

A Google patent describes a method of classifying sites as low quality by ranking the links. The algorithm patent is called, Classifying Sites as Low Quality Sites. The patent names specific factors for identifying low quality sites.
It’s worthwhile to learn these factors and consider them. There’s no way to know if they are in use. But the factors themselves can help improve SEO practices, regardless if Google is using the algorithm or not.
An Obscure Link Algorithm
This patent dates from 2012 to 2015. It corresponds to the time that Penguin was first released.
There have only been a few discussions of this algorithm. It has, in my opinion, not been discussed in the detail offered below. As a consequence, it seems that many people may not be aware of it.
I believe this is an important algorithm to understand. If any parts of it are in use, then it could impact the SEO process.
Just Because it’s Patented…
What must be noted in any discussions of patents or research papers is that just because it’s patented does not mean it’s in use. I would also like to point out that this patent dates from 2012 to 2015. This corresponds to the time period of the Penguin Algorithm.
There is no evidence that this is a part of the Penguin Algorithm. But it is interesting because it is one of the few link ranking algorithms we know about from Google. Not a site ranking algorithm, a link ranking algorithm. That quality makes this particular algorithm especially interesting.
Although this algorithm may or may not be use, I believe that it is worthwhile to understand what is possible. Knowing what is possible can help you better understand what is not possible or likely. And once you know that you are better able to spot bad SEO information.
How the Algorithm Ranks Links
The algorithm is called Classifying Sites as Low Quality. It works by ranking links, not the content itself. The underlying principle can be said to be that if the links to a site are low quality then the site itself must be low quality.
This algorithm may be resistant to spammy scraper links because it only comes into play after the ranking algorithm has done it’s work. It’s the ranking algorithm that includes Penguin and other link related algorithms. So once the ranking engine has ranked sites, the link data that this algorithm uses will likely be filtered and represent a reduced link graph. A reduced link graph is a map of the links to and from sites that have had all the spam connections removed.
The algorithm ranks the links according to three ranking scores. The patent calls these scores, “quality groups.”
The scores are named Vital, Good, and Bad.
Obviously, the Vital score is the highest, Good is medium and Bad is not good (so to speak!).
The algorithm will then take all the scores and compute a total score. If this score falls below a certain threshold then the site or page itself is deemed low quality.
That’s my plain English translation of the patent.
Here is how the the patent itself describes itself:
“The system assigns the resources to resource quality groups (310). Each resource quality group is defined by a range of resource quality scores. The ranges can be non-overlapping. The system assigns each resource to the resource quality group defined by the range encompassing the resource quality score for the resource. In some implementations, the system assigns each resource to one of three groups, vital, good, and bad. Vital resources have the highest resource quality scores, good resource have medium resource quality scores, and bad resources have the lowest resource quality scores.”
Implied Links
The patent also describes something called an Implied Link. The concept of implied links must be explained before we proceed further.
There is an idea in the SEO community that Implied Links are unlinked citations. An unlinked citation is a URL that is not a link, a URL that cannot be clicked to visit the site. However, there are other definitions of an Implied Link.
A non-Google researcher named Ryan Rossi describes a Latent Link as a sort of virtual link. Latent means something that is hidden or can’t be readily seen. The paper is called, Discovering Latent Graphs with Positive and Negative Links to Eliminate Spam in Adversarial Information Retrieval
A latent link happens when there is an implied relationship between two sites that do not directly link to each other. It happens when they share link relationships with other sites in common. Please see the image below for an illustration of the concept.
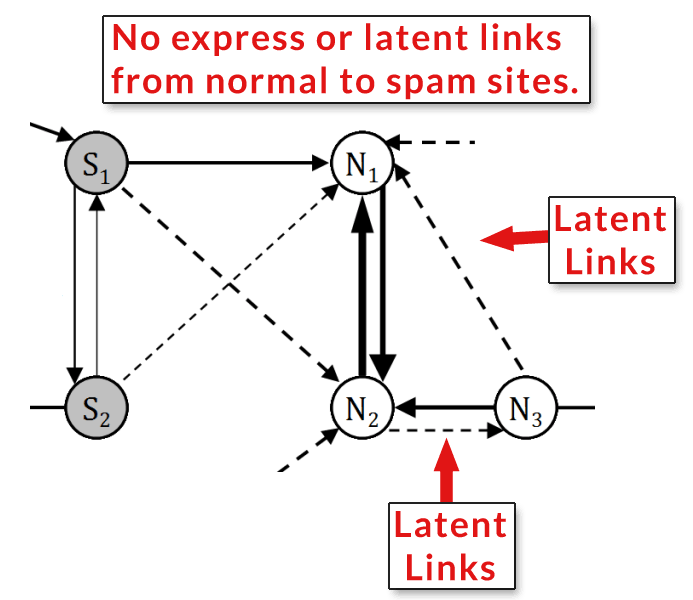 This is an illustration showing the link relationships that create a latent (or implied) link. The nodes labeled S represent spam sites. The nodes labeled N represent normal sites. The dotted lines are implied links. What’s notable is that there are no links from the normal sites to the spam sites.
