

Google creating a language model isn’t something new; in fact, Google LaMDA joins the likes of BERT and MUM as a way for machines to better understand user intent.
Google has researched language-based models for several years with the hope of training a model that could essentially hold an insightful and logical conversation on any topic.
So far, Google LaMDA appears to be the closest to reaching this milestone.
What Is Google LaMDA?
LaMDA, which stands for Language Models for Dialog Application, was created to enable software to better engage in a fluid and natural conversation.
LaMDA is based on the same transformer architecture as other language models such as BERT and GPT-3.
However, due to its training, LaMDA can understand nuanced questions and conversations covering several different topics.
With other models, because of the open-ended nature of conversations, you could end up speaking about something completely different, despite initially focusing on a single topic.
This behavior can easily confuse most conversational models and chatbots.
During last year’s Google I/O announcement, we saw that LaMDA was built to overcome these issues.
The demonstration proved how the model could naturally carry out a conversation on a randomly given topic.
Despite the stream of loosely associated questions, the conversation remained on track, which was amazing to see.
How Does LaMDA work?
LaMDA was built on Google’s open-source neural network, Transformer, which is used for natural language understanding.
The model is trained to find patterns in sentences, correlations between the different words used in those sentences, and even predict the word that is likely to come next.
It does this by studying datasets consisting of dialogue rather than just individual words.
While a conversational AI system is similar to chatbot software, there are some key differences between the two.
For example, chatbots are trained on limited, specific datasets and can only have a limited conversation based on the data and exact questions it is trained on.
On the other hand, because LaMDA is trained on multiple different datasets, it can have open-ended conversations.
During the training process, it picks up on the nuances of open-ended dialogue and adapts.
It can answer questions on many different topics, depending on the flow of the conversation.
Therefore, it enables conversations that are even more similar to human interaction than chatbots can often provide.
How Is LaMDA Trained?
Google explained that LaMDA has a two-stage training process, including pre-training and fine-tuning.
In total, the model is trained on 1.56 trillion words with 137 billion parameters.
Pre-training
For the pre-training stage, the team at Google created a dataset of 1.56T words from multiple public web documents.
This dataset is then tokenized (turned into a string of characters to make sentences) into 2.81T tokens, on which the model is initially trained.
During pre-training, the model uses general and scalable parallelization to predict the next part of the conversation based on previous tokens it has seen.
Fine-tuning
LaMDA is trained to perform generation and classification tasks during the fine-tuning phase.
Essentially, the LaMDA generator, which predicts the next part of the dialogue, generates several relevant responses based on the back-and-forth conversation.
The LaMDA classifiers will then predict safety and quality scores for each possible response.
Any response with a low safety score is filtered out before the top-scored response is selected to continue the conversation.
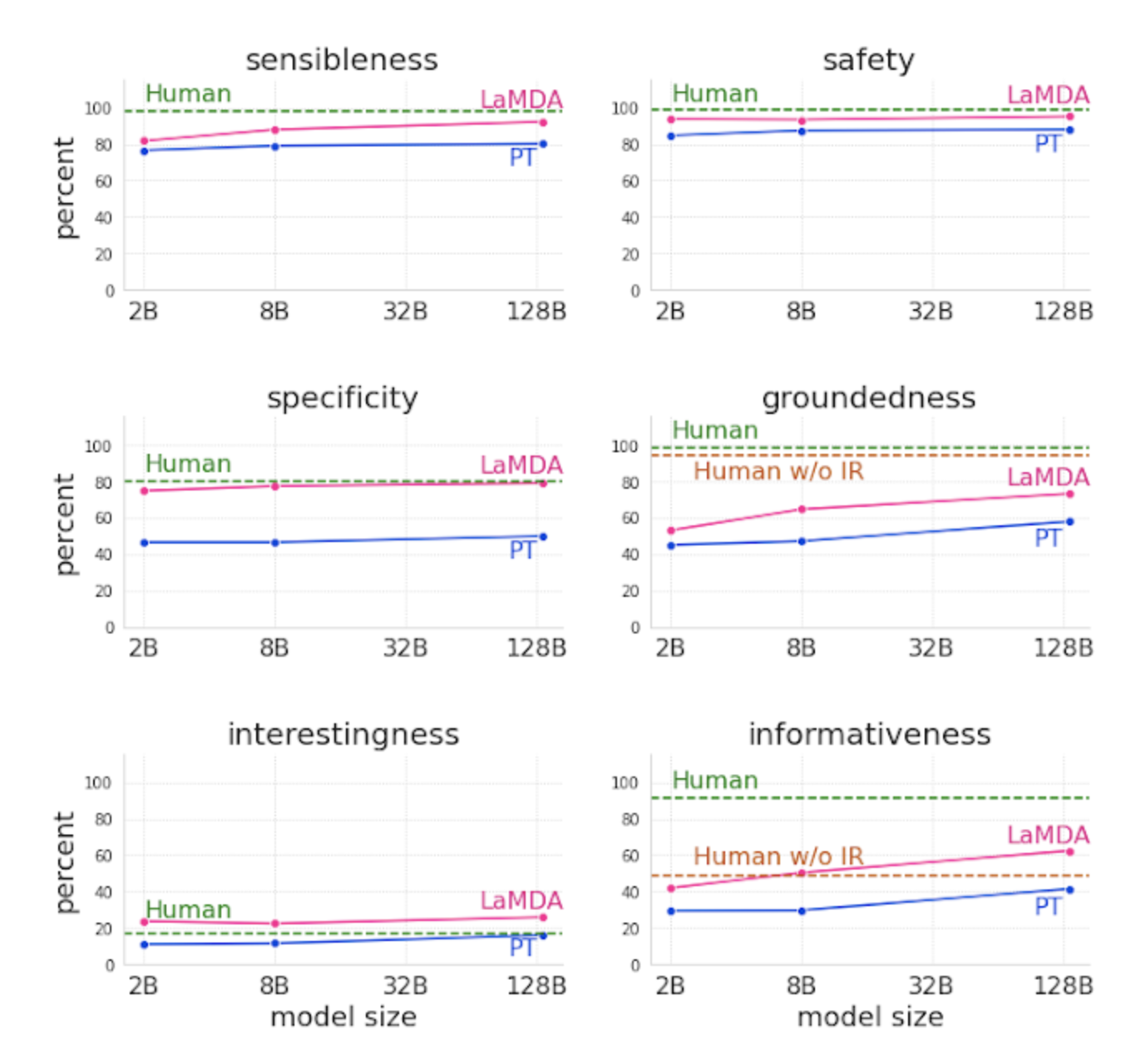
The scores are based on safety, sensibility, specificity, and interesting percentages.

