

This is a sponsored post written by DeepCrawl. The opinions expressed in this article are the sponsor’s own.
We need to talk about log files.
With the assistance of a log file analyzer, it’s possible to optimize your site’s crawl budget, find orphaned pages, identify performance and crawling issues, measure indexing speed for new pages, and more.
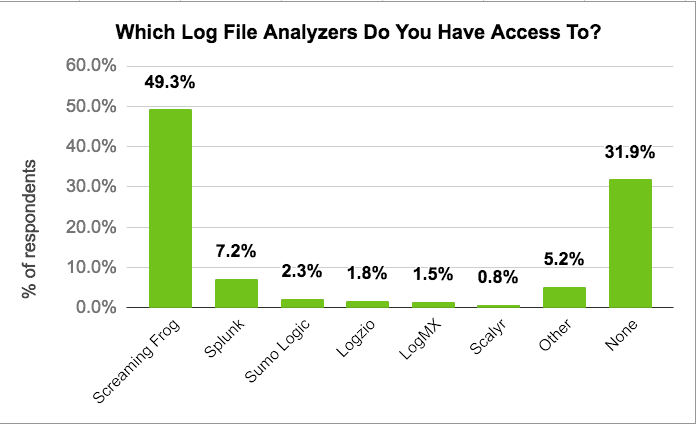
In a recent survey of 666 DeepCrawl users, we found 68 percent had access to a log file analyzer tool, so it’s surprising how little they are spoken about.
While there are some excellent guides on the subject, writing on log files is pretty thin on the ground. Even Google’s John Mueller says that log file data is underutilized.
@glenngabe Log files are so underrated, so much good information in them.
— John ☆.o(≧▽≦)o.☆ (@JohnMu) April 5, 2016
How Log Files Can Help Your SEO Efforts
1. Discover How Frequently Search Engines Are Crawling Your Pages
Log file data can provide you with an understanding of how often your site’s pages are being crawled.
It is especially important to understand crawl frequency if you have pages that change on a regular basis, either with updated content or links to new content. If a frequently updated page is showing a low number of bot requests, this will need to be investigated and resolved, by adding more internal links to the page or adding a last-modified date in a sitemap, for example.
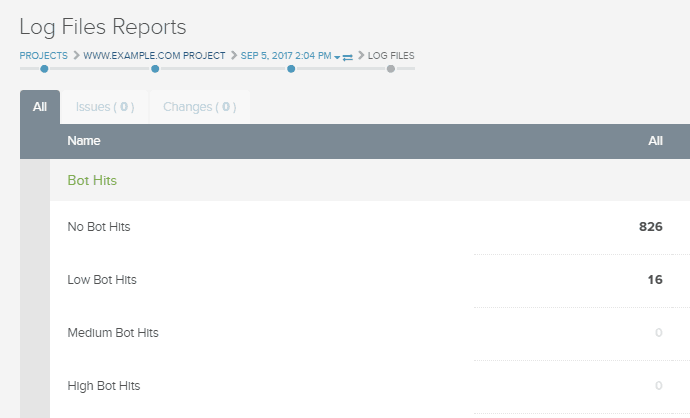
At DeepCrawl, we’ve added the ability to integrate data from any log file analyzer tool, as well as a range of new reports that include the ability to see the frequency of search engine bot requests to each of your website’s pages.
2. Reduce Crawl Budget Waste & Ensure Search Engines Focus on Important Pages
Search engine bots assign a finite crawl budget for each website, which limits the frequency pages are re-crawled and the speed at which new pages are found. Log file analysis can provide insights to use this crawl budget more effectively.
A key use for log file data is to check if your main pages are being crawled by search engine bots and how frequently. There are a number of reasons why your important pages might not be being crawled regularly, ranging from poor site architecture to misplaced meta robots tags.
