

Technical SEO can be a bit scary. It’s got fangs.
To defeat technical SEO monsters, you’ve got to venture into the caves and castles of codebases – sometimes only with a wooden stake in hand.
For this adventure, I’ve recruited SEO savvy developer and professional goth Dave Smart to shine a little light into one of the scariest slices of technical SEO: the Shadow DOM.
Why Does the ShadowDOM Matter?
Like most things, you’ll only care about the SEO monsters likely to show their heads in your world.
I’ve dove fairly deep into the abyss of Rendering, Angular, and performance metrics but this… this is the catacombs of technical SEO, my friend.
You’ll find practical value in learning about the Shadow DOM if/when you’re working with a site that uses Web Components or JavaScript frameworks.
Or you’re staring at a page source that looks like one of these spooky skeletons.
<body>
<section id="root"></section>
</html>
<body>
<section id="root">
<my-web-component></my-web-component>
</section>
</body>
</html>
You’ll care because the Shadow DOM has a bit of a habit of sucking content into it before disappearing into the nether realm.
“When Googlebot renders a page, it flattens the shadow DOM and light DOM content. This means Googlebot can only see content that’s visible in the rendered HTML… If the content isn’t visible in the rendered HTML, Googlebot won’t be able to index it.” – Understand the JavaScript SEO Basics, Search for Developers
We’ll rephrase this and project a little louder for those in the back of the castle:
If our content isn’t indexed, our content can’t rank.

Dungeons & DOMs
Before we head into the crypts, you’ll need to know what a DOM is.
DOM is an acronym for Document Object Model.
The DOM is built with every page request.
Sometimes when the DOM construction goes wrong, the page doesn’t look right.
Other times it assembles slowly prompting panic from an overly concerned but well-intended coworker.
Let’s look at the process that transmutes HTML to the DOM:
- A request is made.
- The requestor receives an initial HTML response (You can see this by right-clicking and selecting View Page Source).
- The requestor assembles as much of the page as possible and queues up the resources required to render the page.
Noteworthy: Google refers to the output of this process as the “Crawled DOM.” - The HTML (a.k.a. Crawled DOM) is passed through a DOMparser, either in the browser or via web rendering service.
- The HTML and resources are converted to a DOM Document, a representation of the content of the page.
What’s in the DOM?
The HTML is represented in the DOM by a series of nested objects called nodes.
Each node can contain content or child nodes.
It’s like the relationship between sitemaps and sitemap indexes.
Most modern browsers are optimized for 1,500 nodes.
This labyrinthian collection of nodes is known as a DOM tree.

We can manipulate and interact with a DOM tree.
This can look like:
- Exposing nodes (think hamburger menus and accordions).
- Changing the content (forms).
- Hiding nodes (dismissing a banner ad).
It’s an important concept because it’s this DOM, not the initial HTML that is served up that defines what you see in the browser, and by extension, what search engines that render pages (like Google!) will index and rank you on.
How Do I See the DOM?
Chrome devTools gives you a great, human-friendly way to see the DOM tree.
- Navigate to a page you want to peek at.
- Hit
Command+Option+C (Mac)orControl+Shift+C(Windows, Linux, Chrome OS). This will open devTools to the elements panel, and you can see the elements of your page, all nicely nested. - Hover over an element in the panel will highlight it on the page.
