



“Star Trek: The Next Generation” aired in 1987.
At the time, having a casual conversation with a computer must have seemed like far-flung science fiction.
Fast forward to today: We see people speaking into their watches, interacting, and getting voice responses from their phones.
It looks like we are almost there.
Not quite, though.
The allure of voice chat is undeniable – it’s faster, it’s hands-free, and it lets you multitask.
Especially with COVID-19, more people are turning to voice search.
According to Gartner, 32% of consumers are interested in hands-free technology that would limit touching or contamination.
Voice search is one of the fastest-growing types of search.
- 55% of users do voice search to ask questions on a smartphone, according to Perficient.
- 39.4% of U.S. internet users operate a voice assistant at least once a month, according to eMarketer.
Voice chat is also becoming increasingly reliable as technology improves.
Voice search is now no longer just a fad.
Beyond mobile phones, connected devices, and smart speakers, over 49% on Google Home and Amazon Echo users find them a necessity.
As voice search evolves from voice recognition to voice understanding, Google gets nearer to its aim to transform voice search into “an ultimate mobile assistant that helps you with your daily life so that you can focus on the things that matter.”
If voice search optimization isn’t already part of your SEO strategy, it’s time to fix that.
In this article, we’ll look at:
- How voice search has evolved.
- Six strategies to take you into 2021, and beyond.

The Evolution of Voice Search
Search Is Getting Smarter Than Ever Before
Few people type the way they speak – especially for search queries.
When you type, you adopt a sort of stilted shorthand, so you enter something like “weather Paris” into your search bar.
When you speak, you’re more likely to ask the complete question, “What’s the weather like in Paris?”
This pattern holds true with voice search queries as well.
As programs like Google Now, Siri, and Cortana become more popular, and their programming becomes more refined, it’s increasingly essential that search engines learn to interpret natural phrases.
AI is helping voice search become capable of interpreting and responding to:
Spelling Corrections / Queries
If you ask Google to show you a picture of Wales and you get a shot of whales, you can then clarify, “W-A-L-E-S,” and a picture of the country will now pop up.
What’s Been Previously Said / Searched For
If you ask, “Where is the Golden Gate Bridge?” and follow that up with, “I want to see pictures of it” and “Who built it?” Google can interpret what “it” is based on your initial search.
Alternatively, if Google cannot immediately answer a query, you can help it narrow down the answer through context.
So, if you ask “How high is Rigi?”, voice search may not respond because it’s an obscure mountain in the Swiss Alps.
But if you ask, “What are the mountains in Switzerland?” first, and follow that up with the query “How high is Rigi?” Google will tell you that it’s 1,798m in elevation.
Context Based on Location
If you’re at a Convention Center in San Jose and you ask voice search, “How far is the airport from the Convention Center?” Google will understand that “the Convention Center” refers to your current location in San Jose.
App-Based Context
If you’re chatting about a specific restaurant in an app, you can ask Google to “Show me the menu.”
Google will understand which restaurant’s menu you want to see based on context and bring up the menu for that restaurant.
Context & Conversation
Context and conversational search are now essential as voice search continues to evolve.
Marketers need to thoughtfully incorporate a voice search strategy into their websites and double down on excellent content, written in a conversational tone.
We also need to understand that people who type a query, and people who ask questions into voice search, are often two different types of people.
The “typer” might be OK with doing research, while the “talker” typically wants quick answers and instant results.
We need to appeal to both types of people.
For example:
Context of What You See On-Screen
Looking up a Wikipedia entry on Johnny Depp?
Asking voice search to “Show me pictures of Johnny” results in a smorgasbord of Johnny Depp photos because he’s the “Johnny” you currently have on screen.
Context About You
Asking Google “What’s my office address?” will bring up your office address, without the need to clarify who “my” refers to.
As Google works on conversational commerce and local search, we now use voice search to help make instant purchases.
Asking voice search to “Order me a large pepperoni and mushroom pizza from Pizza Hut” or “Show me blue jeans / Show me size 12 / Order me the pair from American Eagle” makes shopping easier.
6 Strategies for Voice Search Optimization Success
At its core, optimizing for voice search is similar to the SEO of yesteryear, but with a refined focus.
1. Understand Your Type of Customer & Device Behavior
Just as voice search algorithms use data, location, and several data points to understand search context, marketers have to dig deeper into understanding the consumer and their behavior.
Real-time data and research on consumer insights can help understand how different people use voice search and on what type of voice-enabled device.
