
Like the core algorithm, Google’s Knowledge Graph periodically updates.
But little has been known about how, when, and what it means — until now.
I believe these updates consist of three things:
- Algorithm tweaks.
- An injection of curated training data.
- A refresh of Knowledge Graph’s dataset.
My company, Kalicube, has been tracking Google’s Knowledge Graph both through the API and through knowledge panels for several years.
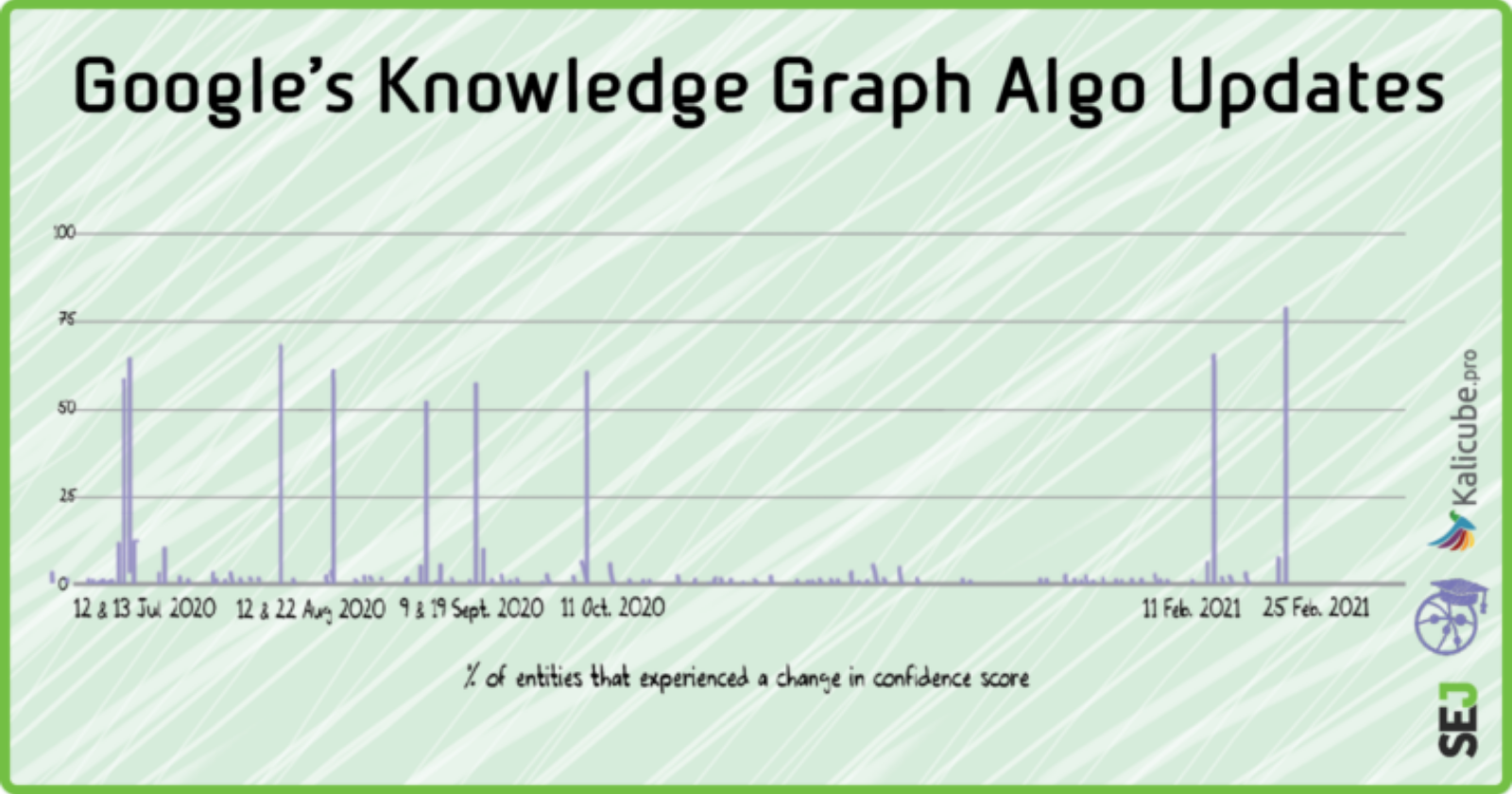
When I wrote about The Budapest Update’ in 2019, for example, I had seen a massive increase in confidence scores. Nothing that seismic on the scores has happened since.
