

Hi there. Technical SEO here. I started working with Angular in 2015 with an ecommerce site redesign. I’ve broken a lot but fixed more.
If you’re new to SEO for JavaScript or need additional information on concepts referenced here, Rachel Costello’s Understanding JavaScript Fundamentals: Your Cheat Sheet is a great resource to have on hand.
Most importantly: don’t panic. You don’t need to be an expert on every piece of technology mentioned.
Your ability to get stakeholder buy-in and communicate with developers will likely be your greatest strength. We’ll provide additional resources to help.
Let’s Start with the Basics
Websites are made of code. Code is written in languages. Three languages comprise the majority of websites.

HTML creates content. CSS makes the layout, design, and visual effects.
These two languages can craft an aesthetically appealing, functional, flat pages – but mostly they’re boring.
Enter JavaScript (JS), a web version of programming code.
With JavaScript, websites can personalize interactive user experiences. People go to engaging sites. JS makes engaging sites.
Angular Is an Evolution of JavaScript
Angular is a way of scaling up JS to build sites. With Angular, a dozen lines of flat HTML sent from your server unfurl and execute personalized interactive user experiences.
Nearly 1 million sites are built with it. Adoption rates are growing rapidly.
If you haven’t worked on an Angular or other JavaScript framework, you probably will soon.
For a Search Engine to Understand Angular Sites, They Have to Render JavaScript
For search engines to experience Angular content, they need to execute JavaScript. Many search engines can’t render JavaScript.
Don’t panic.
If your market is primarily dominated by Baidu, Yandex, Naver, or another non-rendering search engine, skip ahead to rendering section.
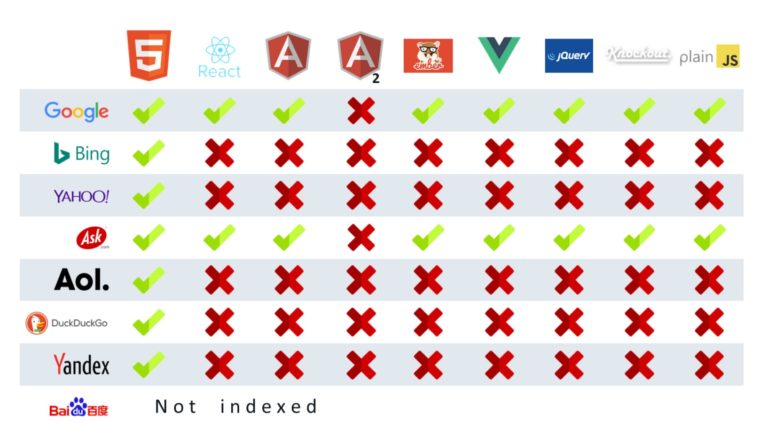
Googlebot <3s JavaScript
No – really. They love it because humans love rich interactive experiences!
… and because 95% of sites use it.
Indexing JS-generated content is good business when your model is reliant on being the most trusted index of web content.
That’s doesn’t mean it’s been a historically perfect relationship. SEO professionals have languished over Googlebot’s capabilities and commitment to crawl JS.
The lack of clarity led to warnings that Angular could kill your SEO.
At I/O 2018, the Webmaster team spoke openly about the issues Google encountered when indexing Angular and other JS content. Some SEO pros were mad, others were angry, some were… unreasonably excited?

I stand by that excitement. Search was represented. (The prior year, I encountered a few confused responses to the presence of SEO people at a developer’s conference. Arrow to the technical SEO heart.)
Developers were excited.
Then John Mueller and Tom Greenaway took the stage to tackle a major misconception in the search community: how search works.
Crawl, Index, Rank – Easy as One, Three, Four!
