

Chatbots have changed many professionals’ workflows and processes.
SEO pros, writers, agencies, developers, and even teachers are still discussing the changes that this technology will cause in society and how we work in our day-to-day lives.
ChatGPT’s release on Nov. 30, 2022 led to a cascade of competition, including Gemini (formerly Bard) and Claude.
If you want to search for information, need help fixing bugs in your CSS, or want to create something as simple as a robots.txt file, chatbots may be able to help.
They’re also wonderful for topic ideation, allowing you to draft more interesting emails, newsletters, blog posts, and more.
But which chatbot should you use and learn to master? Which platform provides accurate, concise information?
Let’s find out.
What Is The Difference Between ChatGPT, Gemini, And Claude?
| ChatGPT | Gemini | Claude | |
| Pricing | ChatGPT’s original version remains free to users. ChatGPT Plus is available for $20/month. Team (starts at $25/month) and Enterprise options available. | Free for the base platform and a cost of $19.99/month for the advanced tier. | Free, Pro ($20/month), Team ($25/month), and Enterprise options available. |
| API | Yes | Yes | Yes |
| Developer | OpenAI | Alphabet/Google | Anthropic |
| Technology | GPT-4o | Combination of models (LaMDA, PaLM 2) | Claude Opus |
| Information Access | Training data with a cutoff date of 2023 but the Pro version has access to real-time data. | Real-time access to the data Google collects from search. | Real-time access to data. |
Wait! What Is GPT? What Is LaMDA?
ChatGPT uses GPT technology, and Gemini initially used LaMDA, meaning they’re different “under the hood.” This is why there’s some backlash against Gemini. People expect Gemini to be GPT, but that’s not the intent of the product.
Since Gemini is available on such a wide scale, it has to tune the responses to maintain its brand image and adhere to internal policies that aren’t as restrictive in ChatGPT – at the moment. However, Gemini’s foundation has evolved to include PaLM 2, making it a more versatile and powerful model.
GPT: Chat Generative Pre-Trained Transformer
GPTs are trained on tons of data using a two-phase concept called “unsupervised pre-training and then fine-tuning.”
Imagine consuming trillions of data points, and then someone comes along after you gain all of this knowledge to fine-tune it. That’s what is happening behind the scenes when you prompt ChatGPT.
ChatGPT has 1.8+ trillion parameters that it has used and learned from, including:
- Articles.
- Books.
- Websites.
- Etc.
While ChatGPT is limited in its datasets, OpenAI has announced a browser plugin that can use real-time data from websites when responding back to you. There are also other neat plugins that amplify the power of the bot.
LaMDA Stands For Language Model For Dialogue Applications
Google’s team initially chose a LaMDA model for its neural network to create a more natural way to respond to questions. The goal was to provide conversational responses to queries.
The platform is trained on conversations and human dialog, but it’s also clear that Google uses search data to provide real-time information.
Google uses an Infiniset of data, which are datasets that we don’t know much about.
Since Gemini has evolved to include PaLM 2, it may have different capabilities and training data compared to LaMDA.
Because these bots are learning from sources worldwide, they can sometimes provide false information.
Hallucinations Can Happen
Chatbots can hallucinate, but they’re also very convincing in their responses. It’s important to heed the warning of the developers.
Google tells us:
Gemini may display inaccurate info, including about people, so double-check its responses.
 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024Claude also tells us:
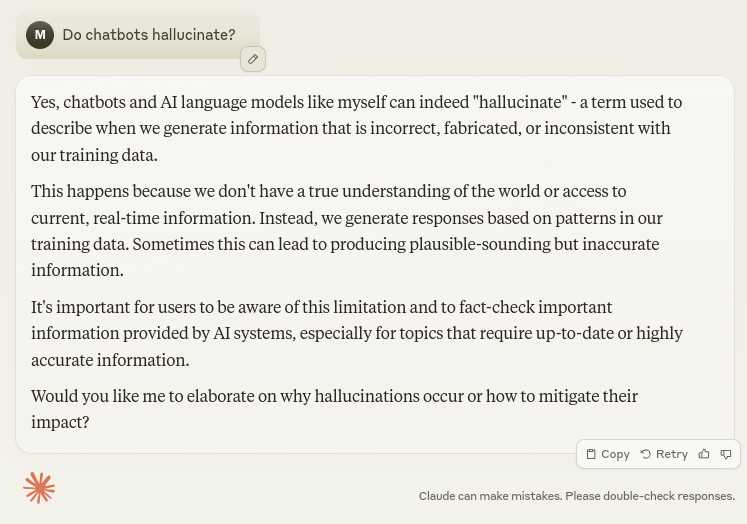 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024If you’re using chatbots for anything requiring facts and studies, crosscheck your work and verify that the facts and events actually happened.
