

Crawl budget is a concept that is often misunderstood and commonly discussed in SEO and digital marketing communities.
Most people tend to think that it’s some sort of magical thing you can use to “hack” your way up to Google’s top results.
Despite all the content written about how search engines work in general – and the crawling process in particular – it seems like marketers and webmasters are still confused about the idea of crawl budget.
The Problem
There’s an evident lack of understanding about the fundamentals of search engines and how the search process works.
This phenomenon creates confusion and normally leads to what business people call the “shiny object syndrome” that basically implies that without an understanding of the fundamentals marketers are less capable of discernment, therefore they blindly follow anyone’s advice
The Solution
This article will teach you the fundamentals of crawling and how to use them to identify whether “crawl budget” is something you should care about, and if it’s actually something important for your business/site.
You’ll learn the following:
- How search engines work (a brief introduction).
- How does crawling work?
- What is crawl budget and how does it work?
- How to track and optimize it.
- The future of crawling.
Let’s get started.
Definitions
Before we dig deeper into the concept of crawl budget and its implications, it is important to understand how the crawling process works and what does it mean for search engines.
How Search Engines Work
According to Google, there are three basic steps the search engine follows to generate results from webpages:
- Crawling: Web Crawlers access publicly available webpages
- Indexing: Google analyzes the content of each page and stores information it finds.
- Serving (and Ranking): When a user types a query, Google presents the most relevant answers from its index.
Without crawling your content won’t be indexed therefore it won’t appear in Google.
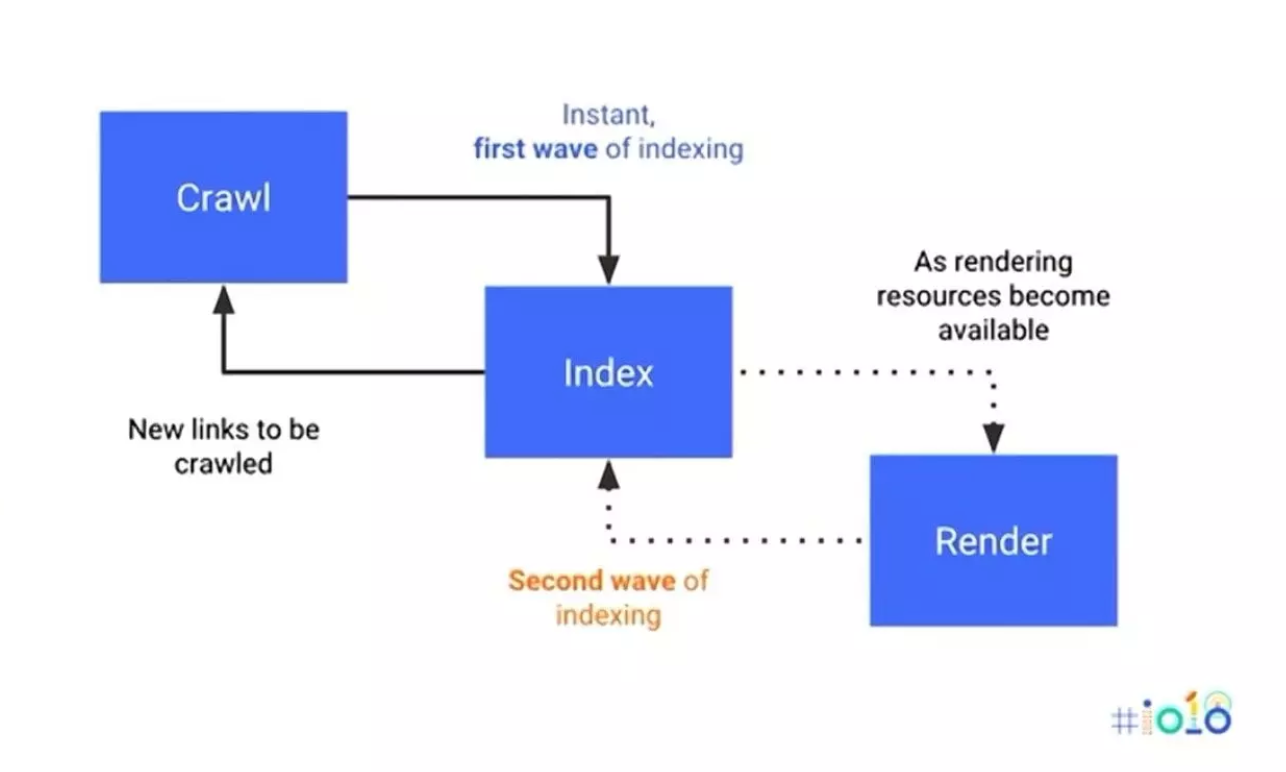
The Specifics of the Crawling Process
Google states on its documentation about crawling and indexing that:
“The crawling process begins with a list of web addresses, crawlers use links on those sites to discover other pages. The software pays special attention to new sites, changes to existing sites and dead links. A Computer program determines which sites to crawl, how often and how many pages to fetch from each site.”
What does it mean for SEO?
- Crawlers use links on sites to discover other pages. (Your site’s internal linking structure is crucial.)
- Crawlers prioritize new sites, changes to existing sites, and dead links.
- An automated process decides which sites to crawl, how often, and how many pages Google will fetch.
- The crawling process is impacted by your hosting capabilities (server resources and bandwidth).
As you can see, crawling the web is a complicated and expensive process for search engines, considering the size of the web.
Without an effective crawling process, Google won’t be able to “organize the world’s information and make it universally accessible and useful.”
But, how does Google guarantee effective crawling?
By prioritizing pages and resources.
It will be almost impossible and expensive for Google to crawl every single webpage.
Now that we understand how the crawl process works, let’s dig deeper into the idea of crawl budget.
What Is Crawl Budget?
Crawl budget is the number of pages a crawler sets to crawl on a certain period of time.
Once your budget has been exhausted, the web crawler will stop accessing your site’s content and move on to other sites.
Crawl budgets are different for every website and your site’s crawl budget is established automatically by Google.
The search engine uses a wide range of factors to determine how much budget is allocated to your site.