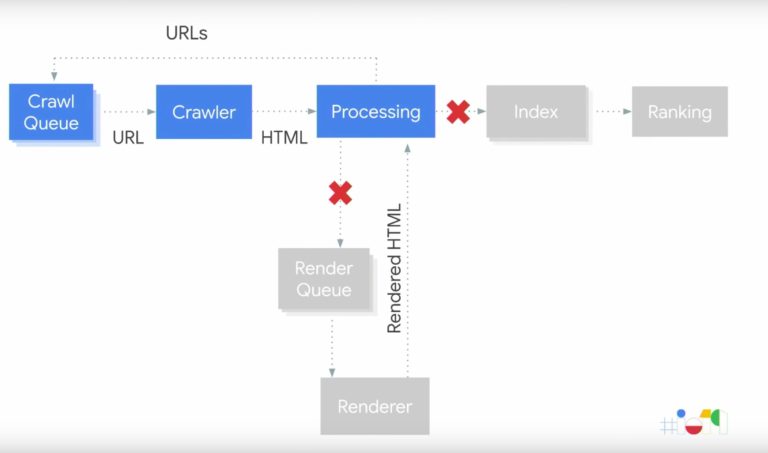
Until Google’s 2018 developer conference, SEO professionals worked with the basic premise that Googlebot’s process worked in three steps: crawl, index, and rank.
Even until April 2019, Google’s own resources reflected a simple three-step process.
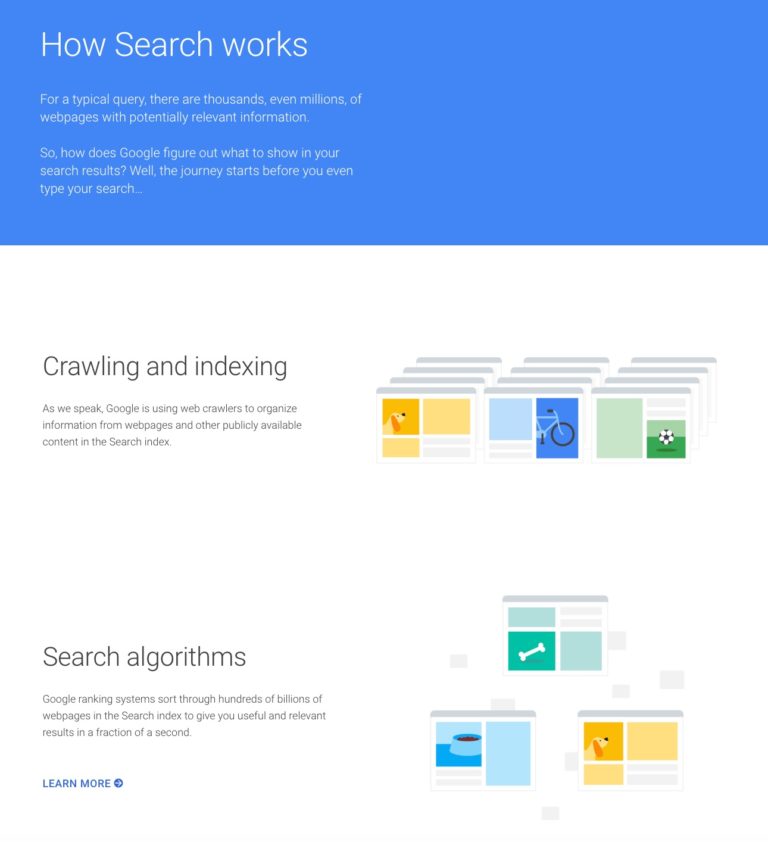
Lurking in this simplified process is a motley assortment of hidden assumptions:
- Googlebot renders JS as it crawls.
- Indexing is based on rendered content.
- These actions occur simultaneously in a single sequence.
- Googlebot is magic and does all the things instantly!
Here’s the problem. We overlooked rendering.
Rendering is the process where the scripts called in the initial HTML parse are fetched and executed.
We call the output of the initial HTML parse and JavaScript the DOM (document object model).