The goal is to ensure the most relevant, high quality, and ultimately safest response is provided.
LaMDA Key Objectives And Metrics
Three main objectives for the model have been defined to guide the model’s training.
These are quality, safety, and groundedness.
Quality
This is based on three human rater dimensions:
- Sensibleness.
- Specificity
- Interestingness.
The quality score is used to ensure a response makes sense in the context it is used, that it is specific to the question asked, and is considered insightful enough to create better dialogue.
Safety
To ensure safety, the model follows the standards of responsible AI. A set of safety objectives are used to capture and review the model’s behavior.
This ensures the output does not provide any unintended response and avoids any bias.
Groundedness
Groundedness is defined as “the percentage of responses containing claims about the external world.”
This is used to ensure that responses are as “factually accurate as possible, allowing users to judge the validity of a response based on the reliability of its source.”
Evaluation
Through an ongoing process of quantifying progress, responses from the pre-trained model, fine-tuned model and human raters, are reviewed to evaluate the responses against the aforementioned quality, safety, and groundedness metrics.
So far, they have been able to conclude that:
- Quality metrics improve with the number of parameters.
- Safety improves with fine-tuning.
- Groundedness improves as the model size increases.
How Will LaMDA Be Used?
While still a work in progress with no finalized release date, it is predicted that LaMDA will be used in the future to improve customer experience and enable chatbots to provide a more human-like conversation.
In addition, using LaMDA to navigate search within Google’s search engine is a genuine possibility.
LaMDA Implications For SEO
By focusing on language and conversational models, Google offers insight into their vision for the future of search and highlights a shift in how their products are set to develop.
This ultimately means there may well be a shift in search behavior and the way users search for products or information.
Google is constantly working on improving the understanding of users’ search intent to ensure they receive the most useful and relevant results in SERPs.
The LaMDA model will, no doubt, be a key tool to understand questions searchers may be asking.
This all further highlights the need to ensure content is optimized for humans rather than search engines.
Making sure content is conversational and written with your target audience in mind means that even as Google advances, content can continue to perform well.
It’s also key to regularly refresh evergreen content to ensure it evolves with time and remains relevant.
In a paper titled Rethinking Search: Making Experts out of Dilettantes, research engineers from Google shared how they envisage AI advancements such as LaMDA will further enhance “search as a conversation with experts.”
They shared an example around the search question, “What are the health benefits and risks of red wine?”
Currently, Google will display an answer box list of bullet points as answers to this question.
However, they suggest that in the future, a response may well be a paragraph explaining the benefits and risks of red wine, with links to the source information.
Therefore, ensuring content is backed up by expert sources will be more important than ever should Google LaMDA generate search results in the future.
Overcoming Challenges
As with any AI model, there are challenges to address.
The two main challenges engineers face with Google LaMDA are safety and groundedness.
Safety – Avoiding Bias
Because you can pull answers from anywhere on the web, there is the possibility that the output will amplify bias, reflecting the notions that are shared online.
It is important that responsibility comes first with Google LaMDA to ensure it is not generating unpredictable or harmful results.
To help overcome this, Google has open-sourced the resources used to analyze and train the data.
This enables diverse groups to participate in creating the datasets used to train the model, help identify existing bias, and minimize any harmful or misleading information from being shared.
Factual Grounding
It isn’t easy to validate the reliability of answers that AI models produce, as sources are collected from all over the web.
To overcome this challenge, the team enables the model to consult with multiple external sources, including information retrieval systems and even a calculator, to provide accurate results.
The Groundedness metric shared earlier also ensures responses are grounded in known sources. These sources are shared to allow users to validate the results given and prevent the spreading of misinformation.
What’s Next For Google LaMDA?
Google is clear that there are benefits and risks to open-ended dialog models such as LaMDA and are committed to improving safety and groundedness to ensure a more reliable and unbiased experience.
Training LaMDA models on different data, including images or videos, is another thing we may see in the future.
This opens up the ability to navigate even more on the web, using conversational prompts.
Google’s CEO Sundar Pichai said of LaMDA, “We believe LaMDA’s conversation capabilities have the potential to make information and computing radically more accessible and easier to use.”
While a rollout date hasn’t yet been confirmed, it’s no doubt models such as LaMDA will be the future of Google.
More resources:
- How Machine Learning in Search Works: Everything You Need to Know
- How Search Engines Use Machine Learning: 9 Things We Know For Sure
- How Search Engines Work
Featured Image: Andrey Suslov/Shutterstock