However, the scores for individual entities fluctuate a great deal and typically over 75% will change during any given month.
The exceptions are December 2019, and over the last four months (I’ll come to that later).
From July 2019 to June 2020, we were tracking monthly (hence the monthly figures).
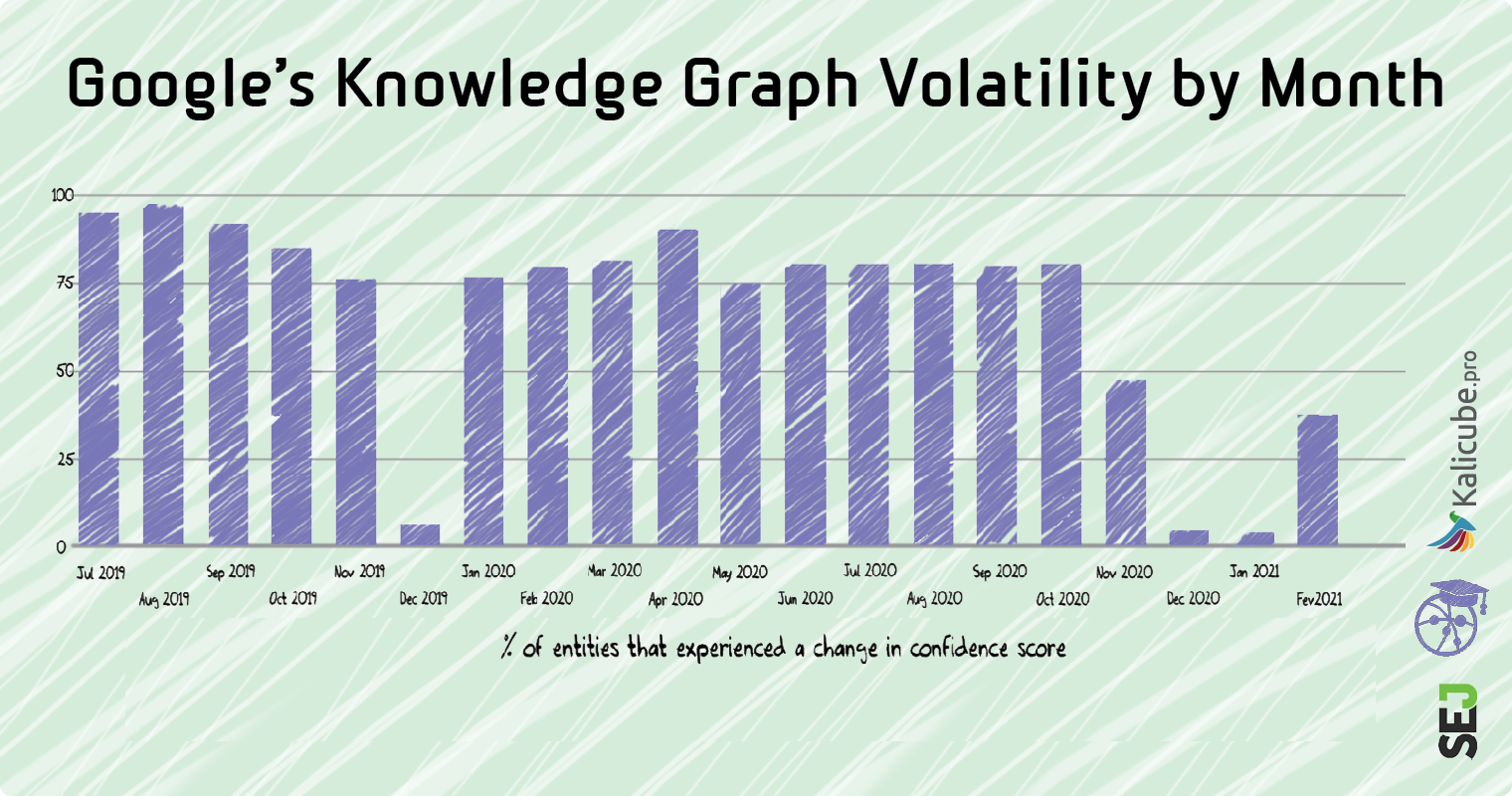
Since July 2020, we have been tracking daily to see if we can spot more granular patterns. I hadn’t seen any until a conversation with Andrea Volpini from Wordlift sent me down a rabbit hole…
And there, I discovered some truly stunning insights.
