

Google’s newest algorithmic update, BERT, helps Google understand natural language better, particularly in conversational search.
BERT will impact around 10% of queries. It will also impact organic rankings and featured snippets. So this is no small change!
But did you know that BERT is not just any algorithmic update, but also a research paper and machine learning natural language processing framework?
In fact, in the year preceding its implementation, BERT has caused a frenetic storm of activity in production search.
On November 20, I moderated a Search Engine Journal webinar presented by Dawn Anderson, Managing Director at Bertey.
Anderson explained what Google’s BERT really is and how it works, how it will impact search, and whether you can try to optimize your content for it.
Here’s a recap of the webinar presentation.

What Is BERT in Search?
BERT, which stands for Bidirectional Encoder Representations from Transformers, is actually many things.
It’s more popularly known as a Google search algorithm ingredient /tool/framework called Google BERT which aims to help Search better understand the nuance and context of words in Searches and better match those queries with helpful results.
BERT is also an open-source research project and academic paper. First published in October 2018 as BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, the paper was authored by Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova.
Additionally, BERT is a natural language processing NLP framework that Google produced and then open-sourced so that the whole natural language processing research field could actually get better at natural language understanding overall.
You’ll probably find that most mentions of BERT online are NOT about the Google BERT update.
There are lots of actual papers about BERT being carried out by other researchers that aren’t using what you would consider as the Google BERT algorithm update.
BERT has dramatically accelerated natural language understanding NLU more than anything and Google’s move to open source BERT has probably changed natural language processing forever.
The machine learning ML and NLP communities are very excited about BERT as it takes a huge amount of heavy lifting out of their being able to carry out research in natural language. It has been pre-trained on a lot of words – and on the whole of the English Wikipedia 2,500 million words.
Vanilla BERT provides a pre-trained starting point layer for neural networks in machine learning and natural language diverse tasks.
While BERT has been pre-trained on Wikipedia, it is fine-tuned on questions and answers datasets.
One of those question-and-answer data sets it can be fine-tuned on is called MS MARCO: A Human Generated MAchine Reading COmprehension Dataset built and open-sourced by Microsoft.
There are real Bing questions and answers (anonymized queries from real Bing users) that’s been built into a dataset with questions and answers for ML and NLP researchers to fine-tune and then they actually compete with each other to build the best model.
Researchers also compete over Natural Language Understanding with SQuAD (Stanford Question Answering Dataset). BERT now even beats the human reasoning benchmark on SQuAD.
Lots of the major AI companies are also building BERT versions:
- Microsoft extends on BERT with MT-DNN (Multi-Task Deep Neural Network).
- RoBERTa from Facebook.
- SuperGLUE Benchmark was created because the original GLUE Benchmark became too easy.
What Challenges Does BERT Help to Solve?
There are things that we humans understand easily that machines don’t really understand at all including search engines.
The Problem with Words
The problem with words is that they’re everywhere. More and more content is out there
Words are problematic because plenty of them are ambiguous, polysemous, and synonymous.
Bert is designed to help solve ambiguous sentences and phrases that are made up of lots and lots of words with multiple meanings.
Ambiguity & Polysemy
Almost every other word in the English language has multiple meanings. In spoken word, it is even worse because of homophones and prosody.
For instance, “four candles” and “fork handles” for those with an English accent. Another example: comedians’ jokes are mostly based on the play on words because words are very easy to misinterpret.
It’s not very challenging for us humans because we have common sense and context so we can understand all the other words that surround the context of the situation or the conversation – but search engines and machines don’t.
This does not bode well for conversational search into the future.
Word’s Context
“The meaning of a word is its use in a language.” – Ludwig Wittgenstein, Philosopher, 1953
Basically, this means that a word has no meaning unless it’s used in a particular context.
The meaning of a word changes literally as a sentence develops due to the multiple parts of speech a word could be in a given context.
