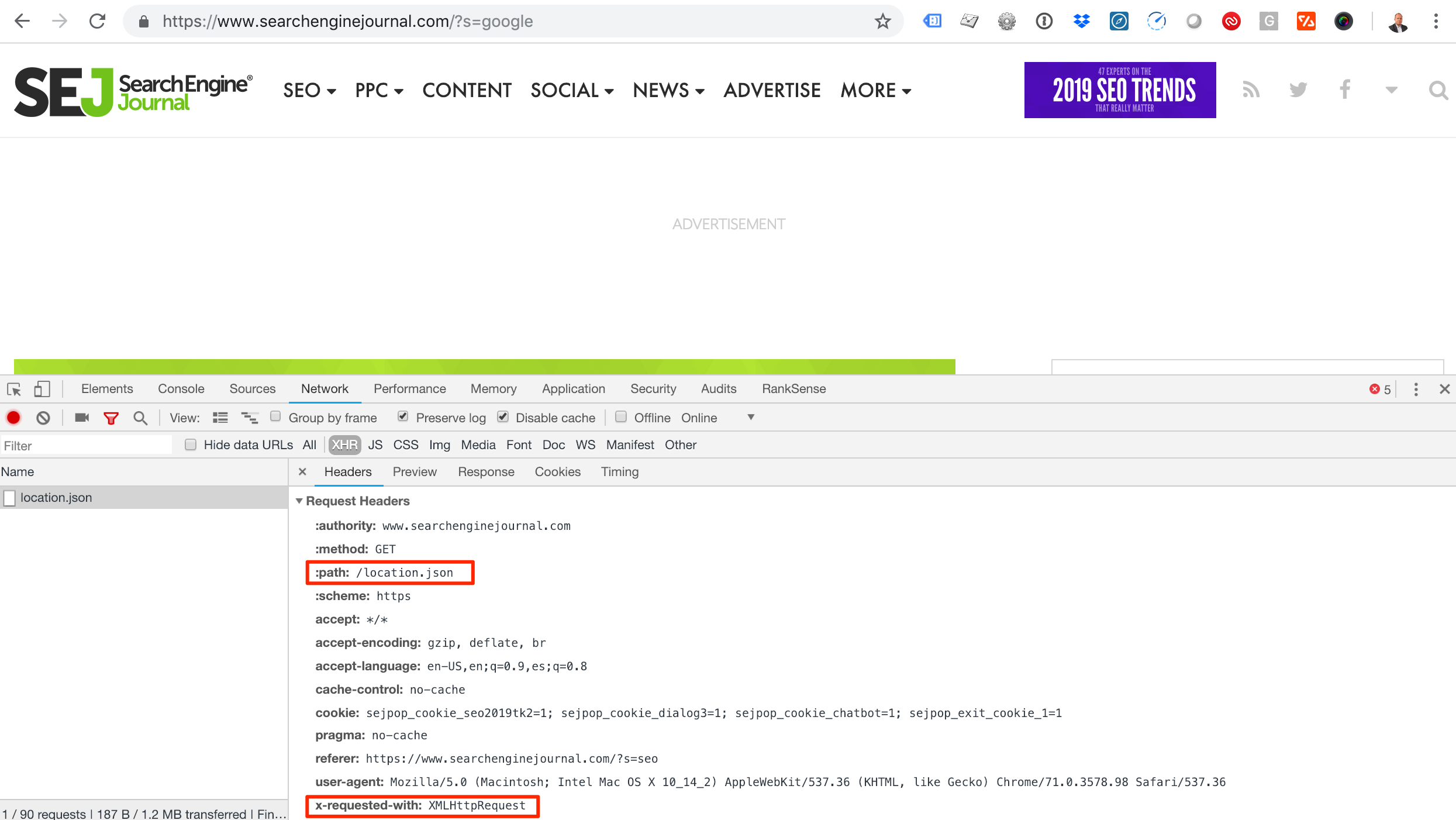
ajax_request='https://www.searchenginejournal.com/location.json' r = requests.get(ajax_request) results=r.json()
You will get the data you need faster as there is no JavaScript rendering or even HTML parsing involved.
