

Website indexing is one of the first steps (after crawling) in a complex process of understanding what webpages are about for them to be ranked and served as search results by search engines.
Search engines are constantly improving how they crawl and index websites.
Understanding how Google and Bing approach crawling and indexing websites is essential for technical SEO and useful in developing strategies for improving search visibility.
Indexing: How Search Engines Work Today
Let’s look at the nuts and bolts of how search engines operate.
This article focuses on indexing. So, let’s dive in.
Web Indexing
Indexing is where the ranking process begins after a website has been crawled.
Indexing essentially refers to adding a webpage’s content to Google to be considered for rankings.
When you create a new page on your site, there are several ways it can be indexed.
The simplest method of getting a page indexed is to do absolutely nothing.
Google has crawlers following links, and thus, provided your site is in the index already, and the new content is linked to from within your site, Google will eventually discover it and add it to its index. More on this later.
How To Get A Page Indexed Faster
But what if you want Googlebot to get to your page faster?
This can be important if you have timely content or if you’ve made an important change to a page you need Google to know about.
I use faster methods when I’ve optimized a critical page or adjusted the title and description to improve click-throughs.
I want to know specifically when they were picked up and displayed in the SERPs to know where the improvement measurement starts.
In these instances, there are a few additional methods you can use.
1. XML Sitemaps
XML sitemaps are the oldest and a generally reliable way to call a search engine’s attention to content.
An XML sitemap gives search engines a list of all the pages on your site, as well as additional details about it, such as when it was last modified.
A sitemap can be submitted to Bing via Bing Webmaster Tools, and it can also be submitted to Google via Search Console.
Definitely recommended!
But when you need a page indexed immediately, it’s not particularly reliable.
2. Request Indexing With Google Search Console
In Search Console, you can “Request Indexing.”
