
“Any sufficiently advanced technology is indistinguishable from magic.” – Arthur C. Clarke (1961)
This quote couldn’t apply better to general search engines and web ranking algorithms.
Think about it.
You can ask Bing about mostly anything and you’ll get the best 10 results out of billions of webpages within a couple of seconds. If that’s not magic, I don’t know what is!
Sometimes the query is about an obscure hobby. Sometimes it’s about a news event that nobody could have predicted yesterday.
Sometimes it’s even unclear what the query is about! It all doesn’t matter. When users enter a search query, they expect their 10 blue links on the other side.
To solve this hard problem in a scalable and systematic way, we made the decision very early in the history of Bing to treat web ranking as a machine learning problem.
As early as 2005, we used neural networks to power our search engine and you can still find rare pictures of Satya Nadella, VP of Search and Advertising at the time, showcasing our web ranking advances.
This article will break down the machine learning problem known as Learning to Rank. And if you want to have some fun, you could follow the same steps to build your own web ranking algorithm.
Why Machine Learning?
A standard definition of machine learning is the following:
“Machine learning is the science of getting computers to act without being explicitly programmed.”
At a high level, machine learning is good at identifying patterns in data and generalizing based on a (relatively) small set of examples.
For web ranking, it means building a model that will look at some ideal SERPs and learn which features are the most predictive of relevance.
This makes machine learning a scalable way to create a web ranking algorithm. You don’t need to hire experts in every single possible topic to carefully engineer your algorithm.
Instead, based on the patterns shared by a great football site and a great baseball site, the model will learn to identify great basketball sites or even great sites for a sport that doesn’t even exist yet!
Another advantage of treating web ranking as a machine learning problem is that you can use decades of research to systematically address the problem.
There are a few key steps that are essentially the same for every machine learning project. The diagram below highlights what these steps are, in the context of search, and the rest of this article will cover them in more details.
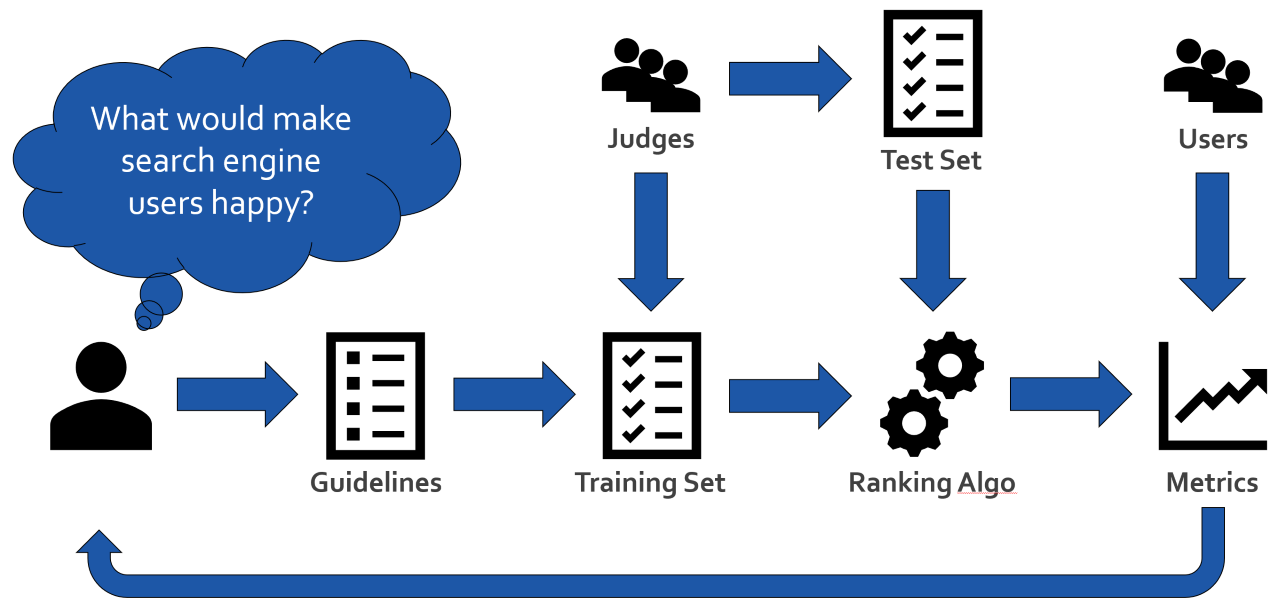
1. Define Your Algorithm Goal
Defining a proper measurable goal is key to the success of any project. In the world of machine learning, there is a saying that highlights very well the critical importance of defining the right metrics.
“You only improve what you measure.”
Sometimes the goal is straightforward: is it a hot dog or not?
Even without any guidelines, most people would agree, when presented with various pictures, whether they represent a hot dog or not.
And the answer to that question is binary. Either it is or it is not a hot dog.
