

It is not an exaggeration to state that Google RankBrain was a revolution in how search results are determined.
In 1996 the idea of links as a ranking signal, revolutionized search with what would become Google PageRank.
It is why the past decade of search market share looks like this:
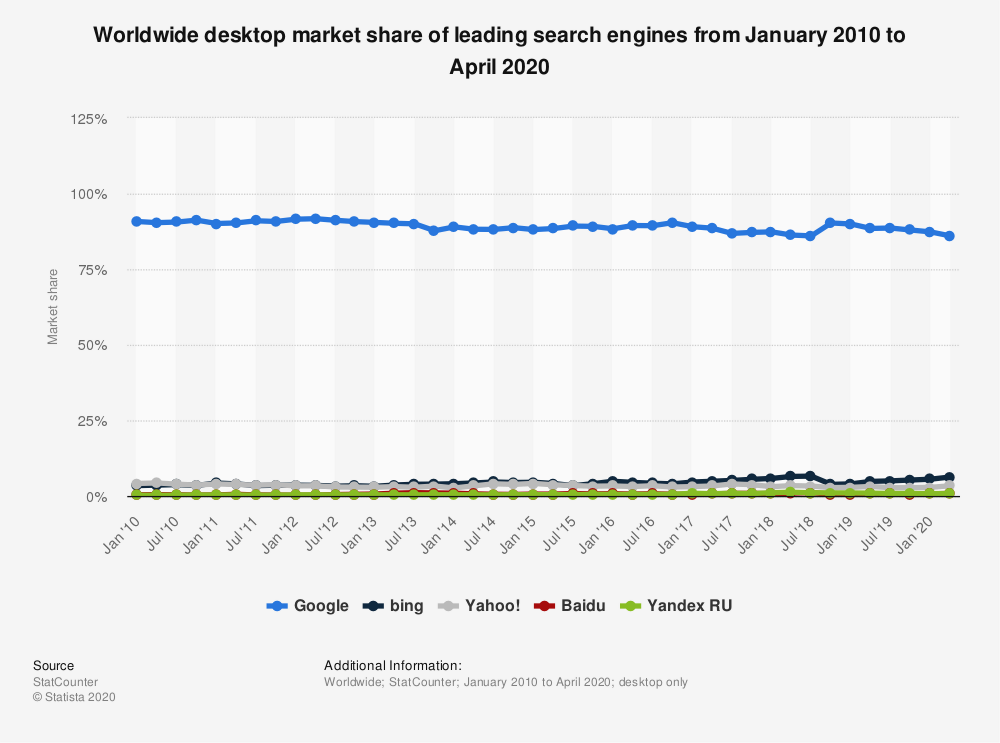
A lot has happened, and a lot of massive shakeups and algorithms have been introduced since then, but arguably none as important as RankBrain.
As we will discuss below, this is not due only to its impact on results (though it arguably wins there too) but rather what it meant – machine learning was introduced into what we think of as search for the first time.
Machine learning had been used in Google News prior to this, but nothing like we were seeing with RankBrain.
So, it was important. It was revolutionary. It was the introduction of machine learning in search.
But …
What Is RankBrain?
RankBrain is a system by which Google can better understand the likely user intent of a search query. It was rolled out in the spring of 2015, but not announced until October 26 of that year.
At inception, RankBrain was applied to queries that Google had not previously encountered which accounted then and still does, for about 15% of all searches. It was expanded from there to impact all search results.
At its core, RankBrain is a machine learning system that builds off Hummingbird, which took Google from a “strings” to “things” environment.
This is to say, it took it from “reading” literal characters, and instead “seeing” the entity they represented.
A Quick Aside About Entities & Things Over Strings
To illustrate this important advancement and its role in RankBrain, we need simply consider the characters that make up the name of a peer and friend of mine:
“jason barnard”
Until Hummingbird, Google saw those characters and a collection of 2 words and 13 characters which, arranged in that order, and used on a page often enough, would make it relevant for the search string “jason barnard”.
It could be any Jason really, that didn’t matter.
They relied on links and a few other signals, to surface the most “relevant” one, without understanding who or what Jason was.
With Hummingbird, my friend is no longer a simple collection of characters but rather, became the entity:
/g/11cm_q3wqr
Which is the Machine ID of this guy:

A Machine ID in this case is an alphanumeric sequence that Google assigns to an entity.
We can’t dive into entities in great detail in this article, though you can read about them here.
In short though, what happened with Hummingbird that was necessary for RankBrain to function, was it turned Google from seeing the statement:
“Jason Barnard is a friend of Dave Davies who likes red shirts, and is a digital marketer.”