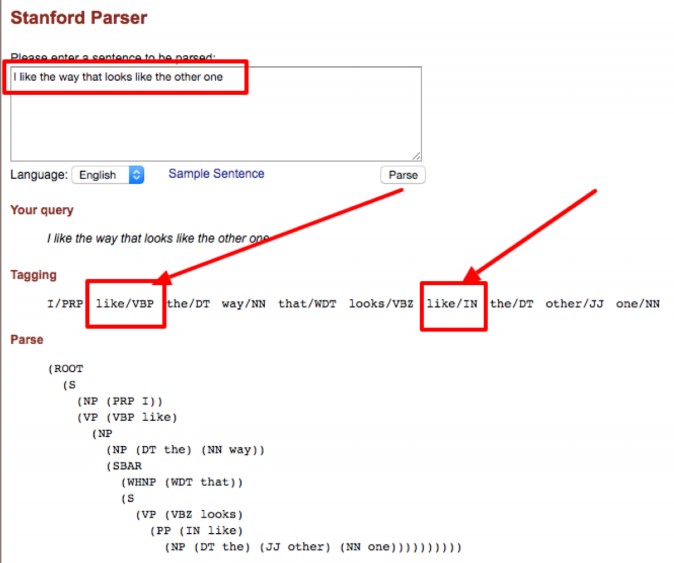
Case in point, we can see in just the short sentence “I like the way that looks like the other one.” alone using the Stanford Part-of-Speech Tagger that the word “like” is considered to be two separate parts of speech (POS).
The word “like” may be used as different parts of speech including verb, noun, and adjective.
So literally, the word “like” has no meaning because it can mean whatever surrounds it. The context of “like” changes according to the meanings of the words that surround it.
The longer the sentence is, the harder it is to keep track of all the different parts of speech within the sentence.
On NLR & NLU
Natural Language Recognition Is NOT Understanding
Natural language understanding requires an understanding of context and common sense reasoning. This is VERY challenging for machines but largely straightforward for humans.
Natural Language Understanding Is Not Structured Data
Structured data helps to disambiguate but what about the hot mess in between?
Not Everyone or Thing Is Mapped to the Knowledge Graph
There will still be lots of gaps to fill. Here’s an example.

As you can see here, we have all these entities and the relationships between them. This is where NLU comes in as it is tasked to help search engines fill in the gaps between named entities.
How Can Search Engines Fill in the Gaps Between Named Entities?
Natural Language Disambiguation
“You shall know a word by the company it keeps.” – John Rupert Firth, Linguist, 1957
Words that live together are strongly connected:
- Co-occurrence.
- Co-occurrence provides context.
- Co-occurrence changes a word’s meaning.
- Words that share similar neighbors are also strongly connected.
- Similarity and relatedness.
Language models are trained on very large text corpora or collections loads of words to learn distributional similarity…
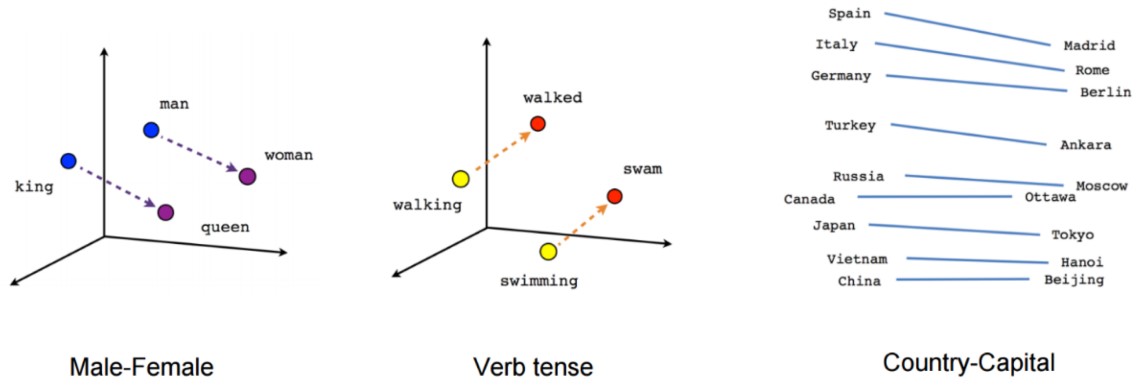 Vector representations of words (word vectors)
Vector representations of words (word vectors)…and build vector space models for word embeddings.