Other times, things are quite more subjective: is it the ideal SERP for a given query?
Everyone will have a different opinion of what makes a result relevant, authoritative, or contextual. Everyone will prioritize and weigh these aspects differently.
That’s where search quality rating guidelines come into play.
At Bing, our ideal SERP is the one that maximizes user satisfaction. The team has put a lot of thinking into what that means and what kind of results we need to show to make our users happy.
The outcome is the equivalent of a product specification for our ranking algorithm. That document outlines what’s a great (or poor) result for a query and tries to remove subjectivity from the equation.
An additional layer of complexity is that search quality is not binary. Sometimes you get perfect results, sometimes you get terrible results, but most often you get something in between.
In order to capture these subtleties, we ask judges to rate each result on a 5-point scale.
Finally, for a query and an ordered list of rated results, you can score your SERP using some classic information retrieval formulas.
Discounted cumulative gain (DCG) is a canonical metric that captures the intuition that the higher the result in the SERP, the more important it is to get it right.
2. Collect Some Data
Now we have an objective definition of quality, a scale to rate any given result, and by extension a metric to rate any given SERP. The next step is to collect some data to train our algorithm.
In other words, we’re going to gather a set of SERPs and ask human judges to rate results using the guidelines.
We want this set of SERPs to be representative of the things our broad user base is searching for. A simple way to do that is to sample some of the queries we’ve seen in the past on Bing.
While doing so, we need to make sure we don’t have some unwanted bias in the set.
For example, it could be that there are disproportionately more Bing users on the East Coast than other parts of the U.S.
If the search habits of users on the East Coast were any different from the Midwest or the West Coast, that’s a bias that would be captured in the ranking algorithm.
Once we have a good list of SERPs (both queries and URLs), we send that list to human judges, who are rating them according to the guidelines.
Once done, we have a list of query/URL pairs along with their quality rating. That set gets split in a “training set” and a “test set”, which are respectively used to:
- Train the machine learning algorithm.
- Evaluate how well it works on queries it hasn’t seen before (but for which we do have a quality rating that allows us to measure the algorithm performance).

3. Define Your Model Features
Search quality ratings are based on what humans see on the page.
Machines have an entirely different view of these web documents, which is based on crawling and indexing, as well as a lot of preprocessing.
That’s because machines reason with numbers, not directly with the text that is contained on the page (although it is, of course, a critical input).
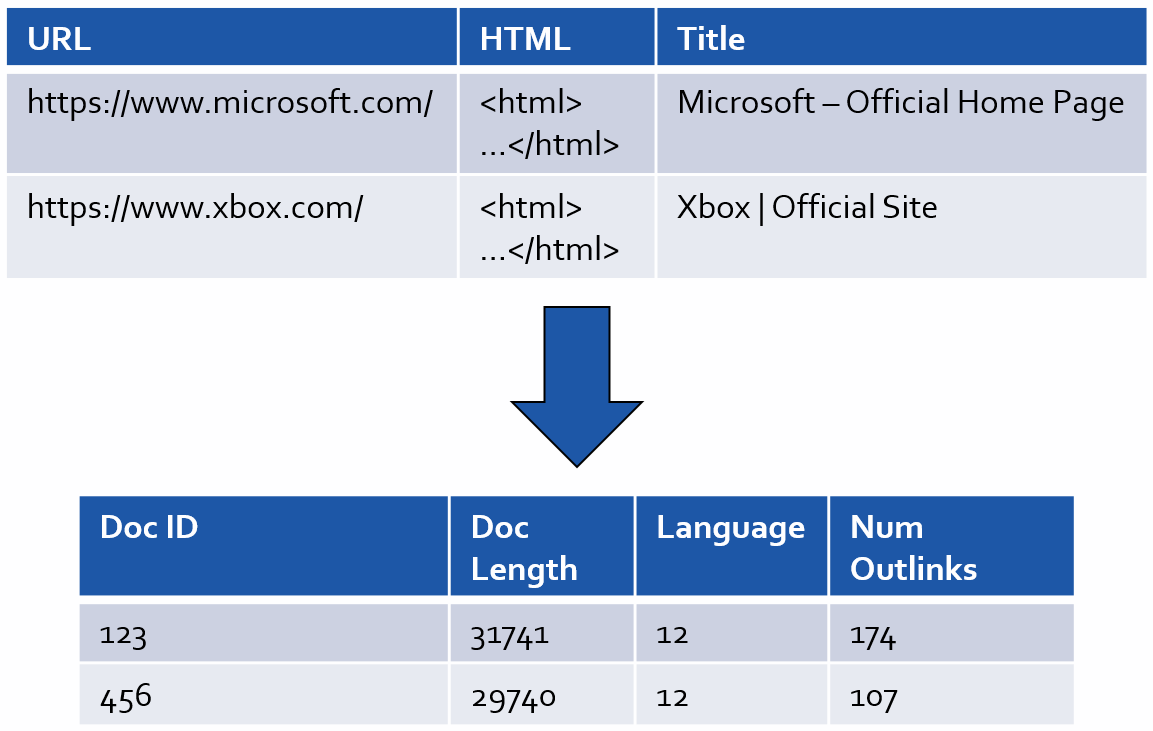
The next step of building your algorithm is to transform documents into “features”.
