

An Ex-Googler who was product manager of Blogger from 2003-2006 revealed that Google tolerated spam on it’s network. He said that resources were devoted to fight spam on the Search side but not for Blogger spam.
According to tweets by the ex-Googler, spam was tolerated in order to grow engagement metrics at Blogger.com. The comments were tweeted in the context of criticism of Google’s handling of low quality obscene and violent content on YouTube.
Blogger Spam has Been a Problem for Publishers
Spam on Blogger gave rise to a variety of link schemes. Spammers on Blogger have used the profile to host stolen content. Blogger spam has been a problem for legitimate publishers. It’s shocking to hear that Google did not devote enough resources to fighting spam on it’s own blog network.
Google Has Been Rumored to Tolerate Spam
In the early days of AdSense, WebmasterWorld Forum members noted a great deal of spam sites participated in the Google AdSense program. WebmasterWorld members called these spam sites MFAs, an acronym for Made for AdSense Sites.
Googlers are on record stating that there is a wall between AdWords and the Search team to prevent manipulation that would skew organic search results to favor the Pay Per Click side.
What I heard at the time was that there was no such wall between the AdSense and the Search departments. I don’t know if this is true. I’m just relating what I heard at the time.
Thus, the rumor went, Google could admit spam sites into the AdSense program while the Search side could take advantage of AdSense data to keep these spammers out of Google Search.
According to the rumors, the goal for admitting spam sites into the AdSense program was to increase engagement metrics but also to pollute Microsoft’s Bing search engine.
Again, I’m not saying this is true. I’m documenting what I heard because the tweet by the ex-Googler seems to partially confirm the rumor.
According to the ex-Googler, Google has a history of allowing spam on their network of sites for the purpose of increasing engagement while focusing their spam fighting resources on the search side.
YouTube Allegedly Allowed Low Quality Content
A Bloomberg article asserted that YouTube executives ignored warnings about troubles with YouTube content in order to pursue growth in engagement metrics.
That focus on growth on engagement metrics echoed what the ex-Googler tweeted.
 An ex-Googler, product manager for Blogger, asserted that Google turned a blind eye to spam content on Blogger in order to grow engagement metrics.
An ex-Googler, product manager for Blogger, asserted that Google turned a blind eye to spam content on Blogger in order to grow engagement metrics.“The company spent years chasing one business goal above others: “Engagement,” a measure of the views, time spent and interactions with online videos.
Conversations with over twenty people who work at, or recently left, YouTube reveal a corporate leadership unable or unwilling to act on these internal alarms for fear of throttling engagement.”
What the Ex-Googler Tweeted
The ex-Googler tweeted within the context of a discussion of YouTube’s issues with problematic content. He affirmed that Google’s commitment was to growing the platforms:
“Platforms believe that more use of their products makes the world a better place. As a consequence abuse is under resourced. Only in the financial world, like PayPal, did you see fraud prevention built in as a competitive advantage rather than a tax to be minimized.”
Google engineer Paul Haahr tweeted a counterargument based on his personal experience:
“I’d argue that web search engines have considered spam-fighting a core competency (and competitive advantage) since the early days.”
The ex-Googler agreed that Google devoted resources to the Search side.
Then he asserted that Google did not devote enough resources to the non-search platform side.
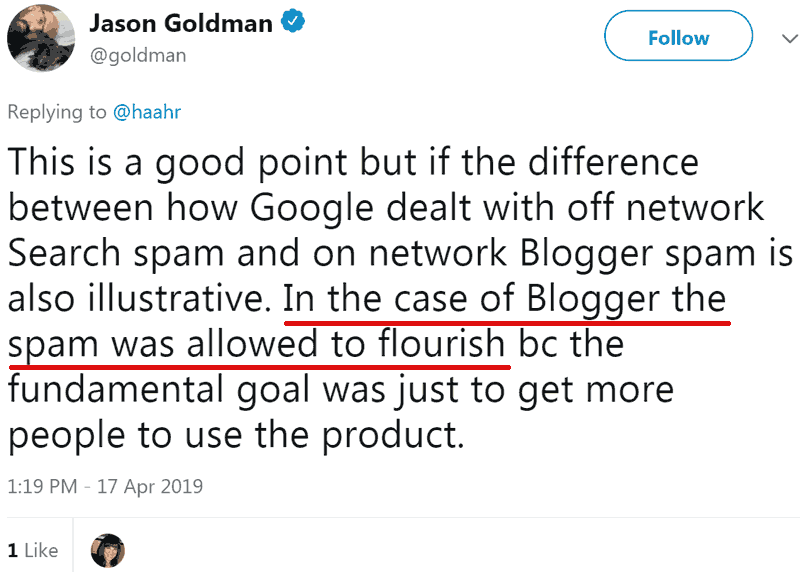
“This is a good point but if the difference between how Google dealt with off network Search spam and on network Blogger spam is also illustrative. In the case of Blogger the spam was allowed to flourish bc the fundamental goal was just to get more people to use the product.”
The Google engineer responded:
“I think my only knowledge of Blogger was from that first meeting we had after you folks were acquired, so I’ll defer to you on that. Does seem like a mistake. (We certainly cared about spam on Blogspot inside search.)”
To which the ex-Googler tweeted:
“Yah and that was the call – we can deal with it on the search side but let the pharma spam go on blogspot. To be clear I supported that call and it was embraced all the way up. But yah a mistake.”
Spam Embraced By Google Management
The shocking part of these tweets is that they revealed that the Blogger.com spam was known and approved by Google all the way up the chain of authority:
“it was embraced all the way up.”
These series of tweets appear to to give more credence to the rumors that Google knew about spam in the AdSense program and tolerated it. The statement also gives a peek into the mindset at Google with regards to spam on the search side versus on it’s content platform site. It hints at possible motives for not adequately policing YouTube for fear of slowing engagement metrics.
Images by Shutterstock, Modified by Author
Screenshots by Author, Modified by Author
