

In this new weekly series, we’ll be looking at some recently granted Google Search Patents.
When it comes to search and SEO, there’s no easy way to know what’s in the black box that is Google. Patent filings can at least give us a glimpse.
It’s always worth noting that just because a patent was filed and granted, it doesn’t mean that Google’s using it. And if it is in use, we don’t know the thresholds or scoring values within the greater context.
All we’re after with this exercise is to get into the mindset. A sense of how things work in information retrieval.
Also, this won’t be a deep-dive adventure. Just some highlights. I do though, encourage you to follow up on any of interest and read them fully.
Latest Google Patents of Interest
Well, the last few weeks have been a bit quiet. Which is kinda sad for guys like Bill Slawski and myself.
But there were a “few” of interest the last few weeks, so let’s have a look.
Computerized systems and methods for enriching a knowledge base for search queries
- Filed: Feb. 29 2016
- Granted: January 14, 2020
Abstract
“Systems and methods are disclosed for enriching a knowledge base for search queries. According to certain embodiments, images are assigned annotations that identify entities contained in the images. An object entity is selected among the entities based on the annotations and at least one attribute entity is determined using annotated images containing the object entity. A relationship between the object entity and the at least one attribute entity is inferred and stored in the knowledge base. In some embodiments, confidence may be calculated for the entities. The confidence scores may be aggregated across a plurality of images to identify an object entity.”
Notable
“In accordance with some embodiments, object recognition technology is used to annotate images stored in databases or harvested from Internet web pages. The annotations may identify who and/or what is contained in the images.”
“(…) can learn which annotations are good indicators for facts by aggregating annotations over object entities and facts that are already known to be true. Grouping annotated images by object entity helps identify the top annotations for the object entity. Top annotations can be selected as attributes for the object entities and relationships can be inferred between the object entities and the attributes.”
“(…) also provide improved systems and methods for calculating confidence scores for annotations assigned to images. Confidence scores may reflect likelihood that an entity identified by an annotation is actually contained in an image. Confidence scores may be calculated on a per-image basis and aggregated over groups of annotated images in order to improve image recognition and annotation techniques.”
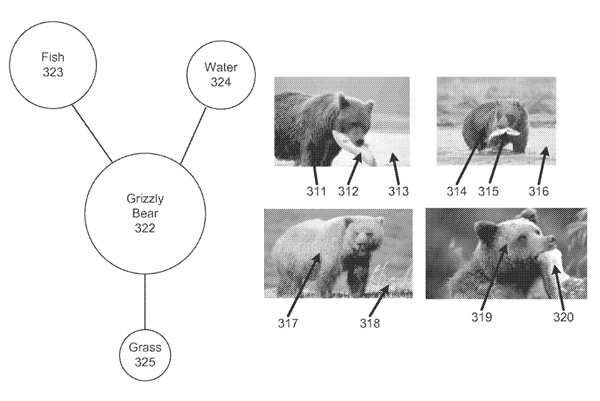
Determining search queries for obtaining information during a user experience of an event
- Filed: March 15, 2017
- Granted: January 28, 2020
Abstract
“A computing system is described that determines a plurality of search queries for subsequent search during an event, and schedules, for each of the plurality of search queries, a respective time during the event to search the corresponding search query. Responsive to determining that a user of a computing device is experiencing the event at the respective time during the event at which a particular search query from the plurality of search queries is scheduled to be searched, the computing system searches the particular search query and automatically sends, to the computing device for subsequent display during the event, an indication of information returned from the search of the particular search query.”
Notable
“While experiencing an event (e.g., watching and/or listening to a presentation of content), a user may wish to obtain secondary information related to the event and may therefore interact with a computing device to manually search for such information while experiencing the event.”
“(…) while a user of a computing device is experiencing an event, dynamically obtain, and cause the computing device to present current information that is relevant to the event. The term “event” as used herein refers to any live performance, broadcast, playback, or other type of presentation of live or pre-recorded content (e.g., meeting presentations, assemblies, conferences, musical or theatrical performances, movies, television shows, songs, concerts, sports events, or any other types of live or pre-recorded content that users may experience).”
“(…) a user may wish to obtain secondary information about the event, at precise timestamps, or in response to particular “subevents” occurring, during the event. For example, while watching a sports event, a user may be interested in obtaining biographical information of a lesser-known player that just made an important play, or may be interested in seeing a replay of the important play. Or, while watching a movie, a user may be interested in seeing vacation deals or other information about an exotic geographical location that is the backdrop of a particular scene. Or while watching a movie or TV presentation, the user may wish to obtain biographical and other acting information about the actors, as they appear on the screen.”
