
Will it ever be possible for Google to create an index of audio content that users can search through like web pages?
Results of early testing, which Google published in a blog article, indicates audio search is harder to accomplish than it might sound.
Details of these tests are shared in an article penned by Tim Olson, SVP of digital strategic partnerships at KQED.
Google is partnering with KQED in a joint effort to make audio more findable.
With the help of KUNGFU.AI, an AI services provider, Google and KQED ran tests to determine how to transcribe audio in a way that’s fast and error-free.
Here’s what they discovered.
The Difficulties of Audio Search
The greatest obstacle to making audio search a possibility is the fact that audio must be converted to text before it can be searched and sorted.
There’s currently no way to accurately transcribe audio in a way that allows it to be found quickly.
The only way audio search on a worldwide scale would ever be possible is through automated transcriptions. Manual transcriptions would take considerable time and effort away from publishers.
Olson of KQED notes how the bar for accuracy needs to be high for audio transcriptions, especially when it comes to indexing audio news. The advances made so far in speech-to-text do not currently meet those standards.
Limitations of Current Speech-to-Text Technology
Google conducted tests with KQED and KUNGFU.AI by applying the latest speech-to-text tools to a collection of audio news.
Limitations were discovered in the AI’s ability to identify proper nouns (also known as named entities).
Named entities sometimes need context to be understood to be identified accurately, which the AI doesn’t always have.
Olson gives an example of KQED’s audio news which contains speech full of named entities that are contextual to the Bay Area region:
“KQED’s local news audio is rich in references of named entities related to topics, people, places, and organizations that are contextual to the Bay Area region. Speakers use acronyms like “CHP” for California Highway Patrol and “the Peninsula” for the area spanning San Francisco to San Jose. These are more difficult for artificial intelligence to identify.”
When named entities aren’t understood, the AI makes its best guess of what was said. However, that’s an unacceptable solution for web search, because an incorrect transcription can change the entire meaning of what was said.
What’s Next?
Work will continue on audio search with plans to make the technology widely accessible when it gets developed.
David Stoller, Partner Lead for News & Publishing at Google, says the technology will be openly shared when work on this project is complete.
“One of the pillars of the Google New Initiative is incubating new approaches to difficult problems. Once complete, this technology and associated best practices will be openly shared, greatly expanding the anticipated impact.”
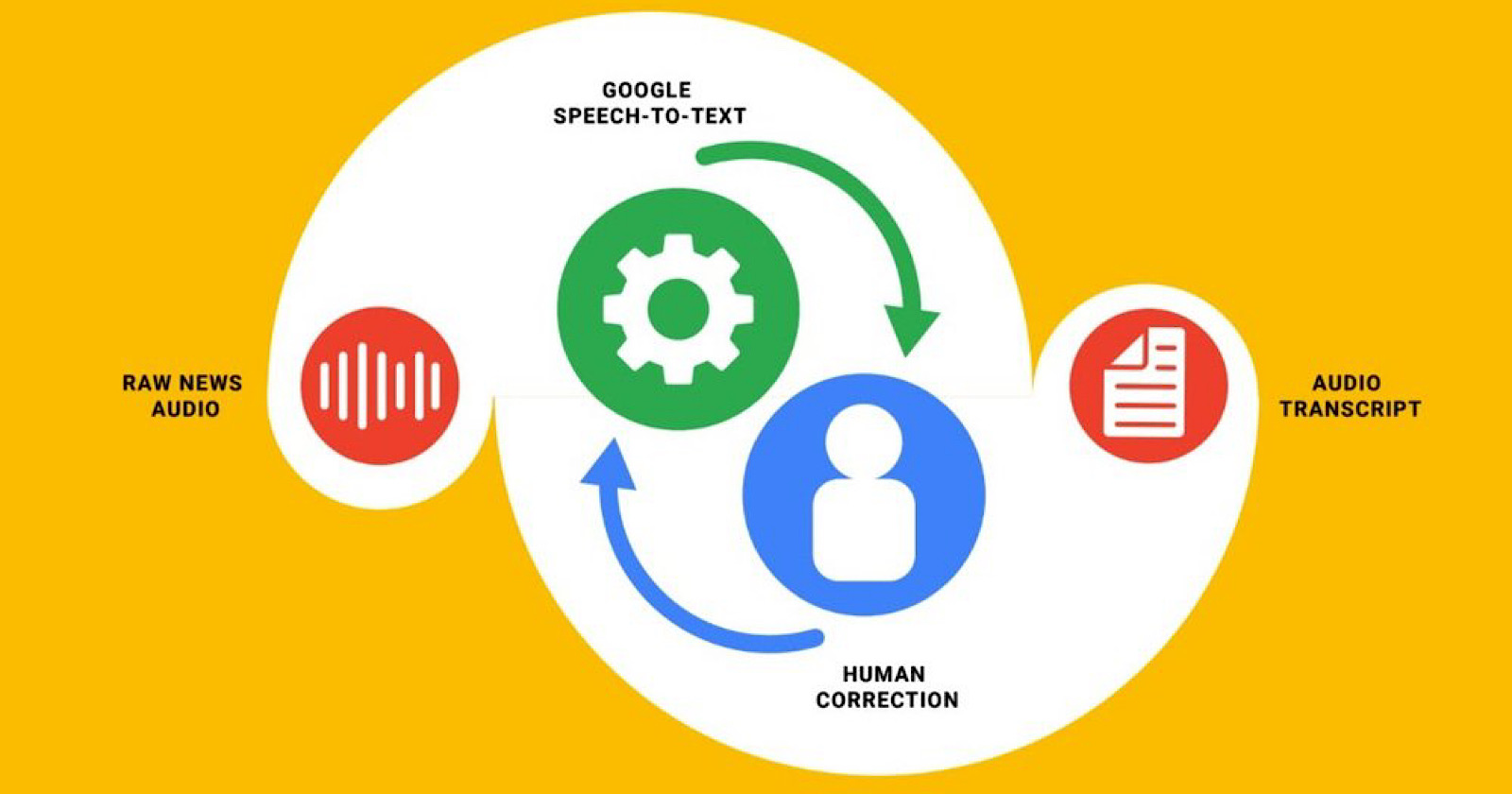
Today’s machine learning models aren’t learning from their mistakes, Olson of KQED says, which is where humans may need to step in.
The next step is to test a feedback loop where newsrooms help to improve the machine learning models by identifying common transcription errors.
“We’re confident that in the near future, improvements into these speech-to-text models will help convert audio to text faster, ultimately helping people find audio news more effectively.”
Source: Google
