

These difficult times it is more important than ever to get more effective work done in less time and with fewer resources.
One boring and time-consuming SEO task that is often neglected is writing compelling titles and meta descriptions at scale.
In particular, when the site has thousands or millions of pages.
It is hard to put on the effort when you don’t know if the reward will be worth it.
In this column, you will learn how to use the most recent advances in Natural Language Understanding and Generation to automatically produce quality titles and meta descriptions.
We will access this exciting generation capability conveniently from Google Sheets. We will learn to implement the functionality with minimal Python and JavaScript code.
Here is our technical plan:
- We will implement and evaluate a couple of recent state of the art text summarization models in Google Colab
- We will serve one of the models from a Google Cloud Function that we can easily call from Apps Script and Google Sheets
- We will scrape page content directly from Google Sheets and summarize it with our custom function
- We will deploy our generated titles and meta descriptions as experiments in Cloudflare using RankSense
- We will create another Google Cloud Function to trigger automated indexing in Bing
Introducing Hugging Face Transformers
Hugging Face Transformers is a popular library among AI researchers and practitioners.
It provides a unified and simple to use interface to the latest natural language research.
It doesn’t matter if the research was coded using Tensorflow (Google’s Deep Learning framework) or Pytorch (Facebook’s framework). Both are the most widely adopted.
While the transformers library offers simpler code, it isn’t as simple enough for end users as Ludwig (I’ve covered Ludwig in previous deep learning articles).
That changed recently with the introduction of the transformers pipelines.
Pipelines encapsulate many common natural language processing use cases using minimal code.
They also provide a lot flexibility over the underlying model usage.
We will evaluate several state of the art text summarization options using transformers pipelines.
We will borrow some code from the examples in this notebook.
Facebook’s BART
When announcing BART, Facebook Researcher Mike Lewis shared some really impressive abstractive summaries from their paper.
I found the summarization performance surprisingly good – BART does seem to be able to combine information from across a whole document with background knowledge to produce highly abstractive summaries. Some typical examples beneath: pic.twitter.com/EENDPgTqrl
— Mike Lewis (@ml_perception) October 31, 2019
Now, let’s see how easy it is to reproduce the results of their work using a transformers pipeline.
First, let’s install the library in a new Google Colab notebook.
Make sure to select the GPU runtime.
!pip install transformersNext, let’s add this the pipeline code.
from transformers import pipeline
# use bart in pytorch
bart_summarizer = pipeline("summarization")This is the example text we will summarize.
TEXT_TO_SUMMARIZE = """
New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
2010 marriage license application, according to court documents.
Prosecutors said the marriages were part of an immigration scam.
On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s
Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
"""Here is the summary code and resulting summary:
summary = bart_summarizer(TEXT_TO_SUMMARIZE, min_length=50, max_length=250)
print(summary) #Output: [{'summary_text': 'Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She is believed to still be married to four men, and at one time, she was married to eight at once.'}]I specified the generated summary should not have less than 50 characters and at most 250.
This is very useful to control the type of generation: titles or meta descriptions.
Now, look at the quality of the generated summary and we only typed a few lines of Python code.
Super cool!
'Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the marriages were part of an immigration scam. She is believed to still be married to four men, and at one time, she was married to eight at once.'
print(len(summary[0]["summary_text"]))
#Output: 249Google’s T5
Another state of the art model is Text-to-Text Transfer Transformer, or T5.
One impressive accomplishment of the model is that its performance got really close to the human level baseline in the SuperGLUE leaderboard.
Google's T5 (Text-To-Text Transfer Transformer) language model set new record and gets very close to human on SuperGLUE benchmark.https://t.co/kBOqWxFmEK
Paper: https://t.co/mI6BqAgj0e
Code: https://t.co/01qZWrxbqS pic.twitter.com/8SRJmoiaw6— tung (@yoquankara) October 25, 2019
This is notable because it NLP tasks in SuperGLUE are designed to be easy for humans but hard for machines.
Google recently published a summary writeup with all the details of the model for people less inclined to learn about it from the research paper.
Their core idea was to try every popular NLP idea on a new massive training dataset they call C4 (Colossal Clean Crawled Corpus).
I know, AI researchers like to have fun naming their inventions.
Let’s have use another transformer pipeline to summarize the same text, but this time using T5 as the underlying model.
t5_summarizer = pipeline("summarization", model="t5-base", tokenizer="t5-base")
summary = t5_summarizer(TEXT_TO_SUMMARIZE, min_length=50, max_length=250)Here is the summarized text.
[{'summary_text': 'in total, barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002 . she is believed to still be married to four men, and at one time, she was married to eight men at once .'}]This summary is also very high quality.