“The system may pre-determine and store (e.g., in cache or other memory) one or more search queries for subsequent search when a user of a computing device is experiencing the event.”
Semantic model for tagging of word lattices
- Filed: August 21, 2017
- Granted: January 7, 2020
Abstract
“Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for tagging during speech recognition. A word lattice that indicates probabilities for sequences of words in an utterance is obtained. A conditional probability transducer that indicates a frequency that sequences of both the words and semantic tags for the words appear is obtained. The word lattice and the conditional probability transducer are composed to construct a word lattice that indicates probabilities for sequences of both the words in the utterance and the semantic tags for the words. The word lattice that indicates probabilities for sequences of both the words in the utterance and the semantic tags for the words is used to generate a transcription that includes the words in the utterance and the semantic tags for the words.”
Notable
“(…) obtaining, from an automated speech recognizer, an utterance-weighted word lattice that indicates probabilities for sequences of words in an utterance; obtaining a conditional probability transducer that indicates a frequency that sequences of both the words and semantic tags for the words appear;”
“(…) mechanisms for tagging words during speech recognition. In general, a semantic tagger may insert tags into a word lattice, such as a word lattice produced by a real-time large vocabulary speech recognition system. For example, the phrase “San Francisco” may appear in a path of a word lattice and tagged with metadata of “<cities>” before “San” and metadata of “</cities>” after “Francisco.””
“The tagging may be performed by distilling a pre-existing very large named entity disambiguation (NED) model into a lightweight tagger. This may be accomplished by constructing a joint distribution of tagged n-grams from a supervised training corpus and then deriving a conditional distribution for a given lattice.”
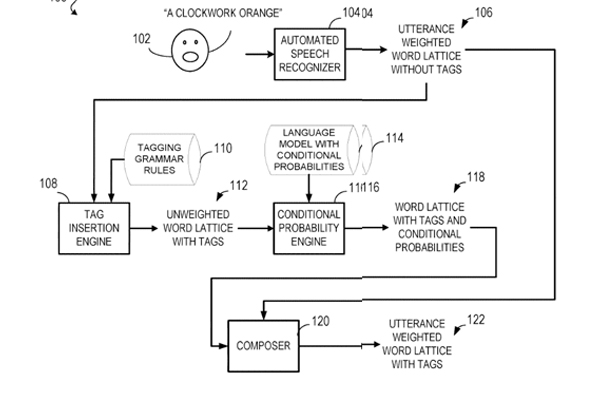
Speech recognition with attention-based recurrent neural networks
- Filed: May 3, 2018
- Granted: January 21, 2020
Abstract
“Methods, systems, and apparatus, including computer programs encoded on computer storage media for speech recognition. One method includes obtaining an input acoustic sequence, the input acoustic sequence representing an utterance, and the input acoustic sequence comprising a respective acoustic feature representation at each of a first number of time steps; processing the input acoustic sequence using a first neural network to convert the input acoustic sequence into an alternative representation for the input acoustic sequence; processing the alternative representation for the input acoustic sequence using an attention-based Recurrent Neural Network (RNN) to generate, for each position in an output sequence order, a set of substring scores that includes a respective substring score for each substring in a set of substrings; and generating a sequence of substrings that represent a transcription of the utterance.”
Notable
“Some speech recognition systems include a pronunciation system, an acoustic modeling system and a language model. The acoustic modeling system generates a phoneme representation of the acoustic sequence, the pronunciation system generates a grapheme representation of the acoustic sequence from the phoneme representation, and the language model generates the transcription of the utterance that is represented by the acoustic sequence from the grapheme representation.”
(…) “processing the input acoustic sequence using a first neural network to convert the input acoustic sequence into an alternative representation for the input acoustic sequence; processing the alternative representation for the input acoustic sequence using an attention-based Recurrent Neural Network (RNN) to generate, for each position in an output sequence order, a set of substring scores that includes a respective substring score for each substring in a set of substrings; and generating a sequence of sub strings that represent a transcription of the utterance.”
Stay Tuned & Get Geeky
And there we have it for the first of many updates to come.
If you’ve never spent some quality time with a search patent – isn’t it time you did?
Be sure to come back each week for all the latest awards and get your geek on.
Over the coming months, I will also be writing in more detail when there’s an especially interesting Google patent that I think you should know about.
See you next week.
More Resources:
- When Google SERPs May Undergo a Sea Change
- Patent: Google Going Old School with Local SEO, But In A New Way
- Google to Capture & Learn Our Emotions on a Smartphone Camera?
Image Credits
Featured Image: Created by author, January 2020
In-Post Images: USPTO