In general, the are four main factors Google uses to allocate crawl budget:
- Site Size: Bigger sites will require more crawl budget.
- Server Setup: Your site’s performance and load times might have an effect on how much budget is allocated to it.
- Updates Frequency: How often are you updating your content? Google will prioritize content that gets updated on a regular basis.
- Links: Internal linking structure and dead links.
While it is true that crawl-related issues can prevent Google from accessing your site’s most critical content, it is important to understand that crawl frequency is not a quality indicator.
Getting your site crawled more often is not going to help you rank better per se.
If your content is not up to your audience’s standards, it won’t attract new users.
This is not going to change by getting Googlebot to crawl your site more often.
(And while crawling is necessary for being in the results, it’s not a ranking signal.)
How Does Crawl Budget Work?
Most of the information we have about how crawl budget works come from an article by Gary Illyes on Google’s Webmaster Central Blog.
In this post, Illyes emphasized that:
- Crawl budget should not be something most publishers have to worry about.
- If a site has less than a few thousand URLs, most of the time it will be crawled efficiently.
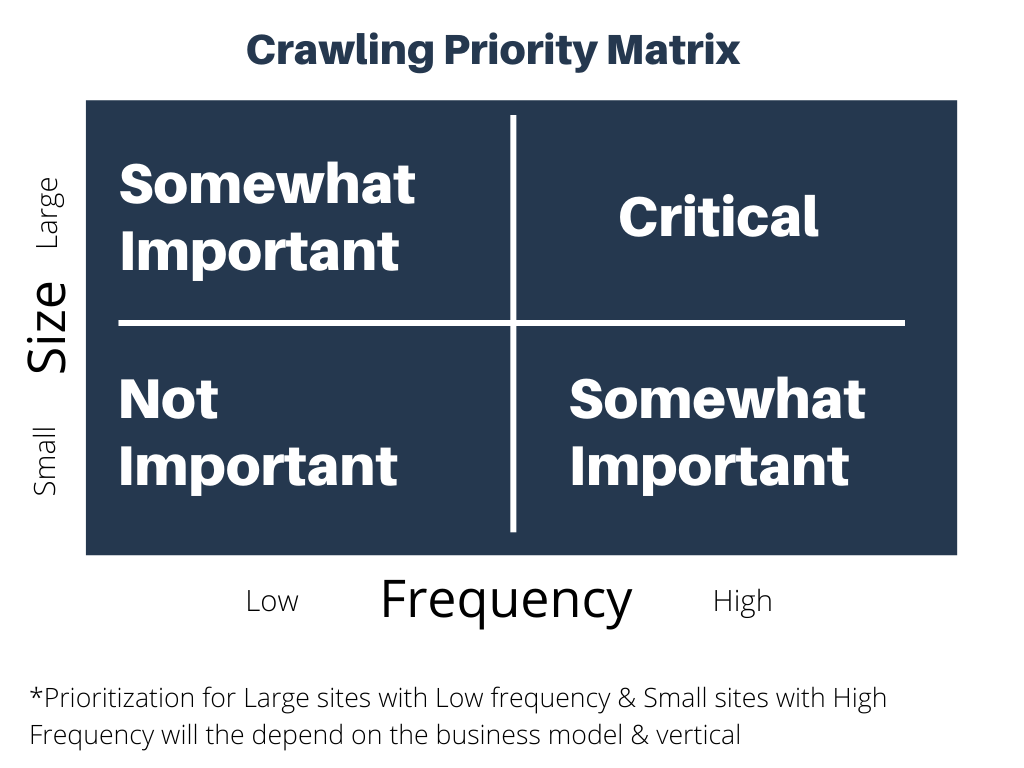
Here are the key concepts you need to know to better understand crawl budget.
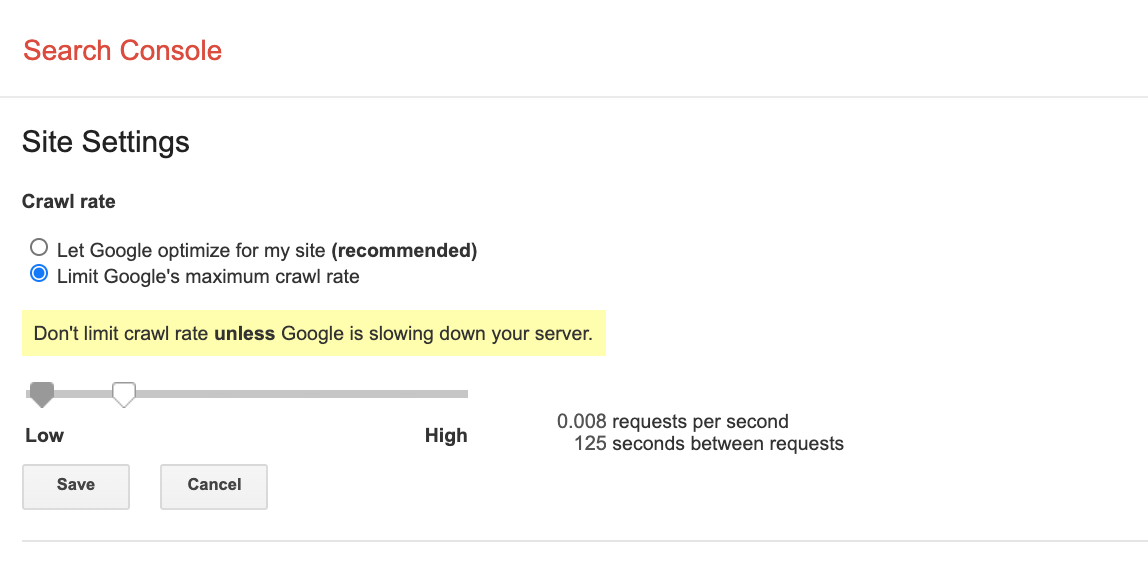
Crawl Rate Limit
Google knows that its bot can place severe constraints on websites if it’s not careful, so they have control mechanisms in place to guarantee their crawlers only visit a website as frequently as is sustainable for that site.
Crawl rate limit helps Google determine the crawl budget for a website.
Here’s how it works
- Googlebot will crawl a website.