You begin by clicking on the top search field, which reads by default, “Inspect and URL in domain.com.”
Enter the URL you want to be indexed, then hit Enter.
If the page is already known to Google, you will be presented with a bunch of information. We won’t get into that here, but I recommend logging in and seeing what’s there if you haven’t already.
For our purposes here, the important button appears whether the page has been indexed or not – meaning that it’s good for content discovery or just requesting Google to understand a recent change.
You’ll find the button shown below.
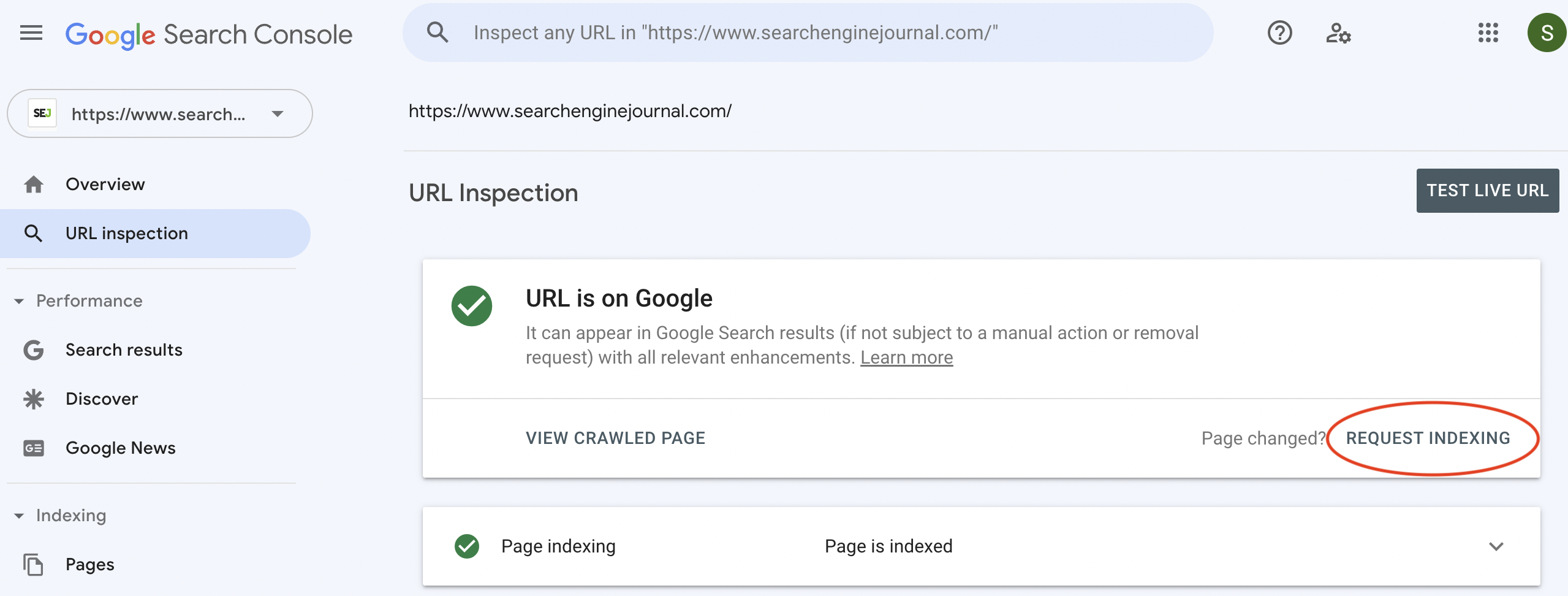
Within a few seconds to a few minutes, you can search the new content or URL in Google and find the change or new content picked up.
3. Participate In Bing’s IndexNow
Bing has an open protocol based on a push method of alerting search engines of new or updated content.
This new search engine indexing protocol is called, IndexNow.
It’s called a push protocol because the idea is to alert search engines using IndexNow about new or updated content, which will cause them to come and index it.
An example of a pull protocol is the old XML sitemap way that depends on a search engine crawler to decide to visit and index it (or to be fetched by Search Console).
The benefit of IndexNow is that it wastes less web hosting and data center resources, which is not only more environmentally friendly but it saves on bandwidth resources.
The biggest benefit, however, is faster content indexing.
IndexNow is currently used only by Bing and Yandex.
Implementing IndexNow is easy:
- There’s an IndexNow WordPress plugin.
- Drupal IndexNow Module.
- IndexNow supported by Cloudflare.
- IndexNow supported by Akamai.
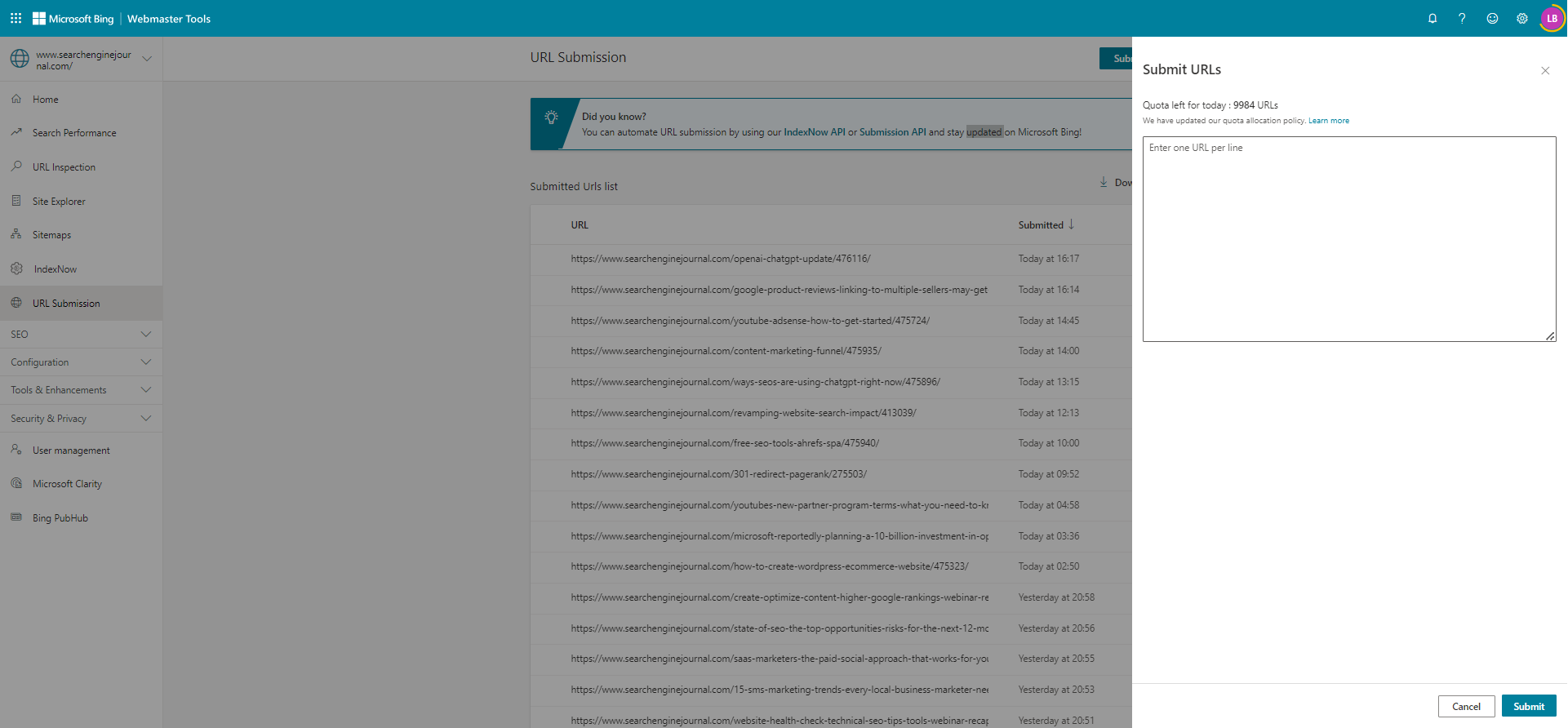
4. Bing Webmaster Tools
In addition to participating in IndexNow, consider a Bing Webmaster Tools account.
If you don’t have a Bing Webmaster Tools account, I can’t recommend it enough.
The information provided is substantial and will help you better assess problem areas and improve your rankings on Bing, Google, and anywhere else – and probably provide a better user experience.
But to get your content indexed, you simply need to click: Configure My Site > Submit URLs.