There have been times when these hallucinations are apparent and other times when non-experts would easily be fooled by the response they receive.
Since chatbots learn from information, such as websites, they’re only as accurate as the information they receive – for now.
With all of these cautions in mind, let’s start prompting each bot to see which provides the best answers.
ChatGPT Vs. Gemini Vs. Claude: Prompt Testing And Examples
Since technical SEO is an area I am passionate about, I wanted to see what the chatbots have to say when I put the following prompt in each:
What Are The Top 3 Technical SEO Factors I Can Use To Optimize My Site?
ChatGPT’s Response
 Screenshot from ChatGPT, October 2024
Screenshot from ChatGPT, October 2024ChatGPT provides a coherent, well-structured response to this query. The response does touch on three important areas of optimization:
- Site speed.
- Crawlability and indexability.
- Mobile optimization.
When prompted to provide more information on site speed, we receive a lot of great information that you can use to begin optimizing your site.
 Screenshot from ChatGPT, October 2024
Screenshot from ChatGPT, October 2024If you’ve ever tried to optimize your site’s speed before, you know just how important all of these factors are for improving your site speed.
ChatGPT mentions browser caching, but what about server-side caching?
When site speed is impacted by slow responses to database queries, server-side caching can store these queries and make the site much faster – beyond a browser cache.
But the details in the response are much better compared to those of April 2023, even though this time I asked it to condense the list:
 Screenshot from ChatGPT, April 2023
Screenshot from ChatGPT, April 2023Gemini’s Response
Gemini’s responses are faster than ChatGPT, and I do like that you can view other “drafts” from Gemini if you like. I went with the first draft, which you can see below.
 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024The information is solid, and I appreciate that Google uses more formatting and bold parts of the responses to make them easier to read.
It is also interesting that Gemini focuses on XML Sitemaps, instead of the overall architecture of the website.
To try and keep things similar, I asked Gemini, “Can you provide more information on page speed?”
 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024You can certainly find similarities between ChatGPT’s and Gemini’s responses about optimization, but some information is a bit off. For example:
“Optimize Images: Compress and use next-gen formats (e.g., WebP).”
I could not provide a condensed list like ChatGPT did. But the list of eight to 11 suggestions (depending on the draft I looked at) was quite promising.
Browsers cache files automatically on their own, and you can certainly manipulate the cache with a Cache-Control or Expires header.
Claude’s Response
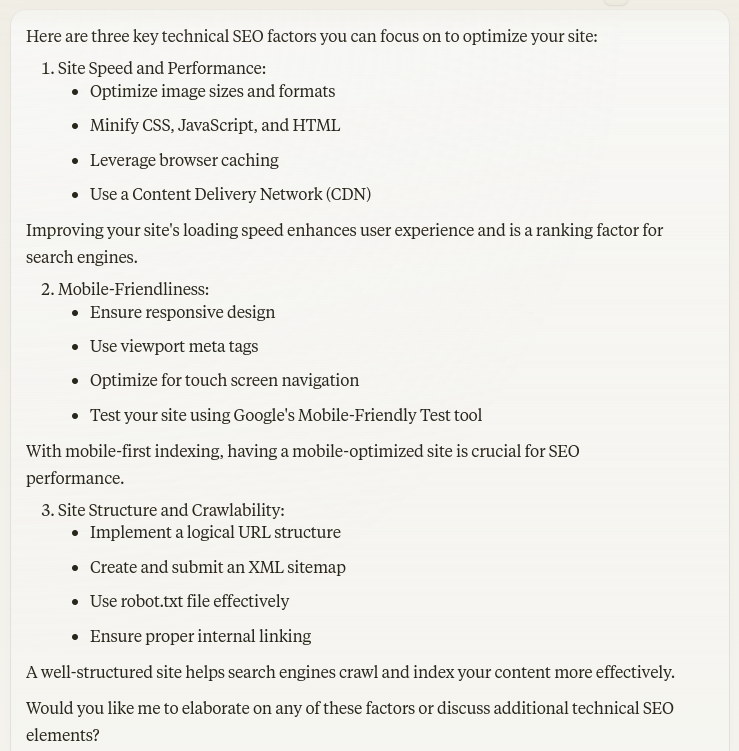 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Claude’s answers are all pretty solid, and I appreciate how it mentions several types for optimization that are a little more in-depth, such as using viewpoint meta tags.