In this context, a feature is a defining characteristic of the document, which can be used to predict how relevant it’s going to be for a given query.
Here are some examples.
- A simple feature could be the number of words in the document.
- A slightly more advanced feature could be the detected language of the document (with each language represented by a different number).
- An even more complex feature would be some kind of document score based on the link graph. Obviously, that one would require a large amount of preprocessing!
- You could even have synthetic features, such as the square of the document length multiplied by the log of the number of outlinks. The sky is the limit!
It would be tempting to throw everything in the mix but having too many features can significantly increase the time it takes to train the model and affect its final performance.
Depending on the complexity of a given feature, it could also be costly to precompute reliably.
Some features will inevitably have a negligible weight in the final model, in the sense that they are not helping to predict quality one way or the other.
Some features may even have a negative weight, which means they are somewhat predictive of irrelevance!
As a side note, queries will also have their own features. Because we are trying to evaluate the quality of a search result for a given query, it is important that our algorithm learns from both.
4. Train Your Ranking Algorithm
This is where it all comes together. Each document in the index is represented by hundreds of features. We have a set of queries and URLs, along with their quality ratings.
The goal of the ranking algorithm is to maximize the rating of these SERPs using only the document (and query) features.
Intuitively we may want to build a model that predicts the rating of each query/URL pair, also known as a “pointwise” approach. It turns out it is a hard problem and it is not exactly what we want.
We don’t particularly care about the exact rating of each individual result. What we really care about is that the results are correctly ordered in descending order of rating.
A decent metric that captures this notion of correct order is the count of inversions in your ranking, the number of times a lower-rated result appears above a higher-rated one. The approach is known as “pairwise”, and we also call these inversions “pairwise errors”.

Not all pairwise errors are created equal. Because we use DCG as our scoring function, it is critical that the algorithm gets the top results right.
Therefore, a pairwise error at positions 1 and 2 is much more severe than an error at positions 9 and 10, all other things being equal. Our algorithm needs to factor this potential gain (or loss) in DCG for each of the result pairs.
The “training” process of a machine learning model is generally iterative (and all automated). At each step, the model is tweaking the weight of each feature in the direction where it expects to decrease the error the most.
After each step, the algorithm remeasures the rating of all the SERPs (based on the known URL/query pair ratings) to evaluate how it’s doing. Rinse and repeat.
Depending on how much data you’re using to train your model, it can take hours, maybe days to reach a satisfactory result. But ultimately it will still take less than a second for the model to return the 10 blue links it predicts are the best.
The specific algorithm we are using at Bing is called LambdaMART, a boosted decision tree ensemble. It is a successor of RankNet, the first neural network used by a general search engine to rank its results.
5. Evaluate How Well You Did
Now we have our ranking algorithm, ready to be tried and tested. Remember that we kept some labeled data that was not used to train the machine learning model.
The first thing we’re going to do is to measure the performance of our algorithm on that “test set”.
If we did a good job, the performance of our algorithm on the test set should be comparable to its performance on the training set. Sometimes it is not the case. The main risk is what we call “overfitting”, which means we over-optimized our model for the SERPs in the training set.
Let’s imagine a caricatural scenario where the algorithm would hardcode the best results for each query. Then it would perform perfectly on the training set, for which it knows what the best results are.
On the other hand, it would tank on the test set, for which it doesn’t have that information.
Now Here’s the Twist…
Even if our algorithm performs very well when measured by DCG, it is not enough.
Remember, our goal is to maximize user satisfaction. It all started with the guidelines, which capture what we think is satisfying users.
This is a bold assumption that we need to validate to close the loop.
To do that, we perform what we call online evaluation. When the ranking algorithm is running live, with real users, do we observe a search behavior that implies user satisfaction?
Even that is an ambiguous question.
If you type a query and leave after 5 seconds without clicking on a result, is that because you got your answer from captions or because you didn’t find anything good?
If you click on a result and come back to the SERP after 10 seconds, is it because the landing page was terrible or because it was so good that you got the information you wanted from it in a glance?
Ultimately, every ranking algorithm change is an experiment that allows us to learn more about our users, which gives us the opportunity to circle back and improve our vision for an ideal search engine.
More Resources:
- How Search Engine Algorithms Work: Everything You Need to Know
- Bing Shares 5 Algo Insights
- A Complete Guide to SEO: What You Need to Know in 2019
Image Credits
In-post Images: Created by author, March 2019