But I decided to try the larger T5 model which is also available as a pipeline to see if the quality could improve.
t5_summarizer_larger = pipeline("summarization", model="t5-large", tokenizer="t5-large")I was not disappointed at all.
Really impressive summary!
[{'summary_text': 'Liana barrientos has been married 10 times . nine of her marriages occurred between 1999 and 2002 . she is believed to still be married to four men, and at one time, she was married to eight men at once .'}]Introducing Cloud Functions
Now that we have code that can effectively summarize page content, we need a simple way to expose it as an API.
In my previous article, I used Ludwig serve to do this, but as we are not using Ludwig here, we are going to a different approach: Cloud Functions.
Cloud Functions and equivalent “serverless” technologies are arguably the simplest way to get server-side code for production use.
They are called serverless because you don’t need to provision web servers or virtual machines in hosting providers.
They dramatically simplify the deployment experience as we will see.
Deploying a Hello World Cloud Function
We don’t need to leave Google Colab to deploy our first test Cloud Function.
First, login to your Google Compute account.
!gcloud auth login --no-launch-browserThen, set up a default project.
!gcloud config set project project-nameNext, we will write our test function in a file named main.py
%%writefile main.py
def hello_get(request):
"""HTTP Cloud Function.
Args:
request (flask.Request): The request object.
Returns:
The response text, or any set of values that can be turned into a
Response object using `make_response`
.
"""
return 'Hello World!'We can deploy this function using this command.
!gcloud functions deploy hello_get --runtime python37 --trigger-http --allow-unauthenticatedAfter a few minutes, we get the details of our new API service.
availableMemoryMb: 256
entryPoint: hello_get
httpsTrigger:
url: https://xxx.cloudfunctions.net/hello_get
ingressSettings: ALLOW_ALL
labels:
deployment-tool: cli-gcloud
name: projects/xxx/locations/us-central1/functions/hello_get
runtime: python37
serviceAccountEmail: xxxx
sourceUploadUrl: xxxx
status: ACTIVE
timeout: 60s
updateTime: '2020-04-06T16:33:03.951Z'
versionId: '8'That’s it!
We didn’t need to set up virtual machines, web server software, etc.
We can test it by opening the URL provided and the get text “Hello World!” as a response in the browser.
Deploying our Text Summarization Cloud Function
In theory, we should be able to wrap our text summarization pipeline into a function and follow the same steps to deploy an API service.
However, I had to overcome several challenges to get this to work.
Our first and most challenging problem was installing the transformers library to begin with.
Fortunately, it is simple to install third-party packages to use in Python-based Cloud Functions.
You simply need to create a standard requirements.txt file like this:
%%writefile requirements.txt
transformers==2.0.7Unfortunately, this fails because transformers require either Pytorch or Tensorflow. They are both installed by default in Google Colab, but need to be specified for the Cloud Functions environment.
By default, Transformers uses Pytorch, and when I added it as a requirement, it threw up an error that led me to this useful Stack Overflow thread.
I got it to work with this updated requirement.txt file.
%%writefile requirements.txt
https://download.pytorch.org/whl/cpu/torch-1.0.1.post2-cp37-cp37m-linux_x86_64.whl
transformers==2.0.7The next challenge was the huge memory requirements of the models and limitations of the Cloud Functions.
I first tested functions using simpler pipelines like the NER one, NER stands for Name Entity Recognition.
I test it first in the Colab notebook.
from transformers import pipeline
nlp_token_class = None
def ner_get(request):
global nlp_token_class
#run once
if nlp_token_class is None:
nlp_token_class = pipeline('ner')
result = nlp_token_class('Hugging Face is a French company based in New-York.')
return resultI got this breakdown response.
[{'entity': 'I-ORG', 'score': 0.9970937967300415, 'word': 'Hu'},
{'entity': 'I-ORG', 'score': 0.9345749020576477, 'word': '##gging'},
{'entity': 'I-ORG', 'score': 0.9787060022354126, 'word': 'Face'},
{'entity': 'I-MISC', 'score': 0.9981995820999146, 'word': 'French'},
{'entity': 'I-LOC', 'score': 0.9983047246932983, 'word': 'New'},
{'entity': 'I-LOC', 'score': 0.8913459181785583, 'word': '-'},
{'entity': 'I-LOC', 'score': 0.9979523420333862, 'word': 'York'}]Then, I can simply add a %%writefile main.py to create a Python file I can use to deploy the function.
When I reviewed the logs to learn why the API calls failed, I saw the memory requirement was a big issue.
But, fortunately, you can easily override the default 250M limit and execution timeout using this command.
