

Google Multitask Unified Model (MUM) is a new technology for answering complex questions that don’t have direct answers. Google has published research papers that may offer clues of what the MUM AI is and how it works.
MUM is likely comprised of multiple innovations. For example, the Google research paper, HyperGrid Transformers: Towards A Single Model for Multiple Tasks describes a new state of the art in multi-task learning that could be a part of MUM.
While this article focuses on two papers that are particularly interesting, that doesn’t mean to imply that these are the only two technologies that may be underlying Google’s Multitask Unified Model (MUM).
Google Algorithms Described in Research Papers and Patents
Google generally does not confirm whether or not algorithms described in research papers or patents are in use.
Google has not confirmed what the Multitask Unified Model (MUM) technology is.
Multitask Unified Model Research Papers
Sometimes, as was the case with Neural Matching, there are no research papers or patents that explicitly use the name of the technology. It’s as if Google invented a descriptive brand name for a group of algorithms working together.
This is somewhat the case with Multitask Unified Model (MUM). There are no patents or research papers with the MUM brand name exactly. But…
There are research papers that discuss similar problems that MUM solves using Multitask and Unified Model solutions.
What is Google Mum?
Google MUM is a group of technologies working together to solve difficult search queries that cannot be answered with a short snippet or the traditional ten blue links.
MUM aims to solve these difficult queries by using multiple forms of content, including images and text content in multiple languages in order to provide a rich and nuanced answer.
Background on Problem that MUM Solves
Long Form Question Answering is a complex search query that cannot be answered with a link or snippet. The answer requires paragraphs of information containing multiple subtopics.
Google’s MUM announcement described the complexity of certain questions with an example of a searcher wanting to know how to prepare for hiking Mount Fuji in the fall.
This is Google’s example of a complex search query:
“Today, Google could help you with this, but it would take many thoughtfully considered searches — you’d have to search for the elevation of each mountain, the average temperature in the fall, difficulty of the hiking trails, the right gear to use, and more.”
Here’s an example of a Long Form Question:
“What are the differences between bodies of water like lakes, rivers, and oceans?”
The above question requires multiple paragraphs to discuss the qualities of lakes, rivers and seas, plus a comparison between each body of water to each other.
Here’s an example of the complexity of the answer:
- A lake is generally referred to as still water because it does not flow.
- A river is flowing.
- Both a lake and a river are generally freshwater.
- But a river and a lake can sometimes be brackish (salty).
- An ocean can be miles deep.
Answering a Long Form question requires a complex answer comprised of multiple steps, like the example Google shared about asking how to prepare to hike Mount Fuji in the fall.
Google’s MUM announcement did not mention Long Form Question Answering but the problem MUM solves appears to be exactly that.
(Citation: Google Research Paper Reveals a Shortcoming in Search).
Change in How Questions are Answered
In May 2021, a Google researcher named Donald Metzler published a paper that presented the case that how search engines answer questions needs to take a new direction in order to give answers to complex questions.
The paper stated that the current method of information retrieval consisting of indexing web pages and ranking them are inadequate for answering complex search queries.
The paper is entitled, Rethinking Search: Making Experts out of Dilettantes (PDF)
A dilettante is someone who has a superficial knowledge of something, like an amateur and not an expert.
The paper positions the state of search engines today like this:
“Today’s state-of-the-art systems often rely on a combination of term-based… and semantic …retrieval to generate an initial set of candidates.
This set of candidates is then typically passed into one or more stages of re-ranking models, which are quite likely to be neural network-based learning-to-rank models.
As mentioned previously, the index-retrieve-then-rank paradigm has withstood the test of time and it is no surprise that advanced machine learning and NLP-based approaches are an integral part of the indexing, retrieval, and ranking components of modern day systems.”
Model-based Information Retrieval
The new system that the Making Experts out of Dilettantes research paper describes is one that does away with the index-retrieve-rank part of the algorithm.
This section of the research paper makes reference to IR, which means Information Retrieval, which is what search engines do.
Here is how the paper describes this new direction for search engines:
“The approach, referred to as model-based information retrieval, is meant to replace the long-lived “retrieve-then-rank” paradigm by collapsing the indexing, retrieval, and ranking components of traditional IR systems into a single unified model.”
The paper next goes into detail about how the “unified model” works.
Let’s stop right here to remind that the name of Google’s new algorithm is Multitask Unified Model
I will skip the description of the unified model for now and just note this:
“The important distinction between the systems of today and the envisioned system is the fact that a unified model replaces the indexing, retrieval, and ranking components. In essence, it is referred to as model-based because there is nothing but a model.”