- Look a the bottom of the console to see how that element is nested in the DOM tree
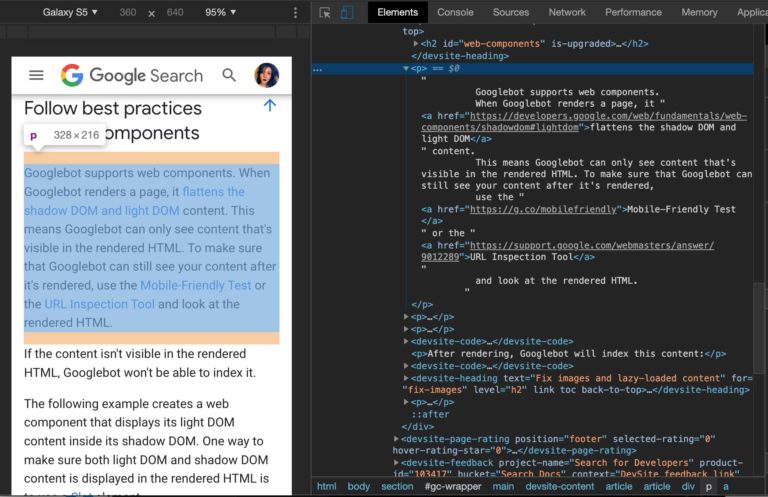
Visualize the DOM Tree in Search Console
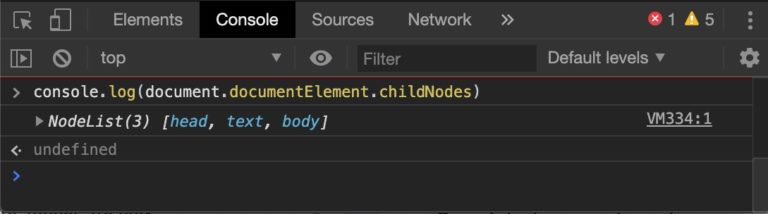
To see the entire DOM Tree and its structure at once, we only need to cast a bit of magic in the dev tools console.
- Open the Dev Tools Console with
Command+Option+J(Mac) orControl+Shift+J (Windows, Linux, Chrome OS)to open the console. - Copy and paste the incantation
console.log(document.documentElement.childNodes). - Hit enter.
- Click an arrow. You’ve expands that node! Nodes can contain their own unique content and children. If you click on any piece of blue anchor text in the DOM tree, you’ll switch over to viewing the node in the Element panels of devTools.
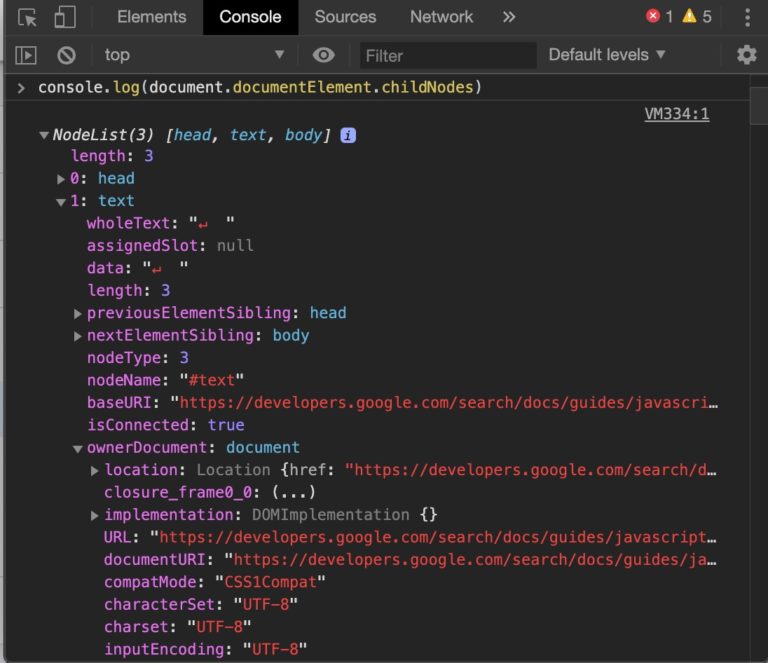
You can repeat this process over and over, exploring all the branches and loot crates to be had because you’ve learned how to traverse the DOM!
If this scary-looking stuff is a bit more than you bargained for, that’s OK.
It isn’t really meant to be human fodder.
