

Like many other concepts in SEO, TF-IDF it a topic that is much debated.
First, you read about it being a silver bullet to rank your content on Google.
Then, immediately, you hear that TF-IDF is so old-school that it isn’t worth any effort.
The truth usually lies somewhere in the middle.
This post will explore why you shouldn’t expect TF-IDF to substitute a comprehensive optimization strategy and what the true benefits are of using it for SEO.
TF-IDF: What Kind of Beast Is That?
For a human brain, it doesn’t take any math to tell what my article is about. It’s about TF-IDF, right?
But when relevancy is evaluated (and, most importantly, compared for several articles) by a machine, we need a numeric representation to see that:
- Article A is about TF-IDF (as opposed to, say, link building).
- Article A is more about TF-IDF than article B.
Could we simply count the number of times our keyword, TF-IDF, appears in each document?
No, thus we obviously ignore the size of the documents.
Could we compare the count of our keyword to the total number of words?
This is what we call keyword density – a widely used content optimization metric of the past.
But relying on keyword density makes me think that the word “to be” (not “TF-IDF”) is the most prominent one in this article.
Is there a way to adjust my calculations for the fact that some words appear more frequently in speech in general?
This is where TF-IDF comes into play, letting us see how “TF-IDF” use frequency in this article compares to its average use frequency across other documents on the Web.
Thus, we’re able to pay less attention to all the commonly used words and distinguish a very specific topic for a particular piece of content.
The formula for my calculations looks like this:
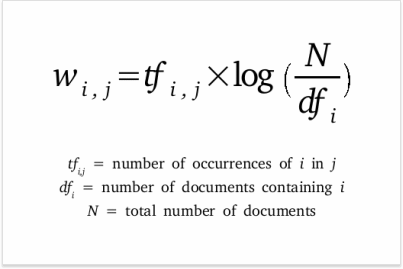
Or, to put it simply (disclaimer: I’m purposefully oversimplifying here for the sake of conveying the basic idea), we’re taking:
- Term Frequency = (count of the term) / (total word count in the document)
- Inverse Document Frequency = log (number of docs) / (docs containing keyword)
When multiplied by Inverse Document Frequency, Term Frequency gets lower for commonly used words and higher for unique topic-identifying terms.
Back to our example, the verb “to be” is used in each and every article in English. But very few articles mention “TF-IDF”, “keywords”, “content” and other important subtopics I’m covering in my article.
So, TF-IDF for these terms gets higher and… voila! The machine knows what my article is about.
Generally, TF-IDF is used when we need a machine to identify topics of a huge set of documents. For instance, it’s widely applied in recommender systems in digital libraries.
Is Google Using TF-IDF as a Ranking Signal?
The short answer is “no.”
TF-IDF is referred to in a number of Google Patents as something that the search engine may use for stop words removal, which is to get rid of all the function words within a search query and in page content:

But using this exact mechanism for identifying and comparing relevancy is very unlikely.
Simply because being an example of a lexical search mechanism, TF-IDF is unable to look beyond keywords.
The model considers keywords as strings of characters and cannot identify semantic relations between them, as opposed to semantic search models most probably used by Google.
In other words, TF-IDF itself is not a ranking signal that determines your page’s position.
There’s no expected TF-IDF value you need to match for each keyword in your content. And you’d better run from anyone trying to convince you otherwise.
Semantic Search & Co-Occurrences
So, Google has moved to semantic search, trying to match the meaning of a search query to topically relevant content, as opposed to matching query keywords to the same keywords on pages.
In practice, this means that instead of counting keywords themselves, Google started counting co-occurrences, using the surrounding context to understand their meaning.
For example, let’s say you encounter the following sentences and you have no idea what a trout is:
- Trout is rich in omega-3 fatty acids.
- Trout has tender flesh and a mild, somewhat nutty flavor.
- When choosing trout we pay attention to a clear red-orange color.
And you also encounter the following. I assume that most of the readers know what a salmon is:
- Salmon is a popular type of fish in Western cuisine, which goes well with white wine.
- Tender salmon meat can be added to pasta.
- Salmon skin is super nutrient-dense, so keep it why you cook.
The fact that trout occurs with words like omega-3, flesh, and pasta might suggest that trout is a sort of edible fish similar in some way to salmon.
Based on this simple understanding of context, Google is able to build an elaborate system of word vectors, further used to understand user queries and content relevance.
And though I’m not saying you and I should try reverse-engineering the whole vector system, giving more relevancy signals by enriching your content with more co-occurrences seems only logical (and, as several case studies show, really influences Google rankings).
How Can TF-IDF Help Your SEO?
Finding co-occurring terms is exactly where TF-IDF comes into play.