Reading from Server Logs
Google Analytics is powerful but doesn’t record or present visits from most search engine crawlers. We can get that information directly from server log files.
Let’s see how we can analyze server log files using regular expressions in Python. You can check the regex that I’m using here.
import re log_line='66.249.66.1 - - [06/Jan/2019:14:04:19 +0200] "GET / HTTP/1.1" 200 - "" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"' regex='([(\d\.)]+) - - \[(.*?)\] \"(.*?)\" (\d+) - \"(.*?)\" \"(.*?)\"' groups=re.match(regex, line).groups() print(groups)
The output breaks up each element of the log entry nicely:
('66.249.66.1', '06/Jan/2019:14:04:19 +0200', 'GET / HTTP/1.1', '200', '', 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)')
You access the user agent string in group six, but lists in Python start at zero, so it is five.
print(groups[5])
The output is:
'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'
You can learn about regular expression in Python here. Make sure to check the section about greedy vs. non-greedy expressions. I’m using non-greedy when creating the groups.
Verifying Googlebot
When performing log analysis to understand search bot behavior, it is important to exclude any fake requests, as anyone can pretend to be Googlebot by changing the user agent string.
Google provides a simple approach to do this here. Let’s see how to automate it with Python.
import socket bot_ip = "66.249.66.1" host = socket.gethostbyaddr(bot_ip) print(host[0])
You will get crawl-66-249-66-1.googlebot.com
ip = socket.gethostbyname(host[0])
You get ‘66.249.66.1’, which shows that we have a real Googlebot IP as it matches our original IP we extracted from the server log.
Reading from URLs
An often-overlooked source of information is the actual webpage URLs. Most websites and content management systems include rich information in URLs. Let’s see how we can extract that.
It is possible to break URLs into their components using regular expressions, but it is much simpler and robust to use the standard library urllib for this.
from urllib.parse import urlparse url="https://www.searchenginejournal.com/?s=google&search-orderby=relevance&searchfilter=0&search-date-from=January+1%2C+2016&search-date-to=January+7%2C+2019" parsed_url=urlparse(url) print(parsed_url)
The output is:
ParseResult(scheme='https', netloc='www.searchenginejournal.com', path='/', params='', query='s=google&search-orderby=relevance&searchfilter=0&search-date-from=January+1%2C+2016&search-date-to=January+7%2C+2019', fragment='')
For example, you can easily get the domain name and directory path using:
print(parsed_url.netloc) print(parsed_url.path)
This would output what you would expect.
We can further break down the query string to get the url parameters and their values.
parsed_query=parse_qs(parsed_url.query) print(parsed_query)
You get a Python dictionary as output.
{'s': ['google'],
'search-date-from': ['January 1, 2016'],
'search-date-to': ['January 7, 2019'],
'search-orderby': ['relevance'],
'searchfilter': ['0']}
We can continue and parse the date strings into Python datetime objects, which would allow you to perform date operations like calculating the number of days between the range. I will leave that as an exercise for you.
Another common technique to use in your analysis is to break the path portion of the URL by ‘/’ to get the parts. This is simple to do with the split function.
url="https://www.searchenginejournal.com/category/digital-experience/"
parsed_url=urlparse(url)
parsed_url.path.split("/")
The output would be:
['', 'category', 'digital-experience', '']
When you split URL paths this way, you can use this to group a large group of URLs by their top directories.
For example, you can find all products and all categories on an ecommerce website when the URL structure allows for this.
Performing Basic Analysis
You will spend most of your time getting the data into the right format for analysis. The analysis part is relatively straightforward, provided you know the right questions to ask.
