

For roughly a decade, the SEO industry has been consistently moving further away from discussions about the internal workings of the search engines, starting around the time of the first Panda update.
This decision to focus on more strategic and long-term SEO approaches has been a positive one, overall.
Marketing strategies built entirely on the whims of a search engine aren’t built to stand the test of time.
However, there’s no denying the value that came from understanding and predicting how search engines would react to certain kinds of tweaks to the HTML or to the backlink profile in the early days of SEO.
Most of us have assumed that those days ended when Google embraced machine learning.
Now that Google’s own engineers don’t even necessarily understand the rules their algorithm has written for itself, the idea that we could reverse engineer what is happening inside has been all that abandoned.
But there’s an exciting development around the fringes of the SEO community, and with many calling 2018 the year when AI and machine learning hit the mainstream for so many industries, those developments are likely to hit hard this year.
I’m talking about using machine learning to understand and comprehend machine learning.
I’m talking about cracking open Google’s black box and peeking inside.
I’m talking about a reincarnation of the early days of SEO.
Following the Rules
In the early days of Google, its search engine was simplistic.
Its competitive advantage over then-leading search engine AltaVista was its PageRank algorithm.
As Google matured and captured a majority of market share over AltaVista, it became the primary target for web spammers seeking to find an easy way to rank their websites.
To protect the quality of their search results, Google’s search team began to write rules to filter out this spam.
This rules-based approach was both direct and to the point.
If a website was doing something to subvert its algorithms, a rule was written to make an exception for whatever was done to subvert it.
Google’s spam team worked tirelessly to close up any and all loopholes in its search algorithms.
Most of these rules were first derivatives of their inputs – in other words, it was easy to guess what the rules did.

Subsequently, many search engine optimization (SEO) tools sprung up overnight, attempting to enumerate these different types of rules.
Some tools called themselves website graders, a master tool that would, with one click of a button, scan a website to see if any of the enumerated rules were triggered.
Here are some examples of what these simple rules would look like:
- Meta title/description too long (or too short)
- Not enough content
- Contains certain “bad keywords”
- H1 tags missing
All of these types of rules were simple.
Website changes could be made.
A positive or negative movement could be observed.
Life was easy.
Google Gets More Complex
Over time, Google began to get really complex, often creating rules that depended on other rules.
Many of these rules were at least second-order derivatives of their inputs.
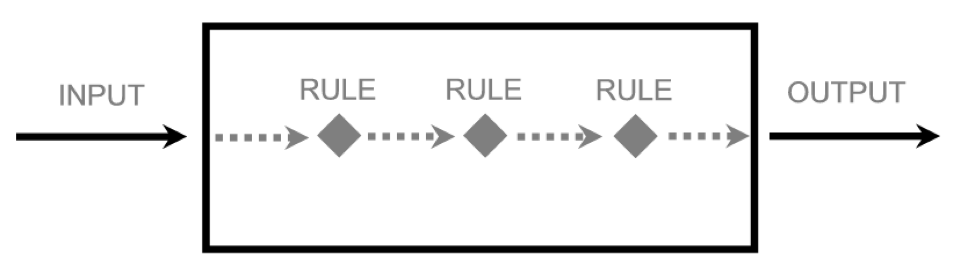
Because of this, Google’s black box became more and more convoluted.
No longer could a simple change be made, and an output observed.
Which rule caused the change? You simply could not know.
These rules became extremely hard to include in the aforementioned website grader tools.
Some tools just left these out, and other tools attempted to oversimplify the relationship inside that black box.
The SEO world stopped trying to look inside the black box and began to put the majority of its focus on the output.
Looking at artifacts like an archeologist, SEO pros would try to piece together what might have happened.
The First Attempt at Cracking the Black Box
With the growing complexity of Google’s search engine and an obsession with measuring the output of this ever-growing black box, a new tool arrived on the scene: the rank tracker.
The idea behind rank trackers was simple: keep a measurement of the order of search results over time, and attempt to piece together a cause and effect relationship with website changes.
These rank trackers worked brilliantly to cover up some of the complexity that was going on inside Google’s black box.
An example of an early rank tracker on the scene was SEMrush.
SEMRush would crawl Google’s search results, and then let users search the results by URL or keyword.
SEMrush started out with the focus of “making online competition fair and transparent, with equal opportunities for everyone.”