This is the skeleton and the squishy bits that make up a page.
It’s the content, structure, and styling and how they are related and apply to each other.
Light vs. Shadow
If you followed along with the steps to inspect the DOM, you saw the “Light DOM.”
It’s only referred to as the Light DOM when there’s a shadow involved.
A shadow DOM is a whole new DOM tree that is attached to an element, its shadow host, in the Light DOM.
That’s right – just as one light can cast many shadows, one Light DOM can involve multiple Shadow DOMs.
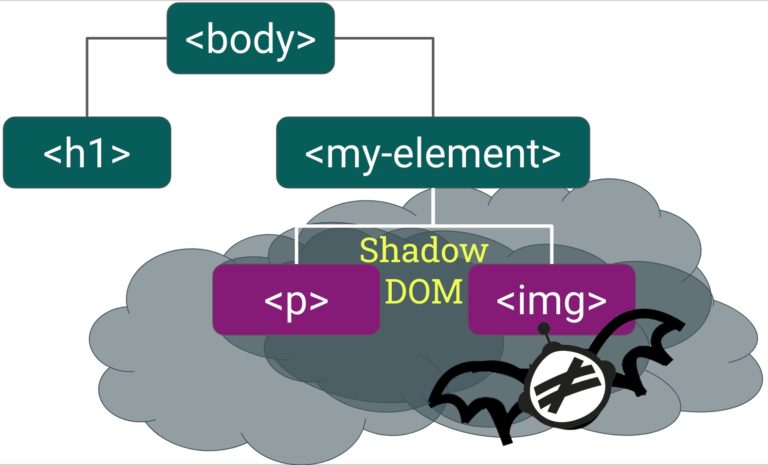
How Is the Shadow DOM Used?
Shadows DOMs are really helpful.
Many browsers use them for native widgets, like <select> or <video>.
(Yes, there’s a shadow DOM lurking behind these elements!)
Let’s pretend we have an ecommerce site and we want to build a category page.
We could mark up the page like this:
<div class="col">
<h2><a href="thing_1.html" class="title">Thing 1</a></h2>
<img src="/thing_1.jpg" alt="lovely green thing" class="responsive">
<p>Thing 1 is like Thing 2 but green</p>
<a href="thing_1.html" class="buttonstyle">Details</a>
<button onclick="addtocart('thing1')" class="buttonstyle">Buy Now</button>
</div>
<div class="col">
<h2><a href="thing_2.html" class="title">Thing 2</a></h2>
<img src="/thing_2.jpg" alt="lovely red thing">
<p>Thing 2 is like Thing 1 but red</p>
<a href="thing_2.html" class="buttonstyle">Details</a>
<button onclick="addtocart('thing2')" class="buttonstyle">Buy Now</button>
</div>
We’d repeat this structure over and over again until we’d listed all our products.
If we hardcoded this solution, we would have to update it every time our inventory changed.
In an effort to save our sanity, we could turn to the shadow DOM, embrace the dark arts of Web Components, and create a custom element like this:
<div class="col">
<product-listing url="thing_1.html" sku="thing1"><span slot="title">Thing 1</span>
<span slot="image"><img src="/thing_1.jpg" alt="lovely green thing"></span>
<span slot="desc"><p>Thing 1 is like Thing 2 but green</p></span>
</product-listing>
</div>
<div class="col">
<product-listing url="thing_2.html" sku="thing2">
<span slot="title">Thing 2</span>
<span slot="image"><img src="/thing_2.jpg" alt="lovely red thing" /></span>
<span slot="desc"><p>Thing 2 is like Thing 1 but red</p></span>
</product-listing>
</div>
Our custom element allows us to simplify the flow.
We can reuse it on any page.
Simply summon in the web-component and reap the rewards of a reusable, component-based architecture.
Here’s what the component and its Shadow DOM familiar looks like in devTools.