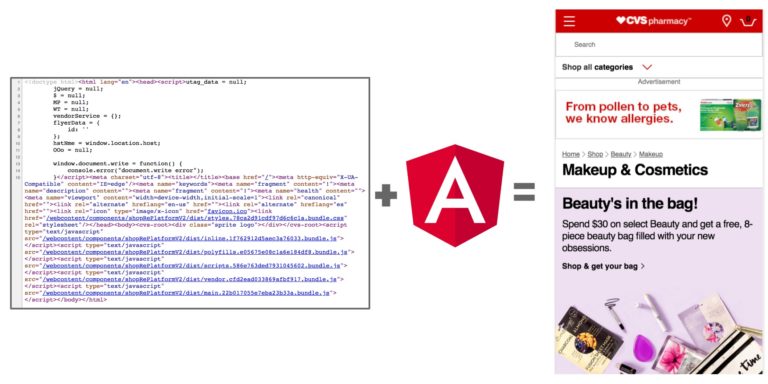
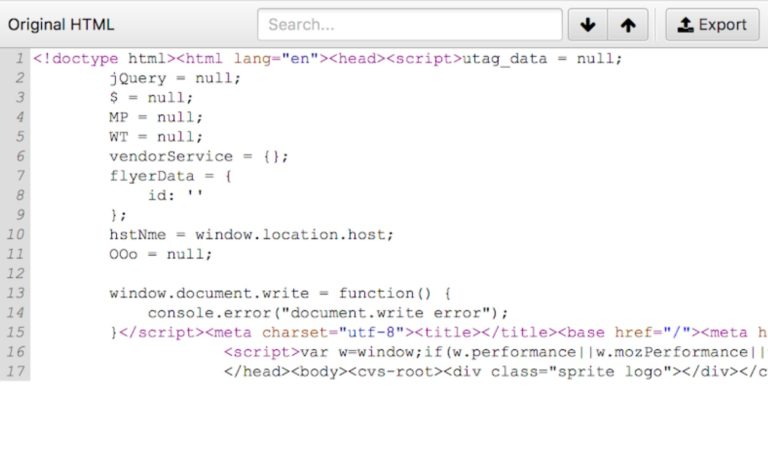
If a site uses JavaScript, the HTML will be different from the DOM.
Initial HTML (Before JavaScript executes)
DOM (After JavaScript Executes)
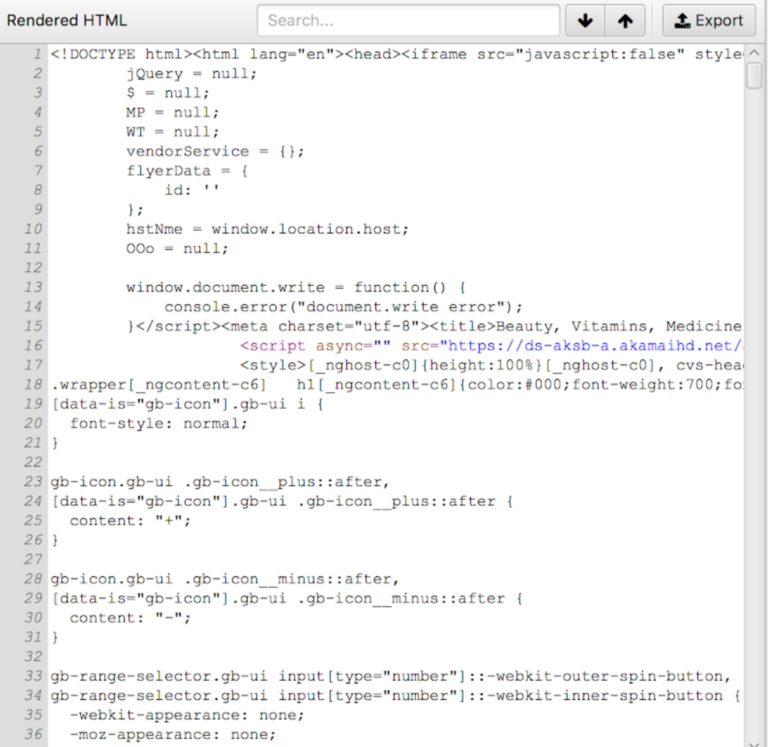
The two views of a single page can be very different. The initial HTML was just 16 lines. After JavaScript executed, the DOM is full of rich content.