!gcloud functions deploy ner_get --memory 2GiB --timeout 540 --runtime python37 --trigger-http --allow-unauthenticated
I basically specify the maximum memory 2GB and 9 minutes execution timeout to allow for the initial download of the model which can be gigabytes of transfer.
One trick I’m using to speed up subsequent calls to the same Cloud Function is to cache the model downloaded in memory using a global variable and checking if it existing before recreating the pipeline.
After testing BART and T5 functions and settled with a T5-small model which fits well within the memory and timeout requirements of Cloud Functions.
Here is the code for that function.
%%writefile main.py
from transformers import pipeline
nlp_t5 = None
def t5_get(request):
global nlp_t5
#run once
if nlp_t5 is None:
nlp_t5 = pipeline('summarization', model="t5-small", tokenizer="t5-small")
TEXT_TO_SUMMARIZE = """
New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York...
"""
result = nlp_t5(TEXT_TO_SUMMARIZE)
return result[0]["summary_text"]And here is the code to deploy it.
!gcloud functions deploy t5_get --memory 2GiB --timeout 540 --runtime python37 --trigger-http --allow-unauthenticatedOne problem with this function is that the text to summarize is hard coded.
But we can easily fix that with the following changes.
%%writefile main.py
from transformers import pipeline
nlp_t5 = None
def t5_post(request):
global nlp_t5
#run once
if nlp_t5 is None:
#small model to avoid memory issue
nlp_t5 = pipeline('summarization', model="t5-small", tokenizer="t5-small")
#Get text to summarize from POST request
content_type = request.headers['content-type']
if content_type == 'application/x-www-form-urlencoded':
text = request.form.get('text')
result = nlp_t5(text)
return result[0]["summary_text"]
else:
raise ValueError("Unknown content type: {}".format(content_type))
return "Failure"I simply make sure the content type is form url-encoded, and read the parameter text from the form data.
I can easily test this function in Colab using the following code.
import requests
url = "https://xxx.cloudfunctions.net/hello_post"
data = {"text": text[:100]}
requests.post(url, data).textAs everything works as expected, I can work on getting this working in Google Sheets.