Enter the URL(s) you want to be indexed and click “Submit.”
So, that’s most of what you need to know about indexing and how search engines do it (with an eye toward where things are going).
More details at the Bing Webmaster Tools URL Submission Tool help page.
There is also a Bing Webmaster Tools Indexing API that can also speed up the time that content appears in Bing’s search results within hours.
More information about the Bing Indexing API is here.
Crawl Budget
We can’t talk about indexing without talking about the crawl budget.
Basically, crawl budget is a term used to describe the number of resources that Google will expend crawling a website.
The budget assigned is based on a combination of factors, the two central ones being:
- How fast is your server (i.e., how much can Google crawl without degrading your user experience)?
- How important is your site?
If you run a major news site with constantly updating content that search engine users will want to be aware of, your site will get crawled frequently (dare I say – constantly).
If you run a small barbershop, have a couple of dozen links, and rightfully are not deemed important in this context (you may be an important barber in the area, but you’re not important when it comes to the crawl budget), then the budget will be low.
You can read more about crawl budgets and how they’re determined in Google’s explanation.
Google Has Two Kinds Of Crawling
Indexing by Google begins with crawling, which has two kinds:
- The first kind of crawling is Discovery, where Google discovers new webpages to add to the index.
- The second kind of crawling is Refresh, where Google finds changes in webpages that are already indexed.
Discover How Search Engines Work
Optimizing websites for search engines begins with good content and ends with sending it off to get indexed.
Whether you do that with an XML sitemap, Google Search Console URL Submission Tool, Bing Webmaster Tools, or IndexNow, getting that content indexed is when your webpage begins its journey to the top of the search results (if everything works out!).
That’s why it’s important to understand how search indexing works.
Read more about the key factors that influence search engine result pages in How Search Engines Work.
Featured Image: Overearth/Shutterstock
