

A new negative SEO attack method has been discovered. What makes this exploit especially bad is that it is virtually impossible to detect the attacker. There is no way to recover if the attacking website is unknown.
So far, Google is remaining silent on how they intend to proceed to close this exploit in how Google ranks and de-ranks web pages.
It is noteworthy that this exploit has been observed but not tested and verified. If this exploit is real, it has the potential to disrupt Google’s search results in a major way.
How the Attack was Uncovered
The cross site canonical attack was discovered by Bill Hartzer of Hartzer Consulting. A business approached him about a sudden drop in rankings. During the course of reviewing the backlinks, Hartzer discovered links to a strange site.
But the client didn’t link to that site. Investigating that other site led him to the negative SEO site.
If that attacking site hadn’t linked to the third page Hartzer would not have been able to identify the attacking website. It was thanks to SEO data mining company Majestic’s new index that includes canonical data that Hartzer was able to discover the attacking site. (Editor’s Note: Hartzer is a Majestic Brand Ambassador.)

How the Canonical Negative SEO Works
The attack works by copying the entire “head” section of the victim’s web page into the head section of the spam webpage, including the canonical tag. The canonical tag tells Google that this spam page is the victim’s webpage.
Google then presumably assigns all the content (and the negative spam scores) from the spam web page to the victim’s web page.
What Does Google’s Support Page on Rel=Canonical Say?
Here is Google’s own support page on how Google handles rel=canonical. The following is form Google’s own support page:
Why should I choose a canonical URL?
There are a number of reasons why you would want to explicitly choose a canonical page in a set of duplicate/similar pages:
-
To consolidate link signals for similar or duplicate pages. It helps search engines to be able to consolidate the information they have for the individual URLs (such as links to them) into a single, preferred URL. This means that links from other sites to
http://example.com/dresses/cocktail?gclid=ABCDget consolidated with links tohttps://www.example.com/dresses/green/greendress.html.
What is Google’s Response?
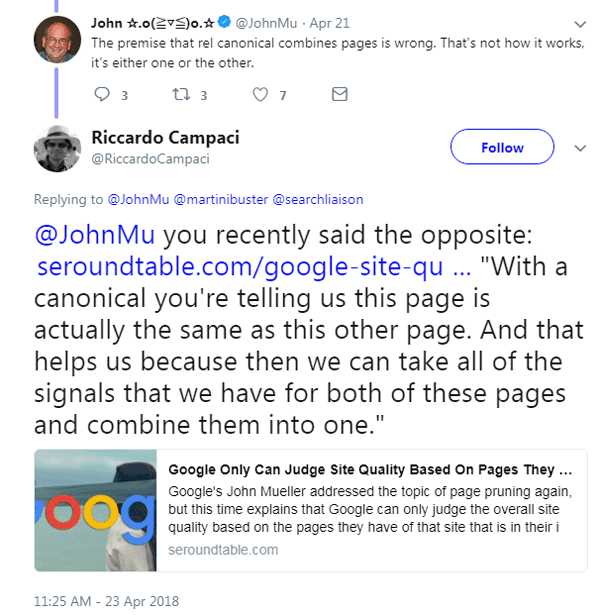
So far, Google seems to be focused on dismissing the idea without investigating it. John Mueller tweeted that Rel-Canonical was a decade old technology and something like this would already have surfaced. Here’s what “Google’s Mueller tweeted:
The rel canonical has been around for over a decade, people have tried lots of things with it. It’s a signal for canonicalization; one URL wins, the others’ crawls get dropped.
His argument is contradicted by the recent XML Sitemap Exploit, which was officially confirmed by Google. Just because a technology is a decade old does not mean it can’t be exploited. The recent XML Sitemap Exploit contradicts Mueller’s statement.
Furthermore, Rel=Canonical does more than affect the crawl budget. As you can see from the above quoted Google Support Page, Rel=Canonical combines link scores.
Mueller followed up and said:
“The premise that rel canonical combines pages is wrong. That’s not how it works, it’s either one or the other.”
But someone else on Twitter pointed out that this statement contradicted Mueller’s own words where he stated in an interview:
“With a canonical you’re telling us this page is actually the same as this other page. And that helps us because then we can take all of the signals that we have for both of these pages and combine them into one.”
That last statement by Mueller describes what Hartzer alleges to be happening. Hartzer is asserting that negative ranking signals from the attacking page, including outbound links to adult sites, gambling and so on are being combined with the page on the victim’s site.
The result is that the victim loses their ability to rank, presumably because of all the negative spam signals being attributed to the victim’s site.
- Statement #1 from Google, that because Rel-Canonicals is a decade old is not a valid reason to dismiss Hartzer’s alert. The confirmed XML Sitemap Exploit contradicts Google’s statement.
- Statement #2 from Google, that rel-canonicals doesn’t combine pages is not valid, because Mueller’s own words and Google’s own support page contradicts his assertion.
Publishers might feel a little better to know that Google is taking the report seriously and are looking into it. That is a better response than to not review the report and simply dismiss it with contradictory statements.
 Google’s John Mueller dismissed the idea of an exploit with a contradictory statement. Google has not yet stated whether they have tested whether this exploit works.
Google’s John Mueller dismissed the idea of an exploit with a contradictory statement. Google has not yet stated whether they have tested whether this exploit works.How to Detect This Attack
I asked Hartzer if there was an alternate way to detect these attacks. He said he tried a number of software tools, including Copyscape and many others. But so far only Majestic was able to identify some of the attacking sites.
“I tried the source code search engine publicwww but it doesn’t show the data – only Majestic actually is showing the relationship, and that’s because the one doing the negative SEO linked out,” Hartzer said. “In the other cases I’ve uncovered, though, the site is not linking out. I know there are other sites that they’re doing this to… seen a few others.”
Is Google Doing Anything to Stop Cross Site Exploits?
Kristine Schachinger, who has recently identified a similar exploit, offered these observations:
“Usually the attack method and the results can be directly tracked back to each other. But this time the vector of the attack is not in the site being attacked, but in a weakness in Google’s algorithms.
The attack is based on Google ‘perceiving’ the two sites as one. This transfers positive or negative variables between the attacker and victim sites.
The confusion persists for some time, meaning the attack has permanence beyond the lifecycle of the actual attack. This is a Google issue that doesn’t seem to be actively addressed by Google.”
Is this Exploit Real?
This exploit has been documented as having happened to several sites. But it’s noteworthy to observe that there have been no experiments to date to confirm that this kind of attack is possible.
What Can Google Do to Stop This Exploit?
If this exploit is real, it has implications on how Google and Bing use the canonical tag.
In practice, the canonical tag is not a directive. This means that unlike with a Robots.txt file, search engines are not obligated to obey the canonical tag. The canonical tag is treated by search engines as a suggestion.
If confirmed as a flaw in how the canonical tag works, then a possible solution may be for the search engines to update the canonical specifications so that it can no longer be used to canonicalize across different domains. Ideally, this is something that should be done through the Google Search Console.
More resources
Images by Shutterstock, modified by Author