For me, I feel like Claude provides more actionable steps than Gemini and ChatGPT. But let’s ask about speed.
 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Claude’s response is extensive, with a thorough understanding of key site speed metrics to follow. But, I was really impressed by the rest of the response:
 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024What I appreciate about Claude’s response is that it explains very important concepts of optimizing site speed while also giving you an extensive list of tools to use.
Caching is briefly mentioned in Claude’s response, but when I prompted it for more about caching, it provided an extensive list of information.
Winner: Claude wins out, thanks to its extensive answers and mention of specific tools and actionable steps.
Who Is Ludwig Makhyan?
All chatbots knew a little something about technical SEO, but how about me? Let’s see what happens when I ask them about myself:
ChatGPT’s Response
 Screenshot from ChatGPT, April 2023
Screenshot from ChatGPT, April 2023ChatGPT couldn’t find any information about me, which is understandable. I’m not Elon Musk or a famous person, but I did publish a few articles on this very blog you’re reading now before the data cutoff date of ChatGPT.
And as I refresh this article over a year later, the free version of ChatGPT still doesn’t know who I am:
 Screenshot from ChatGPT, October 2024
Screenshot from ChatGPT, October 2024But, let’s see what the paid version has to say:
 Screenshot from ChatGPT Plus, October 2024
Screenshot from ChatGPT Plus, October 2024How do Claude and Gemini perform for this query?
Gemini’s Response
 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024Gemini, formerly Bard, doesn’t know who I am either. And I found this quite interesting because Bard knew who I was a year ago.
 Screenshot from Bard, April 2023
Screenshot from Bard, April 2023Hmm. The first sentence seems a bit familiar. It came directly from my Search Engine Journal bio, word-for-word.
The last sentence in the first paragraph also comes verbatim from another publication that I write for: “He is the co-founder at MAZELESS, an enterprise SEO agency.”
I’m also not the author of either of these books, although I’ve talked about these topics in great detail before.
Unfortunately, pulling full sentences from sources and providing false information means Gemini (Bard) failed this test. You could argue that there are a few ways to rephrase those sentences, but the response could certainly be better.
Claude’s Response
 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Claude also doesn’t know who I am, but I did like that it provided a thorough explanation of why it doesn’t know lesser-known people.
From this data, it seems to me that there needs to be a lot of references for chatbots to work from to define a person.
But let’s see what these bots can do with a better prompt that is a bit more advanced.
Advanced Prompt: I Want To Become An Authority In SEO. What Steps Should I Take To Reach This Goal?
Up until this point, the prompts have been a bit easy. Let’s find out how each chatbot performs when we use more advanced prompts:
ChatGPT’s Response
 Screenshot from ChatGPT, April 2023
Screenshot from ChatGPT, April 2023 Screenshot from ChatGPT, October 2024
Screenshot from ChatGPT, October 2024 Screenshot from ChatGPT, October 2024
Screenshot from ChatGPT, October 2024ChatGPT’s new response is more robust than in the past. As you can see, it’s more in-depth than last year’s response.
While some of the underlying responses are similar, the new formatting and added thoroughness were a welcomed addition.
And what about ChatGPT Plus?
 Screenshot from ChatGPT Plus, October 2024
Screenshot from ChatGPT Plus, October 2024Between the free and premium versions of ChatGPT, there are obvious differences, mainly telling you where to take action, such as publishing content on Medium and YouTube.
Next up, let’s test the same query on Gemini.
Gemini’s Response
 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024Gemini’s response is extensive. There are three more points that didn’t fit into the screenshot above, which include: sharing your knowledge, building an online presence, and staying consistent.
Claude’s Response
 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Claude has a lot of good suggestions, and I especially like the mention of certifications. In terms of extensiveness, Claude continues with more recommendations:
 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Overall, these tips are very similar, but Claude was my favorite.
ChatGPT provides me with more “light bulb” moments, explaining that I should learn things like technical SEO research, on-page optimization, and content optimization.
Knowledge seemed to be the core of ChatGPT’s recommendations. I like how the paid version of ChatGPT even tells me which publications to contribute to when trying to build my reputation.
Let’s try putting these chatbots to work on some tasks that I’m sure they can perform.