You can see the initial HTML parse by viewing a page source. To see the DOM, open Developer Tools in your browser and click Inspect. Alternatively, use the keyboard shortcut Cmd+shift+I.
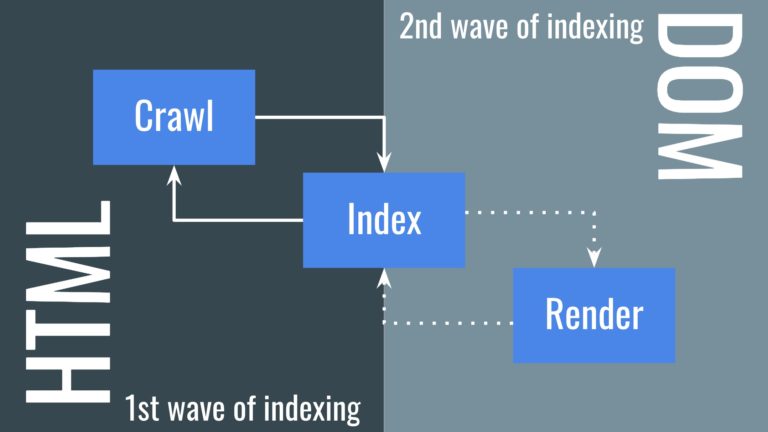
Two Waves of Indexing
Because of the three-step process assumptions and their impact on organic performance, the Google webmaster team clarified that there are two phases of indexing.
The first wave indexes a page based only the initial HTML (a.k.a., view page source).
The second indexes based on the DOM.
Googlebot Wants to Love JavaScript but They Sometimes Need Your Help Understanding It
JavaScript is the most expensive resource on your site.
1MB of script can take 5 seconds on 3G connection. 1.5MB page can cost $0.19 USD to load. (No, really. Test your pages at What Does My Site Cost?)
To Googlebot, that cost comes as CPU to execute the script. With so much JavaScript on the web, a literal queue has formed for Googlebot’s rendering engine.
This means JavaScript generated content is discovered by Googlebot only once the resources become available.
Googlebot’s Tech Debt Made SEO for Angular Difficult
Part of digital life is working with what you have. Often we take easy solutions we can act on now instead of the better approach that would take longer.
The culmination of these shortcuts is tech debt. Often, tech debt has to be cleaned up before large changes can be implemented.
One of the big blockers to Google understanding much of the web’s rich content was its web rendering service (WRS). One of the core components of the web crawler was using a version of Chrome released in 2015. (If you think it isn’t that big of a deal, find your old phone – the one you upgraded from six months ago – and use that for the next hour.)
For SEO professionals and developers, this meant shoving code bases full of polyfill to retrofit ES6 functionalities to ES5. If you’re unfamiliar with these, congratulations! You’ve chosen a golden age to start optimizing Angular sites!
Googlebot’s Revving New Rendering Engine
Search Console Developer Advocate Martin Splitt took the stage with rendering Engineer Zoe Clifford earlier this month at Google I/O to announce that Googlebot is evergreen.
The web crawler is using V8 as its rendering and WebAssembly engine. As of May 2019, it’s running Chrome 74 and will continue to update with a week or so of new versions are released.
The massive upgrade to our beloved web crawler can now render over 1,000 new features. You can test your features compatibility with Can I Use.
Expect a Delay for Rendered Content to Be Indexed
Googlers have hinted that the future of Googlebot will combine crawling and rendering. We’re not there yet. Crawling and rendering are still separate processes.
There is still a delay…but more than 1000 new features are supported now!
— Martin Splitt @ 🇨🇭🏡 (@g33konaut) May 7, 2019
Now that Googlebot can better handle Angular, let’s talk about how you can conquer it.
Optimizing Crawling for Angular
Know Your Version
The version of Angular you’re working on will have a major impact in your ability to optimize – or at least set expectations.
Version 1 is referred to as AngularJS.
For v2, the framework was re-written entirely. This is why everything after v1 is referred to with the blanket term Angular (i.e., the JS was cut).
Version matters (since Angular programs are not backward-compatible), so ask the team you’re working with which version is being used.