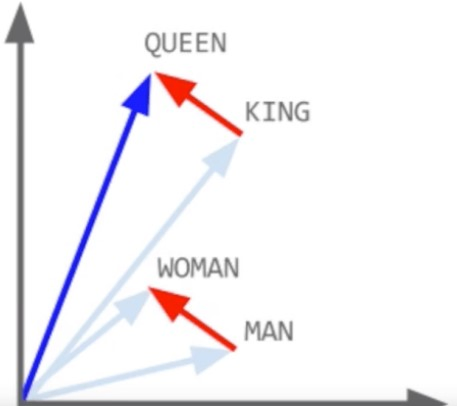
The NLP models learn the weights of the similarity and relatedness distances. But even if we understand the entity (thing) itself, we need to understand word’s context
On their own, single words have no semantic meaning so they need text cohesion. Cohesion is the grammatical and lexical linking within a text or sentence that holds a text together and gives it meaning.
Semantic context matters. Without surrounding words, the word “bucket” could mean anything in a sentence.
- He kicked the bucket.
- I have yet to cross that off my bucket list.
- The bucket was filled with water.
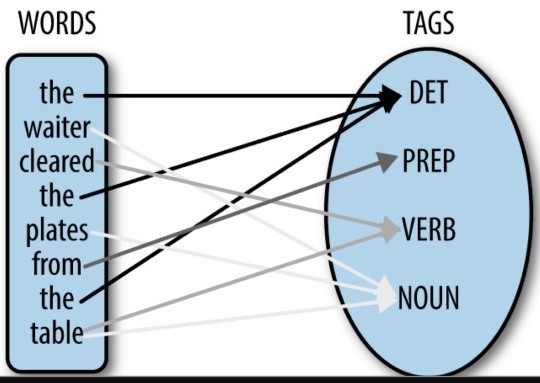
An important part of this is part-of-speech (POS) tagging:
How BERT Works
Past language models (such as Word2Vec and Glove2Vec) built context-free word embeddings. BERT, on the other hand, provides “context”.
To better understand how BERT works, let’s look at what the acronym stands for.
B: Bi-directional
Previously all language models (i.e., Skip-gram and Continuous Bag of Words) were uni-directional so they could only move the context window in one direction – a moving window of “n” words (either left or right of a target word) to understand word’s context.
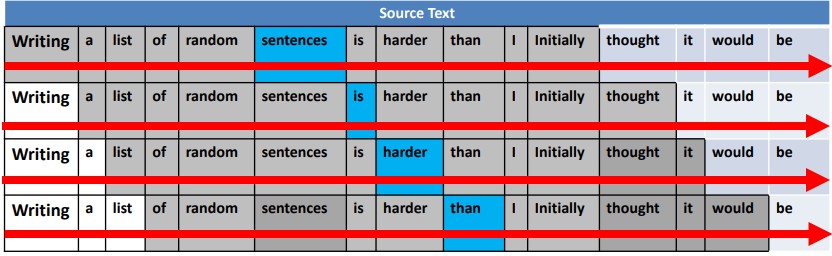 Uni-directional language modeler
Uni-directional language modelerMost language modelers are uni-directional. They can traverse over the word’s context window from only left to right or right to left. Only in one direction, but not both at the same time.
BERT is different. BERT uses bi-directional language modeling (which is a FIRST).