- The bot will push the site’s server and see how it responds.
- Googlebot will then lower or raise the limit.
Website owners can also change the limit in Google search console by Opening the Crawl Rate Settings page for your property.
Crawl Demand
Googlebot also takes into consideration the demand any particular URL is getting from the index itself to determine how active or passive it should be.
The two factors that play a significant role in determining crawl demand are:
- URL Popularity: Popular pages will get indexed more frequently than ones that aren’t.
- Staleness: Google’s system will prevent stale URLs and will benefit up to date content.
Google mainly uses these crawl rate limits and crawl demand to determine the number of URLs Googlebot can and wants to crawl (crawl budget).
Factors Affecting Crawl Budget
Having a significant amount of low-value URLs on your site can negatively affect your site’s crawlability.
Things like infinite scrolling, duplicate content, and spam will significantly reduce your site’s crawling potential.
Here’s a list of critical factors that will affect your site’s crawl budget.
Server & Hosting Setup
Google considers the stability of each website.
Googlebot will not continually crawl a site that crashes constantly.
Faceted Navigation & Session Identifiers
If your website has a lot of dynamic pages, it could cause problems with dynamic URLs as well as accessibility.
These issues will prevent Google from indexing more pages on your website.
Duplicate Content
Duplication can be a big issue as it doesn’t provide value to Google users.
Low Quality Content & Spam
The crawler will also lower your budget if it sees that a significant portion of the content on your website is low quality or spam.
Rendering
Network Requests made during rendering may count against your crawling budget.
Not sure what rendering is?
It is the process of populating pages with data from APIs and/or databases.
It helps Google better understand your site’s layout and/or structure.
How to Track Crawl Budget
It can be difficult to figure out and monitor what your current crawl budget is as the new Search Console hid most legacy reports.
Additionally, the idea of server logs sounds extremely technical for a lot of people
Here’s a quick overview of two common ways you can use to monitor your crawl budget.
Google Search Console
Step 1: Go to Search Console > Legacy Tools and Reports > Crawl Stats
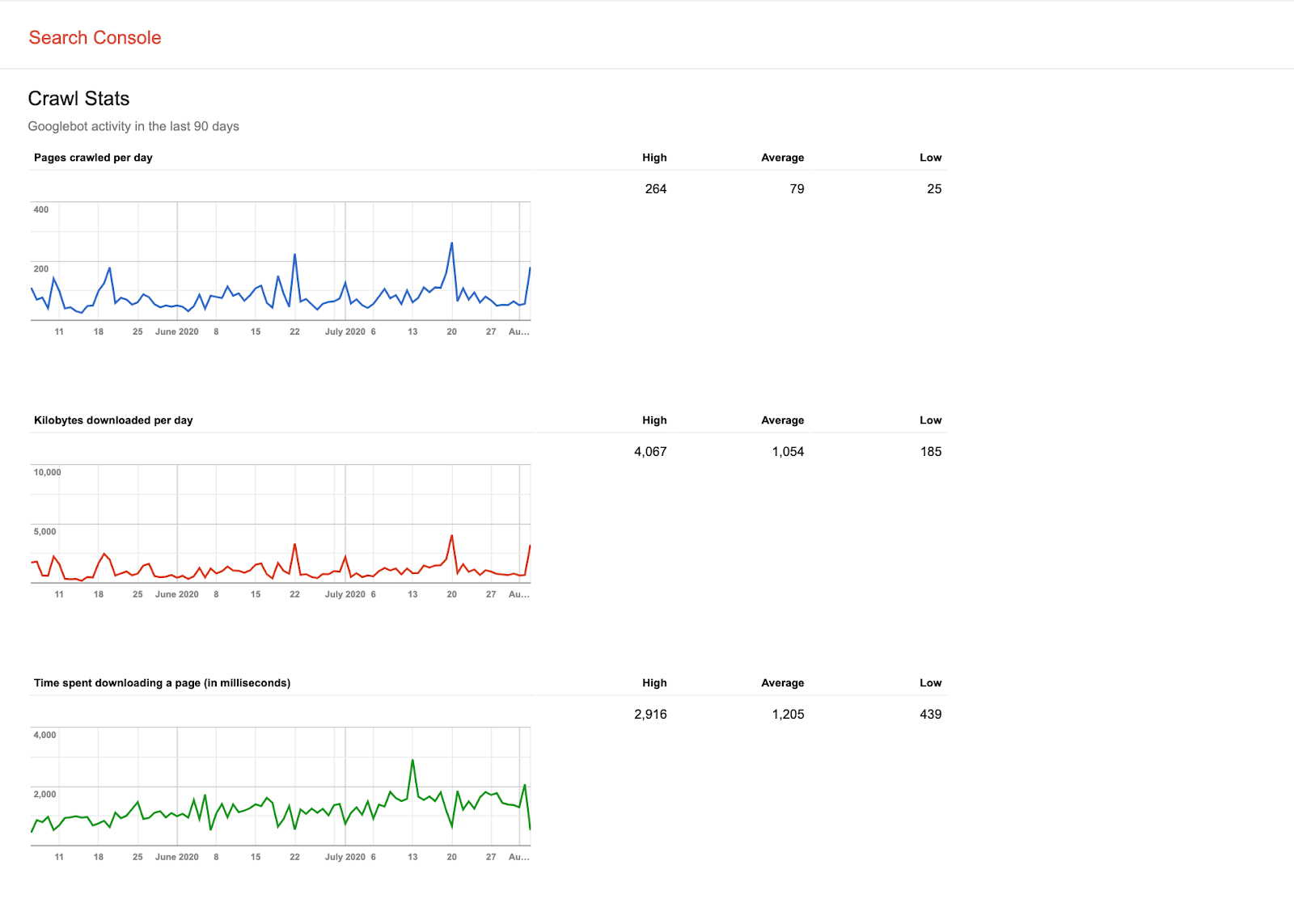
Step 2: Access the Crawl Stats report and get an idea of Googlebot’s activity over the last 90 days. (Can you see any patterns?)
Server Logs
Server logs store every request made to your webserver.
A log entry gets added to the access log file every time a user or Googlebot visits your site.