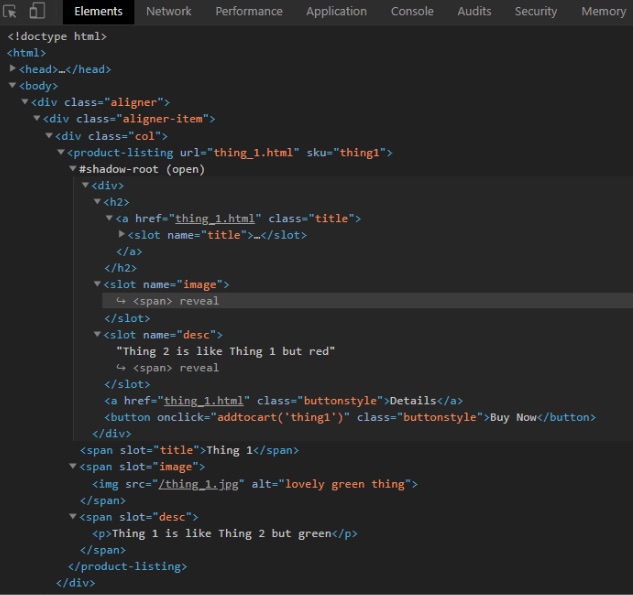
Frameworks like React, Vuejs, and Angular also have their own reusable components.
These JavaScript frameworks and libraries don’t use the shadow DOM instead of manipulating the light DOM directly.
Despite the initial similarities, aiming at different things.
The JavaScript frameworks are more concerned with keeping data and state in sync, web components are not.
If you’re using a JS framework and wanted a shadow DOM of your own: fear not!
You can use web components with all of these, for example, Angular Elements.
Adding to this army of darkness are LitElement and lit-HTML from Polymer Project as well as the collection of ready-built web components from https://www.webcomponents.org/.
The relevancy of the Shadow DOM is going to be more popular soon.
Browser Support
Web components, and specifically custom elements enjoy widespread browser support these days, with both Chrome and Firefox supporting them since 2018 (May for chrome, October for Firefox), with support from all the major browsers except Internet Explorer & Edge.
Internet Explorer is stuck at 11, but Edge is changing to be Chromium-based (Chromium is the open-source version from which Chrome is built) and with that, it too will support custom elements.
The lack of support from the Microsoft browsers has been a sticking point to date but with Edge’s imminent shift to chromium, this roadblock is about to be cleared.
Until then, polyfill can be used to create compatibility.
Googlebot & the Shadow DOM
As SEOs, we ultimately care about how Googlebot (and other savvy search engines) can retrieve, render, and ultimately rank content.
Let’s imagine our page source contains the following HTML.
<ttb-test-component text="This is passed through attributes."></ttb-test-component>
If we inspect the element with devTools, we’ll see:

See that #shadow-root (open) bit?
That’s the boundary of the Light/Shadow DOMs.
It’s been “flattened” meaning that the boundary is pierced.
All the shadow DOM trees are squashed into the light DOM tree resulting in a single DOM.
Luckily for SEOs, this is exactly how Google handles Shadow DOMs as well.
Here’s the same component rendered in the Mobile-Friendly Testing Tool.
![]()
Our content exists!
The difference between Google’s render and our own in-browser experience is the absence of the boundary between light and shadow DOM.
Rejoice! It all works!
We can pack up and go home!
Well… Not quite…
Bing & the Shadow DOM
Google is probably your main focus, but let’s not forget our friends over at Bing.
Despite the smaller market share, Bing can still be a useful source of traffic for many sites, and currently, the outlook isn’t quite so rosy for web-components.
Bing currently doesn’t seem able to render custom elements like the above one – even if the polyfills are in place so they work in Edge. (Another case of “It works on my machine” being the equivalent of the “I’ll be right back” horror trope).
Bing would see our component like this:
<ttb-test-component text="This is passed through attributes."></ttb-test-component>
That’s not content. That’s nothing.