Rank trackers became the primary way to measure the results of optimizing a website.
Hundreds of rank trackers sprang up over the ensuing years, all essentially providing the same service, but with different interfaces.
As Google’s algorithmic rules began to grow even more complex, the SEO industry needed more than just simple website audits.
Teams needed the raw data to view in different pivot tables, to compare different relationships.
This worked for some time to essentially cover up the complexity of the situation.
This spawned a new level of rank trackers: enterprise rank trackers.
Essentially rank trackers on steroids, these souped-up tools often included more integration with things like content marketing (writing content), and other website grader features.
With enterprise rank trackers, SEO professionals could look at competitor movement and try to copy (without actually understanding the mechanics).
Similar to scientists in the early days of DNA that would observe certain RNA strands were present when certain things occurred.
Simple cause and effect.
Rank Tracking Runs Out of Track
Among its many shortfalls (lack of transparency into the black box being a major one), rank trackers, enterprise or not, had a glaring weakness: they depended on one important principle holding true, namely that Search Engine Optimization is a rules-based paradigm.
In 2013, Google’s move towards Artificial Intelligence (A.I.) caused a shift from a rule-based approach to one that was observation-based.
Instead of writing a list of rules to operate its search engine, it started with a rules-based approach but then turned to classification (enhanced by deep learning) to determine the amount of importance of those rules.
The raw data approach no longer worked anymore because the relationships (relative importance of constituent elements) between algorithms were now dynamic.

Rank trackers worked on the premise that users could observe a ranking shift, narrow down a shortlist of what potential changes caused that shift across many keywords, and then apply that knowledge to various markets.
With machine learning, Google broke that model.
Now, each search result had a unique mixture of algorithms.
Rank trackers relied on observing ranking shifts across many keywords to gather clues.
The end result was that the rank trackers became more of, passive, lagging indicators, something that was useful in post-mortem situations, but limited in trying to predict what was going to happen next.
SEO Industry Consolidates
By 2014, the importance of rank trackers and a number of other bold shifts in Google’s data sharing strategy caused many agencies and tools to consolidate.
During this retraction in the SEO industry, some agencies took the opportunity to reposition themselves – to focus on content instead of backlinks, or some other new area of SEO.
Even major players announced they were walking away from SEO altogether.
For a while, Google seemed to be winning. It had successfully built a big enough barrier to entry – an extremely complex black box – that current technologies simply couldn’t crack with top-down approaches.
Peeking Inside the Modern Algorithm
By late 2014, the death knells were already ringing in the SEO industry for its more technically oriented wing.
It was clear that compliant HTML code and sound architecture were still important, but most in the industry were by now speaking in broader terms about marketing strategy and about Google’s business motivations.
There was a divide in the industry, with many aspects of technical SEO, unfortunately, being adopted by spammers, thus labeled spam by the rest of the industry.
But, the beginnings of something new was also emerging.
Scott Stouffer published a post at Search Engine Journal arguing that the future of technical SEO was in emulating and recreating the search engine from the ground up.
Instead of explaining rankings and changes in traffic retroactively, he argued that future SEO professionals would be using statistical inference to make predictions about how Google and other search engines would react.
Essentially, they would build a machine-learning model that would make predictions about how sites would get ranked, then test those predictions against reality, and continually feed the new model data so that it would make increasingly accurate predictions.
Such a machine-learning model of a machine learning ranking algorithm would essentially act like a reverse-engineered Google.
But, since this model would be designed to tell you what rules it was using to make its predictions, it would allow you to essentially sneak a second-hand peak at Google’s inner workings.
Stouffer ultimately co-founded a search engine model with the goal of doing precisely that, and now that machine-learning algorithms are widely available, could this exactly be where the industry is headed?
How effective can models like this really be, though? Can you build your own? Will it be useful? Is anybody else doing this?
Yes, Using AI to “Steal” AI Does Work
In September of 2016, Andy Greenberg published an article in Wired called “How to Steal an AI.”
In it, he discussed how a team of computer scientists at Cornell Tech was able to reverse engineer machine-learning trained AIs, simply by sending queries to that AI and analyzing the responses.
It only took a few thousand queries, sometimes even just a few hundred, before the new AI was capable of making nearly identical predictions.
