

Site pagination is a wily shapeshifter. It’s used in contexts ranging from displaying items on category pages, to article archives, to gallery slideshows and forum threads.
For SEO professionals, it isn’t a question of if you’ll have to deal with pagination, it’s a question of when.
At a certain point of growth, websites need to split content across a series of component pages for user experience (UX).
Our job is to help search engines crawl and understand the relationship between these URLs so they index the most relevant page.
Over time, the SEO best practices of pagination handling have evolved. Along the way, many myths have presented themselves as facts. But no longer.
This article will:
- Debunk the myths around how pagination hurts SEO.
- Present the optimal way to manage pagination.
- Review misunderstood or subpar methods of pagination handling.
- Investigate how to track the KPI impact of pagination.
How Pagination Can Hurt SEO
You’ve probably read that pagination is bad for SEO.
However, in most cases, this is due to a lack of correct pagination handling, rather than the existence of pagination itself.
Let’s look at the supposed evils of pagination and how to overcome the SEO issues it could cause.
Pagination Causes Duplicate Content
Correct if pagination has been improperly implemented, such as having both a “View All” page and paginated pages without a correct rel=canonical or if you have created a page=1 in addition to your root page.
Incorrect when you have SEO friendly pagination. Even if your H1 and meta tags are the same, the actual page content differs. So it’s not duplication.
Yep, that’s fine. It’s useful to get feedback on duplicate titles & descriptions if you accidentally use them on totally separate pages, but for paginated series, it’s kinda normal & expected to use the same.
— 🍌 John 🍌 (@JohnMu) March 13, 2018
Pagination Creates Thin Content
Correct if you have split an article or photo gallery across multiple pages (in order to drive ad revenue by increasing pageviews), leaving too little content on each page.
Incorrect when you put the desires of the user to easily consume your content above that of banner ad revenues or artificially inflated pageviews. Put a UX-friendly amount of content on each page.
Pagination Dilutes Ranking Signals
Correct. Pagination causes internal link equity and other ranking signals, such as backlinks and social shares, to be split across pages.
But can be minimized by using pagination only in cases where a single-page content approach would cause poor user experience (for example, ecommerce category pages). And on such pages, adding as many items as possible, without slowing down the page to a noticeable level, to reduce the number of paginated pages.
Pagination Uses Crawl Budget
Correct if you’re allowing Google to crawl paginated pages. And there are some instances where you would want to use that budget.
For example, for Googlebot to travel through paginated URLs to reach deeper content pages.
Often incorrect when you set Google Search Console pagination parameter handling to “Do not crawl” or set a robots.txt disallow, in the case where you wish to conserve your crawl budget for more important pages.
Managing Pagination According to SEO Best Practices
Use Crawlable Anchor Links

For search engines to efficiently crawl paginated pages, the site must have anchor links with href attributes to these paginated URLs.
Be sure your site uses <a href=”your-paginated-url-here”> for internal linking to paginated pages. Don’t loaded paginated anchor links or href attribute via JavaScript.
Additionally, you should indicate the relationship between component URLs in a paginated series with rel=”next” and rel=”prev” attributes.
Yes, even after Google’s infamous Tweet that they no longer use these link attributes at all.
Spring cleaning!
As we evaluated our indexing signals, we decided to retire rel=prev/next.
Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what’s best for *your* users! #springiscoming pic.twitter.com/hCODPoKgKp— Google Webmasters (@googlewmc) March 21, 2019
Shortly afterward, Ilya Grigorik clarified that rel=“next” / ”prev” can still be valuable.
no, use pagination. let me reframe it.. Googlebot is smart enough to find your next page by looking at the links on the page, we don’t need an explicit “prev, next” signal. and yes, there are other great reasons (e.g. a11y) for why you may want or need to add those still.
— Ilya Grigorik (@igrigorik) March 22, 2019
Google is not the only search engine in town. Here is Bing’s take on the issue.
We’re using rel prev/next (like most markup) as hints for page discovery and site structure understanding. At this point we’re not merging pages together in the index based on these and we’re not using prev/next in the ranking model. https://t.co/ZwbSZkn3Jf
— Frédéric Dubut (@CoperniX) March 21, 2019
Complement the rel=”next” / “prev” with a self-referencing rel=”canonical” link. So /category?page=4 should rel=”canonical” to /category?page=4.
This is appropriate as pagination changes the page content and so is the master copy of that page.
If the URL has additional parameters, include these in the rel=”prev” / “next” links, but don’t include them in the rel=”canonical”.
For example:
<link rel="next" href="https://www.example.com/category?page=2&order=newest" />
<link rel="canonical" href="https://www.example.com/category?page=2" />
Doing so will indicate a clear relationship between the pages and prevent the potential of duplicate content.
Common errors to avoid:
- Placing the link attributes in the
<body>content. They’re only supported by search engines within the<head>section of your HTML. - Adding a rel=”prev” link to the first page (a.k.a. the root page) in the series or a rel=”next” link to the last. For all other pages in the chain, both link attributes should be present.
- Beware of your root page canonical URL. Chances are on ?page=2, rel=prev should link to the canonical, not a ?page=1.
The <head> code of a four-page series will look something like this:
- One pagination tag on the root page, pointing to the next page in series.
<link rel="next" href="https://www.example.com/category?page=2″><link rel="canonical" href="https://www.example.com/category">
- Two pagination tags on page 2.
<link rel="prev" href="https://www.example.com/category"><link rel="next" href="https://www.example.com/category?page=3″><link rel="canonical" href="https://www.example.com/category?page=2">
- Two pagination tags on page 3.
<link rel="prev" href="https://www.example.com/category?page=2″><link rel="next" href="https://www.example.com/category?page=4″><link rel="canonical" href="https://www.example.com/category?page=3">
- One pagination tag on page 4, the last page in the paginated series.
<link rel="prev" href="https://www.example.com/category?page=3"><link rel="canonical" href="https://www.example.com/category?page=4">
Modify Paginated Pages On-Page Elements
John Mueller commented, “We don’t treat pagination differently. We treat them as normal pages.”
Meaning paginated pages are not recognized by Google as a series of pages consolidated into one piece of content as they previously advised. Every paginated page is eligible to compete against the root page for ranking.
To encourage Google to return the root page in the SERPs and prevent “Duplicate meta descriptions” or “Duplicate title tags” warnings in Google Search Console, make an easy modification to your code.
If the root page has the formula:

