

In May 2018, Matt Southern published an article on Search Engine Journal about ranking fluctuations for new content. John Mueller confirmed that new content bounce around in the search results before finally settling down. What was left unspoken was why new content fluctuates. If Google is operating on a continuous update, why is there fluctuation?
I saw a post on a private Facebook Group where someone asked why new pages fluctuated.
Possible reasons that were offered were:
- User metrics
- A temporary PageRank score that is later updated
- Clicks on the listing to test how relevant the page was
Those are great suggestions for why rankings fluctuate for new pages.
There is a patent filed by Google that’s titled, Modifying Search Result Ranking Based on Implicit User Feedback.
It describes monitoring clicks to a web page as well as when a web page is not clicked in the search engine results pages (SERPs), in order to understand if a web page appeals to users. It also discusses using how long a user stays on a site before returning.
Here’s what it says:
“…identifies user selections (clicks) of individual document results and also identifies when the user returns to the results page, thus indicating the amount of time the user spent viewing the selected document result.”
That may contribute to ranking fluctuations. But it’s not a paper about testing new web pages that are added to Google’s search index.
Most if not all the papers involving CTR are about improving search results and predicting click through rates for advertising.
Google’s Indexing System
I believe that the answer has to do with how Google stores data. Google’s index is continuous since the Caffeine update. The Caffeine update was really about something called Google Instant. In 2010 the software underlying the storage of all of Google’s data was called BigTable and the Google File System was called Colossus.
When talking about indexing, we’re talking about Caffeine and the underlying Percolator system. Here is a Google PDF document detailing how Percolator works and that also discusses the trade-offs between the old Google File System using MapReduce and the new distributed file system that runs computations in parallel.
An important distinction is that Percolator has an overhead that’s 30 times greater than the old system. Thus, as long as Google can keep throwing hardware at it the system can keep on scaling.
Here is what the Google document from 2010 says about that overhead:
“We chose an architecture that scales linearly over many orders of magnitude on commodity machines, but we’ve seen that this costs a significant 30-fold overhead compared to traditional database architectures. …how much is fundamental to distributed storage systems, and how much can be optimized away?”
This is a notable section from the Google document about Percolator:
“Percolator applications are structured as a series of observers; each observer completes a task and creates more work for “downstream” observers by writing to the table.
In our indexing system, a MapReduce loads crawled documents into Percolator by running loader transactions, which trigger the document processor transaction to index the document (parse, extract links, etc.). The document processor transaction triggers further transactions like clustering. The clustering transaction, in turn, triggers transactions to export changed document clusters to the serving system.
Percolator applications consist of very few observers — the Google indexing system has roughly 10 observers. Each observer is explicitly constructed in the main() of the worker binary, so it is clear what observers are active.
…at most one observer’s transaction will commit for each change of an observed column. The converse is not true, however: multiple writes to an observed column may cause the corresponding observer to be invoked only once. We call this feature message collapsing, since it helps avoid computation by amortizing the cost of responding to many notifications. For example, it is sufficient for http://google.com to be reprocessed periodically rather than every time we discover a new link pointing to it.“
That’s kind of interesting, isn’t it? It’s talking about a periodic reprocessing rather than processing a page or domain every time a link is discovered.
Could that contribute to the latency in ranking changes, where something is updated but a change in ranking shows up later?
Here is another Google document about Google’s storage systems (PDF).
The main points described in that document are:
- Cluster-level structured storage
- Exports a distributed, sparse, sorted-map
- Splits and rebalances data based on size and load
- Asynchronous, eventually-consistent replication
- Uses GFS or Colossus for file storage
Link Graph Algorithms
There are other considerations. I think once you read what I wrote below, you may agree that the reason rankings fluctuate for new content may be because of how Google’s indexing and link ranking system works.
A Plausible Explanation
I say this may be the explanation because while we know as a fact there is a ranking fluctuation, there is no explicit statement of exactly what causes this fluctuation. Thus, we can only do our best to research what can be known and make a plausible explanation armed with that knowledge.
A plausible explanation is better than pure speculation because knowledge of what is possible puts you right in the range of what is actually happening.
How Link Graphs are Generated and Maintained
The link graph is a map of the Internet. Any time a new link is created or a new page page is published, the link graph changes.
According to a Google patent from 2009, a way to efficiently accomplish the link ranking calculation is to divide the link graph into shards. Each shard takes a turn independently updating and recalculating rankings after something changes.
It’s a practical thing, like breaking a problem up into multiple pieces and handing them out to a crowd of people who in turn work on their little piece of the project then return it to you to put it all back together.
This patent describes a system for ranking links between web pages. What it does is to divide the map of all the web pages in the Internet into pieces called shards. These shards represent little pieces of the problem to be solved independently from the rest of the map of the web, which we sometimes refer to as Google’s index.
What is interesting is that all these calculations are performed in parallel. In parallel means at the same time.
Ranking web pages and links at the same time, on a continuous basis, is what Google’s index, known as Google Instant (or Caffeine or Colossus) is all about.
In the paragraph above I have restated in plain English what the patent describes.
Here is what the 2009 patent states:
“A system, comprising:
multiple computer servers programmed to perform operations comprising: dividing a directed graph representing web resources and links into shards, each shard comprising a respective portion of the graph representing multiple web resources and links associated with the multiple web resources; assigning each of the shards to a respective server, including assigning, to each of the respective servers, data describing the links associated with the multiple web resources represented by the portion of the graph corresponding to the shard assigned to the server; and calculating, in parallel, a distance table for each of the web resources in each shard using a nearest seed computation in the server to which the shard was assigned using the data describing the links associated with the multiple web resources.”