Calling our Text Summarization Service from Google Sheets
I introduced Apps Script in my previous column and it really gives Google Sheets super powers.
I was able to make minor changes to the function I created to make it usable for text summarization.
function getSummary(text){
payload = `text=${text}`;
payload = encodeURI(payload);
console.log(payload);
var url = "https://xxx.cloudfunctions.net/t5_post";
var options = {
"method" : "POST",
"contentType" : "application/x-www-form-urlencoded",
"payload" : payload,
'muteHttpExceptions': true
};
var response = UrlFetchApp.fetch(url, options);
var result = response.getContentText();
console.log(result);
return result;
}That’s all.
I changed the input variable name and the API URL.
The rest is the same as I need to submit a POST request with form data.
We run tests, and check the console logs to make sure that everything works as expected.
It does.
One big limitation in Apps Script is that custom functions can’t run for more than 30 seconds.
In practice, this means, I can summarize text if it is under 1,200 characters, while in Colab/Python I tested full articles with more than 10,000 characters.
An alternative approach that should work better for longer text is to update the Google Sheet from Python code as I’ve done in this article.
Scraping Page Content from Google Sheets
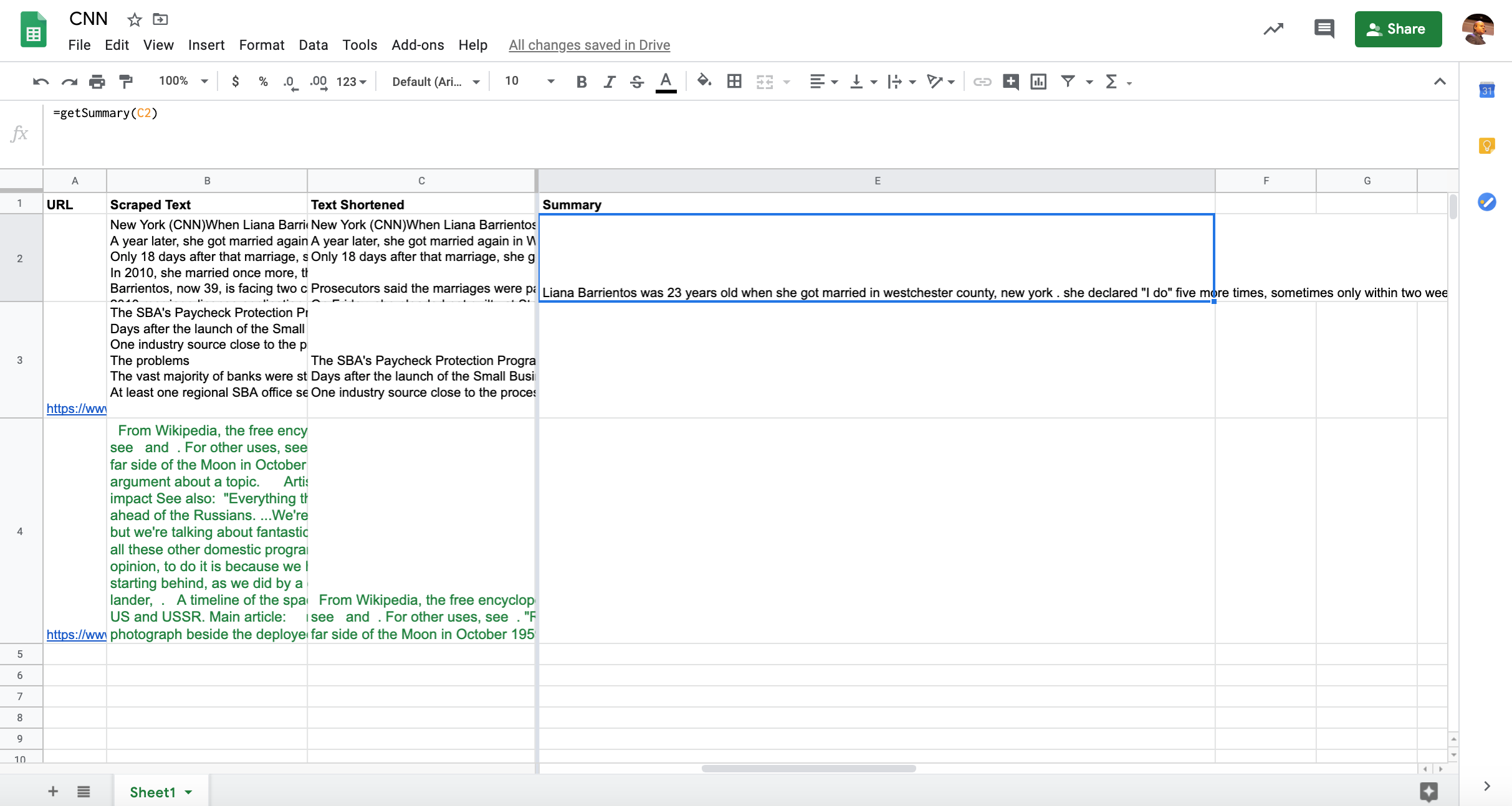
Here are some examples of the full working code in Sheets.
Now that we are able to summarize text content, let’s see how we can extract it directly from public webpages.
Google Sheets includes a powerful function for this called IMPORTXML.
We just need to provide the URL and an XPath selector that identifies the content we want to extract.
Here is code to extract content from a Wikipedia page.
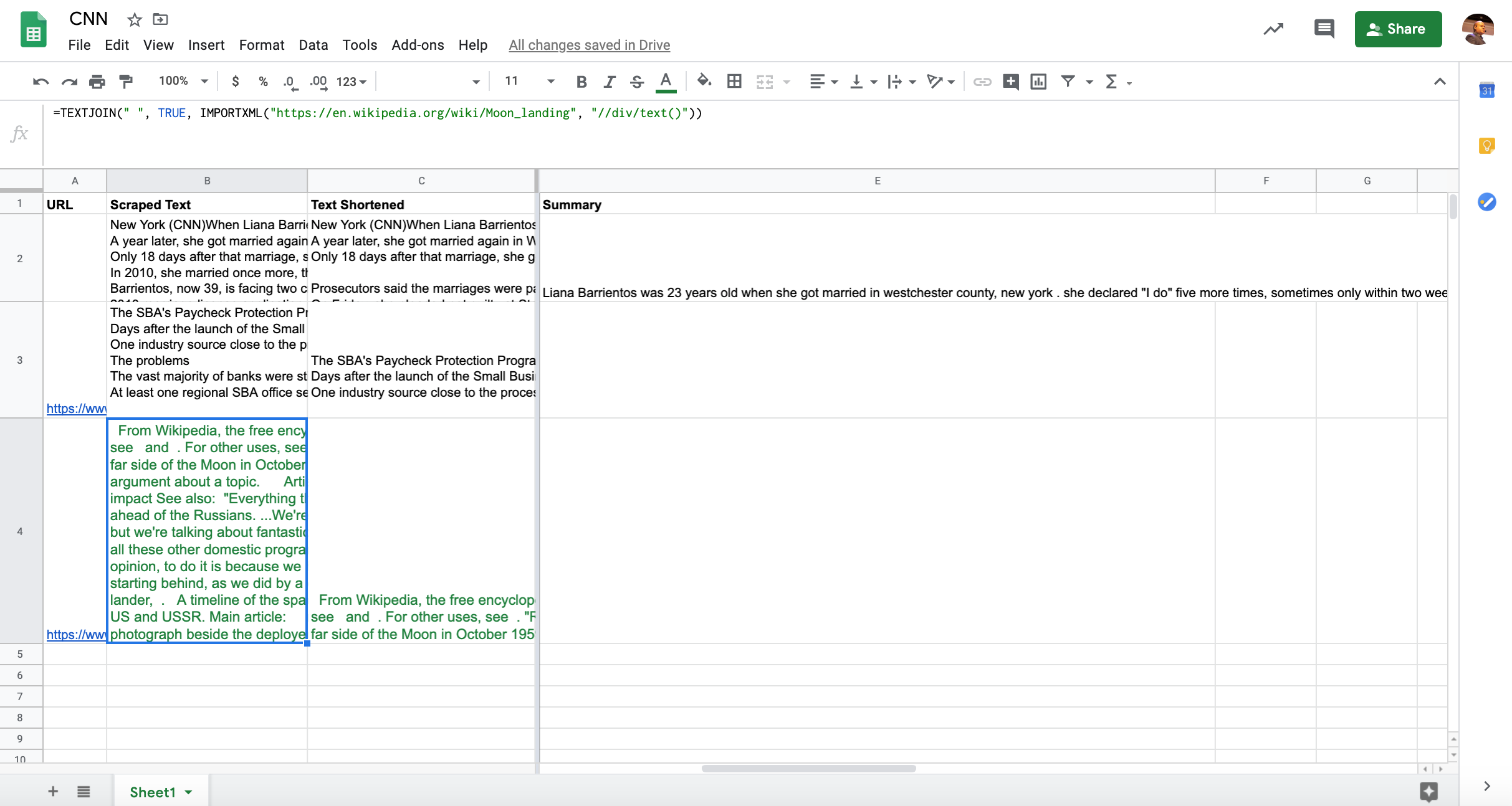
=IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing", "//div/text()")I used a generic selector to capture all text inside DIVs.
Feel free to play with different selectors that fit your target page content.
While we are able to get the page content, it breaks down over multiple rows. We can fix that with another function, TEXTJOIN.