The successive paginated pages could have the formula:

These paginated URL page titles and meta description are purposefully suboptimal to dissuade Google from displaying these results, rather than the root page.
If even with such modifications, paginated pages are ranking in the SERPs, try other traditional on-page SEO tactics such as:
- De-optimize paginated page H1 tags.
- Add useful on-page text to the root page, but not paginated pages.
- Add a category image with an optimized file name and alt tag to the root page, but not paginated pages.
Don’t Include Paginated Pages in XML Sitemaps
While paginated URLs are technically indexable, they aren’t an SEO priority to spend crawl budget on.
As such, they don’t belong in your XML sitemap.
Handle Pagination Parameters in Google Search Console
If you have a choice, run pagination via a parameter rather than a static URL. For example:
example.com/category?page=2 over example.com/category/page-2
While there is no advantage using one over the other for ranking or crawling purposes, research has shown that Googlebot seems to guess URL patterns based on dynamic URLs. Thus, increasing the likelihood of swift discovery.
On the downside, it can potentially cause crawling traps if the site renders empty pages for guesses that aren’t part of the current paginated series.
For example, say a series contains four pages.
URLs with a content stop at www.example.com/category?page=4
If Google guesses www.example.com/category?page=7 and a live, but empty, page is loaded, the bot wastes crawl budget and potentially get lost in an infinite number of pages.
Make sure a 404 HTTP status code is sent for any paginated pages which are not part of the current series.
Another advantage of the parameter approach is the ability to configure the parameter in Google Search Console to “Paginates” and at any time change the signal to Google to crawl “Every URL” or “No URLs”, based on how you wish to use your crawl budget. No developer needed!
Don’t ever map paginated page content to fragment identifiers (#) as it is not crawlable or indexable, and as such not search engine friendly.
Misunderstood, Outdated or Plain Wrong SEO Solutions to Paginated Content
Do Nothing