Screenshot Showing What a Unified Model Is
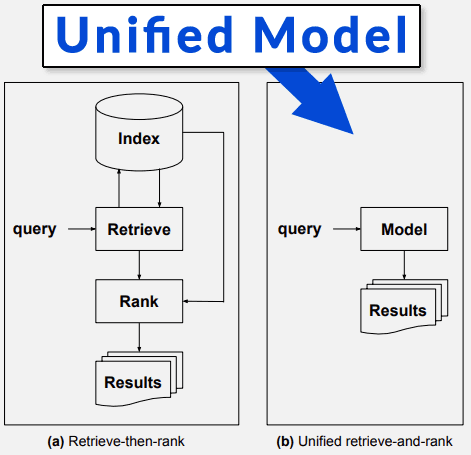
In another place the Dilettantes research paper states:
“To accomplish this, a so-called model-based information retrieval framework is proposed that breaks away from the traditional index retrieve-then-rank paradigm by encoding the knowledge contained in a corpus in a unified model that replaces the indexing, retrieval, and ranking components of traditional systems.”
Is it a coincidence that Google’s technology for answering complex questions is called Multitask Unified Model and the system discussed in this May 2021 paper makes the case for the need of a “unified model” for answering complex questions?
What is the MUM Research Paper?
The “Rethinking Search: Making Experts out of Dilettantes” research paper lists Donald Metzler as an author. It announces the need for an algorithm that accomplishes the task of answering complex questions and suggests a unified model for accomplishing that.
It gives an overview of the process but it is somewhat short on details and experiments.
There is another research paper published in December 2020 that describes an algorithm that does have experiments and details and one of the authors is… Donald Metzler.
The name of the December 2020 research paper is, Multitask Mixture of Sequential Experts for User Activity Streams
Let’s stop right here, back up and reiterate the name of Google’s new algorithm: Multitask Unified Model
The May 2021 Rethinking Search: Making Experts out of Dilettantes paper outlined the need for a Unified Model. The earlier research paper from December 2020 (by the same author) is called, Multitask Mixture of Sequential Experts for User Activity Streams (PDF).
Are these coincidences? Maybe not. The similarities between MUM and this other research paper are uncannily similar.
MoSE: Multitask Mixture of Sequential Experts for User Activity Streams
TL;DR
MoSE is a machine intelligence technology that learns from multiple data sources (search and browsing logs) in order to predict complex multi-step search patterns. It is highly efficient, which makes it scalable and powerful.
Those features of MoSE match certain qualities of the MUM algorithm, specifically that MUM can answer complex search queries and is 1,000 times more powerful than technologies like BERT.
What MoSE Does
TL;DR
MoSE learns from the sequential order of user click and browsing data. This information allows it to model the process of complex search queries to produce satisfactory answers.
The December 2020 MoSE research paper from Google describes modeling user behavior in sequential order, as opposed to modeling on the search query and the context.
Modeling the user behavior in sequential order is like studying how a user searched for this, then this, then that in order understand how to answer a complex query.
The paper describes it like this:
“In this work, we study the challenging problem of how to model sequential user behavior in the neural multi-task learning settings.
Our major contribution is a novel framework, Mixture of Sequential Experts (MoSE). It explicitly models sequential user behavior using Long Short-Term Memory (LSTM) in the state-of-art Multi-gate Mixture-of-Expert multi-task modeling framework.”
That last part about “Multi-gate Mixture-of-Expert multi-task modeling framework” is a mouthful.
It’s a reference to a type of algorithm that optimizes for multiple tasks/goals and that’s pretty much all that needs to be known about it for now. (Citation: Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts)
The MoSE research paper discusses other similar multi-task algorithms that are optimized for multiple goals such as simultaneously predicting what video a user might want to watch on YouTube, which videos will perpetuate more engagement and which videos will generate more user satisfaction. That’s three tasks/goals.
The paper comments:
“Multi-task learning is effective especially when tasks are closely correlated.”
MoSE was Trained on Search
The MoSE algorithm focuses on learning from what it calls heterogeneous data, which means different/diverse forms of data.
Of interest to us, in the context of MUM, is that the MoSE algorithm is discussed in the context of search and the interactions of searchers in their quest for answers, i.e. what steps a searcher took to find an answer.
“…in this work, we focus on modeling user activity streams from heterogeneous data sources (e.g., search logs and browsing logs) and the interactions among them.”
The researchers experimented and tested the MoSE algorithm on search tasks within G Suite and Gmail.
MoSE and Search Behavior Prediction
Another feature that makes MoSE an interesting candidate for being relevant to MUM is that it can predict a series of sequential searches and behaviors.
Complex search queries, as noted by the Google MUM announcement, can take up to eight searches.
But if an algorithm can predict these searches and incorporate those into answers, the algorithm can be better able to answer those complex questions.
The MUM announcement states:
“But with a new technology called Multitask Unified Model, or MUM, we’re getting closer to helping you with these types of complex needs. So in the future, you’ll need fewer searches to get things done.”