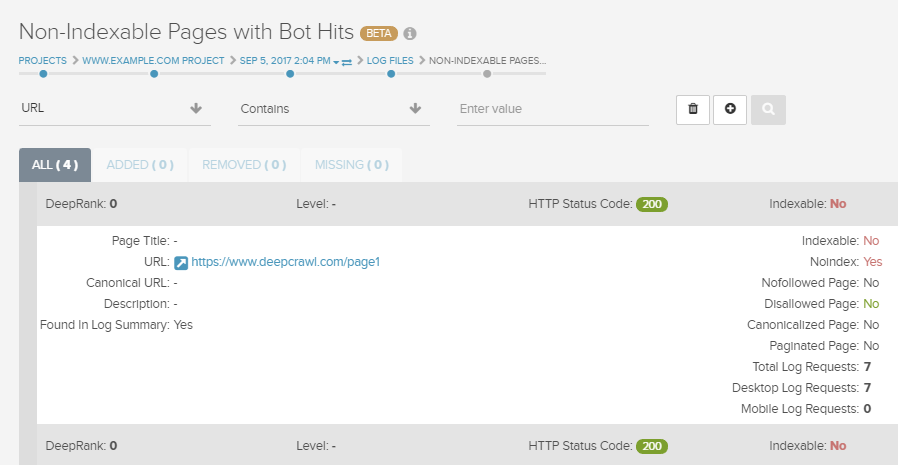
On the flip side, you want to ensure that your non-indexable pages aren’t receiving bot requests and wasting crawl budget, and check that search engine bots aren’t wasting time crawling pages returning 3xx status codes and redirect chains (hint: DeepCrawl’s Non-Indexable Pages With Bot Hits Report can help with this).
Removed pages will return a 404/410 status code, and these need to be crawled a few times in order for Google to understand these pages no longer exist. Google will continue to crawl these URLs at a low frequency, as it’s possible the pages could become active again. However, you might see a large number of URLs crawled with a 404/410 which were never valid pages on the site, which could be caused by broken internal linking.
Some pages crawled by Google which returns a 200 response could be soft 404 pages which are lacking any unique content, or orphaned pages that still exist but have been removed from a site’s internal linking. By crawling these URLs with a crawler such as DeepCrawl, you can identify them and decide if they should return a 404/410 or be redirected to another URL instead.
3. Find Out How Often Bots Crawl Your Sitemaps to Discover New Pages
It’s important to see how often bots crawl your sitemaps to get an idea of how regularly Google is checking for fresh content.
If your sitemaps aren’t crawled frequently, you should use a crawler to make sure they don’t contain non-indexable pages, or you can try breaking them into small sitemaps and have a separate sitemap that only includes new pages.
4. Identify Site Performance Issues & Inconsistent Response Codes
Log files can also be examined to identify site performance issues. Log file analyzer tools sometimes display the load time of individual pages, so if some pages have a relatively high load time, you will need to determine why and find an appropriate solution.
You can also find pages with varying response codes. If you see pages intermittently returning 200 and 503 status codes, this points to a server performance issue that should be addressed.
5. Understand How Bots Crawl Your Site With Mobile and Desktop User Agents
DeepCrawl’s log file integration, splits out hits from a desktop bot and the mobile bot, so you can understand how a search engine is using crawl budget to understand your site’s mobile setup.
With responsive sites, you would expect a search engine to use both user-agents on the same URL to validate that the same content is returned. With dynamic sites, the search engine needs to crawl with both user agents to validate the mobile version. With separate mobile sites, the search engine needs to crawl the dedicated mobile URLs with a mobile user agent to validate the pages and confirm the content matches the desktop pages.
Integrate Log Files Into Your Daily Routine
If in doubt. > To the server log files
— Dawn Anderson (@dawnieando) February 6, 2017
The above is not an exhaustive list of log file use cases, but will hopefully serve as a starting point to incorporate log files into your daily routine.
The most powerful way to harness log file data is by combining it with a crawl and including other data sources such as Google Search Console, web analytics, and backlinks.
If you’re new to DeepCrawl, you can sign up for a free trial and set up a crawl straight away and upload log files in the second stage of the crawl setup. If you’re a DeepCrawl veteran, simply log in and add log file summary data as a crawl source.
So what are you waiting for? Start making the most out of your log files now!
About the Author
 Sam Marsden is Technical SEO Executive at DeepCrawl and writer on all things SEO.
Sam Marsden is Technical SEO Executive at DeepCrawl and writer on all things SEO.Image Credits
Featured Image: Image by DeepCrawl. Used with permission.
In-post Images: Images by DeepCrawl. Used with permission.