Googlebot leaves an entry in your access log file when it visits your website.
You can either manually or automatically analyze this log file to see how often Googlebot comes to your website.
There are commercial log analyzers that can do this, they help you get relevant information about what Google bot is doing on your website.
Server log analysis reports will show:
- How frequently your site is being crawled.
- Which pages is Googlebot accessing the most.
- What type of errors the bot has encountered.
Here’s a list of the most popular log analyzer tools.
SEMrush Log File Analyzer
 SEO Log File Analyser by Screamingfrog
SEO Log File Analyser by Screamingfrog
 OnCrawl Log Analyzer
OnCrawl Log Analyzer
 Botlogs by Ryte
Botlogs by Ryte
 SEOlyzer
SEOlyzer

How to Optimize Crawl Budget
By now, I hope you know that optimizing crawl budget is more important for bigger sites.
1. Prioritize What & When to Crawl
You should always prioritize pages that provide real value to your end-user.
Here’s how you can find those URLs by integrating data from Google Analytics and Search Console.
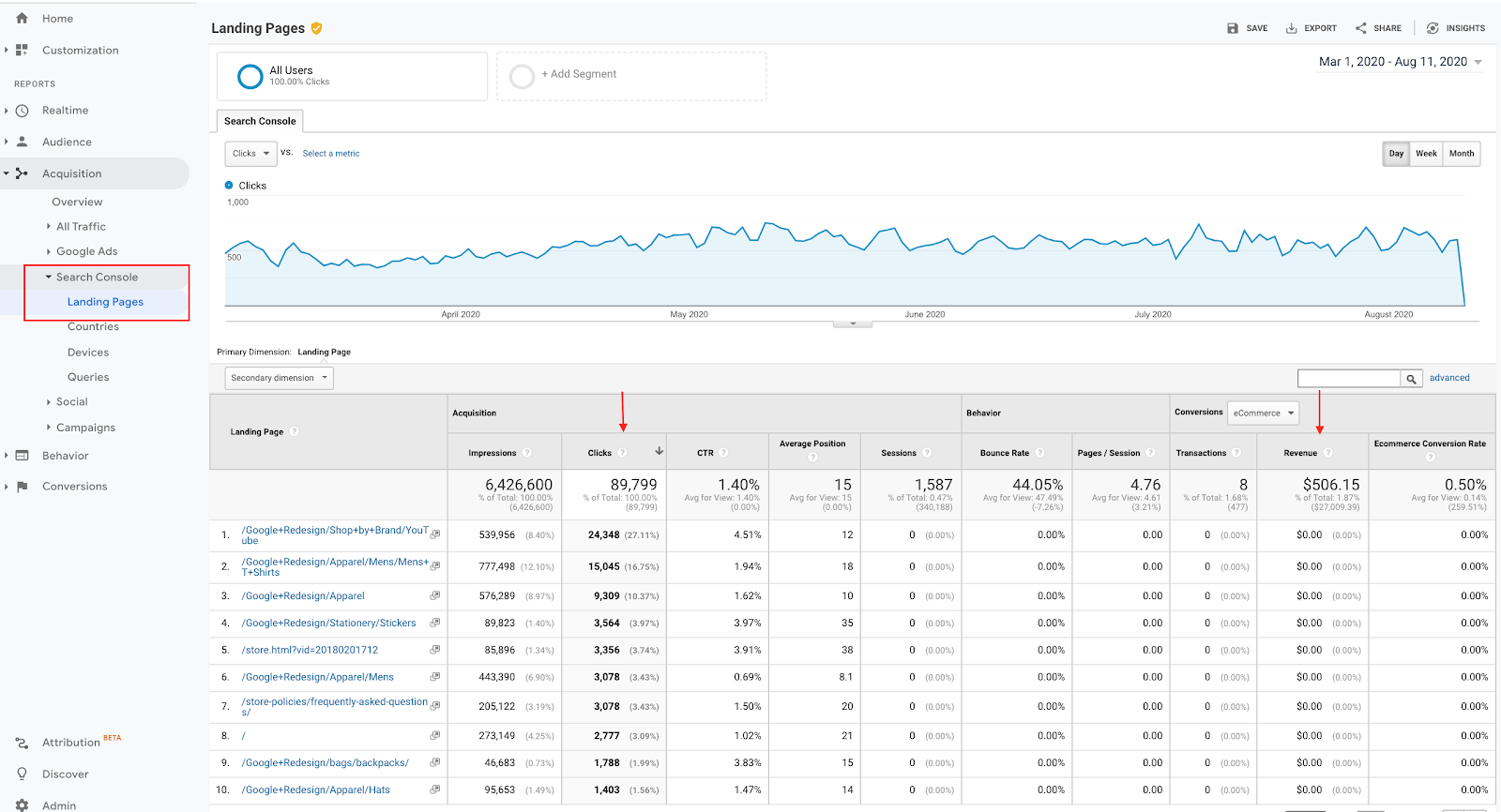
Pages generating clicks and revenue should be easily accessible for crawlers.