Google believes Googlebot is smart enough to find the next page through links, so doesn’t need any explicit signal.
The message to SEO’s is essentially, handle pagination by doing nothing.
While there is a core of truth to this statement, by doing nothing you’re gambling with your SEO.
Many sites have seen Google select a paginated page to rank over the root page for a search query.
There’s always value in giving clear guidance to crawlers how you want them to index and display your content.
Canonicalize to a View All Page
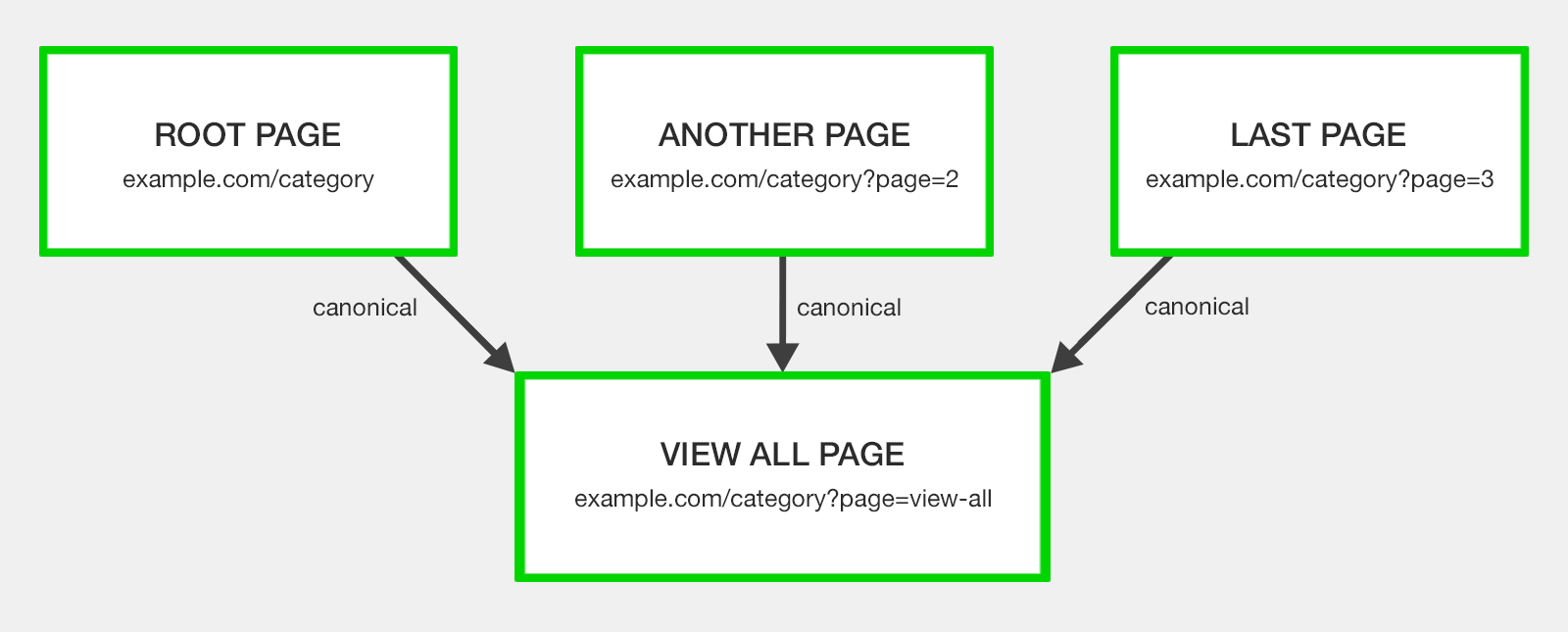
The View All page was ideated to contain all the component page content on a single URL.
With all paginated pages having a rel=”canonical” to the View All page to consolidate ranking signals.
The argument here is that searchers prefer to view a whole article or list of categories items on a single page, as long as it’s fast loading and easy to navigate.
The concept was if your paginated series has an alternative View All version that offers the better user experience, search engines will favor this page for inclusion in the search results as opposed to a relevant segment page of the pagination chain.
Which raises the question – why do you have paginated pages in the first place?
Let’s make this simple.
If you can provide your content on a single URL while offering a good user experience, there is no need for pagination or a View All version.
If you can’t, for example, a category page with thousands of products would be ridiculously large and take too long to load, then paginate. View All is not the best option as it would not offer a good user experience.
Using both rel=”next” / “prev” and a View All version gives no clear mandate to search engines and will result in confused crawlers.
Don’t do it.
Canonicalize to the First Page

A common mistake is to point the rel=”canonical” from all paginated results to the root page of the series.
Some ill-informed SEO people suggest this as a way to consolidate authority across the set of pages to the root page, but this is misinformed.
Incorrect canonicalization to the root page runs the risk of misdirecting search engines into thinking you have only a single page of results.
Googlebot then won’t index pages that appear further along the chain, nor acknowledge the signals to the content linked from those pages.
You don’t want your detailed content pages dropping out of the index because of poor pagination handling.
Each page within a paginated series should have a self-referencing canonical, unless you use a View All page.
Use the rel=canonical incorrectly and chances are Googlebot will just ignore your signal.
Noindex Paginated Pages

A classic method to solve pagination issues was a robots noindex tag to prevent paginated content from being indexed by search engines.
Relying solely on the noindex tag for pagination handling will result in any ranking signals from component pages being disregarded.
However, the larger issue with this method is that a long-term noindex on a page will eventually lead Google to nofollow the links on that page.
This could cause content linked from the paginated pages to be removed from the index.
Pagination & Infinite Scrolling or Load More