Let’s start by loading a Screaming Frog crawl into a pandas dataframe.
import pandas as pd
df = pd.DataFrame(pd.read_csv('internal_all.csv', header=1, parse_dates=['Last Modified']))
print(df.dtypes)
The output shows all the columns available in the Screaming Frog file, and their Python types. I asked pandas to parse the Last Modified column into a Python datetime object.
Let’s perform some example analyses.
Grouping by Top Level Directory
First, let’s create a new column with the type of pages by splitting the path of the URLs and extracting the first directory name.
df['Page Type']=df['Address'].apply(lambda x: urlparse(x).path.split("/")[1])
aggregated_df=df[['Page Type','Word Count']].groupby(['Page Type']).agg('sum')
print(aggregated_df)
After we create the Page Type column, we group all pages by type and by total the number of words. The output partially looks like this:
seo-guide 736 seo-internal-links-best-practices 2012 seo-keyword-audit 2104 seo-risks 2435 seo-tools 588 seo-trends 3448 seo-trends-2019 2676 seo-value 1528
Grouping by Status Code
status_code_df=df[['Status Code', 'Address']].groupby(['Status Code']).agg('count')
print(status_code_df)
200 218
301 6
302 5
Listing Temporary Redirects
temp_redirects_df=df[df['Status Code'] == 302]['Address'] print(temp_redirects_df) 50 https://www.searchenginejournal.com/wp-content... 116 https://www.searchenginejournal.com/wp-content... 128 https://www.searchenginejournal.com/feed 154 https://www.searchenginejournal.com/wp-content... 206 https://www.searchenginejournal.com/wp-content...
Listing Pages with No Content
no_content_df=df[(df['Status Code'] == 200) & (df['Word Count'] == 0 ) ][['Address','Word Count']] 7 https://www.searchenginejournal.com/author/cor... 0 9 https://www.searchenginejournal.com/author/vic... 0 66 https://www.searchenginejournal.com/author/ada... 0 70 https://www.searchenginejournal.com/author/ron... 0
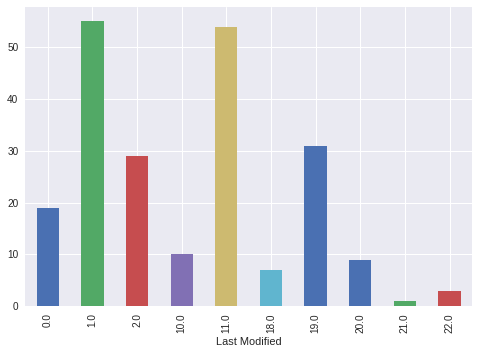
Publishing Activity
Let’s see at what times of the day the most articles are published in SEJ.
lastmod = pd.DatetimeIndex(df['Last Modified']) writing_activity_df=df.groupby([lastmod.hour])['Address'].count() 0.0 19 1.0 55 2.0 29 10.0 10 11.0 54 18.0 7 19.0 31 20.0 9 21.0 1 22.0 3
It is interesting to see that there are not many changes during regular working hours.
We can plot this directly from pandas.
writing_activity_df.plot.bar()
Saving & Exporting Results
Now we get to the easy part – saving the results of our hard work.
Saving to Excel
writer = pd.ExcelWriter(no_content.xlsx') no_content_df.to_excel(writer,'Results') writer.save()
Saving to CSV
temporary_redirects_df.to_csv('temporary_redirects.csv')
Additional Resources to Learn More
We barely scratched the surface of what is possible when you add Python scripting to your day-to-day SEO work. Here are some links to explore further.
- The official Python tutorial
- Python for data science cheat sheet
- An SEO guide to XPATH
- 10 minutes to pandas
- Introduction to pandas for Excel super users
- Pandas cheat sheet
More Resources:
- How to Use Regex for SEO & Website Data Extraction
- Understanding JavaScript Fundamentals: Your Cheat Sheet
- A Complete Guide to SEO: What You Need to Know in 2019
Image Credits
Screenshot taken by author, January 2019
Bar plot generated by author, January 2019