Sometimes it’s a good idea to create an individual XML sitemap including or your key pages (more on this later on)
2. Determine How Much Resources the Server Hosting the Site Can Allocate
Download your server log files and use one of the tools mentioned above to identify patterns and potential issues
Here’s an example of SEMrush Log File Analyzer
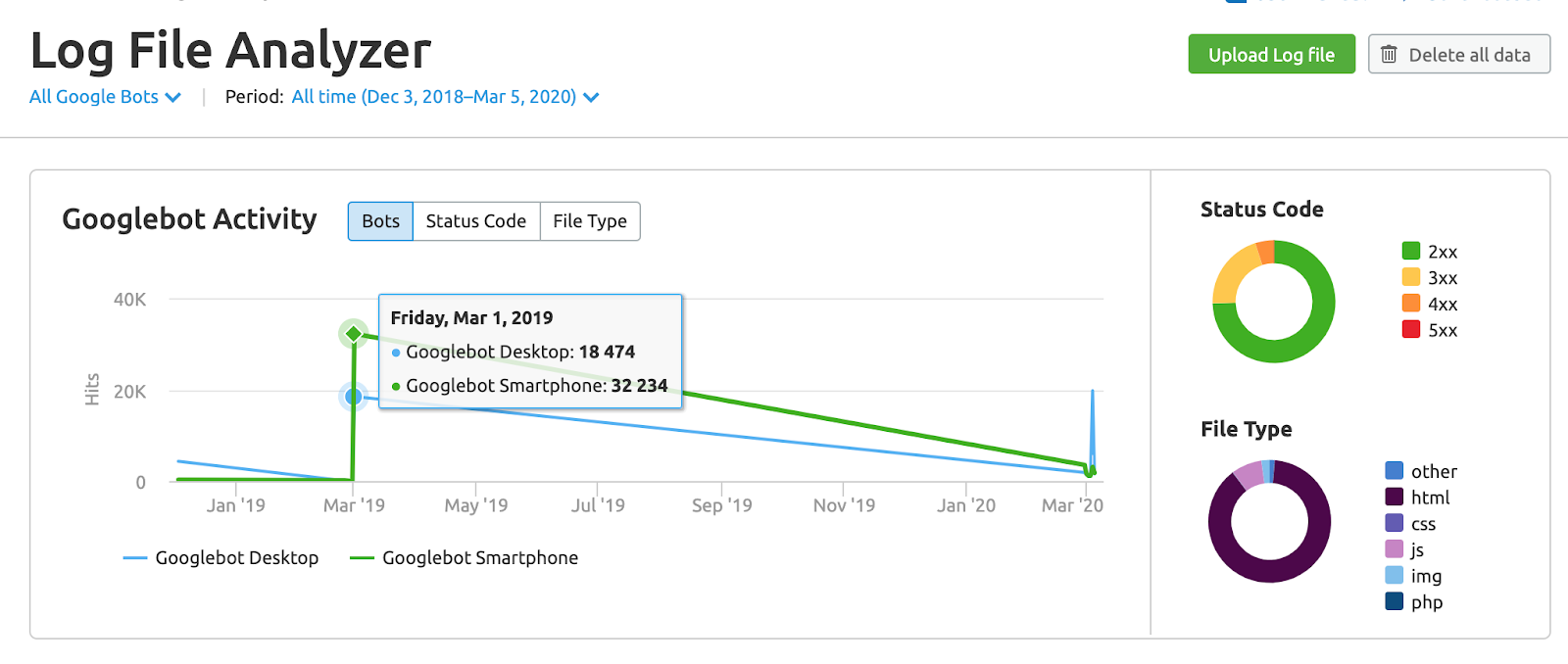
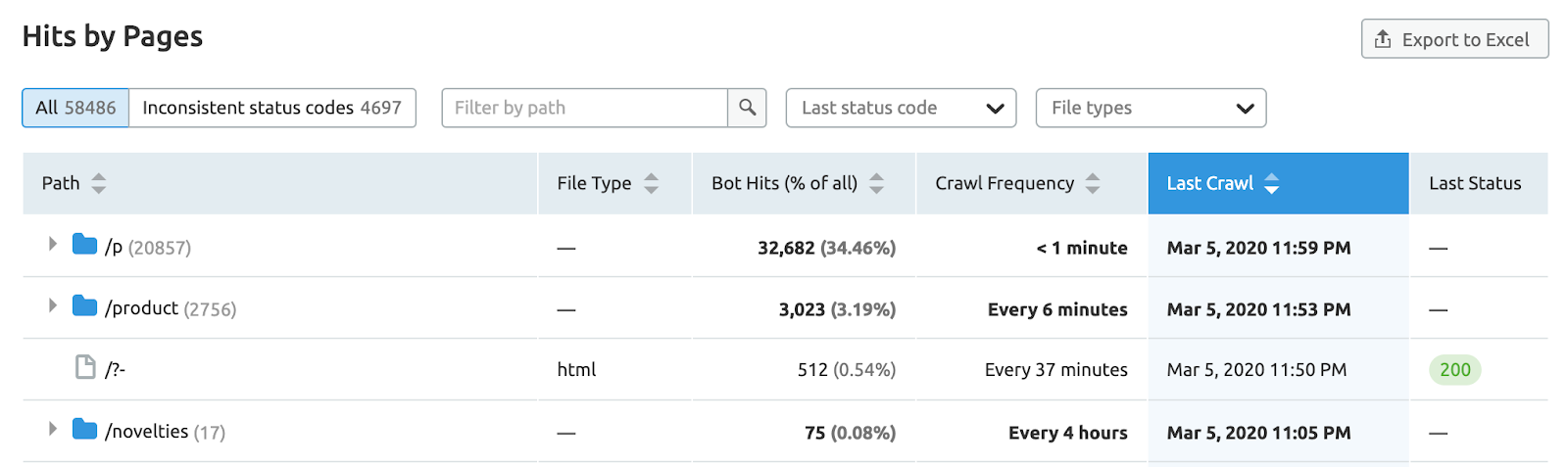
Your end goal here should be to get an idea of how your current server setup is impacted by Googlebot.