And simply interpreting it as a series of characters to be arranged and weighed against the query.
While very advanced, there were basically stuck answering the question: How many times does “jason barnard” appear in the text, and in links to that text?
Assuming the query is again “jason barnard”, with Hummingbird that sentence would look to Google more like:
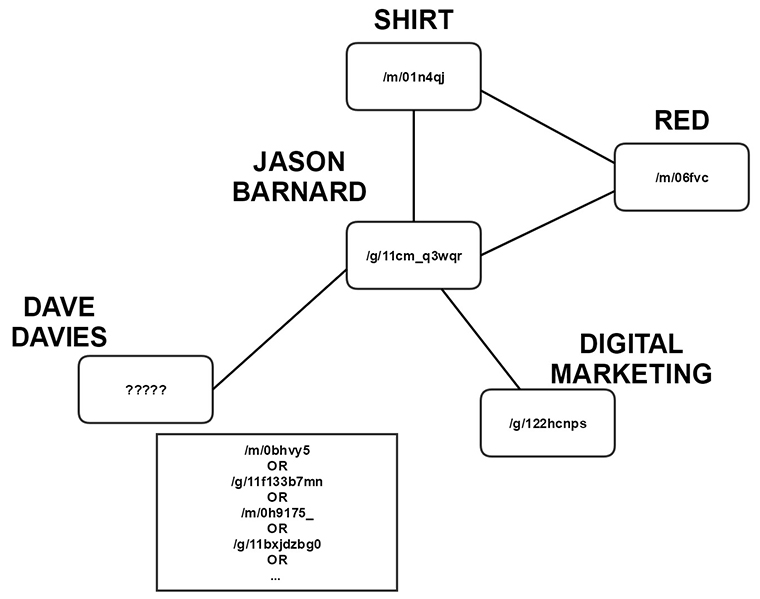
Each core entity is represented by a Machine ID.
These IDs are unique to each one – and no two entities have the same ID.
I purposely added myself into the sentence to illustrate that it isn’t always perfect.
My name is very common, and there are more notable “dave davies” out there than me (I know, I know… hard to believe).
Because of Jason’s background in music, Google could easily assume without additional context, that the Dave Davies that Jason was friends with is the Dave Davies (/m/01pwfk) from The Kinks (/m/08w4pm).
Google would get clarification via other entities on the page, and other connections on the web. But that’s another story, for another day.
What’s important to know in the context of RankBrain, is that with Hummingbird, Google (/m/045c7b) now understood the world as a collection of things and not strings.
Back to RankBrain
With that bit about entities under our belts, we can get back to RankBrain.
RankBrain, at its core, can be thought of as a pre-screening system.
When a query is entered into Google, the search algorithm matches the query against your intent in an effort to surface the best content, in the best format(s).
But what if Google doesn’t know your intent?
Why Did Google Introduce RankBrain?
RankBrain was initially rolled out to satisfy one simple but large problem.
Google had not seen 15% of queries used, and as such had no context for them, nor past analytics to determine if their results were good or not at satisfying the user’s intent.
Enter RankBrain.
This system would look at the things instead of the strings.
RankBrain would also consider environmental contexts (e.g., searcher location) and extrapolate meaning where there had been done.
This could be a simple process of understanding that word order may be a function of the search process, and not the intent.
Who among us hasn’t refined a query by simply tacking on a word or two.
Before I entered it, Google has certainly seen:
“pizza victoria bc”
But when I didn’t get back the assortment I wanted, I might just start adding on terms, resulting in a query more like:
“pizza victoria bc thin crust veggie”
There’s a good chance Google hasn’t seen that specific query, but because they are looking at things and not strings, they know that the query would be similar, if not the same, as:
“thin crust vegetarian pizza victoria bc”
“thin crust veggie pizza near me”
Or with voice:
“OK Google, where can I get a thin crust vegetarian pizza?”
How Does RankBrain Work?
Unsurprisingly, Google has never outlined how RankBrain functions specifically.
Nonetheless, we can make some educated guesses about what’s going on behind the scenes.
New Search Function
As discussed above, we need to stop thinking in terms we understand, and start thinking like a machine.
Where I might see:
“pizza victoria bc”
Google sees:
/m/0663v /m/07ypt
This dramatically changes things. “victoria bc” is not two things, but one.
When comparing other locations for:
“pizza” “location”
They can extrapolate that:
/m/0663v /m/07ypt (pizza victoria bc)
Is likely the same as:
/m/07ypt /m/0663v (victoria bc pizza)
Basically, because they know the nature of how entities function, they can look beyond the query, and into the meaning.