Further down the page the patent describes how the web crawler (diagram element #204) crawls the Internet and stores the information in the data centers (diagram element #208). Then the engine responsible for indexing and ranking (diagram element #206) divides the index into shards at which point everything gets ranked on a continuous basis.
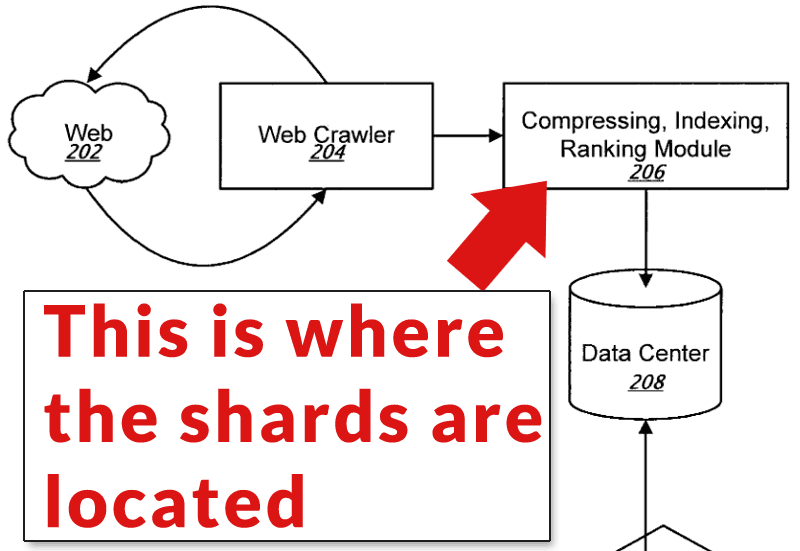 The above paragraph is my plain English translation of what the patent states below:
The above paragraph is my plain English translation of what the patent states below:
“The compression, indexing and ranking module 206 can receive a link graph and a list of the nodes of the link graph to be used as seeds. In addition, the module 206 can divide the link graph into shards and compute nearest seed distances using a large number of shard servers as described above.”
Checkpointing
This is the part of the patent that mentions time. Each shard is independently creating a checkpoint of it’s current state and updating. What’s interesting is how it is described as being asynchronous.
Asynchronous means that the computations are done independently, at random intervals, at any time. That’s the opposite of synchronous, which means that it has to wait for something else to finish before it can begin updating or processing.
So now we have a description of an index system that is updating on a rolling basis. Each shard updates and recalculates it’s section of the Internet according to it’s own time schedule.
The patent states that RAM (memory) is used to store data. The time schedule described in the patent is timed to optimize memory resources.
The above is the plain English version of what is described in the patent.
This is the part that mentions memory and the timing of the re-calculated web page ranking is integrated:
“More specifically, once the leaf table reaches a certain size, it is flushed to a disk file in node identifier sorted order, so that it is sorted the same way the distance table is. If flushing occurs too infrequently or too slowly, the leaf table may grow to a maximum allowed size, causing the server to stop processing incoming updates, so as not to run out of memory. The size of the leaf table is a tradeoff between memory consumption and the amount of data written to disk. The larger the table the higher the chances of updating an existing in-memory leaf entry before it is flushed to disk (leaf disk space).
At predetermined time intervals, or at times of low activity, or after many changes have accumulated, each shard server stores an incremental checkpoint of the distance table and of the leaf table on a reliable data store, e.g., as a distance table increment file and a leaf table increment file on a GFS. The leaf table may be flushed at other times as well.”
Now here is the part of the patent where time is again mentioned in terms of how the updated web page rankings are folded into the main index.
It states that a “checkpoint” represents a change in how web pages are interlinked with each other.
For example, when someone publishes a new web page, the link relationships within that site change. The checkpoint represents that change.
The above is my plain English translation. Below is what the patent describes:
“The term “checkpoint” is used within this specification to describe a data structure that may describe a state change in a portion of the distance table respective to a particular shard server and a particular time interval.
Each checkpoint includes a timestamp and a delta representing the changes to the data from the previous checkpoint. The shard servers will generally write checkpoints to the GFS independently of one another, and their regular interval times may include an element of pseudo-randomness so as to smooth out the demand for GFS resources. Because each shard server determines when a particular checkpoint is written to the GFS, the process is asynchronous.”
So there you have it. The timing may have something to do with optimizing the use of RAM so that it doesn’t become overburden. It’s possible that for a site that is constantly being updated and links are constantly being added, the time it takes to rank may be faster.
Just my opinion, but I believe that this isn’t necessarily because the page or website is “authoritative” but because the shard that is responsible for updating this part of the index is particularly busy and it needs to create a checkpoint in order to keep running smoothly.
In my experience, rankings tend to stabilize from ten to fifteen days. If it’s a large amount of content in the tens of thousands of pages, in my experience stabilization of ranking positions can take as long as a month.
Why New Pages Bounce in the Search Results
The answer to a seemingly simple question such as “why do new pages fluctuate in Google’s search results” can be extraordinarily complex.
It’s easy to toss out random guesses such as Google is tracking clicks and user satisfaction metrics. But there is zero evidence in scientific papers and patents that are published by Google to support that it’s Google tracking clicks. To choose to believe such a conclusion, without any evidence at all, is an exercise in willful ignorance.
John Mueller simply said that new pages are subject to extreme fluctuations (as noted in the link at the top of this article). The reasons, as I outlined in this article, may be many. I highlighted several of these reasons
More Resources
- Google Freshness Algorithm: Everything You Need to Know
- Safe or Risky SEO: How Dangerous Is It REALLY to Change Your Article Dates?
- Google’s Caffeine Update: Better Indexing & Fresher Search Results
Images by Shutterstock, Modified by Author
Screenshots by Author, Modified by Author