3. Optimize Your Pages
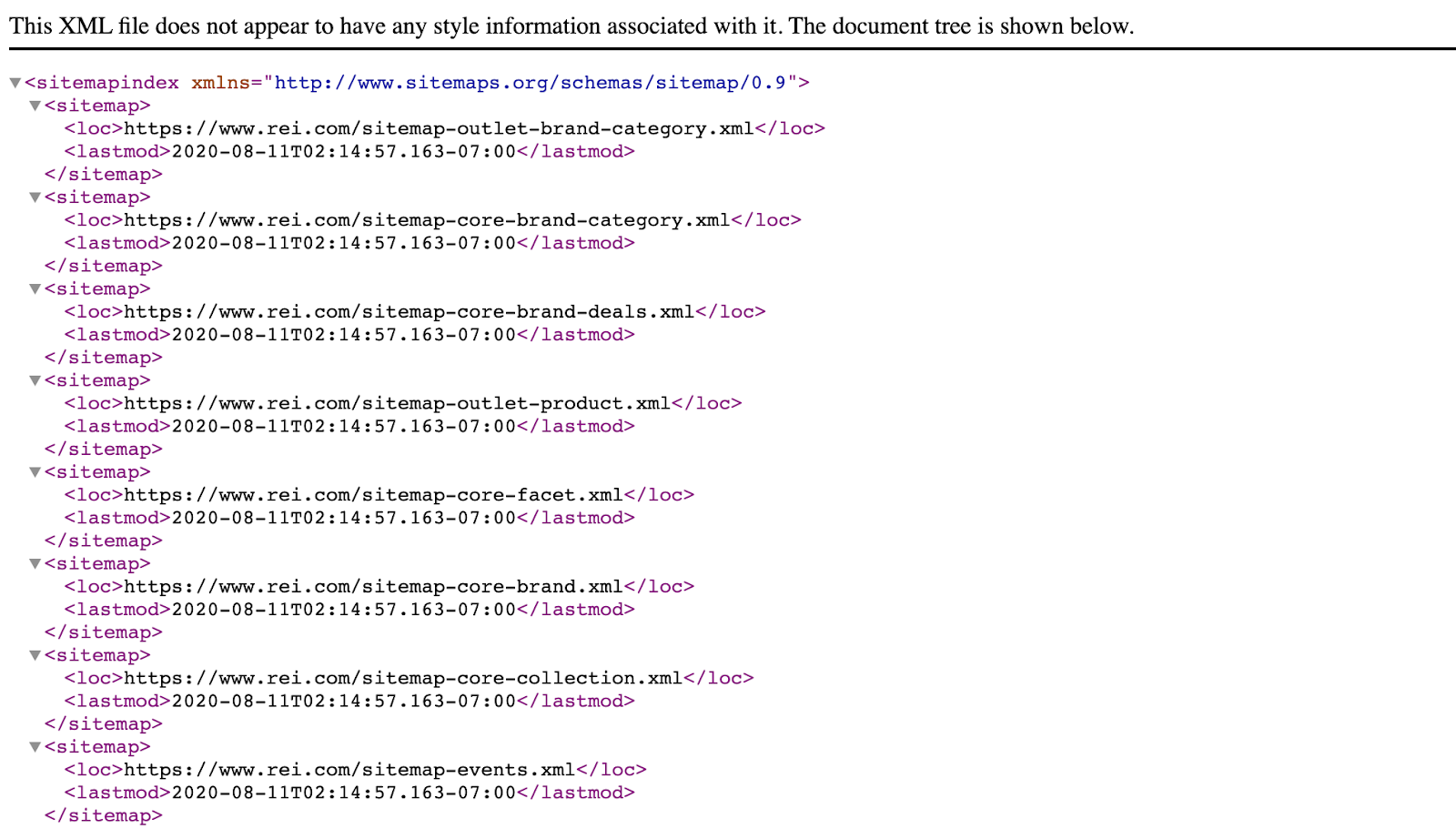
XML Sitemap Optimization
Create multiple sitemaps categorized by URL type or section within your site (i.e., products.xml, blog-post.xml, etc.).
This will help you control the crawling process to the most valuable sections on your site.
 Updates Frequency
Updates Frequency
Make sure you notify Google every time your content gets updated.
You can do this via structured data, XML sitemaps, or even an eTag.
Low Quality Content, Spam & Duplicate Content
Clean up your website by removing low quality, duplicate content, and/or spam.
Link Issues
Links from page to page still extremely important for the crawling process,
Every website should periodically fix things like wrong redirections, 404 errors, and redirect chains.
Robots.txt Optimization
You can optimize your robots.txt file by excluding non-valuable URLs or files (like internal analytics or chatbots) from the crawling process.
Don’t exclude useful or important sources from Googlebot (i.e., a CSS file necessary to render a particular page).
How the Crawling Process Has Changed
Google and the crawl process have evolved over time.
Here’s an overview of the most important changes we have experienced over the last few years.
Mobile-First Indexing
In March 2018, Google started to prioritize mobile content across the web and updating its index from desktop-first to mobile-first in an attempt to improve users’ experience on mobile devices.
With this shift, Google’s Desktop Bot got replaced with the smartphone Googlebot as the main crawler.
Google initially announced that it will be switching to mobile-first indexing for all sites starting September 2020.
The date has been delayed until March 2021 due to some issues.
When the switch over is done, most of the crawling for search will be done by Google’s mobile smartphone user-agent.
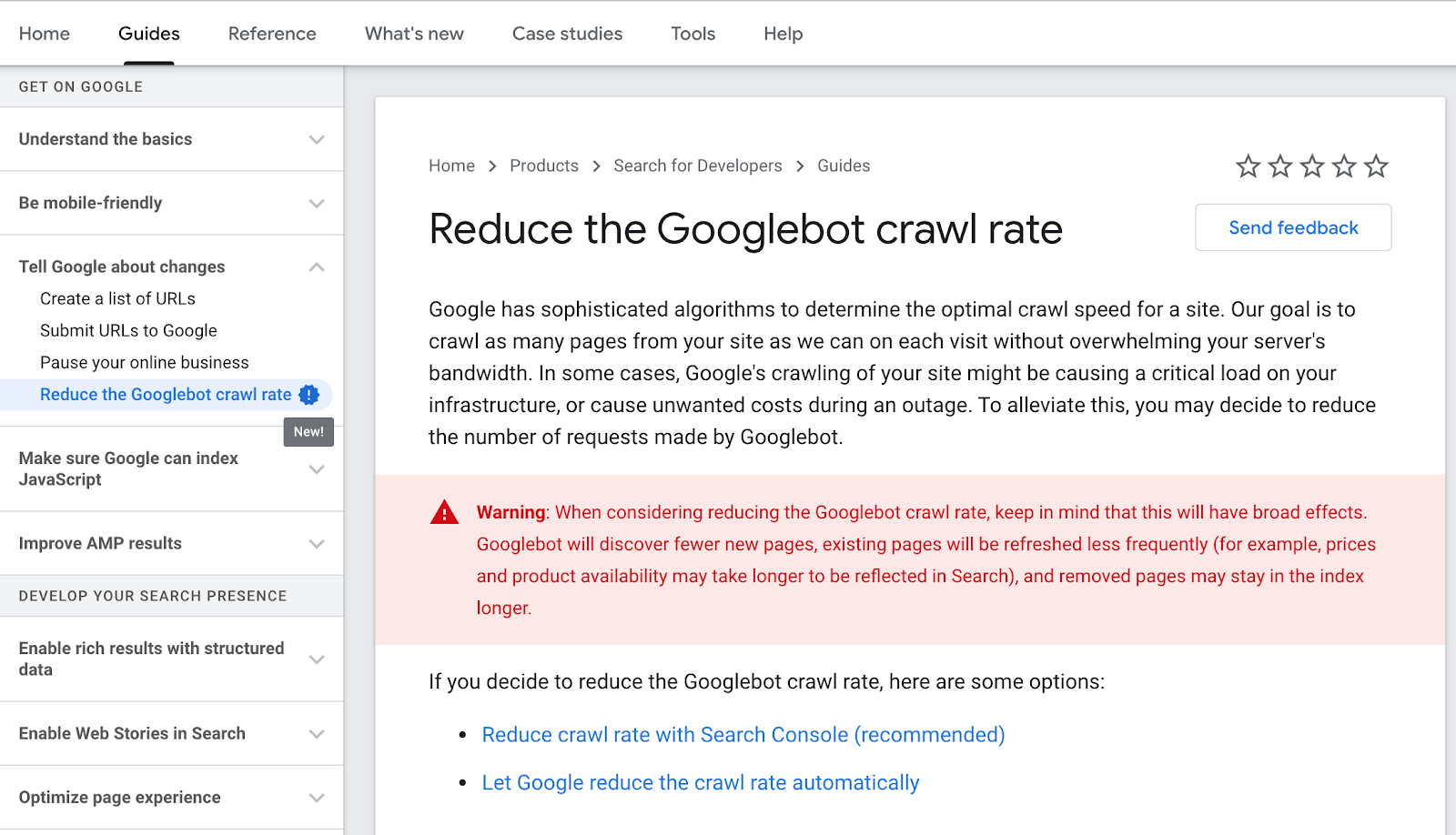