Common Entities
As outlined above, one of the core mechanisms they will use is entity recognition.
If they understand that a query contains the same entities as another they have seen before with little in the way of qualifiers (such as changing from “where” to “when” in a query about a concert), then that would be an indication that the result sets may be identical, highly similar, or at least drawn from the same shortlist of URLs.
The Top 10
In their 2013 patent, Question answering using entity references in unstructured data, Google describes a method in which they would:
- Submit the entities into their own index.
- Review the entities within their own top 10.
- Extrapolate from that the various entities they would expect to be related both to each other, and to top answer to queries.
For example, if Google sees the ID for Jason and the ID for me often co-occurring, they would be able to connect the two.
If it were Jason and that pesky Kink’s guy who keeps ranking for my name… then they would conclude that it was that Dave Davies.
Similarly, if they see that pages that rank for Jason’s name also have a common set of entities on them, they can assume that complete data on Jason includes that information and omit those without it for that query.
Monitoring
Remember that this is a machine learning system.
Inherent in that is the function to determine, test, track, and adjust.
Basically, the system will be looking at queries with a success metric(s) in mind.
It will then adjust how it weights different signals and which it favors, and then monitor for success.
This will not be done on a query-by-query basis.
Remember, this system launched to address the problem of queries that Google had never encountered before, there are going to often be no-or-low volume words that can’t be monitored themselves.
Rather the system will look for patterns like:
[food item] [location] [qualifier]
and then creating rule sets that govern all such queries.
So, if it found that weighting of signals worked for a query like:
pizza victoria bc vegetarian
It could use that to support or augment what it does with a query like:
tacos seattle wa chicken
Also, worth noting, the system will not just be considering the entities in the query, but the entities involved with making it. That includes you, your location, your device, etc.
These are all variables that RankBrain would take into consideration in much the same way you likely look at your analytics and compare your desktop with your mobile traffic, or review the hour of day or device types to understand how different users interact with your business in different scenarios.
Likely About a Dozen More Things…
The folks at Google are smart.
I have literally zero doubt that if one of the engineers responsible for the upkeep of RankBrain reads this article they’ll simply smile and think, “Aw … isn’t that cute? A little SEO who thinks they know what’s going on behind the curtain… again.”
They undoubtedly have dozens more mechanisms going into RankBrain than I’ve thought of, and the machines may have made up even more of their own.
What we want to keep in mind is the purpose.
The purpose is to understand queries.
The variables we need to contend with are entities and signals and what the machines do with them.
Rolling Out RankBrain Like Pizza Dough in Victoria …

So, RankBrain was developed to deal with queries that Google has never seen before.
But that changed somewhere between the spring of 2015 and 2016.
It seems the folks at Google once more didn’t give us a heads up, as it was slipped into an article with Wired in the present tense.
“Rankbrain is involved in every query.”
Once more, it seems, Google rolled it out without telling anyone.
At that time, and presumably more now, it was considered highly effective and labeled as the third most important ranking signal.
That’s probably the wrong way for us to think of RankBrain, but let’s not worry about semantics.
Instead, knowing its importance (and yes it still is, very – if not more important when combined with other systems) let’s focus on …
How Do You Optimize for RankBrain?
At its core, you don’t optimize for RankBrain.
But that’s a bit of a cop-out answer.
Let’s try to do better.
Google’s Gary Illyes stated at SMX that you can’t optimize for it back in 2016:
You don’t optimize for RankBrain says @methode #smx
— Barry Schwartz (@rustybrick) June 23, 2016
And later, basically said it’s just optimizing for users:
you optimize your content for users and thus for rankbrain. that hasn’t changed
— Gary 鯨理/경리 Illyes (@methode) September 26, 2019
But to me, that’s a bit of a Googley statement.
My advice for those wanting to optimize for RankBrain or better worded, optimize their site and take RankBrain and similar systems into consideration?
Don’t look for tricks.
Look for function.
A free tool that’s interesting to use in this task is Google’s own Natural Language API Demo.
Let’s say we want to understand how Google sees the article I linked to above on entities.
What better way than to go to the source – Google.
We can copy the text of the article, paste it into their NLP demo, and voila!
We are given their analysis of which entities appear on the page along with sentiment analysis and syntax.
You’ll notice that syntax arrows travel both forward and backward.
You can thank BERT for that being relevant, not RankBrain.
