
 Zanran is an interesting search start-up that both indexes and maps the numerical content-finding ‘semi-structured’ (as they put it) data on the web. Such data could be a graph in a PDF report, a table in an Excel spreadsheet, or a bar chart shown as an image on an HTML page.
Zanran is an interesting search start-up that both indexes and maps the numerical content-finding ‘semi-structured’ (as they put it) data on the web. Such data could be a graph in a PDF report, a table in an Excel spreadsheet, or a bar chart shown as an image on an HTML page.
Currently, the search engine extracts tables and images from HTML, PDF and Excel files. In the near future it will also process PowerPoint and Word documents. The system examines millions of images and determines whether each one is a graph, chart or table – and if has numerical content.
Search Options:
By playing with various search options you can find more related numerical data:
- Target search to any country
- Set the document age
- Set the file type (PDF, Excel, images embed within HTML files, tables within HTML files):
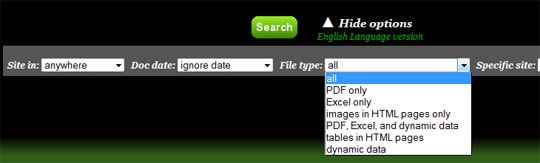
Additional search tips:
- Use quotes for an exact-match search (such as “mobile phones”).
- Play around with synonyms. The tool claims to know only a “few”, so you may want to add your suggestions.
Examples of searches:
- london employment rate
- poverty in new york (only US documents included)
- firefox usage (only images included)
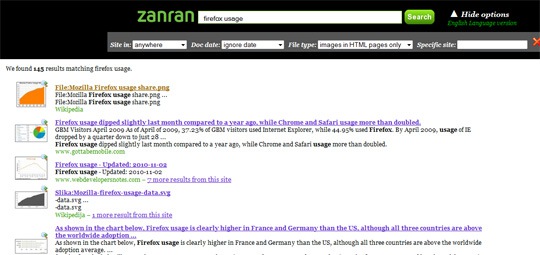
While the tool seems really useful, it currently lacks some search operators as well as some detailed help sections explaining what works and how. But I am sure the team behind Zanran is working hard to improve it. I wish them the best of luck!