Reduce the Googlebot Crawl Rate
Google allows crawl rate reductions for websites that experience critical server issues or unwanted costs during the crawling process.
There’s a new guide on their Developers documentation.
The Future of Crawling
As pointed out by Kevin Indig, there are signs for a potential shift on the way Google accesses web content from crawling to indexing APIs.
From Mobile-First to AI-First
In 2017, Google CEO Sundar Pichai announced a transition from searching and organizing the world’s information to AI and machine learning.
This transition will be implemented across all products and platforms
Google Search is already using different types of machine learning (i.e., BERT) to support and improve its understanding of human language, ranking algorithms, and search result pages.
Heavy investments in machine learning and AI programs will allow Google to get a better prediction model for highly personalized search result pages.
(Please note that most applications developed by Google AI are purely machine learning applications and Narrow AI.)
With an accurate prediction model that is able to rank websites based on multiple data points (i.e., location, search history, entity likes, etc.), the current crawling process will become redundant as the search engine will be able to provide a good output with a limited input.
In other words, Google won’t need to crawl the whole web – only relevant websites for its users.
Google is already testing this out.
In a paper called Predictive Crawling for Commercial Web Content, you can see how they created a machine learning system that was able to optimize crawling sources by predicting pricing changes on ecommerce sites for Google shopping.
It Is Getting Harder to Crawl the Web
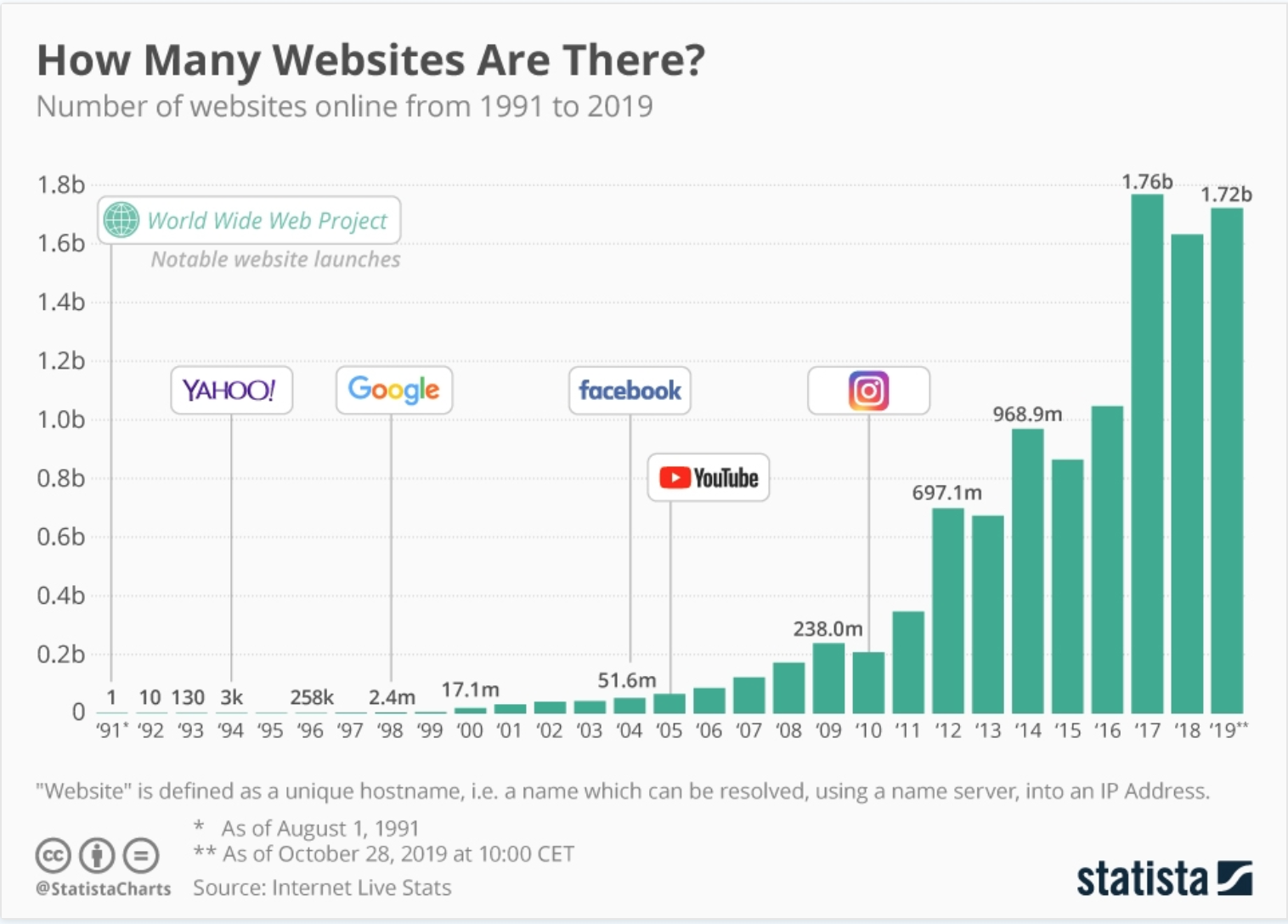
With almost 2 billion websites on the web, crawling and indexing content has become a challenging and expensive process for Google.