Note: This article is specifically about the results returned by the API and the insights they give us into when Google updates its Knowledge Graph – including the size, nature, and day of the update — which is a game-changer if you ask me.
Major Knowledge Graph Updates Over the Last 8 Months
- Sunday, July 12, 2020.
- Monday, July 13, 2020.
- Wednesday, August 12, 2020.
- Saturday, August 22, 2020.
- Wednesday, September 9, 2020.
- Saturday, September 19, 2020.
- Sunday, October 11, 2020.
- Thursday, February 11, 2021.
- Thursday, February 25, 2021.
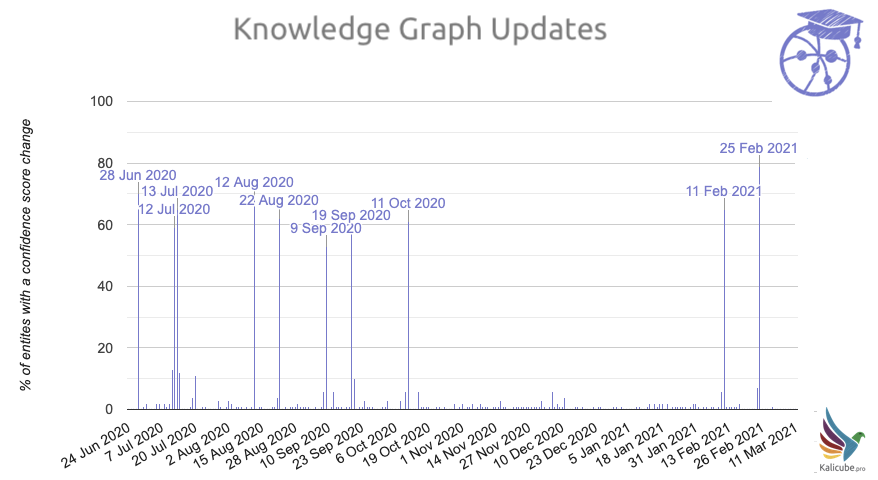
You can check the updates on Kalicube’s Knowledge Graph Sensor here (updated daily).
For anyone following the core blue link algorithm updates, you might notice that the two are out of sync, up until February 2021 updates.
The exceptions I found are (with my wild theorizing in italics):
- The October 11 update that is uncomfortably close to the Indexing Bug of October 12, 2020, reported by Moz.
Could it be that the 3-month hiatus in Knowledge Graph updates is simply that, over those months, Google merged the two datasets and that the Knowledge Graph took a 3-month hiatus while they worked on the kinks of that massive move? - The February 11 update that occured just one day after the move to Passage Indexing (February 10, 2021).
Could passage-based indexing mean entity-based indexing? Passage-based indexing is all about chunking the pages to better extract the entities. - The February 25 update coincides with the volatility in Google SERPs widely reported on 25th and 26th of February 2021.
Could this be a sign that the core algorithm and the Knowledge graph are now synched and entity-based results are now a reality?
Reach, Scope & Scale of These Updates
We can usefully consider three aspects of an update:
- The magnitude (reach/breadth), which is the percentage of entities affected (so far, between 60-80%).
- The amplitude (scope/height), or the change (up or down) in confidence scores on a micro, per entity level (the average amplitude for the middle fifty has been around 10-15%).
- The shift (scale/depth), which is the change in confidence scores on a macro level (the Budapest update aside, this is less than 0.1%).
What We Found by Tracking the Knowledge Graph Daily
The Knowledge Graph has very regular updates.
These updates occur every 2 to 3 weeks but with long pauses at times, as you can see above.
The updates are violent and sudden.
We see that 60-80% of entities are affected, and the changes are probably immediate across the entire dataset.
Updates to individual entities continue in between.
Any individual entity can see its confidence score increase or decrease on any day, whether there is an update or not. It can disappear (in a virtual puff of smoke) and information about that entity can change at any time between these major updates to the Knowledge Graph algorithm and data.
There are extreme outlying cases.
Individual entities react very differently. In every update (and even in between), some changes are extreme. A confidence score can increase multifold in a day. It can drop multi-fold. And an entity can disappear altogether (when it does reappear it has a new id).
There is a ceiling.
The average confidence score for the entire dataset rarely changes by more than one-tenth of one percent per day (the shift), even on days where a major update occurs.
It appears there may be a ceiling to the scores the system can attribute, presumably to stop the more dominant entities from completely crowding out the rest (thanks Jono Alderson for that suggestion).