A newer form of pagination handling is by:
- Infinite scroll, where content is pre-fetched and added directly to the user’s current page as they scroll down.
- Load more, where content is rendered upon the click of a ‘view more’ button.
These approaches are appreciated by users, but Googlebot? Not so much.
Googlebot doesn’t emulate behavior like scrolling to the bottom of a page or clicking to load more. Meaning without help, search engines can’t effectively crawl all of your content.
To be SEO-friendly, convert your infinite scroll or load more page to an equivalent paginated series, based on crawlable anchor links with href attributes, that is accessible even with JavaScript disabled.
As the user scrolls or clicks, use JavaScript to adapt the URL in the address bar to the component paginated page.
Additionally, implement a pushState for any user action that resembles a click or actively turning a page. You can check out this functionality in the demo created by John Mueller.
Essentially, you’re still implementing the SEO best practice recommended above, you are just adding additional user experience functionality on top.
Discourage or Block Pagination Crawling
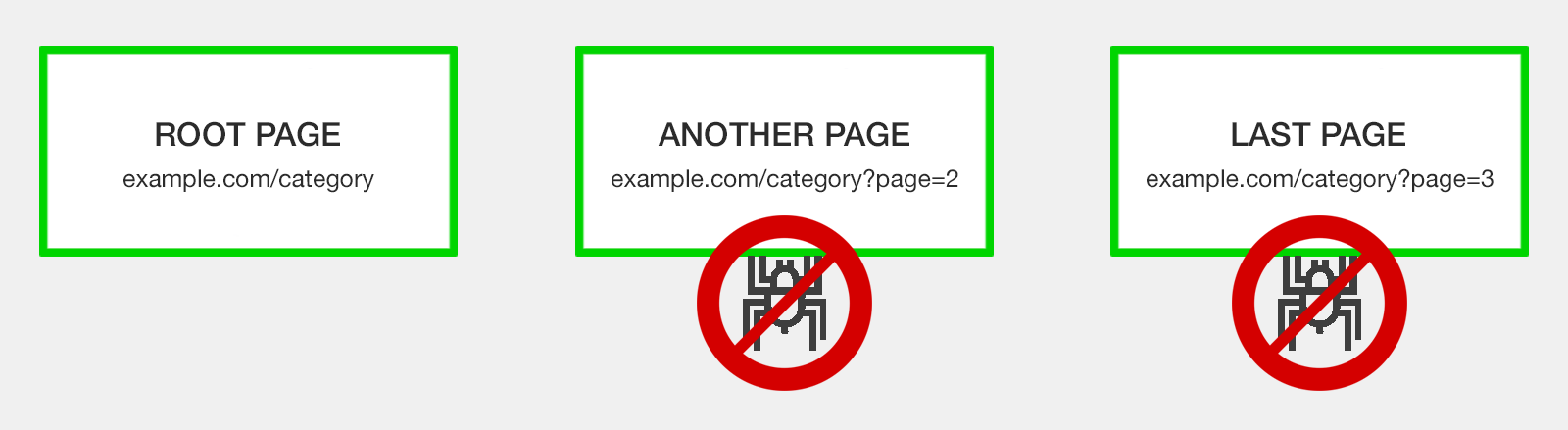
Some SEO pros recommend avoiding the issue of pagination handling altogether by simply blocking Google from crawling paginated URLs.
In such a case, you would want to have well-optimized XML sitemaps to ensure pages linked via pagination have a chance to be indexed.
There are three ways to block crawlers:
- The messy way: Add nofollow to all links that point towards paginated pages.
- The cleaner way: Use a robots.txt disallow.
- The no dev needed way: Set paginated page parameter to “Paginates” and for Google to crawl “No URLs” in Google Search Console.
By using one of these methods to discourage search engines from crawling paginated URLs you:
- Stop search engines from recognizing ranking signals of paginated pages.
- Prevent the passing of internal link equity from paginated pages down to the destination content pages.
- Hinder Google’s ability to discover your destination content pages.
The obvious upside is that you save on crawl budget.
There is no clear right or wrong here. You need to decide what is the priority for your website.
Personally, if I were to prioritize crawl budget, I would do so by using pagination handling in Google Search Console as it has the optimum flexibility to change your mind.
Tracking the KPI Impact of Pagination
So now you know what to do, how do you track the effect of optimization pagination handling?
Firstly, gather benchmark data to understand how your current pagination handing is impacting SEO.
Sources for KPIs can include:
- Server log files for the number of paginated page crawls.
- Site: search operator (for example site:example.com inurl:page) to understand how many paginated pages Google has indexed.
- Google Search Console Search Analytics Report filtered by pages containing pagination to understand the number of impressions.
- Google Analytics landing page report filtered by paginated URLs to understand on-site behavior.
If you see an issue getting search engines to crawl your site pagination to reach your content, you may want to change the pagination links.
Once you have launched your best practice pagination handling, revisit these data sources to measure the success of your efforts.
Image Credits
Featured Image: Paulo Bobita
In-Post Images/screenshots: Created/taken by author