If the web continues to grow at this rate, it will be easier for Google to control only the indexing and ranking process of search.
Rejecting spammy or low-quality pages without wasting resources crawling millions of pages Google will significantly improve its operations.
In the future, Google might need to reduce the size of its index to prioritize quality and make sure its results are relevant and useful.
Both Google & Bing Have Indexing APIs
Both companies have developed tools you can use to notify them whenever your website gets updated.
Indexing APIs aim to provide instant crawling, indexing and discovery of your site content.
 As seen on Bing Webmaster Tools
As seen on Bing Webmaster Tools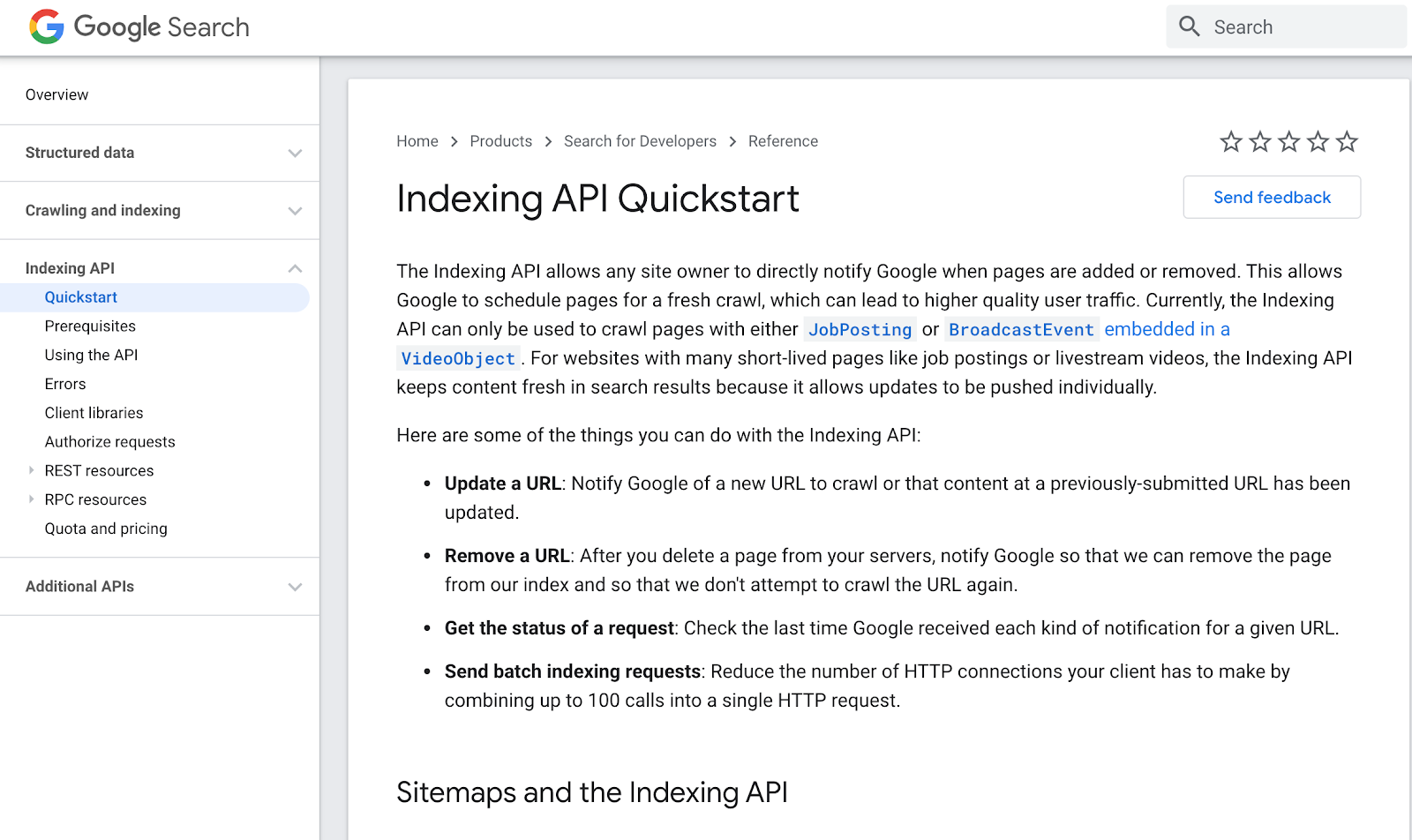 As seen on developers.google.com
As seen on developers.google.comClosing Thoughts
Crawl budget – as a concept and potential optimization metric – is relevant and useful for a specific type of website.
In the near future, the idea of a crawl budget might change or even disappear as Google is constantly evolving and testing new solutions for its users.
Stick to the fundamentals and prioritize activities that create value to your end-users
More Resources:
- 7 Tips to Optimize Crawl Budget for SEO
- 5 Ways to Get Better Log File Insights for Crawl Budget Optimization
- Advanced Technical SEO: A Complete Guide
Image Credits
Featured Image: Created by author, August 2020
All screenshots taken by author, August 2020