And here is what the MoSE research paper states:
“For example, user behavior streams, such as user search logs in search systems, are naturally a temporal sequence. Modeling user sequential behaviors as explicit sequential representations can empower the multi-task model to incorporate temporal dependencies, thus predicting future user behavior more accurately.”
MoSE is Highly Efficient with Resource Costs
The efficiency of MoSE is important.
The less computing resources an algorithm needs to complete a task the more powerful it can be at those tasks because this gives it more room to scale.
MUM is said to be 1,000 times more powerful than BERT.
The MoSE research paper mentions balancing search quality with “resource costs,” resource costs being a reference to computing resources.
The ideal is to have high quality results with minimal computing resource costs which will allow it to scale up for a bigger task like search.
The original Penguin algorithm could only be run on the map of the entire web (called a link graph) a couple times a year. Presumably that was because it was resource intensive and could not be run on a daily basis.
In 2016 Penguin became more powerful because it could now run in real time. This is an example of why it’s important to produce high quality results with minimal resource costs.
The less resource costs MoSE requires the more powerful and scalable it can be.
This is what the researchers said about the resource costs of MoSE:
“In experiments, we show the effectiveness of the MoSE architecture over seven alternative architectures on both synthetic and noisy real-world user data in G Suite.
We also demonstrate the effectiveness and flexibility of the MoSE architecture in a real-world decision making engine in GMail that involves millions of users, balancing between search quality and resource costs.”
Then toward the end of the paper it reports these remarkable results:
“We emphasize two benefits of MoSE. First, performance wise, MoSE significantly outperforms the heavily tuned shared bottom model. At the requirement of 80% resource savings, MoSE is able to preserve approximately 8% more document search clicks, which is very significant in the product.
Also, MoSE is robust across different resource saving level due to the its modeling power, even though we assigned equal weights to the tasks during training.”
And of the sheer power and flexibility to pivot to change, it boasts:
“This gives MoSE more flexibility when the business requirement keeps changing in practice since a more robust model like MoSE may alleviate the need to re-train the model, comparing with models that are more sensitive to the importance weights during training.”
Mum, MoSE and Transformer
MUM was announced to have been built using the Transformer technique.
Google’s announcement noted:
“MUM has the potential to transform how Google helps you with complex tasks. Like BERT, MUM is built on a Transformer architecture, but it’s 1,000 times more powerful.”
The results reported in the MoSE research paper from December 2020, six months ago, were remarkable.
But the version of MoSE tested in 2020 was not built using the Transformer architecture. The researchers noted that MoSE could easily be extended with transformers.
The researchers (in paper published in December 2020) mentioned transformers as a future direction for MoSE:
“Experimenting with more advanced techniques such as Transformer is considered as future work.
… MoSE, consisting of general building blocks, can be easily extended, such as using other sequential modeling units besides LSTM, including GRUs, attentions, and Transformers…”
According to the research paper then, MoSE could easily be supercharged by using other architectures, like Transformers. This means that MoSE could be a part of what Google announced as MUM.
Why Success of MoSE is Notable
Google publishes many algorithm patents and research papers. Many of them are pushing the edges of the state of the art while also noting flaws and errors that require further research.
That’s not the case with MoSE. It’s quite the opposite. The researchers note the accomplishments of MoSE and how there is still opportunity to make it even better.
What makes the MoSE research even more notable then is the level of success that it claims and the door it leaves open for doing even better.
It is noteworthy and important when a research paper claims success and not a mix of success and losses.
This is especially true when the researchers claim to achieve these successes without significant resource levels.
Is MoSE the Google MUM AI Technology?
MUM is described as an Artificial Intelligence technology. MoSE is categorized as Machine Intelligence on Google’s AI blog. What’s the difference between AI and Machine Intelligence? Not a whole lot, they’re pretty much in the same category (note that I wrote machine INTELLIGENCE, not machine learning). The Google AI Publications database classifies research papers on Artificial Intelligence under the Machine Intelligence category. There is no Artificial Intelligence category.
We cannot say with certainty that MoSE is part of the technology underlying Google’s MUM.
- It’s possible that MUM is actually a number of technologies working together and that MoSE is a part of that.
- It could be that MoSE is a major part of Google MUM.
- Or it could be that MoSE has nothing to do with MUM whatsoever.
Nevertheless, it’s intriguing that MoSE is a successful approach to predicting user search behavior and that it can easily be scaled using Transformers.
Whether or not this is a part of Google’s MUM technology, the algorithms described within these papers show what the state of the art in information retrieval is.
Citations
MoSE – Multitask Mixture of Sequential Experts for User Activity Streams (PDF)
Rethinking Search: Making Experts out of Dilettantes (PDF)
Official Google Announcement of MUM
MUM: A new AI Milestone for Understanding Information