Give Each Asset Has a Unique URL
Angular is frequently used as part of a Single Page Application (SPA).
Single page applications allow content on the page to be updated without making a page request back to the server.
Requests for new content are populated using Asynchronous JavaScript and XML (AJAX) calls. No new page load can mean that the URL visible in the browser doesn’t represent the content on screen.
This is an SEO problem because search engines want to index content that consistently exists at a known address. If your content only tends to exist at the URI, it also tends not to rank.
A tiny piece of code known as pushState() updates the URL as new content is requested.

Google offers a Codelab for optimizing Single Page Applications (SPAs) in search.
Track Analytics for Single Page Applications with Virtual Pageviews
If your website loads page content dynamically and updates the document’s URL, you’ll want to send additional pageviews to track these “virtual pageviews”.
When your application loads content dynamically and updates the URL in the address bar, the data stored on your tracker should be updated as well.
The Google Analytics crew has thorough documentation on virtual pageviews for SPAs, which involves adding a manual tag to send information to your tracking server, when new content is loaded.
Get Your Content Discovered in First Wave Indexing by Server-Side Rendering Your Hero Elements
Search engines are looking to match pages to an intent.
Does this page useful in answering a transactional, information, or local intent?
If my query has a transactional intent, then elements like product name, price, and availability are critical to answering my intent.
This content is known as your hero elements.
By server-side rendering these, you can tell Google what intent your page matches in the first wave of indexing – without waiting for JavaScript to render.
In addition to these on hero elements, use SSR for:
- Structured data (Sam Vloeberghs create a useful tutorial)
- Page title
- Meta Description
- <link> HTML tag, including:
- Canonical
- Hreflang
- Date Annotations
Don’t Contradict Yourself Between the HTML & DOM
The basics of SEO teach us simplicity.
Pages get one title. One meta description. One set of robots directives.
With Angular, you could send different meta data and directives in the HTML than DOM.
Our bot friends run on code doing things in a set order. If you place a noindex directive in the HTML, Googlebot won’t execute the script to find the index tag in the DOM because you told it not to render the DOM.
Don’t Split Structured Data Markup Between HTML & DOM
With Angular, you could render Schema.org markup in either the HTML (preferable) or DOM.
Either will work but it very important that the complete markup is in a single location – either the HTML or DOM.
If you split the two by rendering part of the markup in HTML and populating attributes DOM, the separate components are seen as different sets of markups.
Neither of them will be complete. Structured data markup is either valid or not. There’s no “partial.” Maximum effort.
Slow or Blocked Resources Can Make Content Undiscoverable
Slow or blocked resources won’t be considered in how your content is discovered. Slow resources will show as temporarily unavailable.
A request for a script needs to be completed in ~4s. Blocked resources will be denoted as such in the tool output.
Support Paginated Loading for Infinite Scroll
Pagination on mobile can be frustrating.
You don’t have to choose between ease of use and Googlebot crawling. Instead, use History API checkpoints – URLs that would allow a user (or bot) to return back to the same place.
According to Google:
If you are implementing an infinite scroll experience, make sure to support paginated loading. Paginated loading is important for users because it allows them to share and re-engage with your content. It also allows Google to show a link to a specific point in the content, rather than the top of an infinite scrolling page.
To support paginated loading, provide a unique link to each section that users can share and load directly. We recommend using the History API to update the URL when the content is loaded dynamically.
Learn more with Google’s fresh Lazy Loading developer documentation.
Don’t Wait on Permissions, Events, or Interactions to Display Content
Interaction Observer > Onscroll Events
Using onscroll events to lazy load?
Googlebot won’t see it. Instead, use Googlebot-friendly Intersection Observer to know when a component is in the viewport.
Use CSS Toggle Visibility for Tap to Load
If your site has valuable context behind accordions, tabs, or other tap-to-load interactions, don’t wait for the area to be exposed to load it.
Load the content in the HTML or DOM and expose it using CSS functionalities.
You’re Never Getting That Permission
If your site asks for permissions, Googlebot will decline. These include geolocation, notifications, push, and many others listed on W3C’s permission registry.
