
With the ever-increasing appetite of SEO professionals to learn Python, there’s never been a better or more exciting time to take advantage of machine learning’s (ML) capabilities and apply these to SEO.
This is especially true in your competitor research.
In this column, you’ll learn how machine learning helps address common challenges in SEO competitor research, how to set up and train your ML model, how to automate your analysis, and more.
Let’s do this!
Why We Need Machine Learning in SEO Competitor Research
Most if not all SEO pros working in competitive markets will analyze the SERPs and their business competitors to find out what it is their site is doing to achieve a higher rank.
Back in 2003, we used spreadsheets to collect data from SERPs, with columns representing different aspects of the competition such as the number of links to the home page, number of pages, etc.
In hindsight, the idea was right but the execution was hopeless due to the limitations of Excel in performing a statistically robust analysis in the short time required.
And if the limits of spreadsheets weren’t enough, the landscape has moved on quite a bit since then as we now have:
- Mobile SERPs.
- Social media.
- A much more sophisticated Google Search experience.
- Page Speed.
- Personalized search.
- Schema.
- Javascript frameworks and other new web technologies.
The above is by no means an exhaustive list of trends but serves to illustrate the ever-increasing range of factors that can explain the advantage of your higher-ranked competitors in Google.
Machine Learning in the SEO Context
Thankfully, with tools like Python/R, we’re no longer subject to the limits of spreadsheets. Python/R can handle millions to billions of rows of data.
If anything, the limit is the quality of data you can feed into your ML model and the intelligent questions you ask of your data.
As an SEO professional, you can make the decisive difference to your SEO campaign by cutting through the noise and using machine learning on competitor data to discover:
- Which ranking factors can best explain the differences in rankings between sites.
- What the winning benchmark is.
- How much a unit change in the factor is worth in terms of rank.
Like any (data) science endeavor, there are a number of questions to be answered before we can start coding.
What Type of ML Problem is Competitor Analysis?
ML solves a number of problems whether it’s categorizing things (classification) or predicting a continuous number (regression).
In our particular case, since the quality of a competitor’s SEO is denoted by its rank in Google, and that rank is a continuous number, then the ML problem is one of regression.
Outcome Metric
Given that we know the ML problem is one of regression, the outcome metric is rank. This makes sense for a number of reasons:
- Rank won’t suffer from seasonality; an ice cream brand’s rankings for searches on [ice cream] won’t depreciate because it’s winter, unlike the “users” metric.
- Competitor rank is third-party data and is available using commercial SEO tools, unlike their user traffic and conversions.
What Are the Features?
Knowing the outcome metric, we must now determine the independent variables or model inputs also known as features. The data types for the feature will vary, for example:
- First paint measured in seconds would be a numeric.
- Sentiment with the categories positive, neutral, and negative would be a factor.
Naturally, you want to cover as many meaningful features as possible including technical, content/UX, and offsite for the most comprehensive competitor research.
What Is the Math?
Given that rankings are numeric, and that we want to explain the difference in rank, then in mathematical terms:
rank ~ w_1*feature_1 + w_2*feature_2 + … + w_n*feature_n
~ (known as the “tilde”) means “explained by”
n being the nth feature
w is the weighting of the feature
Using Machine Learning to Uncover Competitor Secrets
With the answers to these questions in hand, we’re ready to see what secrets machine learning can reveal about your competition.
At this point, we will assume that your data (known in this example as “serps_data”) has been joined, transformed, cleaned, and is now ready for modeling.
As a minimum, this data will contain the Google rank and feature data you want to test.
For example, your columns could include:
- Google_rank.
- Page_speed.
- Sentiment.
- Flesch_kincaid_reading_ease.
- Amp_version_available.
- Site_depth.
- Internal_page_rank.
- Referring_comains count.
- avg_domain_authority_backlinks.
- title_keyword_string_distance.
Training Your ML Model
To train your model, we’re using XGBoost because it tends to deliver better results than other ML models.
Alternatives you may wish to trial in parallel are LightGBM (especially for much larger datasets), RandomForest, and Adaboost.