Oh, bother.
<slot> to the Rescue!
So, is that curtains for web-components in Bing?
Nope, thanks to the <slot> element!
The slot element can cross the boundary between light and shadow DOM and has the added benefit of being present in the Light DOM for services that don’t flatten the DOM.
Let’s conjure up a component:
<ttb-test-component-slotted><strong>This is the stuff in the slot</strong></ttb-test-component-slotted>
Next, we’ll declare the component:
<script>
class TtbTestComponentSlotted extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'This is the stuff in JS. <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('ttb-test-component-slotted', TtbTestComponentSlotted);
</script>
While Googlebot would get the full thing:
![]()
Bing would at least get the slotted content:
![]()
So if Bing is important, make sure your critical content is passed in slots.
<slot> Alternatives: Moving or Cloning the Node
Disclaimer: Node manipulation is above the author’s spellcasting ability, but she’s certainly going to try to provide a thorough resource.
If slotted content isn’t your cauldron of tea, a skilled engineer can assist with moving or cloning node.
A node basically has two connecting points in the DOM tree: the component instance (visible as the web component as an HTML tag in the document’s tree) and the shadow root.
Each node can only have a single parent, but this can be to our advantage.
We can move nodes around in a tree and append each child node to its respective component or shadow root.
In moving the node and ultimately changing its paternity, we can shift an element from Light DOM to Shadow DOM or visa versa.
If you’re ready to level up into DOM Enlightenment, Cody Lindley is an excellent resource for learning about the nodular pocket dimensions.
Our favorite internet fairy Martin Splitt has even crafted a bit of node moving code for SEOs to inspect.
Bingbot Upgrade Coming Soon
Bing announced that their web crawler will be going evergreen.
Similar to Google’s May 2019 announcement, they plan to render pages with their latest version of the Edge browser, stating that the switch to a chromium-base may include support for the shadow DOM.
Whether that means flattening in the same style as Google’s Web Rendering Service, only time will tell.
Testing Your Shadow DOM
If you’re looking to test your content for Google, you have a bounty of options.
The URL inspection tool in search console, Mobile-Friendly Test, and Rich Results Test all return the same rendered HTML created by Google’s Web Rendering Service.
These are great for confirming that they can reliably pick up any shadow DOM content for indexing.
Be sure to copy and paste out the rendered HTML created by these tools for a more thorough inspection.
It provides a thorough look into what content is available as opposed to the superficial screenshots we can be tempted to lean on.
If you’re looking for a third-party tool, the majority don’t flatten the DOM as Googlebot does.
If you use web crawler services or software, and have links in a web component, like say a navigation bar web component, it’s likely that these links would go missed by these services and software.
Tame the Bot’s Fetch and Render is a notable exception that flattens the DOM.
Conclusion
If this all seems a bit convoluted and complex, well… you’re not wrong.
But before you launch into a litany remember our goal is to be aware wolves, not swear wolves.
What we do in the Shadow DOM matters to our site’s visibility.
A basic understanding of the unseen-until-it-isn’t Shadow DOM can help you better communicate with developers and achieve your shared goals.
My undying thanks again to frontend developer and Google Webmaster Central Gold Product Expert Dave Smart for sharing his expertise in the dark arts of necromicode.
Thanks for reading and I look forward to our next shared adventure of learning in public.
|-----------|
| DON'T READ|
| THE LATIN |
| & ALWAY |
| COMMENT |
| YOUR CODE |
|-----------|
(\__/) ||
(•ㅅ•) ||
/ づ
More Resources:
- The SEO’s Introduction to Rendering
- Understanding JavaScript Fundamentals: Your Cheat Sheet
- 4 Advanced Ways to Use Chrome DevTools for Technical SEO Audits
Image Credits
Featured Image: Pixabay / Modified by author, March 2020
All screenshots taken by author, March 2020