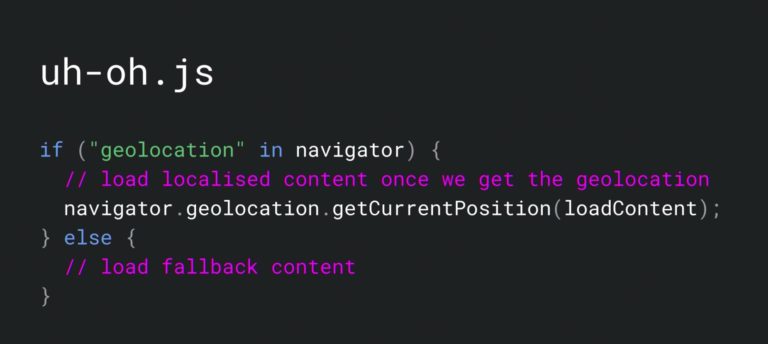
Crawlable Links Have Anchor Tags With Href Attributes
<a href=”/good-times”>
The concept of web crawlers is based on discovering content by following links. Your Angular content needs links with a href attributes to be discovered.
<a href="/good link">Will be crawled</a>
<span onclick="changePage('bad-link')">Not crawled</span>
<a onclick="changePage('bad-link')">Not crawled</a>
<a onclick="changePage('bad-link')">Not crawled</a>
Google does not pick images embedded with CSS styles.
Advanced image embedding options include using <picture> and srcset for responsive images.
Google’s recommendation is:
…that you always provide an img element as a fallback with a src attribute when using the picture tag using the following format:
<picture>
<source type="image/svg+xml" srcset="pyramid.svg">
<source type="image/webp" srcset="pyramid.webp">
<img src="pyramid.png" alt="large PNG image...">
</picture>
Use Inline Styles for Above the Fold Content
Script dependencies for above-the-fold content put your findability at risk. If your content can’t be rendered without waiting for script resources to load, search engines and users will likely experience a delay.
Optimize the critical rendering path by inlining critical CSS in the <head>, which allows above-the-fold content to render in the browser without waiting for the rest of the CSS to load.
Learn more about how to minimize render blocking CSS at Web Fundamentals.
Render Optimization
Googlebot love isn’t about whether a site uses JavaScript. It’s about how that JavaScript is rendered.
Rendering options and technologies are as bountiful as they are confusing.
Here’s a high-level overview of Angular rendering options. Grab a cup of coffee and sit down with your developers to review the detailed documentation on rendering options. As always, the devil is in the implementation and your experience may vary.
Client-Side Rendering (CSR)
CSR builds the page in the user’s browser. The initial HTML is an anemic shell. The user can only see and interaction after the main JavaScript bundle is fetched and rendered.
Discoverability rating: 👾
Performance rating: ⭐️
Server-Side Rendering (SSR)
HTML so good, you’ll be Bing proof!
Also known as Universal, SSR builds the page on the server and ships HTML. The method is server intensive and has a high Time to First Byte trade-off so you’ll need to be proactive in monitoring server health.
Discoverability rating: 👾👾👾
Performance rating: ⭐️⭐️
Notable achievement: 🌏 Ideal for non-rendering search engines
Dynamic Rendering
A terribly confusing cloaking (but not cloaking) short-term solution workaround for search engine crawlers. This technique requires having both CSR and SSR renderings available and deciding which to serve based on the user-agent.
Technologies like the open-source pre-rendering tool Rendertron can still be very useful for your business.
Crawlability rating: 👾👾👾
Performance rating: ⭐️
Sustainability rating: ⚰️
If you haven’t already implemented dynamic rendering, this option is likely past its best-by date.
Pre-rendering
Crawlability rating: 👾👾👾👾
Performance rating: ⭐️⭐️⭐️
Creates HTML at build time and stores it to serve upon request. Improved FCP and no SSR overhead.
Only works for static content – not for content that’s meant to change (think personalization and A/B testing).
Remember kids, your paid pre-rendering service owns you.
