

Editor note: Welcome to Ask an SEO, the first of a bi-weekly column with different experts every few months. Want to ask Jenny an SEO question? Fill out our form or use #AskAnSEO on social media.
The first batch of questions we received were all about canonical use and best practices with regards to helping search engines crawl sites more effectively. I thought it might help to start by giving some background on why this matters for SEO. For those who may not be familiar with crawl budget as a term, it refers to the amount of time a search engine (like Google of course) will spend trying to access your site’s information. In most cases, you don’t have an unlimited amount of time, because Google has a lot of other sites to crawl. So it’s important to get things in order and help them save time. There are a lot of ways to do this, but it comes down mostly to consistency and focus.
Consistently referencing URLs the same way – whether in internal links, with canonicals, or on your XML sitemap – can help search engines understand which version of a page is most important to you. The most common problems that occur with consistency are URLs that can be accessed either with or without the www, with or without https, and with or without slashes (called a trailing slash) at the end of the file names. It’s best to pick one variation and stick with it.
Focusing the search engines on what is most important is the other key element in controlling crawl budget. You can do this a lot of different ways, with various file types and commands, such as robots.txt, noindex, and xml sitemap priority designation.
Each has its own purpose, and they are not interchangeable. The best way to focus the search engine, though, is by consistently (there’s that word again!) using the same URLs and using internal links to emphasize which is most important. It’s no accident that most websites have a main navigation from which all pages within the site are accessed. A good internal site navigation looks like a tree when you graph it out.
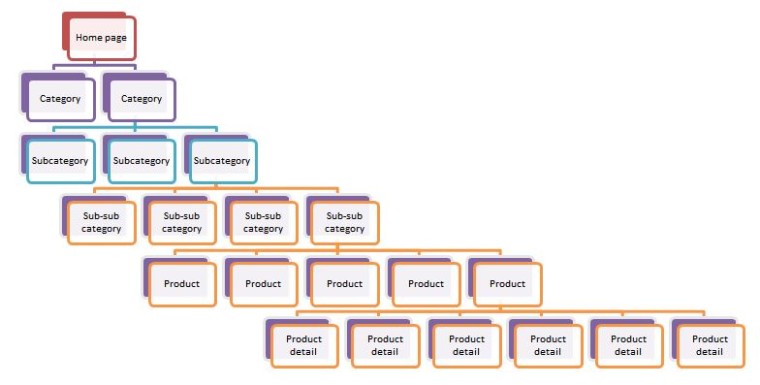
This, by the way, is why the theory that all site content should be no more than three clicks from the homepage is bunk. The more information you have to share, the more levels deep the content is going to need to go. I’m not suggesting that you add sub-directories or sub-categories where there is no need for them, but do allow logic to prevail. If you have a hundred thousand individual products, some of those product links are going to need to be more than three clicks away from the homepage.
On to the Questions!
“I see many well acclaimed websites using self-referencing rel=canonical tag in every page of their domain. Why are they doing this, should I implement the same tactic?”
The rel=canonical tag is a signal, not a definitive command. While it’s certainly not a bad idea to include a canonical on every page, this is also a way that a lot of sites (especially very large sites) cause problems for themselves. If you set the canonical so that it is truly self-referential, then every possible version of that page will have its own canonical. The more canonicals a search engine sees that are “false”, the more likely the search engine will not trust any of your canonical commands.
For example, let’s say you have decided that the main version of your site will standardize on https protocol, with a www, and with a trailing slash. So a page on your site might be: https://www.site.com/things/
With a truly self-referential canonical, a request for http://site.com/things would show that the canonical is
<link rel="canonical" href="http://site.com/things" /> – and we know that’s not right because it doesn’t use the www, the https protocol, or trailing slash.
So for this canonical to work properly, a request for that second page needs to have the following rel=canonical command associated with it:
<link rel="canonical" href="https://www.site.com/things/" />
Also, be wary of doing things just because big sites do it. In my experience, a lot of really large sites get these simple things wrong, but their massive link value or other elements outweigh the problem. When they fix these issues, they usually benefit just as you would.
After adding https://www, https://, http://www, http:// versions of my site in Google Search Console, per their instructions, What should the rel=canonical link look like for the 1 page site?
https://www.websitename.com, https://www.websitename.com/, or https://www.websitename.com/index.html?
The answer is that you should standardize on one. Make a decision as to which one you will use, and use the rel=canonical command to point all other versions to the standard version. While it’s not definitive, try to avoid using a file name like /index.html as your main website home page. There are a lot of reasons for this, but the most practical is that most people who link to your site won’t remember to include the filename. Also remember that rel=canonical is just a suggestion, and 301 redirecting these pages is a better strategy.
Should my sitemap.xml file include https://www.websitename.com/ AND https://www.websitename.com/index.html ? Could you confirm best practices in this situation?
No. Your sitemap.xml file needs to include only the standardized version of any given page. If you’ve decided to standardize on http://www.websitename.com, that should be the only version you include in your sitemap.xml file. The only exception to this is when you’re dealing with multiple domains and using Hreflang tags, but that’s another question entirely.
If someone doesn’t have something to write in the robots.txt file, should they submit a blank one in order to prevent 404 created by the robots?
It is up to you. Best practice is to have a standard robots.txt file that uses the command:
User-Agent: *
Disallow:
This indicates that nothing on the site is disallowed. In reality, this is very rare. Even with a WordPress site, you will want to disallow certain areas of the site that are intended only for administrators. However if you do not use a robots.txt file, the search engine will assume that the site is open and nothing is disallowed.
While not required, I also recommend webmasters include a link to their XML sitemap in their robots.txt file, as this is a primary place that Google and other search engines seek it out. To do this, just change the example file above to:
User-Agent: *
Disallow:
sitemap: https://www.website.com/sitemap.xml
Just be sure to replace the URL with the actual location of your XML sitemap, being careful to use the proper http/https and www/non version.
Thanks for the great questions! While we’re always glad to answer any questions you submit. Next month we’ll likely focus on metrics and measurement for SEO.
Want to ask Jenny an SEO question? Fill out our form or use #AskAnSEO on social media.
Image Credits
Featured Image: Image by Paulo Bobita
In-post Photo: Image by Jenny Halasz