Sure, we don’t have access to every webpage, as Google does. But why would we need those?
To get a whole list of co-occurrence ideas, it is perfectly enough to look at a bunch of pages (say 20 to 30).
And the beauty is that using TF-IDF isn’t rocket science. All you have to do fits in three simple steps.
1. Write Your Content
I’m not urging you to make TF-IDF the purpose of your piece of content.
In the end, unnatural writing simply won’t convert even if the page ranks high and brings in the needed traffic.
So, first of all, you sit down and write about whatever it is that you have on your content plan.
2. Plug in a TF-IDF Tool
Most of the tools I’ve seen work pretty similarly.
You enter a URL and the keywords you want to optimize it for. The tool then checks pages that rank on Google for that keyword, parses their content, calculates TF-IDF for all the terms it finds and compares your content stats to those of your competitors.
With basic tools, like Seobility, you will get a single-keyword list.
If you’re using SEO PowerSuite’s WebSite Auditor, Ryte or Text Tools, you will also have a list of key phrases (or N-grams, if you like a taint of science), which is definitely more informative. (Disclosure: I work for SEO PowerSuite.)
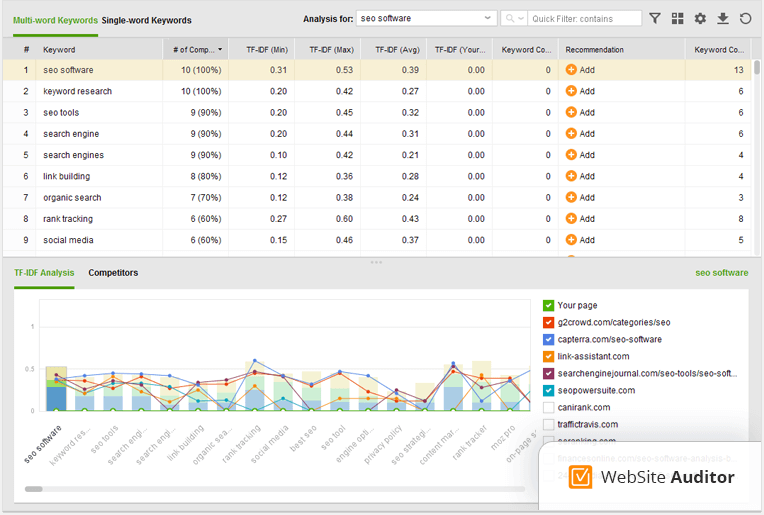
3. Enrich Your Content with TF-IDF Co-Occurrence Suggestions
Some of the phrases will simply be synonymous with what you already have in your content.
If appropriate, try using them along the way.
Some of the phrases will point out the new topics, which haven’t crossed your mind yet.
Sift through the ideas and think of ways to use them in your content (without getting obsessed about them).
TF-IDF for Keyword Research
A little bonus tip.
Picking up the most widely used terms from your competitors’ content might also spur new ideas into your keyword research and content planning, especially when you feel the need for out-of-the-box thinking and inspiration.
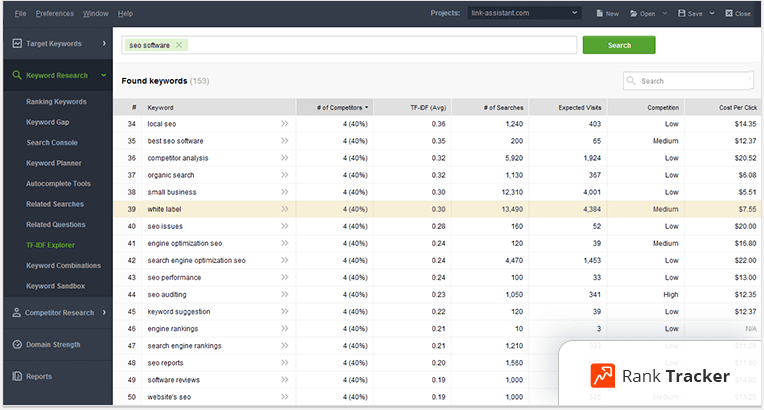
Conclusion
Many a time, you’ll see TF-IDF used as clickbait – articles either promising the formula to be “Google algorithm reverse-engineered” or “busting the myth of TF-IDF”.
But I encourage you to take things for what they are and use the opportunities TF-IDF optimization gives. Without betting your entire SEO campaign on it.
More Resources:
- Google’s John Mueller Discusses TF-IDF Algo
- The Rise of On-Page SEO Tools: Pushing the Frontiers of SEO & Content
- Content Analysis and Better Ranking
Image Credits
Featured Image: Created by author, October 2019
All screenshots taken by author, October 2019