Today’s face palm: if you’re using React, don’t use a third party for server side rendering. If they go down or your credit card fails (example below) then your site will tank in the SERPs.
Self host https://t.co/7xAiWkW7XW for less headaches. pic.twitter.com/jkN3eMAvs0
— ˗ˏˋ Jesse Hanley ˎˊ˗ (@jessethanley) August 21, 2018
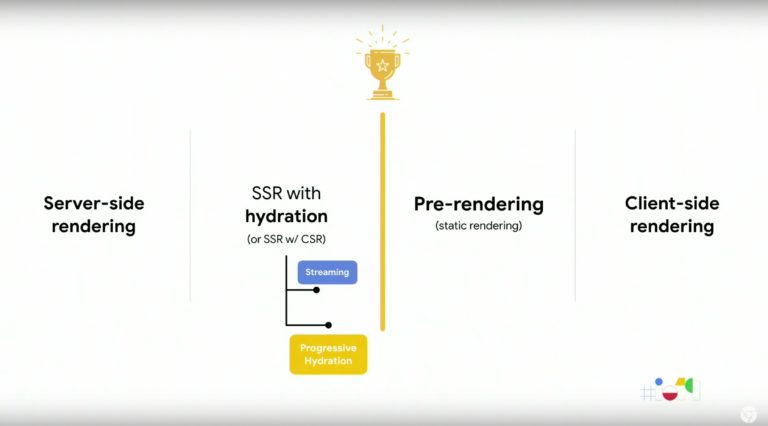
Hybrid Rendering (Server-Side Rendering with Hydration)
We want the speed of SSR, but the interactivity of CSR. Solution: SSR + Hydration.
Progressive hydration rendering looks to be the way of the future. It allows for component level code splitting.
Sites can postpone rendering components until they’re visible to the user or require interaction. Angular Universal has a built-in hydration solution: ngExpressEngine.
Crawlability rating: 👾👾👾👾
Performance rating: ⭐️⭐️⭐️⭐️
Index Coverage Optimization
Test With First-Party Tools
A technical SEO nightmare is getting a code release to prod and realizing it doesn’t render. The upgrades to Googlebot should mitigate polyfill and other cumbersome issues.
The best way to find out is to use Google’s tools to test. Search Console URL Inspector provides full rendering with screenshot scroll.
Mobile Friendly Test and Rich Results also return the DOM but won’t have screenshot scroll. You can even test firewalled and locally hosted builds.
Coming Soon: Googlebot User-Agent Updates
Googlebot’s user-agent will remain the same – for now.
We can expect Search Console tools to migrate to v8 rendering.
We can expect to see Googlebot user-agents to change once the migration is complete.
This will give us better insight into which version of Chrome Googlebot is using.
Cache Scripts Efficiently
Calls to scripts count toward your crawl budget.
If you’re using the same scripts on multiple pages, settings a cache expiry lets Googlebot request the script once and use it on relevant pages. Once the cache expires, Google will request the script again.
Get the most out of your scripts by using versioning. With versioning, you can set a long expiry date on your script. Hey Google, you can use /myscript.js?v=1 for the next year!
When a code release includes a change to that script bundle, my website will update the JavaScript bundle it references. Hey Google, use /myscript.js?v=2 to render this page!
Bundle Versioning Can Mitigate Rendering Issues Post-Release
If a web crawler attempts to render your page but is using an out of date script, the page could be incorrectly rendered.
If your page references the numbered versions to use, the search engine will check to see if that is the current version in the cache. If the versions don’t match, the search engine will request the correct bundle.

If Asynchronous Calls Have Unique Uris, Use X-Robots Noindex Directives
I have a webpage that loads 3 pieces of content asynchronously. Each of these AJAX calls has a unique URI:
https://example.com/ajax/meet-my-cat-cta
https://example.com/ajax/random-cat-picture-generator
https://example.com/ajax/featured-bean-toes
Every time Googlebot requests my webpage, it’s getting 4 URLs back. It’s not very resource efficient.
This is commonly seen during personalization or components that must make a logical check before deciding which content to give back.