Try using the following Python code for XGBoost for your SERPs dataset:
# import the libraries
import xgboost as xgb
import pandas as pd
serps_data = pd.read_csv('serps_data.csv')
# set the model variables
# your SERPs data with everything but the google_rank column
serp_features = serps_data.drop(columns = ['Google_rank'])
# your SERPs data with just the google_rank column
rank_actual = serps_data.Google_rank
# Instantiate the model
serps_model = xgb.XGBRegressor(objective='reg:linear', random_state=1231)
# fit the model
serps_model.fit(serp_features, rank_actual)
# generate the model predictions
rank_pred = serps_model.predict(serp_features)
# evaluate the model accuracy
mse = mean_squared_error(rank_actual, rank_pred)
Note that the above is very basic. In a real client scenario, you’d want to trial a number of model algorithms on a training data sample (about 80% of the data), evaluate (using the remaining 20% data), and select the best model.
So what secrets can this machine learning model tell us?
The Most Predictive Drivers of Rank
The chart shows the most influential SERP features or ranking factors in descending order of importance.
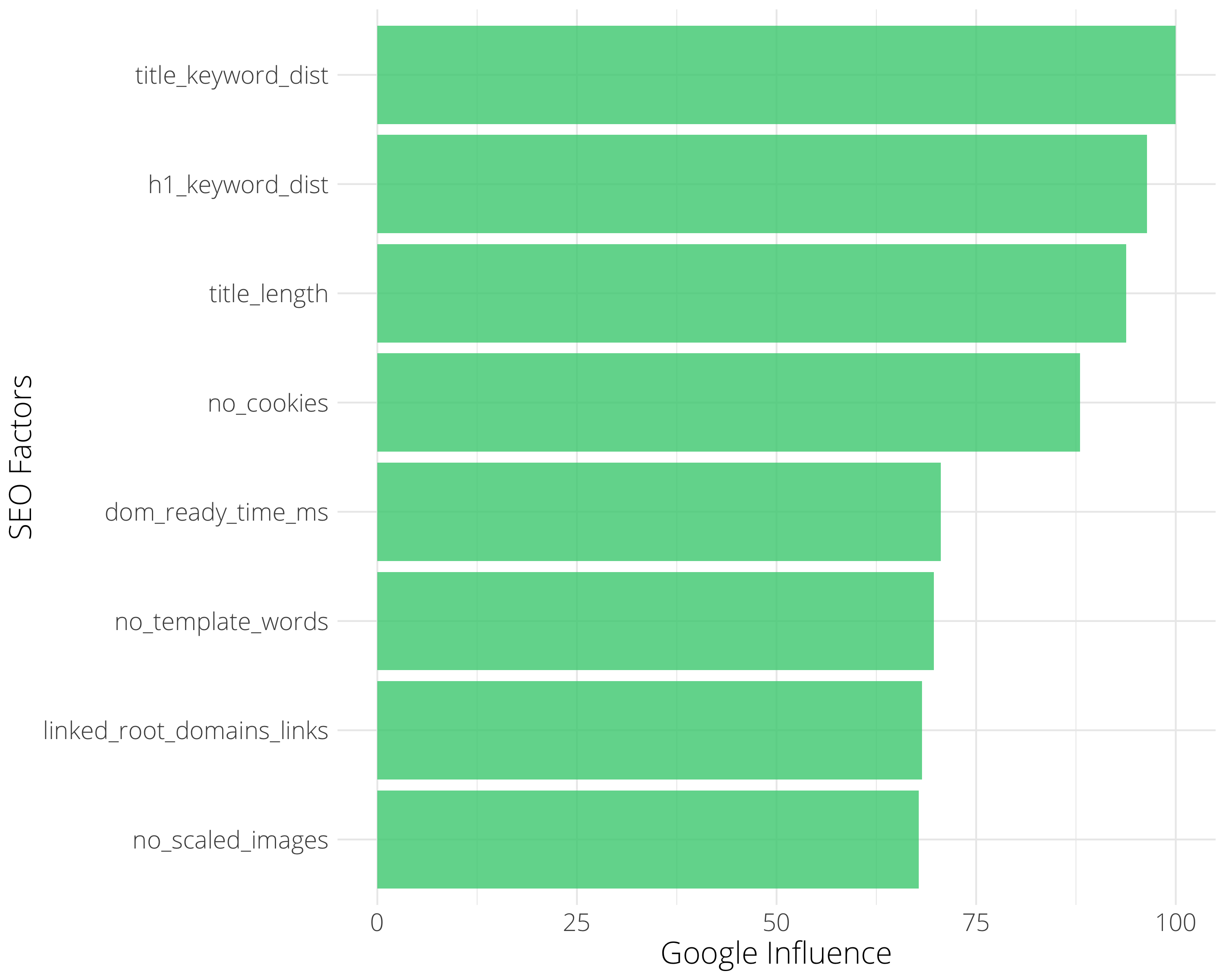
In this particular case, the most important factor was “title_keyword_dist” which measures the string distance between the title tag and the target keyword. Think of this as the title tag’s relevance to the keyword.
