

Welcome back to another week where we look at some of the more interesting search-related patents awarded to Google.
If you didn’t catch last week’s post, we rounded up all of the patents of interest for the first half of 2020.
In our weekly entries, we don’t go into a deep-dive of the patents, more of an overview so that you can decide if you want to dig deeper.
Getting into Google patents is a great way to get a sense of how Google might be doing things out in the wild.
That can help you better strategize your SEO efforts and just make you a better practitioner in general.
Let’s get into some of the goodies from this week.
Latest Google Patents of Interest
Generating vector representations of documents
- Filed: September 12, 2016
- Awarded: October 13, 2020
Dave’s Notes
This is a tough one as there’s not readily anything an SEO can take from it to implement.
That being said, what is important with some of the elements within this (specifically, vectors, neural networks, and machine learning) is the understanding that Google has moved beyond simple “keywords” and older variations of semantic analysis.
I’ve written in the past about Word Vectors and even paragraph vectors.
Getting your head around this type of stuff is a good plan for the modern-day SEO professional.
Far too often, I find folks are rooted in the old-school approaches from Google that aren’t really as relevant in modern SEO.
Abstract
“Methods, systems, and apparatus, including computer programs encoded on computer storage media, for generating document vector representations. One of the methods includes obtaining a new document; selecting a plurality of new document word sets; and determining a vector representation for the new document using a trained neural network system, wherein the trained neural network system comprises: a document embedding layer and a classifier, and wherein determining the vector representation for the new document using the trained neural network system comprises iteratively providing each of the plurality of new document word sets to the trained neural network system to determine the vector representation for the new document using gradient descent.”
Notable
“Text classification systems can classify pieces of electronic text, e.g., electronic documents. For example, text classification systems can classify a piece of text as relating to one or more of a set of predetermined topics. Some text classification systems receive as input features of the piece of text and use the features to generate the classification for the piece of text.”
“A vector representation of a document that can be used as a feature of the document, e.g., by a text classification system, can be effectively generated. For example, documents that are semantically similar can have document vector representations that are closer together than the document vector representations for two documents that do not include semantically similar content. Thus, the vector representations can be used as document features for many useful tasks, e.g., finding documents that relate to a current document, or finding other documents that may be of interest to a user given that the user browsed a current document.”
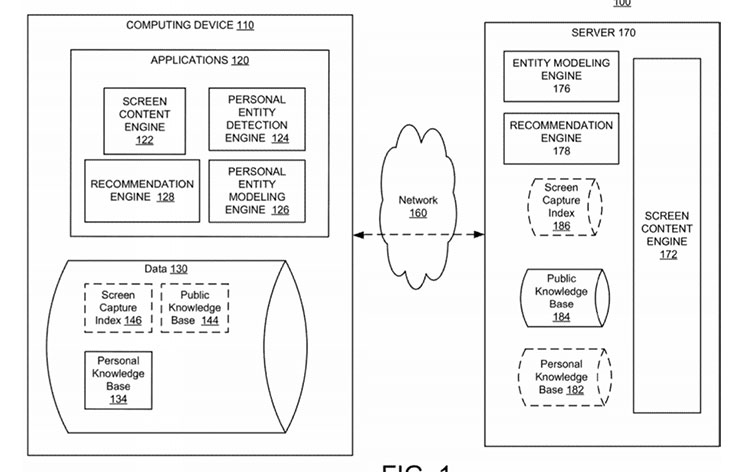
Modeling personal entities on a mobile device using embeddings
- Filed: July 29, 2015
- Awarded: October 13, 2020
Dave’s Notes
Once more, we’re not really going to get some form of direct information that an SEO professional can use in the wild.
But what we can learn from approaches such as this is that all may not always be as it seems.
Far too often I see SEO professionals in various settings talking about testing this or that.
The problem with that is there are so many layers of potential personalization elements that we don’t consider.
If I’m honest, the approach many take these days is far too simplistic for the depth of tech potentially in play at Google.
Another element of interest in this patent is the use of the term “personal knowledge base.”
Most SEO pros are familiar with larger knowledge base corpus, but a personalized set is something seemingly more finite and definitely worth reading into.
This one also discussed the “continous bag of words” concepts (and vectors), so here’s some more reading on those for you:
Notable
“The embedding spaces are learned and adjusted over time, so that the embeddings become a representation of a user’s personal knowledge base. The system can model entities in any content generated by a computing device, including screens on a mobile device, email messages in a user’s account, updates and posts in a user’s social media account, etc. In some implementations such as email systems, detection of personal entities may be based on a user specifically identifying the entity (e.g., in the sender or recipient address of an email).”
“ A feature can include other personal entities (e.g., from past and current screens), a public entity/topic, an application the entity most often appears in, etc. For example, the system may train the model to predict one entity given another entity (e.g., Mary and Rob are both often included in the same email stream or football is commonly discussed in communications to John). In addition, the system can be trained to predict personal sequences, such as the user typically reads email and then opens a news app.”