=TEXTJOIN(" ", TRUE, IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing", "//div/text()"))Fast Indexing Our New Meta Descriptions and Titles in Bing
So, how do we know if these new search snippets perform better than manually written ones or compared to no meta data at all?
A surefire way to learn is by running a live test.
In such case, it is critically important to get our changes indexed fast.
I’ve covered how to do this in Google by automating the URL Inspection tool.
That approach limits us to a few hundred pages.
A better alternative is to use the awesome Bing fast indexing API because we get to request indexing for up to 10,000 URLs!
How cool is that?
As we would be primarily interested in measuring CTR, our assumption is that if we get higher CTR in Bing, the same will likely happen in Google and other search engines.
A service allowing publishers to get URLs instantly indexed in Bing and actually begin ranking within minutes deserves to be considered. It's like free money, why would anyone not take it?@sejournal @bing @BingWMC https://t.co/a5HkIpbxHI
— Roger Montti (@martinibuster) March 20, 2020
I have to agree with Roger. Here is the code to do that.
api_key = "xxx" # Get your own API key from this URL https://www.bing.com/webmaster/home/api
import requests
def submit_to_bing(request):
global api_key
api_url=f"https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey={api_key}"
print(api_url)
#Replace for your site
url_list = [
"https://www.domain.com/page1.html", "https://www.domain.com/page2.html"]
data = {
"siteUrl": "http://www.domain.com",
"urlList": url_list
}
r = requests.post(api_url, json=data)
if r.status_code == 200:
return r.json()
else:
return r.status_codeIf the submission is successful, you should expect this response.
{'d': None}We can then create another Cloud Function by adding it to our main.py file and using the deploy command as before.
Testing Our Generated Snippets in Cloudflare
Finally, if your site uses the Cloudflare CDN, you could use the RankSense app to run these changes as experiments before you roll them out across the site.
Simply copy the URL and text summary columns to a new Google Sheet and import it into the tool.