Here’s what it looks like:
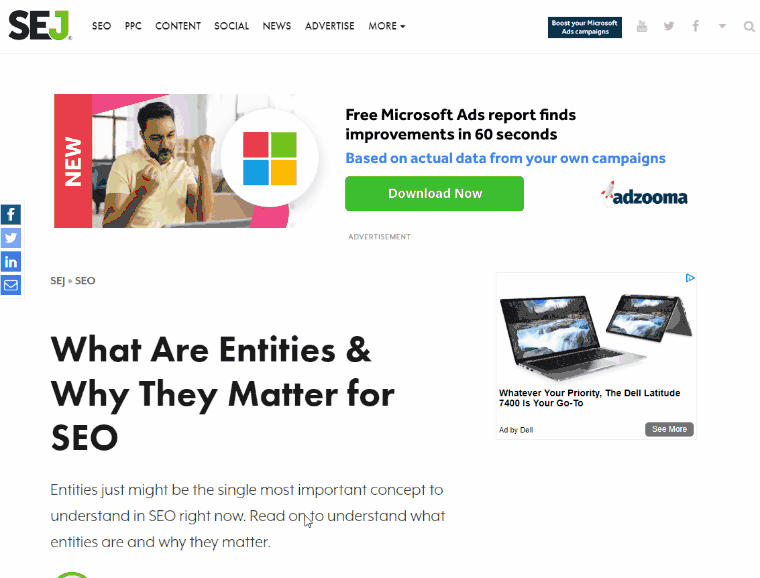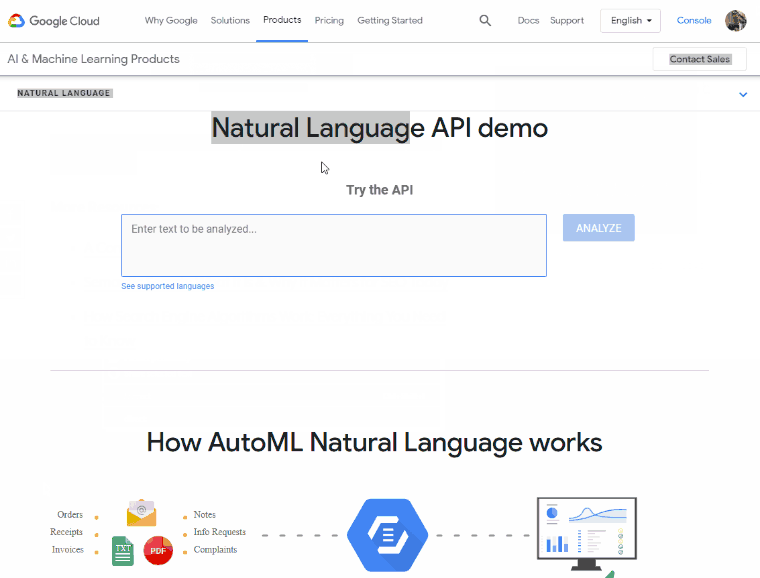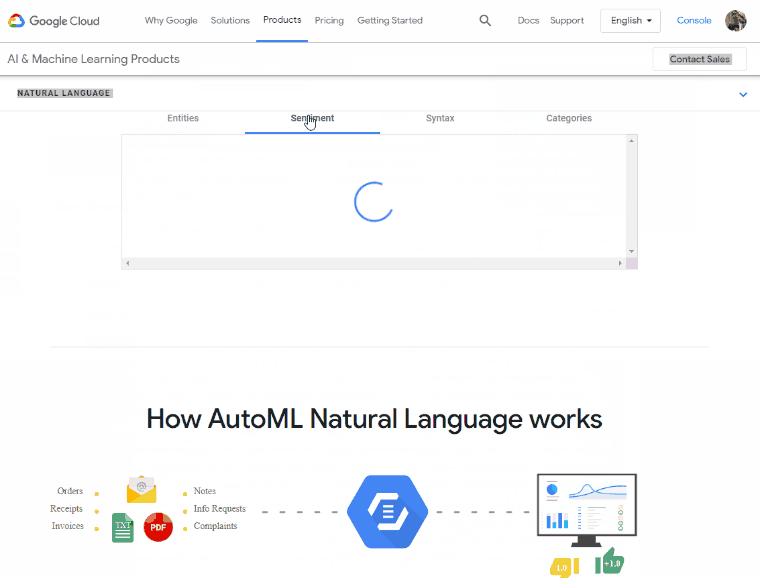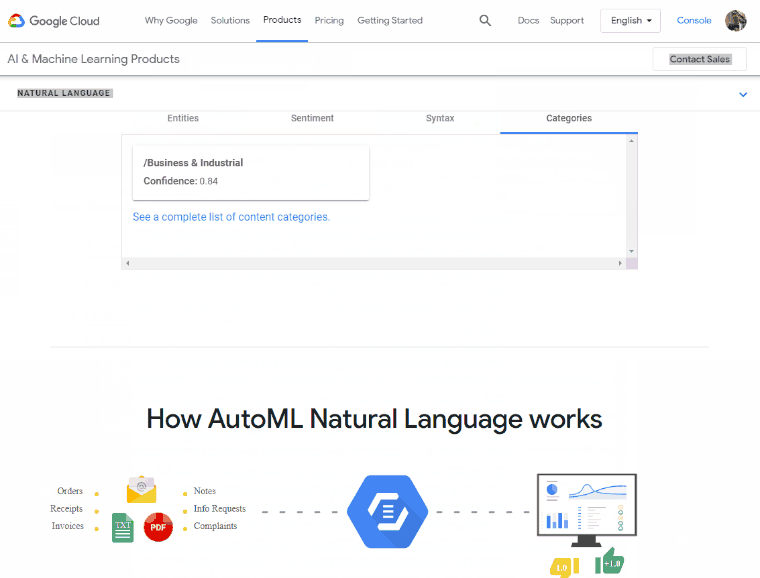
If you scroll down on the Entities list, Google also presents to you a full breakdown of the types of entities on the page.
I need to note, these are far from perfect and meant to work as a default entity set to train with – not a complete list of how Google views the world.
But it does give a nice, visual understanding of your content.
Another free tool I like for this is Google Knowledge Graph API, but the output isn’t particularly pretty.
Thankfully, that same friend I used in my example above has tapped into is in his free Knowledge Graph Explorer.
With the Knowledge Graph Explorer, you can manually check and see what Google is seeing about an entity in realtime.
It doesn’t take into consideration the relationship between other entities on the page, and Google really would boost the confidence they had the right entity, but it’s quite enlightening.
With these two tools you can explore how Google perceives the top ranking sites for various queries, what entities are on the pages, whether they are people, places or things, etc. and get a real understanding of how Google is interpreting the page from a Hummingbird perspective.
From there we need them only to consider the variables we can’t control or see, such as the likely user location, device, etc.
So yes, consider the user – Google is right there.
So, to “optimize for RankBrain”:
- Review the entities with the NLP API.
- Deeper dive into entity Knowledge Graph Explorer.
- Take all of this and put it in the context of you (what device and location you have).
- Run some tests from other locations and devices using a tool like Mobile Moxie to compare the results and understand how things skew.
- Start optimizing for RankBrain.
Google will tell you that optimizing for RankBrain is optimizing for users.
It’s pretty easy to see how that’s their suggestion, and it’s not a bad one.
