

Google’s John Mueller recently “liked” a tweet by search marketing consultant Barry Adams (of Polemic Digital) that concisely stated the purpose of the robots.txt exclusion protocol. He freshened up an old topic and quite possibly gave us a new way to think about it.
Google Can Index Blocked Pages
The issue began when a publisher tweeted that Google had indexed a website that was blocked by robots.txt.

“URLs can be indexed without being crawled, if they’re blocked by robots.txt – that’s by design.
Usually that comes from links from somewhere, judging from that number, I’d imagine from within your site somewhere.”
How Robots.txt Works
“Robots.txt is a crawl management tool, not an index management tool.”
We often think of Robots.txt as a way to block Google from including a page from Google’s index. But robots.txt is just a way to block which pages Google crawls.
That’s why if another site has a link to a certain page, then Google will crawl and index the page (to a certain extent).
Barry then went on to explain how to keep a page out of Google’s index:
“Use meta robots directives or X-Robots-Tag HTTP headers to prevent indexing – and (counter-intuitively) let Googlebot crawl those pages you don’t want it to index so it sees those directives.”
NoIndex Meta Tag
The noindex meta tag allows crawled pages to be kept out of Google’s index. It doesn’t stop the crawl of the page, but it does assure the page will be kept out of Google’s index.
The noindex meta tag is superior to the robots.txt exclusion protocol for keeping a web page from being indexed.
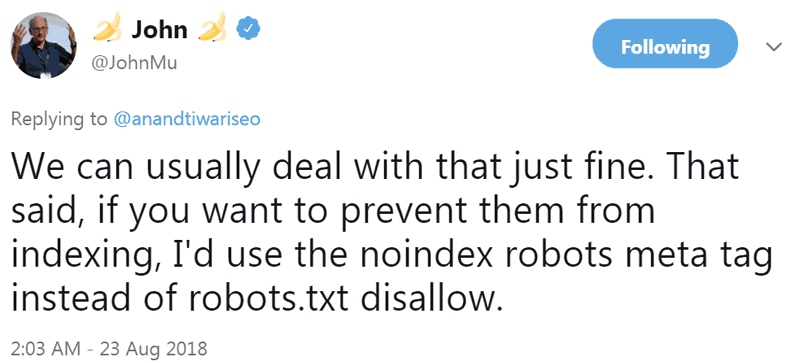
Here is what John Mueller said in a tweet from August 2018
“…if you want to prevent them from indexing, I’d use the noindex robots meta tag instead of robots.txt disallow.”
Robots Meta Tag Has Many Uses
A cool thing about the Robots meta tag is that it can be used to solve issues until a better fix comes along.
For example, a publisher was having trouble generating 404 response codes because the angularJS framework kept generating 200 status codes.
His tweet asking for help said:
Hi @JohnMu I´m having many troubles with managing 404 pages in angularJS, always give me a 200 status on them. Any way to solve it? Thanks

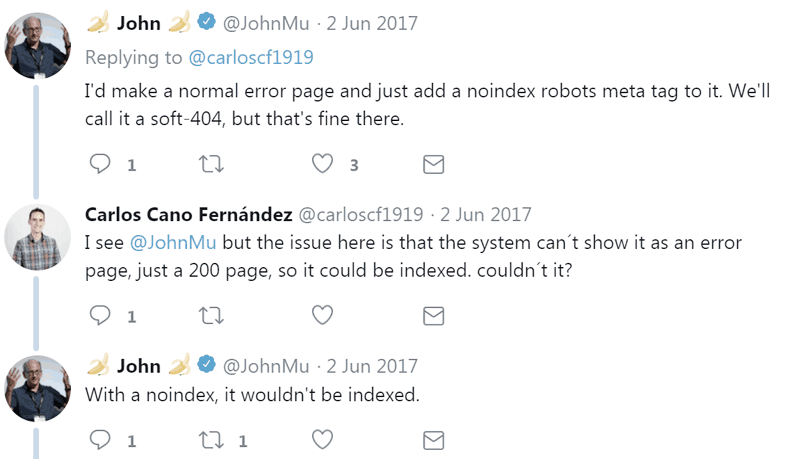
John Mueller suggested using a robots noindex meta tag. This would cause Google to drop that 200 response code page from the index and regard that page as a soft 404.
“I’d make a normal error page and just add a noindex robots meta tag to it. We’ll call it a soft-404, but that’s fine there.”
So, even though the web page is showing a 200 response code (which means the page was successfully served), the robots meta tag will keep the page out of Google index and Google will treat it as if the page is not found, which is a 404 response.
Official Description of Robots Meta Tag
According to the official documentation at the World Wide Web Consortion, the official body that decides web standards (W3C), this is what the Robots Meta Tag does:
“Robots and the META element
The META element allows HTML authors to tell visiting robots whether a document may be indexed, or used to harvest more links.”
This is how the W3c documents describe the Robots.txt:
“When a Robot visits a Web site,it firsts checks for …robots.txt. If it can find this document, it will analyze its contents to see if it is allowed to retrieve the document.”
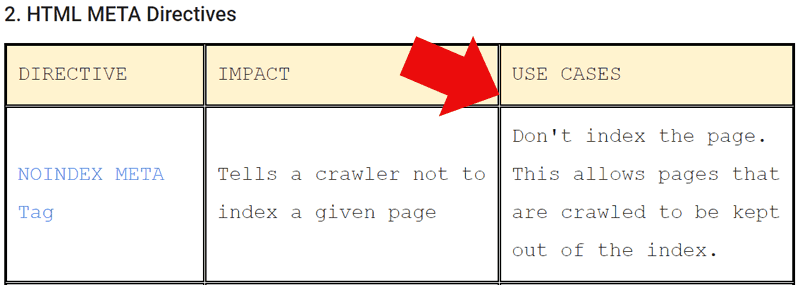
The W3c interprets the role of the Robots.txt as like a gate keeper for what files are retrieved. Retrieved means crawled by a robot that obeys the Robots.txt exclusion protocol.
Barry Adams was correct to describe the Robots.txt exclusion as a way to manage crawling, not indexing.
It might be useful to thik of the Robots.txt as being like security guards at the door of your site, keeping certain web pages blocked. It may make untangling strange Googlebot activity on blocked web pages a little easier.
More Resources
- Best Practices for Setting Up Meta Robots Tags and Robots.txt
- 16 Ways to Get Deindexed by Google
- Google Offers Advice on 404 and 410 Status Codes
Images by Shutterstock, Modified by Author
Screenshots by Author, Modified by Author
