

“Do you want to spend money on ads or solve this black box?”
That (rough) question helped to determine the path of my career 10+ years ago into becoming the SEO I am today.
I chose this path because I love working at challenges and looking under the hood for what causes something to happen.
Seeking to solve the answer to life, the universe, and everything given with the help of Google Deep Thought as 42 and then double-checking that I had the right question (spoiler: it’s six times nine) is what excites me with SEO.
And what got me to work on this article was a great discussion on Jeff Ferguson‘s post about whether we had the math to decode Google’s algorithm, and if so, what was it that the industry needed?
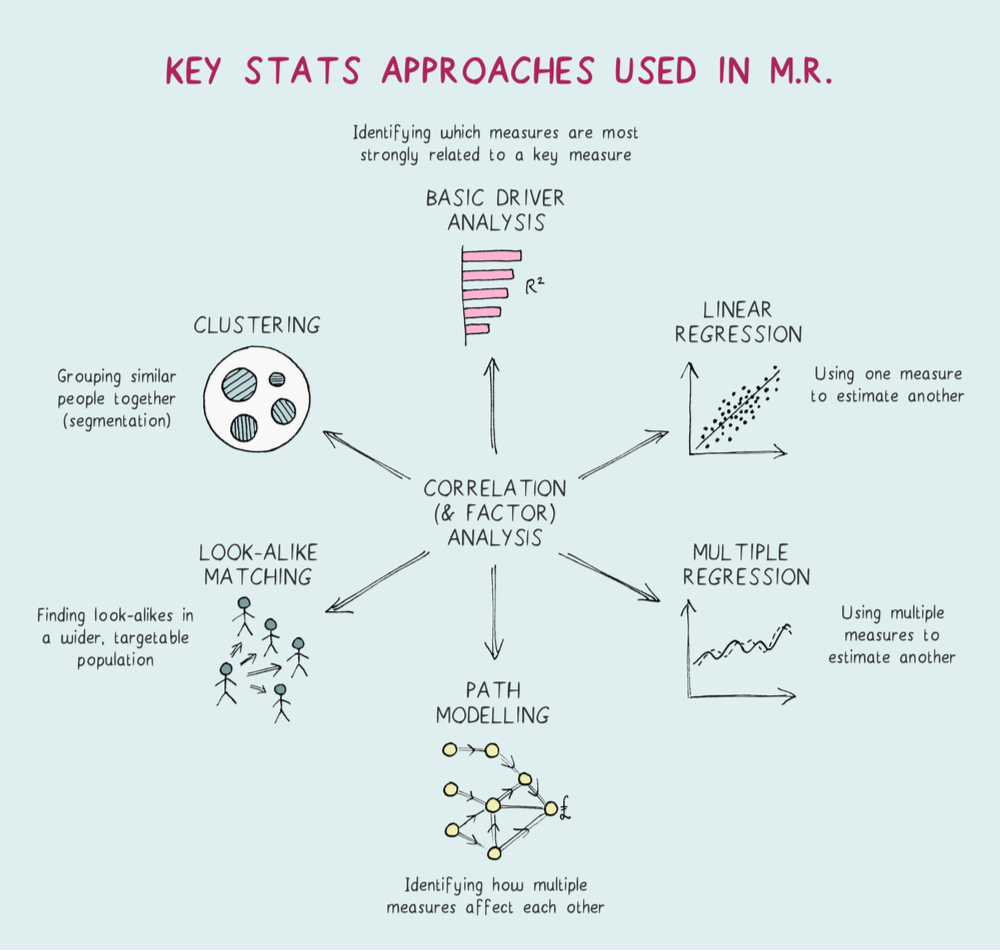
The Two Things Needed
So, for those that know me, you won’t be surprised to see that I stand against the view that a basic correlation analysis, even with the use of Spearman’s coefficient, is sufficient for analyzing Google’s algorithm.
Since my 2011 SMX East presentation, I have publicly advocated for the use of multi-linear regressions as the minimum for how one should analyze what matters.
Other advanced statistical methods, be it Machine Learning or Neural Networks, have their role to play.
But for this article, I’m focusing on regressions.
An important caveat to the use of statistical methods is that a tool by itself or tacked on at the end does not in of itself qualify as a good study.
That’s where having the right data analysis skills with SEO experience comes into play.
As seen repeatedly with COVID-19 analyses, just having a data analyst background is not sufficient to claim one can solve challenges in a Medium or Twitter post over epidemiology experts.
And while a few might seem to help provide valuable ideas to share, the predominant majority go without a strong caution with humility allowing misinformation to spread.
Need I remind the industry what happens when SEO misinformation spreads into the news by non-search experts?
The ‘I’m Not a Statistician, But…’
OK, so what gives me the right to point in the direction of advanced statistics for the studies?
A Master’s in International Relations with an International Economics concentration where I learned Econometrics and got the pleasure of tearing apart Econometrics papers on China’s economy.
There’s a reason why you’ll find me on Twitter tearing apart SEO correlation studies as they come out.
So, Why Regressions?
First and foremost, it’s no longer about analyzing a single measure in isolation.
Instead, it’s around multiple measures that also may interact with each other on what can impact rankings.
That mandates the use of a multi-linear regression at a minimum just on this point alone.
Beyond that, moving away from focusing on single metrics and instead of talking about the multiple factors push SEOs to think more broadly about a comprehensive set of metrics to work on to improve rankings.
And on the flip side, this prioritizes the work as 1,000 metrics may seem daunting, but if 900+ barely move the needle 0.1%, the certainty for which ones to work on speeds up the optimization tasks.