No surprise there for the SEO practitioner, however, the value here is providing empirical evidence to the non-expert business audience that doesn’t understand the need to optimize title tags.
Other factors of note in this industry are:
- no_cookies: The number of cookies.
- dom_ready_time_ms: A measure of page speed.
- no_template_words: Counts the number of words outside the main body content section.
- link_root_domains_links: Count of links to root domains.
- no_scaled_images: Count of images scaled that need scaling by the browser to render.
Every market or industry is different, so the above is not a general result for the whole of SEO!
How Much Rank a Ranking Factor Is Worth
In another market case, we can also see how much rank will be delivered.
![]()
In the chart above, we have a list of factors and the rank change for every positive unit change in that factor.
For example, for every unit increase in meta description length by 1 character, there is a corresponding decrease in Google rank of 0.1.
Taken out of context, this sounds ridiculous. However, given that most meta descriptions are populated it would mean that a unit change away from the average meta description length would then lead to a decrease in Google Search ranking.
The Winning Benchmark for a Ranking Factor
Below is a graph plotting the average title tag length for a different industry to the one above, which also includes a line of best fit:
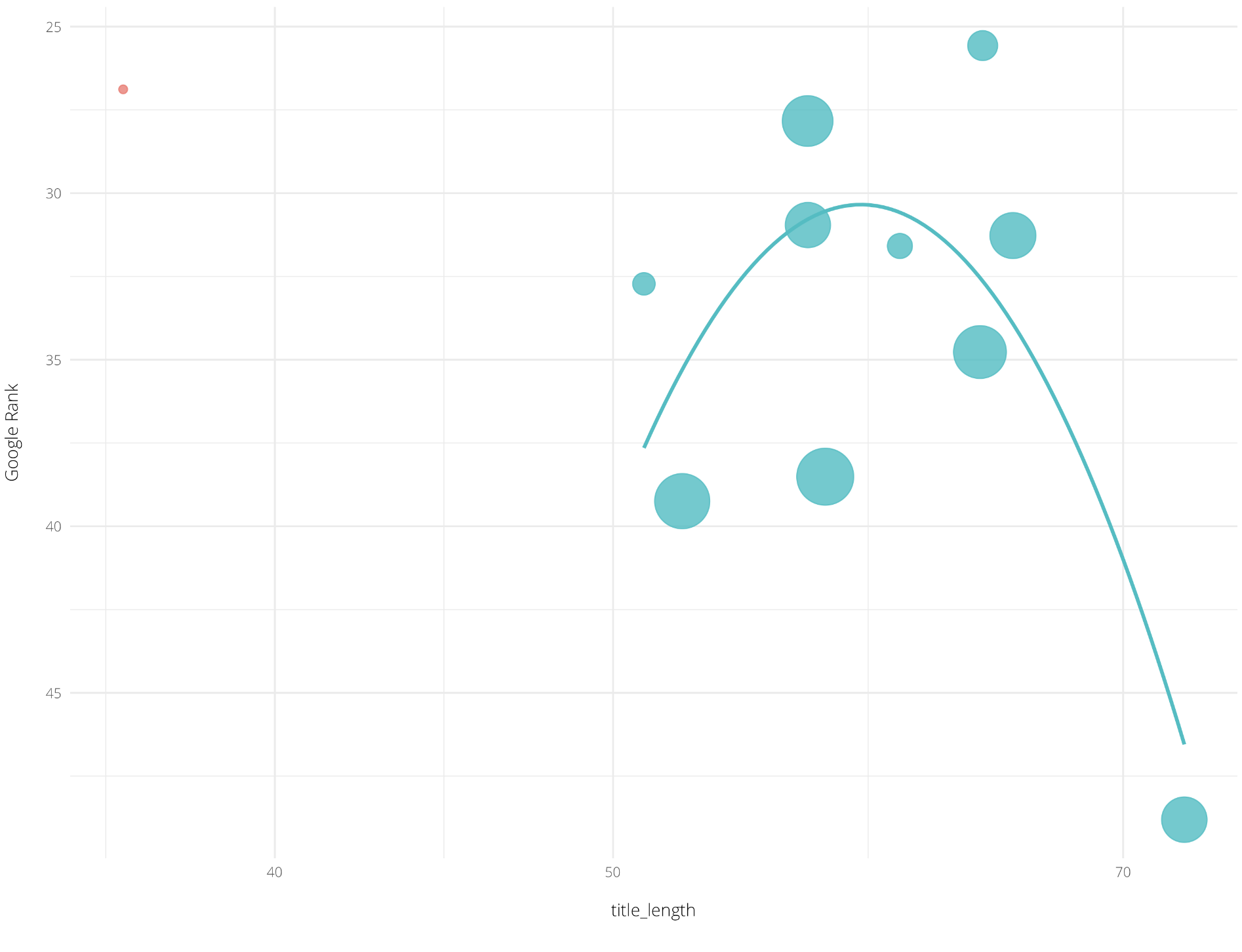
Despite the best practice SEO recommendation of using up to 70 characters for title tag length, the data plotted above shows the actual optimum length in this industry to be 60 characters.
Thanks to machine learning, we’re not only able to surface the most important factors but when taking a deep dive can also see the winning benchmark.
Automating Your SEO Competitor Analysis with Machine Learning
The above application of machine learning is great for getting some ideas to split AB test and improve the SEO program with evidence-driven change requests.
It’s also important to recognize that this analysis is made all the more powerful when it is ongoing.