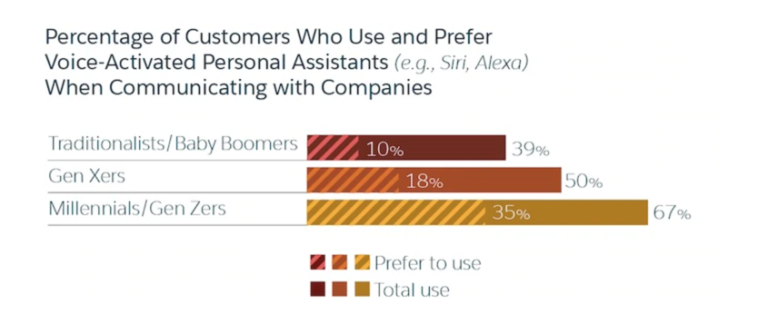
2. Focus on Conversational Keywords
While I don’t believe that short tail keywords will ever disappear entirely, they do become far less relevant when we consider the natural phrases used in voice searches.
More than ever, marketers need to focus attention on conversational long-tail keywords.
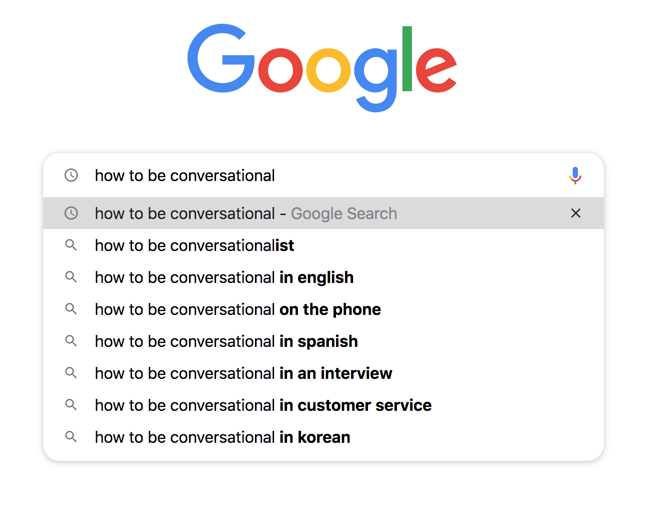
It’s essential to work out what questions you need to complete to answer.
3. Create Compelling Persona-Based Content
Brevity, context, and relevance are essential when optimizing for voice search.
What might be different from your usual SEO strategy is that now you also need to pay special attention to:
- Creating detailed answers to common questions.
- Answering simple questions clearly and concisely.
Create rich, compelling content that answers your users’ most common questions and solves their pain points.
A good strategy that’s already been adopted successfully by many websites is to:
- Create content or a webpage with a headline that asks a common question.
- Immediately after the headline, provide a concise answer or definition to the question.
- Use the rest of the page to provide further elaborative detail on the topic.
The significant thing about this strategy is that the rich, robust webpage ultimately appeals to Google’s ranking algorithm.
At the same time, the short-and-sweet information at the top of the page is optimized for voice search and might even become a featured snippet.
4. Provide Context with Schema Markup
Get acquainted with schema markup, if you aren’t already.
Use schema to mark up your content and tell search engines what your site’s about.
This HTML add-on helps search engines understand the context of your content, which means you rank better in typical searches, and more relevant in specific queries made through voice search.
Google understands language by utilizing schemas, and they can be a great way to add more information to your website, so you’re ready to answer questions.
According to Milestone Marketing research, based on 9,400 schema deployments, they found significant gains of +20-30% – with an average of:
- 40 schema types.
- 130 attributes and properties.
This is the kind of information mobile users and voice searchers will most often be after.
5. Build Pages That Answer FAQs
When voice searchers ask a question, they typically begin it with “Who,” “What,” “Where,” “When,” “Why,” and “How.”
They’re looking for answers that fulfill an immediate need.
To answer these queries, make a FAQ page and begin each question with these adverbs.
Then answer them conversationally to appeal to voice search.
From a performance perspective, make sure your website is technically sound and includes schemas.
Ensure navigation and informational structure are easy to find, and page load speeds are fast.
6. Think Mobile & Think Local
We are shifting to a mobile-first world where devices and people are mobile.
As a result, it is important to remember that mobile and local go hand in hand, especially where voice search is concerned.
Mobile devices allow users to perform on-the-go local queries.
Voice search, in turn, enables users to ask hyper-local questions.
Make sure things like directions to brick-and-mortar locations and XML sitemaps are readable to visitors and search engines on your website.
Also, create different experiences for desktop and mobile users – i.e., optimize for “near me” type searches on mobile.
Lastly, ensure your mobile strategy is sound and focus on improving page speed and load times.
Voice Search Optimization Moving Forward
Many that grew up in an age where technology couldn’t talk back still have a certain stigma attached to talking to our phones when another human being isn’t on the other end.
Younger generations don’t have that same hesitation, and most feel “tech-savvy” using voice search.
Voice search is clearly on the rise, and we’d be foolish to ignore this trend in the SEO industry.
It’s time to stop thinking about it and optimize for voice as it is a winner-take-all search result.
More Resources:
- 5 Voice Engine Optimization Strategies to Get Ahead
- 4 Reasons Why We Need Voice Search Analytics Now
- 3 Content Optimization Tips for Voice Search Success
Image Credits
All screenshots taken by author