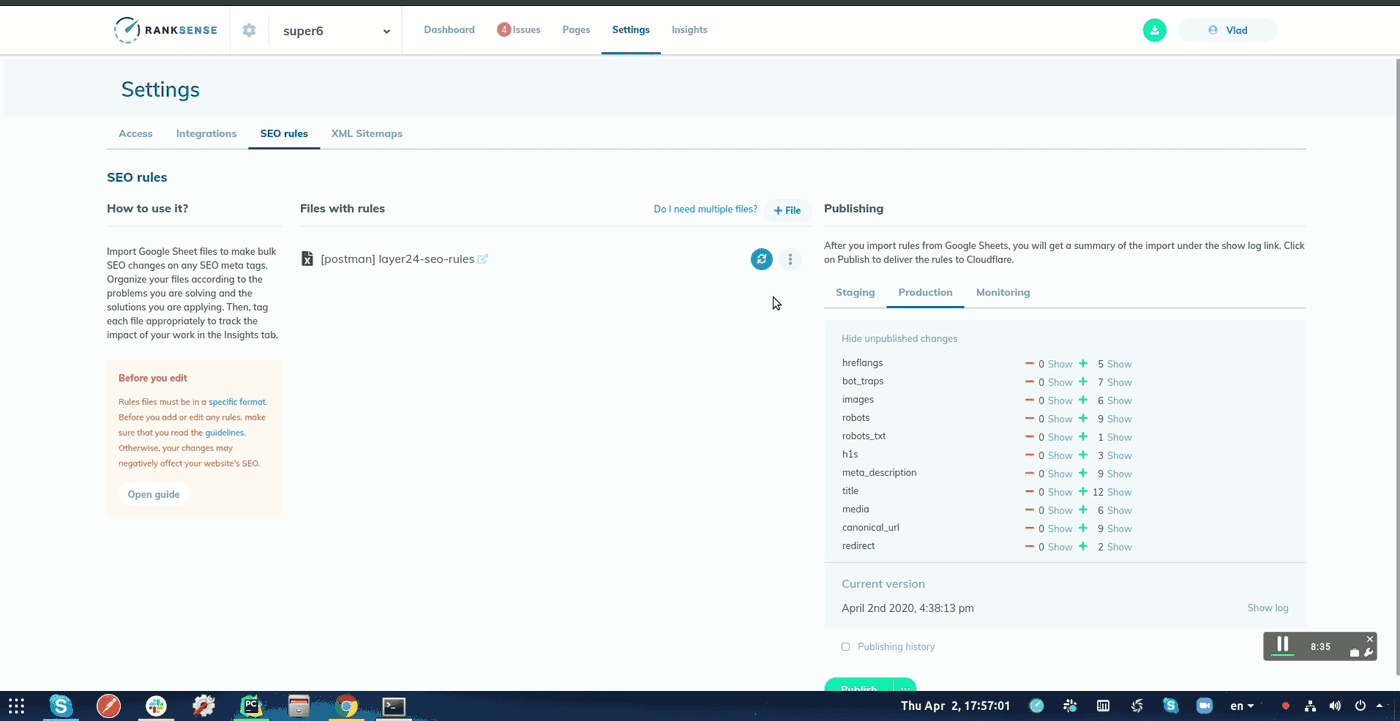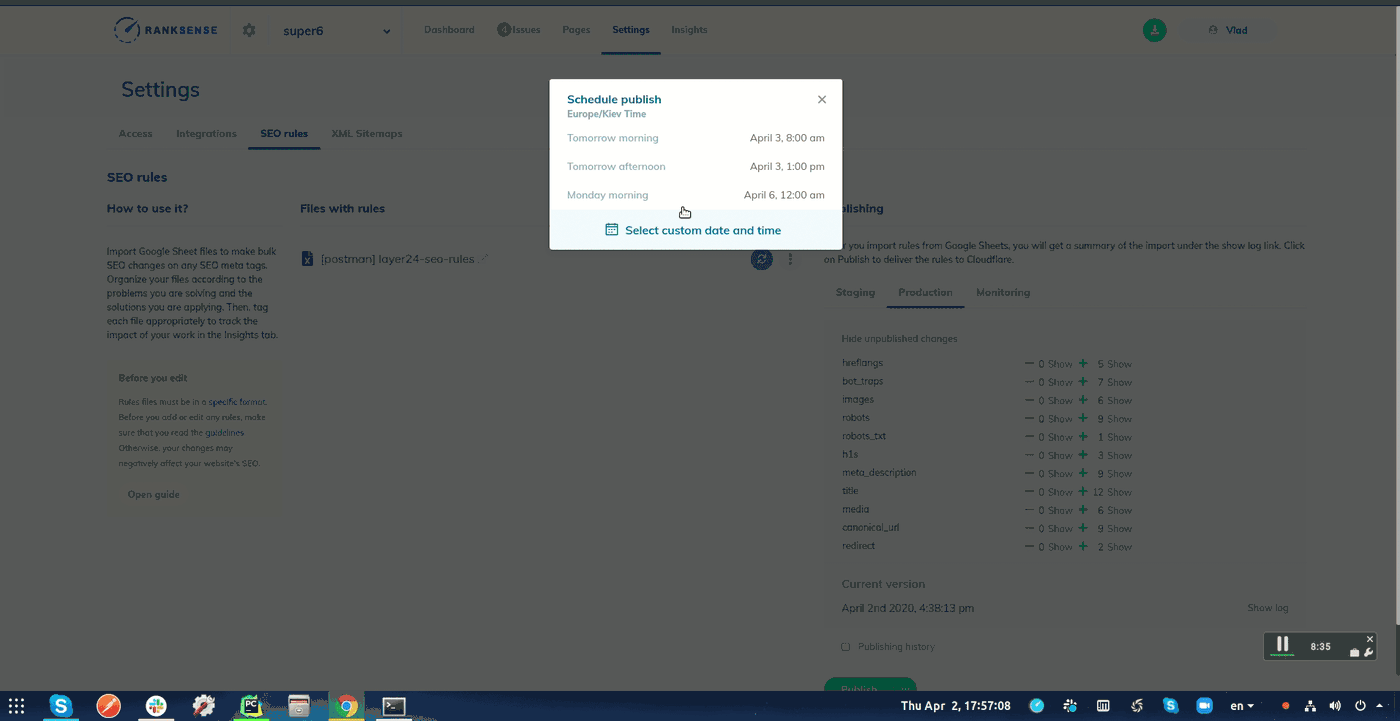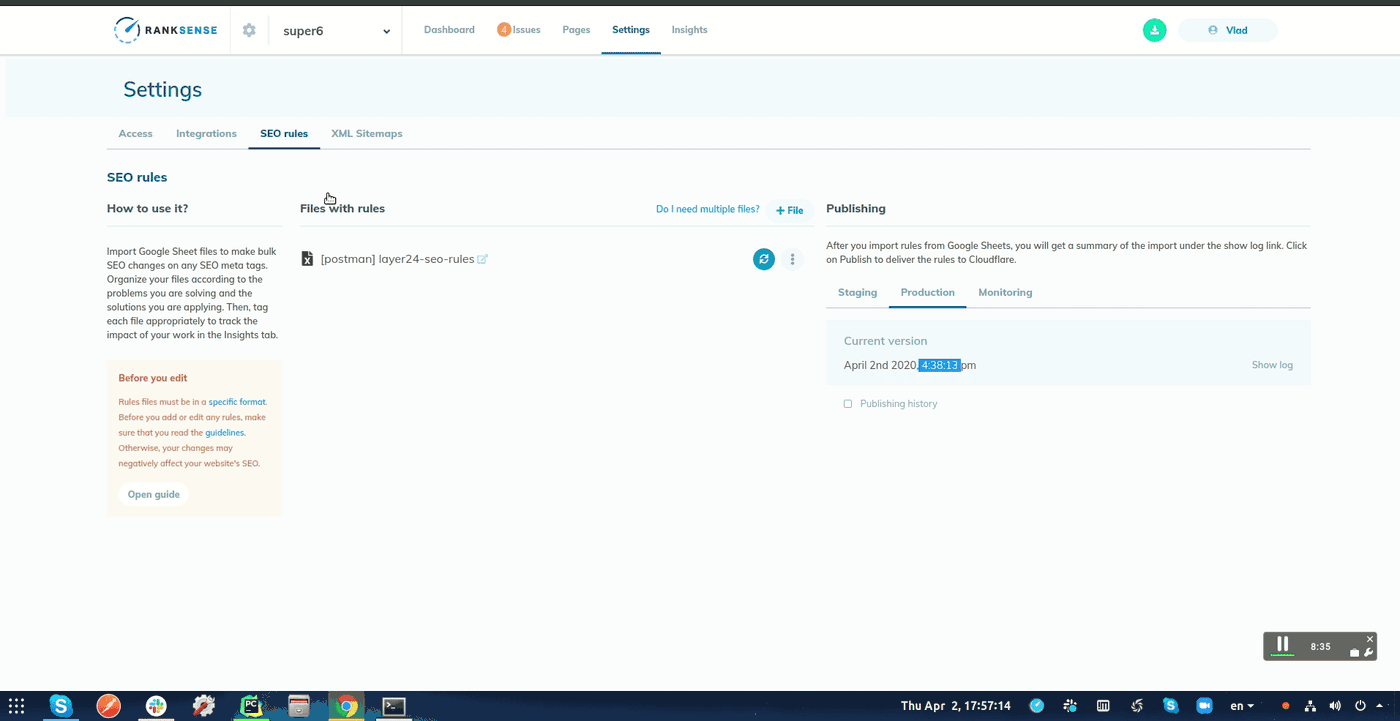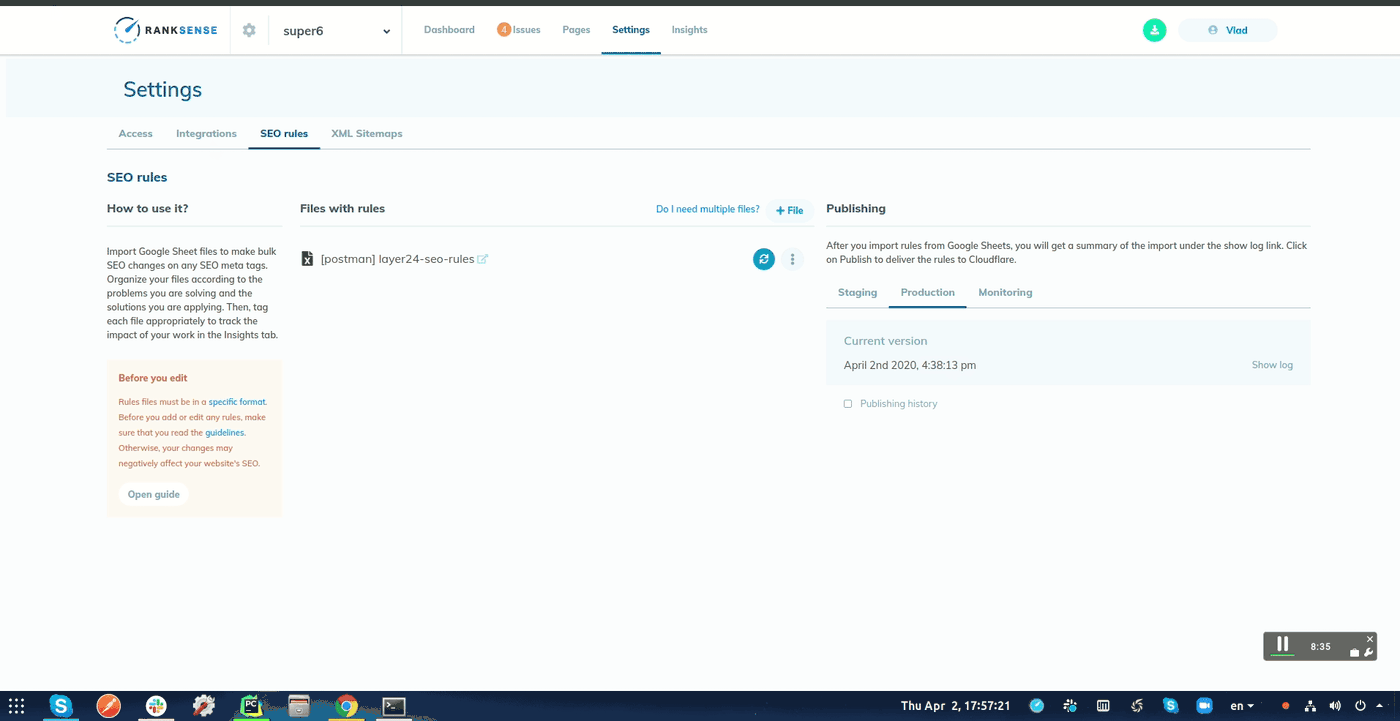
When you publish the experiment, you can opt to schedule the change and specify a webhook URL.
A webhook URL allows apps and services to talk to each other in automated workflows.
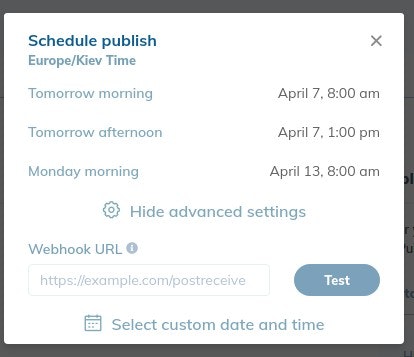
Copy and paste the URL of the Bing indexing Cloud Function. RankSense will call it automatically 15 minutes after the changes are propagated in Cloudflare.
Resources to Learn More
Here are links to some resources that were really useful during the research for this piece.
- Hugging Face Transformers Tutorial
- Summarization pipelines
- Google Cloud Functions Quickstart
- Serving Models using Cloud Functions
- Bing Submission API
- Bing Submission API Tutorial
- RankSense Webhook API
Image Credits
All screenshots taken by author, April 2020
