

There’s been discussion about a Google insider who claims Google filters traffic from publishers. Is Google filtering website traffic? As fringe as that idea sounds, there actually is a Google patent on filtering web results.
Bill Lambert is Not Real
This article was published several hours before Mueller tweeted the following denial. Added as an update.
As I suspected and this article concluded, John Mueller confirmed that the persona known as Bill Lambert is not a Google contractor with access to inside information.
Consider anything sourced from that persona to be misinformation.
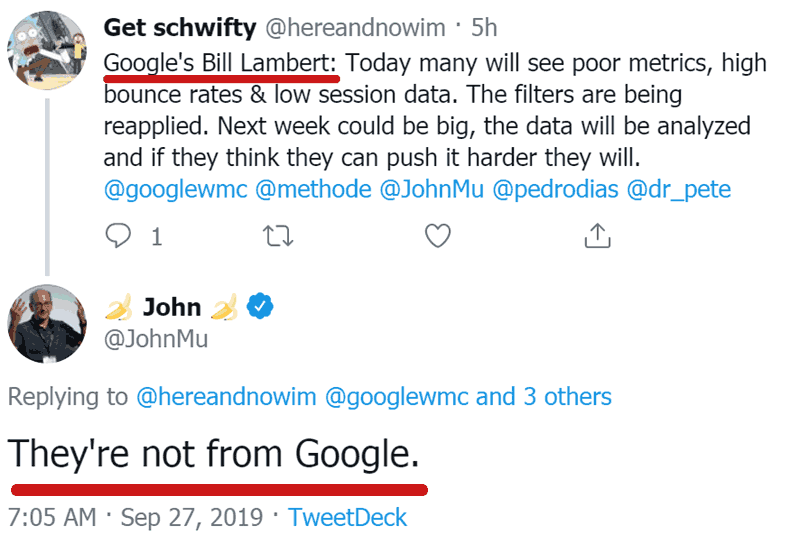
Claim that Google Filters Traffic
A WebmasterWorld discussion about Google’s broad core algorithm update quoted someone who claims inside knowledge about filters designed to take away publisher traffic.
In the quote they said:
“Bill Lambert: “As I explained, prior to an update you will see traffic & metrics like you are used to. This is because while the core algo is updated the various “filters” designed to take your traffic away are not live. While the update rolls you will see flux.
Post update you will see traffic levels around where they were prior to the update BUT these will slowly drop away. We are still in filter drop mode. Geo targeting will be out for the next few days too (as it was last week with the test).”
If you listen to Googlers and read patents and research papers, you will not find evidence of a Google filters that takes “your traffic away.”
But there is a patent about filtering the search results.
Google Filter Algorithm Patent
The Google patent is called, Filtering in Search Engines
The research focused on satisfying user intent and information needs by filtering the search results.
This is how the paper describes the problem:
“…given the same query by two different users, a given set of search results can be relevant to one user and irrelevant to another, entirely because of the different intent and information needs.”
The research paper then states that a problem with identifying user intent is that user intent varies by user.
“Most attempts at solving the problem of inferring a user’s intent typically depend on relatively weak indicators, such as static user preferences, or predefined methods of query reformulation that may be educated guesses about what the user is interested in based on the query terms.
Approaches such as these cannot fully capture user intent because such intent is itself highly variable and dependent on numerous situational facts that cannot be extrapolated from typical query terms.”
The proposed solution is to filter the results “based on content sought by a user.”
Then it describes a method of filtering results based on content in the URL, like the word “reviews” which signals that the page may satisfy the user intent.
The paper proposes creating a database that has a label that represents the search query and URLs containing words that match that search query.
“Annotation database… may contain a large collection of annotations. Generally, an annotation includes a pattern for a uniform resource locator (URL) for the URLs of documents, and a label to be applied to a document whose URL matches the URL pattern. Schematically, an annotation may take the form:
<label, URL pattern>
where label is a term or phrase, and URL pattern is a specification of a pattern for a URL.
For example, the annotation
<“professional review”, www.digitalcameraworld.com/review/>
would be used to apply the label “professional review” to any document whose URL includes a prefix matching the network location “www.digitalcameraworld.com/review/”. All documents in this particular host’s directory are considered by the provider of the annotation to be “professional review(s)” of digital cameras.”
I recall seeing something like this with two word search queries shortly after the Caffeine update. It looked like Google was excluding commercial sites for a specific SERP that used to feature commercial sites. After Caffeine it was preferring government and educational research related pages.
Except for one commercial site. One commercial site was still ranking.
That site had the word “/research” in the URL. Strange, right?
Google Filter Algorithm is Not About Taking Away Traffic
That patent is about satisfying user intent. It’s not about taking traffic away from publishers.
The idea of a Google algorithm that deprives users of traffic is part of an old myth. This myth holds that Google is purposely making it’s search results poor in order to increase ad clicks.
That myth is typically spread by SEOs whose sites have suffered in the search results and haven’t recovered. In my opinion it’s easier to blame Google of bad intents than it is to admit that maybe the SEO strategy is lacking. After all, commercial sites still rank for commercial queries.
The idea that Google filters traffic to help ad clicks is a myth. All information retrieval research and patents I have read focus on satisfying users. Google can’t win by being a poor search engine.
Only SEOs Talk About Google Filters
Filtering is an SEO viewpoint. Filtering is how an SEO sees things from their point of view.
Remember the theory of the Sandbox? SEOs believed that the algorithm was filtering websites that were new or that Google was filtering sites that had affiliate ads.
At the time, the SEO strategy was to create a website and link it up with directory links, reciprocal links and/or link bait viral links.
As we know now, Google was neutralizing the influence of those kinds of links. So it’s likely, in my opinion, that the filtering that SEOs thought they were looking at was really the effect of their outdated link building strategies.
The point is that “filtering” is culturally an SEO way of seeing things. It’s related to the word “targeting” in that SEOs tend to believe that Google “targets” certain kinds of sites in order to “filter” them out of the SERPs.
That is not not how Google describes their algorithms.
How Google Works
Google’s research and patents tend to focus on relevance.
- Understanding search queries
- Matching web pages to search queries
To drastically simplify how Google works, there are four basic parts to a search engine:
Google’s search engine has at least these four parts:
- Crawl Engine
Crawl engine is what crawls your site. - Indexing Engine
Indexing engine represents the document set - Ranking Engine
Ranking engine is where the ranking factors live - Modification engine
The modification engine is where other factors related to personalization, geographic/time related factors, user intent and possibly fact checking.
All of those engines do many things but filtering traffic to web publishers is not one of them.
Google Filters are an SEO Idea
From the outside, to an SEO, it might look like Google is filtering. But when you read the research papers and patents, it’s really about satisfying user intent, about relevance.
Maybe the link algorithm contains processes that identify suspicious link patterns. But that’s not the “filter” being talked about.
It’s a misnomer to call them filters. Research papers and patents, especially the most recent ones, do not refer to filters or filtering.
Filters are exclusively an SEO idea. It’s how some in the SEO community perceive what Google is doing.
That is one reason among many why it seems likely to me that the so-called insider is not really an insider.
Relevance is a Google Focus
Research and patents focus on relevance. The idea that Google filters search results to keep “traffic away” is outside of accepted knowledge about Google.
The claim can be accurately described as surreal.
It’s safe to say that Google ranks websites from the point of view of relevance, not filtering.