The results can be highly effective. https://example.com/ajax/random-cat-picture-generator?cat=tank&&pose=bellyrubs is clearly part fantastic personalized experience for you, the user.

Every parameter combination is a unique URL. Googlebot treats unique URLs as unique pages (unless told otherwise).
One AJAX call unchecked could lead to thousands of confusing, low-value pages for search engines to sort through. That picture of Tank, the most handsome cat in the world, really adds to user experience but it’s about context.
AJAX Calls & Index Inflation
These URIs by themselves can muck up your index. A simple pair of parameters on an AJAX URI will breed like bunnies. Each can be unique and indexable.
Your index status will looks like a roller coaster – a stark climbing rise in the number of pages – followed by a gut-churning drop as Googlebot purges pages from their index.
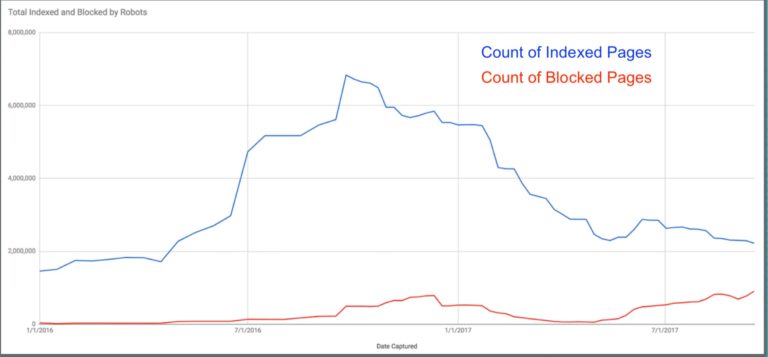
To avoid this, add X-Robots noindex directives to URIs that load content asynchronously to the page. This will create cleaner technical signals and make Googlebot resources spent on understanding my site more effective.
Make a New Developer Ally
Developers are some of the best allies an SEO can have. Google Webmasters recognize this and have created a new web series focused on the code changes needed to make a discoverable site.
Looking for a place to start? Check out Make your Angular web apps discoverable and SEO codelab for developers.
Tuck & Roll, My Friends
In summary, the keys to SEO for Angular are:
- Knowing the difference between HTML and DOM.
- Delivering content at the right time and place.
- Consistent, unique, and crawlable URLs.
- Being aware of your script resources’ indexability, size, response time, and caching policies.
This is the part where we work together to get everybody’s site out there alive and well.
The best way to learn Angular is hands-on so if you’re reading this, keep calm and remember the ancient digital proverb:
It’s not yours until you break it.
More Resources:
- Google Explains When JavaScript Does and Does Not Matter for SEO
- Understanding JavaScript Fundamentals: Your Cheat Sheet
- Google’s John Mueller Predicts Much More JavaScript in SEO in the Coming Years
Image Credits
In-Post Image #1: Created by author, May 2019
In-Post Image #2: Screenshot taken by author, April 2019
In-Post Image #3: Bartosz Góralewicz via Moz
In-Post Image #4: Taken by Jennifer Holzman at i/o 2018
In-Post Image #5: Screenshot from Archive.org, 3 April 2019
In-Post Image #6: Created by author, May 2019
In-Post Image #7: Screenshot taken by author, March 2019
In-Post Image #8: Screenshot taken by author, March 2019
In-Post Image #9: Created by author, April 2019
In-Post Image #10: Screencap from Google Search and JavaScript Sites (Google I/O’19)
In-Post Image #11: Screenshot of MDN Web Docs
In-Post Image #12: User-centric Performance Metrics, Google Web Fundamentals
In-Post Image #13: Screencap from Google Search and JavaScript Sites (Google I/O’19)
In-Post Image #14: Screencap from Rendering on the Web: Performance Implications of Application Architecture (Google I/O ’19)
In-Post Image #15: Screenshot taken by author, March 2018
In-Post Image #16: Glamorshot of incredibly handsome cat by author
In-Post Image #17: Screenshot and chart creation by author, April 2018