Further, the use of time series with regression analyses (where one analyzes the factors over a set period of time rather than at a specific point) can help smooth out the daily or weekly changes to focus in on the core areas, while providing insight into what major algorithm updates shifted.
And for agencies looking to gain credibility, look to the scientific fields for how they run regression analyses on complicated areas. For example:
- Sea level rise.
- Material science for superconductivity.
- Or, if you want something closer to SEO, what drives organic traffic to retail sites.
And while rare, specific submissions for SEO research papers do come up to enter in.
Good Analyzing Skills Matter
Logically, giving someone a tool without the right training doesn’t mean this will automatically lead to good results.
And that’s why having the right inquisitive mindset willing to delve deep (like a power user) and put the data through the ringer will complement the advanced statistical tool.
That mindset will work to determine:
- What data to collect.
- What has directional quality.
- Which to remove before one even begins an analysis.
It’s a fundamental standard that requires some SEO experience especially for recognizing in advance what metrics may be the underlying cause and how to avoid bias around demographics, seasonality, buyer intent, etc.
And having that SEO experience also means the analysis has a better chance for including worthwhile interaction effects to analyze, especially when an isolated optimization may not be seen as spam unless done in conjunction with other tactics. (For example, white text in a large paragraph on a white background without a way for the user to see it)
Furthermore, knowing that Google isn’t using a single monolithic algorithm means any analyses will need to include categories or groups, be it by:
- Keyword intent.
- Search volume.
- Ranking positions.
- Industries.
- Etc.
All the more reason why reviewing the data’s scatterplot to make sure there aren’t problems like:
- Heteroskedasticity: Data that fans outwards due to variability being unequal.
- Simpson’s Paradox: Two different populations showing the same trend that when combined together result in the opposite trend.
So, scatterplots or whisker plots are a must-have in these analyses as a way to show that study has avoided common statistical problems.
With the results, providing a standard regression result format helps those with statistical backgrounds to quickly and easily review the conclusions without having to separately run the regression just to double-check claim to the results.
Because a crucial part of a statistical study, and a common failing over the course of many publicly promoted SEO studies, is the interpretations are far from being reasonable.
Too often the credulous claims are used as linkbait rather than elucidate for the SEO community.
I often ask myself when I dig into these studies:
- Does the data set exclude potential outliers such as Wikipedia or Amazon?
- How does the study handle endogeneity where the ranking impacts CTR if the claim is CTR impacts ranking?
- Does a fantastical claim of direct traffic impacting rankings have the extraordinary proof to back it up?
- Why are rankings being shown on the X-axis? Okay, that last one is more my pet peeve.
And that’s where peer review comes in.
It’s one thing to double-check one’s own work for inaccuracies.
Peer review takes it to another level by helping to find blind spots, challenge assumptions made, improve study quality, and establish suitability of the work for the larger SEO community to trust.
All That in One Go?
In an ideal world, yes!
In reality, it will likely take a couple of steps (and missteps) to get there.
And I, and many statistically-minded SEOs, aren’t asking to follow a single example.
To generate model ideas, take a look at:
- My 2019 TechSEO Boost presentation.
- Michael King’s Runtime video.
See Hulya Coban‘s article for how to write a regression study as well as use Python to run a linear regression model.
That’s where the SEO industry needs to go if we really want to truly understand what is going on in Google’s algorithm, build a solid foundation of trust in the studies, and stop the disinformation out there.
What About This Study That…
OK, it depends.
Or more precisely, there are acceptable exceptions and some salient counter-points by Russ Jones that should be taken into account when correlation studies and software metrics have value.
I’ve got nothing against the private use of correlation studies to make an internal business use case.
Have at it.
Time is precious in the business world, so use what you can and own up if it fails.
In the public realm, the few worthwhile studies have been well-thought through using the right analytical framework with the right written care or focus on year-over-year changes in Google’s SERPs.
And articles highlighting methodology with data transparency requires well-deserved praise for being open.
Separately, there are SEO live testing studies through tools like SearchPilot.
These are more mathematically structured and I’ve worked with developers to build in-house and have publicly presented on the value of them since 2011.
So, the works of these studies from using PPC titles for SEO to the experiments done on Pinterest are a great stepping stone if you have the immense amount of traffic it requires.
Let’s Move Upwards
Outside of these, the advanced statistical methods and a solid data analysis skills with SEO experience is a must for what the industry needs to achieve.
And there are enough statistically-minded SEOs out there willing to help, review, and provide suggestions to make the studies become authoritative.
Yes, there is a lot of heavy critique in Twitter threads by these SEOs whenever a new study comes out, but it is from a well of caring for the industry’s reputation to prevent a study’s point becoming misconstrued pushing poor SEO and a desire for others to learn how to analyze a complicated system better.
And while a multi-linear regression model is not perfect given the need to rely on historic data and the amount of maintenance over time that can otherwise create a bias in the results, it is still a step in the right direction for the SEO industry becoming more statistically-minded.
Succinctly Put…
If you have the immense amount of data (as well as time and resources) required to do this right and want to become the first SEO agency, consultant, etc., to do this in the industry, here’s what will be needed:
- An advanced statistical model like multi-linear regressions.
- An inquisitive mindset with SEO experience.
- A large set of metrics, reduced in size by those with directional quality.
- Interaction metrics.
- Groups and categories of the data.
- A time period greater than a week.
- Endogeneity, heteroskedasticity, and other biases reviewed.
- Data outliers, if any, removed.
- Methodology explained.
- Work showcased with scatterplots and regression data formats.
- Claims backed up with sufficient amount of proof.
- Data and analyses peer-reviewed.
More Resources:
