



Google recently announced they are using a “neural matching” algorithm to better understand concepts. Google’s Danny Sullivan said is being used for 30% of search queries.
Google has recently published a research paper that successfully matches search queries to web pages using only the search query and the web pages. While this algorithm may not be in use, or maybe used as part of a group of algorithms, it does serve as an example of how a “neural matching” algorithm could work.
Does Google Use Published Algorithms?
Google does not always use the algorithms that are published in patents and research papers. However, an indeterminate number of published algorithms are indeed used in Google’s search algorithms.
It must also be stated that Google does not generally confirm whether a specific algorithm is in use.
Google Discusses New AI Algorithm
Google has in the past discussed algorithms in general terms, such as the Panda algorithm and the Penguin Algorithm. And this seems to be the case today, as Danny Sullivan drops clues as to this new “neural matching” algorithm.
This new algorithm was discussed by Danny Sullivan (in a tweet) as being a:
“…neural matching, –AI method to better connect words to concepts.”
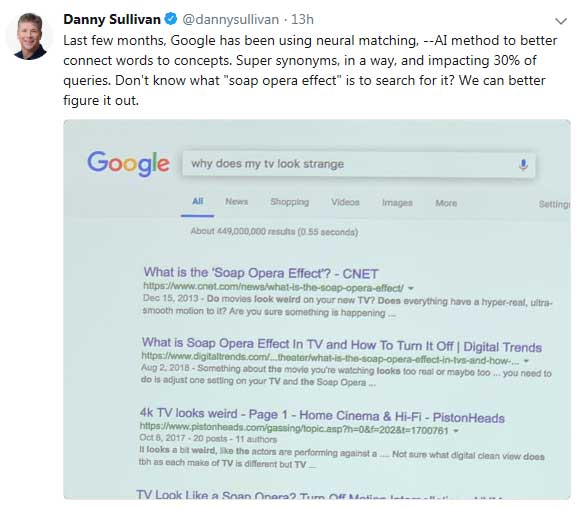 Google’s Danny Sullivan discusses Neural Matching.
Google’s Danny Sullivan discusses Neural Matching.“How people search is often different from information that people write solutions about.”
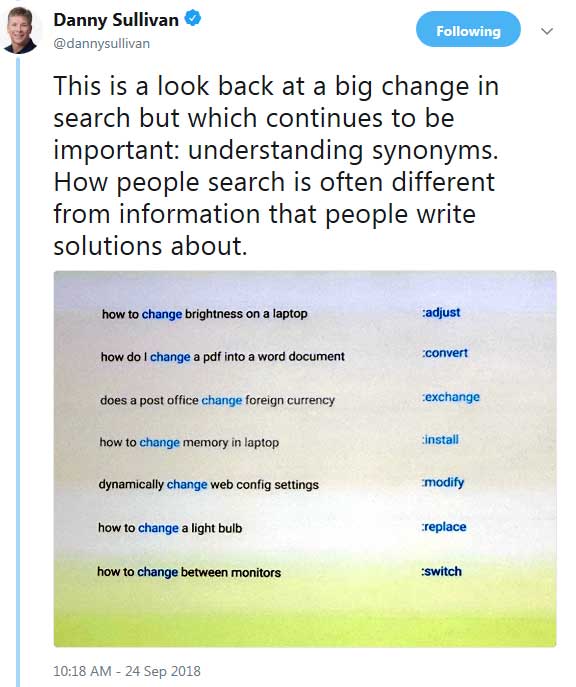 Danny Sullivan tweeted a screenshot showing how words have different meanings.
Danny Sullivan tweeted a screenshot showing how words have different meanings.AI, Deep Learning and Ranking Pages
Google’s AI Blog recently published a link to a new research paper called, Deep Relevance Ranking using Enhanced Document-Query Interactions. Although this algorithm research is relatively new, it improves on a revolutionary deep neural network method for accomplishing a task known as Document Relevance Ranking. This method is also known as Ad-hoc Retrieval.
While it can’t be said definitively that this is a part of what Google’s calling Neural Matching, it makes for interesting research on something that is similar to that.
This is how the new research paper describes ad-hoc retrieval:
“Document relevance ranking, also known as ad-hoc retrieval… is the task of ranking documents from a large collection using the query and the text of each document only.”