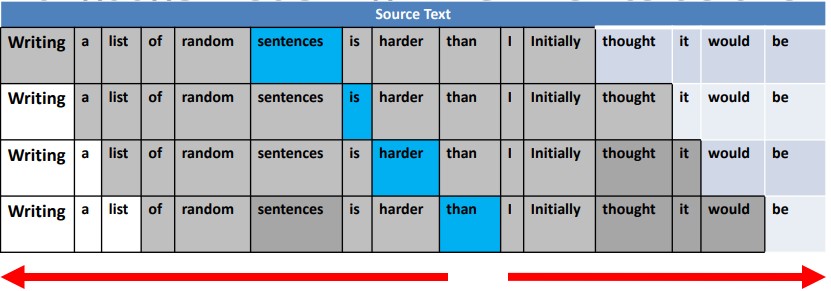 BERT can see both the left and the right-hand side of the target word.
BERT can see both the left and the right-hand side of the target word.BERT can see the WHOLE sentence on either side of a word contextual language modeling and all of the words almost at once.
ER: Encoder Representations
What gets encoded is decoded. It’s an in-and-out mechanism.
T: Transformers
BERT uses “transformers” and “masked language modeling”.
One of the big issues with natural language understanding in the past has been not being able to understand in what context a word is referring to.
Pronouns, for instance. It’s very easy to lose track of who’s somebody’s talking about in a conversation. Even humans can struggle to keep track of who somebody’s being referred to in a conversation all the time.
That’s kind of similar for search engines, but they struggle to keep track of when you say he, they, she, we, it, etc.
So transformers’ attention part of this actually focuses on the pronouns and all the words’ meanings that go together to try and tie back who’s being spoken to or what is being spoken about in any given context.
Masked language modeling stops the target word from seeing itself. The mask is needed because it prevents the word that’s under focus from actually seeing itself.
When the mask is in place, BERT just guesses at what the missing word is. It’s part of the fine-tuning process as well.
What Types of Natural Language Tasks Does BERT Help With?
BERT will help with things like:
- Named entity determination.
- Textual entailment next sentence prediction.
- Coreference resolution.
- Question answering.
- Word sense disambiguation.
- Automatic summarization.
- Polysemy resolution.
BERT advanced the state-of-the-art (SOTA) benchmarks across 11 NLP tasks.
How BERT Will Impact Search
BERT Will Help Google to Better Understand Human Language
BERT’s understanding of the nuances of human language is going to make a massive difference as to how Google interprets queries because people are searching obviously with longer, questioning queries.
BERT Will Help Scale Conversational Search
BERT will also have a huge impact on voice search (as an alternative to problem-plagued Pygmalion).
Expect Big Leaps for International SEO
BERT has this mono-linguistic to multi-linguistic ability because a lot of patterns in one language do translate into other languages.
There is a possibility to transfer a lot of the learnings to different languages even though it doesn’t necessarily understand the language itself fully.
Google Will Better Understand ‘Contextual Nuance’ & Ambiguous Queries
A lot of people have been complaining that their rankings have been impacted.
But I think that that’s probably more because Google in some way got better at understanding the nuanced context of queries and the nuanced context of content.
So perhaps, Google will be better able to understand contextual nuance and ambiguous queries.
Should You (or Can You) Optimize Your Content for BERT?
Probably not.
Google BERT is a framework of better understanding. It doesn’t judge content per se. It just better understands what’s out there.
For instance, Google Bert might suddenly understand more and maybe there are pages out there that are over-optimized that suddenly might be impacted by something else like Panda because Google’s BERT suddenly realized that a particular page wasn’t that relevant for something.
That’s not saying that you’re optimizing for BERT, you’re probably better off just writing natural in the first place.
[Video Recap] BERT Explained: What You Need to Know About Google’s New Algorithm
Watch the video recap of the webinar presentation.
Or check out the SlideShare below.
Image Credits
All screenshots taken by author, November 2019
Join Us For Our Next Webinar!
The Data Reveals: What It Takes To Win In AI Search
Register now to learn how to stay away from modern SEO strategies that don’t work.