The paper explicitly mentions that this technique could be used t0o “steal” algorithms like those of Amazon, Microsoft, and yes, Google.
It even argues that it could be used to sneak spam and malware through machine-learning based security systems.
One disturbing paper even demonstrates that it’s possible to reproduce the faces that facial recognition software was trained on, and even more shockingly, that they could do it faster with their “stolen” version of the AI than with the original.
Another experiment demonstrated that it was possible to “trick” a visual recognition algorithm into seeing something that wasn’t there, even using a “copy” that was only 80 percent accurate.
Put together, all of this means that yes, it’s entirely plausible that you could make a “copy” of Google’s search engine and use it to reconstruct the rules it uses to rank sites in its search results.
If built correctly, your copy might actually give you more enlightening information about those rules than having a copy of the original would.
Guiding Principles Behind Building a Search Engine Model
So, if building a search engine model based on existing search engine results were possible, where would you even start with a project like this?
A complete guide would be impossible within this blog post, but I want to give you some guiding principles to work with.
The basic process is as follows and has been made relatively simple by new platforms that are relatively widely available:
- Pass in a batch of data (current rankings).
- Calculate the difference between the output generated by the search engine model and the actual truth (i.e., the loss).
- Calculate the derivatives of the model’s parameters with respect to their impact on the loss.
- Optimize the parameters in a way that will decrease the loss.
The advantage of a bottom-up approach is readily apparent: transparency.

Now that you have a simple model that behaves like the real thing, you can put it to use.
Instead of measuring the output of a black box, start by measuring the individual rule outputs inside the box.
For example, with a search engine model, teams can measure the differences between their site and their competitor sites, for specific algorithms.
Remember, these are the things that SEO practitioners used to do, back when Google was simpler.
The closer your outputs are to the inputs in your data, the more likely to find a cause and effect.
By measuring each point along the input-output path, SEO pros using a bottom-up approach (e.g. search engine model) can see exactly which points change.
Keep the following in mind:
- Unless you already specialize in machine learning, don’t attempt to build a machine-learning platform from scratch. You don’t have to. Machine learning is now widely available for rent. The primary platforms are Amazon, Azure, IBM, and yes, Google, each with their own pros and cons.
- The accuracy of your model will depend primarily on the accuracy and diversity of your inputs, which will need to be highly specific. It’s a misconception that you can just plug a piece of content into a machine learning algorithm and assign a score to each one, then let the AI loose. Highly specific, measurable quantities will need to be identified.
- We are long past the point where decision should be made entirely based on whether they will lead to rankings in the short term. Every decision must be justifiable as part of a cohesive marketing strategy with the user front and center.
- You will likely get the most accurate results if you aim for categorical predictions. That is, predicting the position of a URL in search results is a fool’s errand, but predicting whether one URL will perform better than another is much more likely to lead to accurate results.
- Your confidence intervals are everything. If you are basing decisions on predictions with low confidence, you are putting too much faith in your model.
Final Thoughts
With machine learning technologies becoming widely available, a central assumption of modern SEO is in question. Perhaps we can reverse engineer the algorithm after all.
Should we?
I’m of two minds about this.
I believe in making data-driven decisions. I’m a strong believer in the continuing value of technical SEO. I think it’s a mistake to separate computer and data science from SEO, and “feel good” notions about “just creating good content” have never been enough on their own to justify calling yourself a professional SEO.
At the same time, using approaches like this does leave us with a temptation to abuse search engine algorithms, to “sneak” subpar content into the search results that may not last or, worse, could do long-lasting damage to your brand.
Personally, I feel tools like this are valuable, but they need to be used carefully.
Nostalgic as all of us are for the good old days of early SEO, nobody wants the spam back, some of us remember what it felt like to get burned, and most of us have learned there’s a lot more to a solid long-term SEO strategy than understanding what will get you rankings today.
Let’s use these tools to move forward, not backward.
More SEO and Machine Learning Resources:
- A Beginner’s Guide to SEO in a Machine Learning World
- How Machine Learning Is Changing SEO & How to Adapt
- Why Machine Learning Is Key to the Search Marketing of Tomorrow
Image Credits
In-Post Photo # 1: Internet Archive
In-Post Photos # 2, 3 & 5: Created by Pratik Dholakiya, January 2018
In-Post Photo # 4: Screenshot taken by Pratik Dholakiya, January 2018