But we know it’s built on entities.
So why not add that knowledge into your efforts?
Understand how Google interprets the user intent, and you’ll understand how to do it yourself.
Why Is RankBrain Important?
RankBrain is important not just for what it is, but for what it means.
It was the first push into machine learning being applied to search results at Google. It was not the last.
In fact, as far back as 2018, John Mueller noted:
I think that train has left the station – we use machine learning in so many places, it doesn’t make sense to try to single out RankBrain and to guess individual factors involved. Ranking is complex. Sorry for not having a simple answer, but IMO the question is irrelevant :).
— 🍌 John 🍌 (@JohnMu) November 5, 2018
Is RankBrain Still the Third Most Important Signal?
Unlikely. But I’ve never really thought of it as a signal to begin with.
I’ve always thought of it more as a pre-conditioner – a system that didn’t produce results, but rather assessed the type and meaning of a query and weights of the signals to be applied for that type and meaning.
Basically, more like a filter than a signal.
But again, that’s semantics.
Think of it however works best for you.
But definitely think about it. It may be 5 years old, but its meaning and impact have only grown.
Certainly, within Google, they will be calling elements and offshoots of it different things, but what RankBrain was there to do initially and does to this day is huge.
And, if I can predict the future, I would suggest that some future variant of it will replace PageRank.
Of course, entities can connect through links.
So that’s more a continuation of PageRank, than replacement.
But again, there’s no need to worry about semantics.
More Resources:
- Google’s Gary Illyes Explains How RankBrain Works
- Google Algorithm Updates & Changes: A Complete History
- 3 Places for SEO Beginners to Focus Their Time
Image Credits
Featured Image: Modified by author, August 2020
All screenshots taken by author, August 2020