This is an illustration showing the link relationships that create a latent (or implied) link. The nodes labeled S represent spam sites. The nodes labeled N represent normal sites. The dotted lines are implied links. What’s notable is that there are no links from the normal sites to the spam sites.Here’s what the non-Google research paper says:
“Latent relationships between sites are discovered based on the structure of the normal and spam communities.
… Automatic ranking of links where latent links are discovered… between the spam sites {S1, S2} and normal sites {N1, N2,N3} based on the fundamental structure of the two communities.
…The results provide significant evidence that our Latent Graph strongly favors normal sites while essentially eliminating spam sites and communities through the suppression of their links.”
The takeaway from the above is the concept of Latent Links, which can correspond with the concept of Implied Links.
Here is what the Google Patent says about Implied Links:
“A link can be an express link or an implied link. An express link exists where a resource explicitly refers to the site. An implied link exists where there is some other relationship between a resource and the site.”
If the Google patent author meant to say that the link was an unlinked URL, it’s not unreasonable to assume they would have said so. Instead, the author states that there is “some other relationship” between the “resource” (the linking site) and the website (the site that’s being linked to implicitly).
It’s my opinion that a likely candidate for an Implied Link is similar to what Ryan Rossi described as a Latent Link.
Link Quality Factors
Here are the quality factors that the patent named. Google does not generally say whether or not a patent or research is actually in use or how. And what is actually in use could possibly go beyond. Nevertheless, it’s useful to know that these factors were named in the patent and to then think about these link ranking factors when creating a link strategy.
Diversity Filtering
Diversity filtering is the process of identifying that a site has multiple incoming links from a single site. This algorithm will discard all the links from the linking site and use just one.
“Diversity filtering is a process for discarding resources that provide essentially redundant information to the link quality engine.
…the link quality engine can discard one of those resources and select a representative resource quality score for both of them. For example, the link quality engine can receive resource quality scores for both resources and discard the lower resource quality Score.”
The patent also goes on to say that it could also use a Site Quality Score to rank the link.
Boilerplate Links
The patent says that it has the option to not use what it calls “boilerplate” links. It uses navigational links as an example.
That appears to say that links from the navigation and possibly from a sidebar or footer that are repeated across the entire site will optionally not be counted. They may be discarded entirely.
This makes a lot of sense. A link is a vote for another site. In general a link that has a context and meaning is what is counted because they say something about the site they are linking to. There is no such semantic context in a sitewide link.
Links That Are Related
It’s not unusual for groups of sites within a niche to link to each other. This part of the patent describes a group of sites that seem to be linking to similar sites. This could be a statistical number that represents an unnatural amount of similar outbound links to the same sites.
The research paper doesn’t go into further detail. But this is, in my opinion a typical way of identifying related links and unraveling a spam network.
“…the system can determine that a group of candidate resources all belong to a same different site, e.g., by determining that the group of candidate resources are associated with the same domain name or the same Internet Protocol (IP) address, or that each of the candidate resources in the group links to a minimum number of the same sites.”
Links from Sites with Similar Content Context
This is an interesting example. If the links share the context of the content, the algorithm will discard it:
“In another example, the system can determine that a group of candidate resources share a same content context.”
…The system can then select one candidate resource from the group, e.g., the candidate resource having the highest resource quality score, to represent the group.”
Overview and Takeaways
This algorithm is described as “for enhancing search results.” This means that the ranking engine does it thing and then this algorithm steps in to rank the inbound links and lower the ranking scores of sites that have low quality scores.
An interesting feature is that this belongs to a class of algorithms that ranks links, not sites.
Classifying Sites as Low Quality Sites
Read the entire patent here. And download the PDF version of the patent here.
More Resources
- 5 Strategies Unlocked From Google’s Quality Rating Guidelines
- The SEO Implications of Google’s Search Quality Raters Guidelines
Images by Shutterstock, Modified by Author
Screenshots by Author, Modified by Author