Why?
Because the ML analysis is just a snapshot of the SERPs for a single point in time.
Having a continuous stream of data collection and analysis means you get a truer picture of what is really happening with the SERPs for your industry.
This is where SEO purpose-built data warehouse and dashboard systems come in handy, and these products are available today.
What these systems do is:
- Ingest your data from your favorite SEO tools daily.
- Combine the data.
- Use ML to surface insights like to above in a front end of your choice like Google Data Studio.
To build your own automated system, you would deploy into a cloud infrastructure like Amazon Web Services (AWS) or Google Cloud Platform (GCP) what is called ETL i.e., extract, transform and load.
To explain:
- Extract – Daily calling of your SEO tool APIs.
- Transform – The cleaning and analysis of your data using ML as described above.
- Load – Depositing the finished result in your data warehouse.
Thus your data collection, analysis, and visualization are automated in one place.
TL;DR?
Competitor research and analysis in SEO is difficult because there are so many ranking factors to control for.
Spreadsheet tools are not up to it, due to the amounts of data involved (let alone the statistical capabilities that data science languages like Python offer).
When conducting SEO competitor analysis using machine learning, it’s important to understand that this is a regression problem, the target variable is Google rank, and that the hypotheses are the ranking factors.
Using ML on your competitors can tell you what the key drivers are, identify winning benchmarks among them, and inform just how much lift in rank your optimizations can potentially deliver.
The analysis is a snapshot only, so to stay on top of the competitors, automate this process using Extract, Transform, Load (ETL).
More Resources:
- Why SEO & Machine Learning Are Joining Forces
- A Practical Introduction to Machine Learning for SEO Professionals
- A Complete Guide to SEO: What You Need to Know
Image Credits
All screenshots taken by author, June 2021