“In one general aspect, a method includes identifying a first personal entity in content generated for display on a computing device, the first personal entity being associated with an embedding in a personal knowledge base associated with a user of the computing device, predicting an association between the first personal entity and a second entity based on the embedding, and providing a recommendation related to the second entity, the recommendation to be displayed on the computing device.”
“As one example, once a modeling of personal entities (e.g., a personal knowledge base) is generated, the system can use it to predict words or phrases based on onscreen content, to identify circles or categories for the personal entities, to enhance on-device search with nearest neighbor retrieval, to personalize predictions (e.g., predict a recipient of a text message based on previous onscreen content, to bias entities related to a particular category when messaging a particular person, etc.), to personalize advertisements, etc.”
Providing results to parameterless search queries
- Filed: July 26, 2019
- Awarded: October 13, 2020
Dave’s Notes
This is certainly an interesting one.
From the way it reads, it’s predominantly focused on mobile devices and prediction/recommendation engine elements.
There’s certainly nothing new about the predictive type of algos with Google, this is just one that seemed interesting in that it attempts to think ahead for you.
One also has to consider that it might also be a bit on the freaky side given that there’s potential for Google to further decide what you want and who you are without any actions from your end.
But that’s a debate for another day.
One would also have to assume something like this would be cross implemented with Google Ads and other monetization systems.
For SEO professionals, this further makes the point that keywords and other term targeting aren’t the end goal these days.
In this instance, a strong local presence would likely be the more important element.
Abstract
“In one implementation, a computer-implemented method includes receiving a parameterless search request, which was provided to a mobile computing device, for information that is relevant to a user of the mobile computing device. The method also includes, in response to the received parameterless search request, identifying with a digital computer system one or more results that are determined to be relevant to the user of the mobile computing device based upon a current context of the mobile computing device. The method further includes providing the results for display to a user of the mobile computing device.”
Notable
“A parameterless search query is a search query that queries a mobile computing device for information that is relevant to a user, but where the user does not provide any parameters to further specify what is relevant to the user at a given time. Instead, a parameterless search query puts on the mobile computing device the onus of determining what the user is likely to deem relevant. To provide an indication of relevance to a user, a mobile computing device can examine a current context within which the mobile computing device and/or the user of the mobile computing device exist at the time the parameterless search query is received. A parameterless search query is a search query that does not contain any parameters for the search query (may also be termed a “zero input” query). Instead, a parameterless search query asks the mobile computing device to infer what a user of the mobile computing device wants to know (infer the parameters for the search query) based upon a current context for the mobile computing device (e.g., time of day, geographic location, calendar appointments, etc.).”
“For example, assume that a mobile computing device is moving with a user on a highway who is travelling at speed during rush hour on a workday (e.g., Monday-Friday). If the user submits a parameterless search query to the mobile computing device, the device can examine its current context (travelling on the highway during rush hour) and infer that the user would like to receive traffic information for the stretch of highway ahead. The mobile computing device can infer parameters for the search query (e.g., traffic conditions and highway number), identify results for the search query (e.g., expect to encounter stop-and-go traffic in two miles), and provide the results to the user (e.g., activate a speaker on the mobile device and audibly transmit the traffic conditions to the user).”
“ Given that it can be tedious and time consuming to provide input to a mobile computing device (e.g., typing on a smaller keyboard/screen), minimizing the time it takes for a user to receive relevant information can save the user time. Additionally, users of a mobile computing device may want to submit a search query to a mobile computing device while they are occupied with another task that makes providing the input impractical or unsafe, such as driving a car. In such situations, a user can provide a simple input (e.g., press a button on the mobile device, shake the mobile device, etc.) that allows the user to receive relevant information without requiring the user to exhibit impractical or unsafe behavior.”
“(…) it can often take several steps for a user to provide a search query with parameters to a mobile computing device to locate information that is relevant to the user. For example, if a user would like to quickly locate a nearby restaurant, the user may have to navigate through a variety of menus on the mobile computing device to reach a location-based search interface (e.g., interface for a map application) and then may have to type out parameters for the query (e.g., “restaurant,” “near current location”). With parameterless search queries, a user can obtain the information they are interested in without having to provide a formulated search query. Instead, using a parameterless search query, a user can access the information he/she is interested in by merely providing input to the mobile computing device that indicates a request for a parameterless search query. Such input can be simple and easy for a user to perform, such as shaking the mobile computing device a set number of times (e.g., shake one time, shake two times, etc.), pressing a button on the mobile computing device for a period of time (e.g., press and hold button for two seconds), providing a verbal command to the mobile computing device (e.g., commanding the device to “search now”), etc.”
Be sure to get your geek on and spend some time reading fully through these.
It will certainly help broaden your thinking as an SEO pro beyond the core simplistic elements that are the general fodder in the community.
See you next week!
More Resources:
- A Rundown of Google Patents from the First Half of 2020
- A Personalized Entity Repository in the Knowledge Graph
- Does Google Use Sentiment Analysis to Rank Web Pages?
Image Credits
Featured Image: Created by author, October 2020
In-Post Images: USPTO