The research paper is clear, that this form of ranking uses only the search query and the web page only. It goes on to say:
“This contrasts with standard information retrieval (IR) systems that rely on text-based signals in conjunction with network structure (Page et al., 1999; Kleinberg, 1999) and/or user feedback (Joachims, 2002).”
In the above statement, it states that Document Relevance Ranking differs from other search technologies (information retrieval systems) that rely on “network structure” and then it cites Larry Page, which is a reference to PageRank and links. It also cites Kleinberg, which is a reference to Jon Kleinbergs research on using links to rank web pages.
It is clear that Document Relevance Ranking is a relatively new method for ranking web pages and that it doesn’t rely on link signals.
Does Google’s Document Relevance Ranking Not Use Links?
The new alorithm that was published in Google’s AI blog doesn’t directly use traditional ranking factors. However, traditional ranking factors are used first. Then the Ad-hoc retrieval part of the algorithm is used.
The research paper states that it is re-ranking web pages that have already been ranked.
This means that whatever ranking signal hoops a web page must jump through in order to get ranked still exist. However, the traditional ranking signals do not determine what pages will rank in the top ten.
So it could be said that traditional ranking signals serve a sort of vetting function. The ranking signal removes the spam and collects the most relevant documents.
What this new algorithm does is re-ranks those web pages according to a whole different set of criteria for matching what Danny Sullivan called, “Super synonyms.”
And this use of ranking signals first is what makes this algorithm different than the one published in 2016, referred to as a Deep Relevance Matching Model (DRMM).
Here is what the new reseach said, in comparing DRMM with this new algorithm:
“In the interaction based paradigm, explicit encodings between pairs of queries and documents are induced. This allows direct modeling of exact- or near-matching terms (e.g., synonyms), which is crucial for relevance ranking.
Indeed, Guo et al. (2016) showed that the interaction-based DRMM outperforms previous representation-based methods. On the other hand, interaction-based models are less efficient, since one cannot index a document representation independently of the query. This is less important, though, when relevance ranking methods rerank the top documents returned by a conventional IR engine, which is the scenario we consider here.”
What Does the Algorithm Actually Do?
The purpose of the algorithm is to match a search query to a web page, using only the search query and the web page text itself. Web pages ranked by this kind of algorithm will not have been promoted to the top positions by virtue of links or keywords, since this kind of algorithm is about “relevance matching.”
“We explore several new models for document relevance ranking, building upon the Deep Relevance Matching Model (DRMM)… Unlike DRMM, which uses context-insensitive encodings of terms and query-document term interactions, we inject rich context-sensitive encodings throughout our models, inspired by PACRR’s (Hui et al.,2017) convolutional n-gram matching features, but extended in several ways including multiple views of query and document inputs.”
Content is More Important
Does this mean publishers should use more synonyms? Adding synonyms has always seemed to me to be a variation of keyword spamming. I have always considered it a naive suggestion.
The purpose of Google understanding synonyms is simply to understand the context and meaning of a page. Communicating clearly and consistently is, in my opinion, more important than spamming a page with keywords and synonyms.
What Google has officially stated is that it is able to understand concepts. So in a way, that goes beyond mere keywords and synonyms. It’s a more natural understanding of how a web page solves the problem implied in a search query. According to Google’s official announcement:
“…we’ve now reached the point where neural networks can help us take a major leap forward from understanding words to understanding concepts. Neural embeddings, an approach developed in the field of neural networks, allow us to transform words to fuzzier representations of the underlying concepts, and then match the concepts in the query with the concepts in the document. We call this technique neural matching.”
Is This Neural Matching?
It’s possible that neural matching has elements of this algorithm mixed with elements of other algorithms. Whether Google is using this exact algorithm is less important than understanding that ranking documents using only the search query and the web page content is possible.
Understanding this will help publishers avoid spinning their wheels with unhelpful strategies like adding synonyms.
This new kind of AI ranking shows how it’s possible to generate search results that are not directly ranked by traditional ranking factors like links or keywords. And this demands closer attention to things like user intent and understanding how a page of content helps a user.
Read the research paper here: Deep Relevance Ranking Using Enhanced Document-Query Interactions
Images by Shutterstock, Modified by Author
Screenshots by Author