Following the massive raising of that ceiling during the Budapest update, the ceiling appears to have not moved in any meaningful manner since.
Every update since Budapest affects both reach and scope. None since Budapest has triggered a major shift in scale.
The ceiling may never change again. But then it may. And if it does, that will be big. So stay tuned (and ideally, be prepared).
After a great deal of experimentation, we have isolated and excluded those extreme outliers.
We do track them and continue to try to see any obvious pattern. But that is a story for another day.
How We Are Measuring
We have isolated each of the three aspects of the changes and measure them daily on a dataset of 3000 entities. We measure:
- How many entities saw an increase or decrease (reach/breadth/magnitude).
- How significant that change was on a micro-level (scope/height/amplitude).
- How significant the change was to the overall score (scale/depth/shift).
What Is Happening?
One thing is clear: these updates have been violent, wide-ranging, and sudden.
Someone at Google had (and perhaps still has) “a big red button.”
Bill Slawski mentioned to me a Bing patent that mentions exactly that process.
The last two updates on Thursdays smack of the developers’ mantra “never change anything on a Friday if you don’t want to work the weekend.”
A Google Knowledge Graph Dance
Slawski suggested a concept to me that I think speaks volumes. Google has been playing “musical chairs” with the data – the core algorithms and the Knowledge Graph algorithm have very different needs.
- The core algorithms have a fundamental reliance on popularity (the probability that inbound links lead to your site), whereas the Knowledge Graph necessarily needs to put that popularity/probability to one side and look at reliability/probable truthfulness/authority — in other words, confidence.
- The core algorithms focus on strings of characters/words, whereas the Knowledge Graph relies on the understanding of the entities those same words represent.
It is possible that the updates of the core and Knowledge Graph algorithms were necessarily out of sync, since Google was having to “reorganize” the data for each approach every time they wanted to update either, then switch back.
Remember the Google Dance back in the day?
At the time it was simply a batch upload of fresh link data. This could have been something similar.
As of February 2021, Is the Dance Over?
It remains to be seen if that is now a “solved problem.”
I would imagine we’ll see a few more out-of-sync dances and a few more weird bugs due to updates of each that contradict each other.
But that by the end of 2021, the two will be merged to all intents and purposes and entity-based search will be a reality that we, as marketers, can productively and measurably leverage.
However the algorithms evolve and progress, the underlying shift is seismic.
Classifying the corpus of data Google possesses into entities and organizing that information according to confidence in its understanding of those entities is a huge change from organizing that same data by pure relevancy (as has been the case up until now).
The convergence of the algorithms?
Opinion: The following things make me think that winter 2020/2021 was the moment Google truly implemented the switch “from string to things” (after five years’ worth of PR):
- The three-month hiatus from October to February when the core algorithm was relatively active, but the Knowledge Graph updates were very clearly paused.
- The announcement that the topic layer was active in November.
- The introduction of passage-based indexing to the core algorithm in February that appears to focus on extracting entities.
- The seeming convergence of the updates (this is fresh; we only have two updates to judge from, and our tracking might later prove me wrong on this one, of course).
The Knowledge Graph Is a Living Thing
The Knowledge Graph appears to be based on a data-lake approach rather than the data-river approach of today’s core algorithm (delayed reaction versus immediate effect).
However, the fact that entities change and move between these major updates and the fact that the updates appear to be converging suggests that we aren’t far from a Knowledge Graph algorithm that not only works on fresh data rivers but is also integrated as part and parcel of the core algorithm.
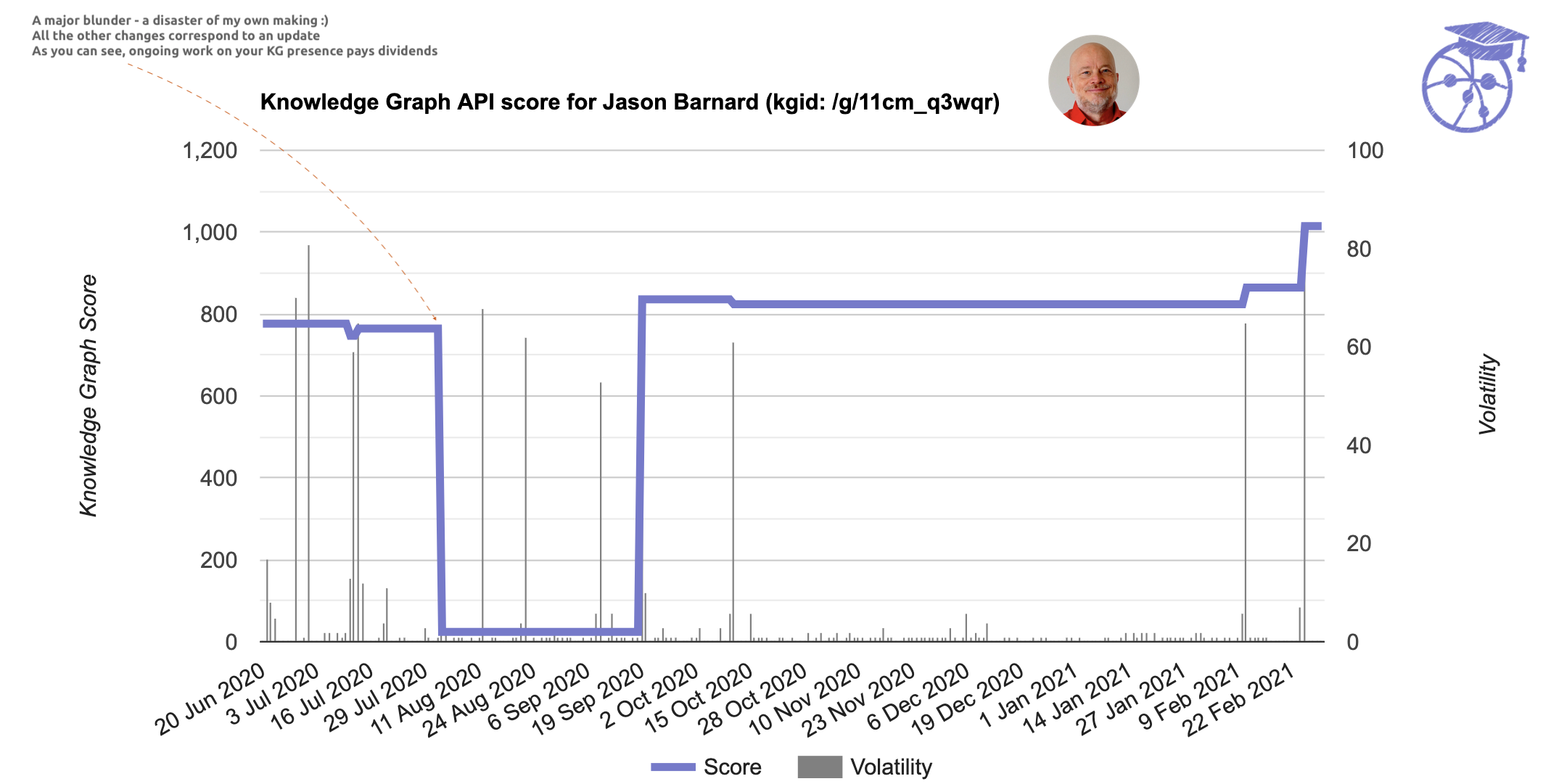
Here’s a specific example that maps the updates to changes in the confidence score for my name (one of my experiments).
That vertiginous drop doesn’t map to an update.
It was a blunder on my part and shows that the updates to individual entities are ongoing, and can be extreme!
Read about that particular disaster here in my contribution to an article by SE Ranking.
The Future
My take: The “big red button” will be progressively retired and the violent and sudden updates will be replaced by changes and shifts that are smoother and less visible.
The integration of entities into the core blue links algorithms will be increasingly incremental and impossible to track (so let’s make the most of it while we can).
It is clear that Google is moving rapidly toward a quasi-human understanding of the world and all its algorithms will increasingly rely on its understanding of entities and its confidence in its understanding.
The SEO world will need to truly embrace entities and give more and more focus to educating Google via its Knowledge Graph.
Conclusion
In this article I have purposefully stuck to things I am fairly confident will prove to be true.
I have hundreds of ideas, theories, and plans, and my company continues to track 70,000+ entities on a monthly basis — over 3,000 daily.
I am also running over 500 active experiments on the Knowledge Graph and knowledge panels (including on myself, the blue dog, and the yellow koala), so expect more news soon.
In the meantime, I’m just hoping Google won’t cut my access to the Knowledge Graph API!
More Resources:
- What Is the Google Knowledge Graph & How it Works
- How to Maximize Your Reach Using Google’s Knowledge Graph
- A Personalized Entity Repository in the Knowledge Graph
Image Credits
All screenshots taken by author, March 2021