Advanced Prompt: Create A Robots.txt File Where I Block Google Search Bot, Hide My “Private” Folder, And Block The Following IP Address “123.123.123.123”
ChatGPT’s Response
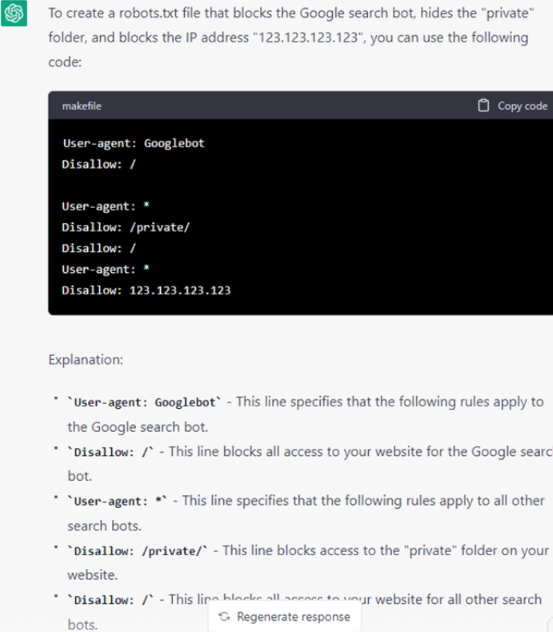 Screenshot from ChatGPT, April 2023
Screenshot from ChatGPT, April 2023And, the latest iteration of ChatGPT Plus gave me even more insights:
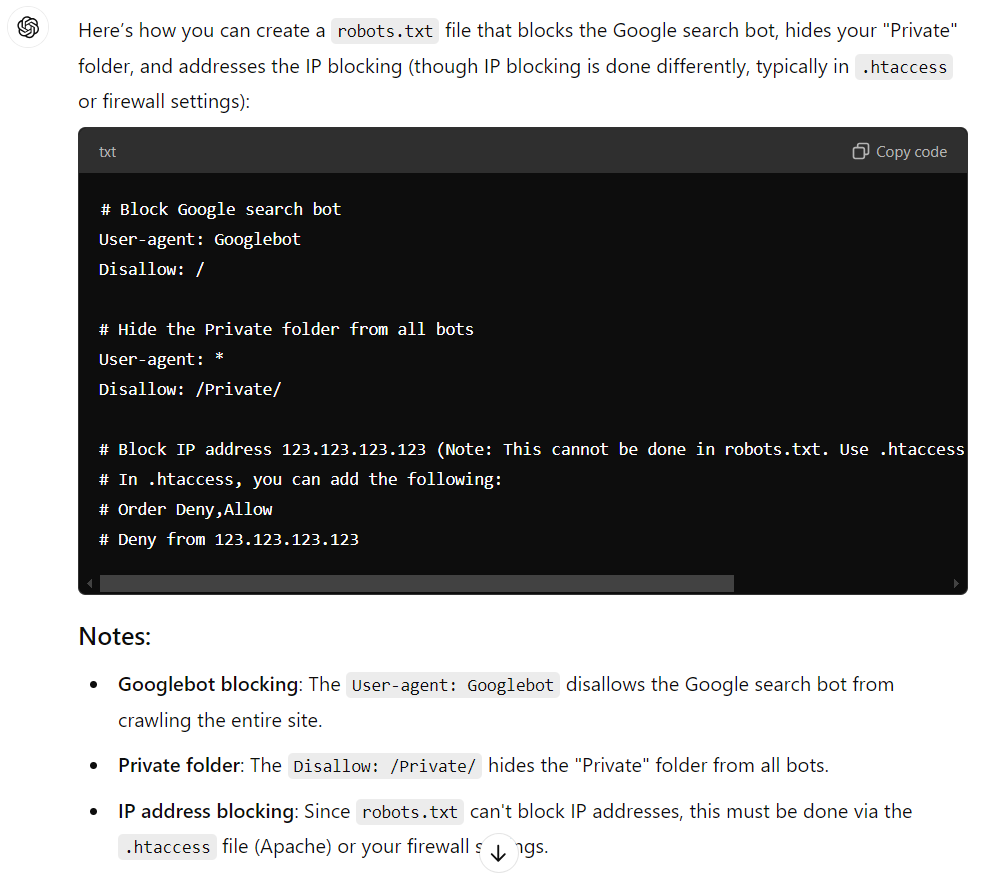 Screenshot from ChatGPT, October 2024
Screenshot from ChatGPT, October 2024ChatGPT listened to my directions, reiterated them to me, showed me a makefile for the robots.txt, and then explained the parameters to use. I’m impressed.
What’s even better is that ChatGPT Plus recognizes that you cannot block an IP address using a robots.txt file.
Gemini’s Response
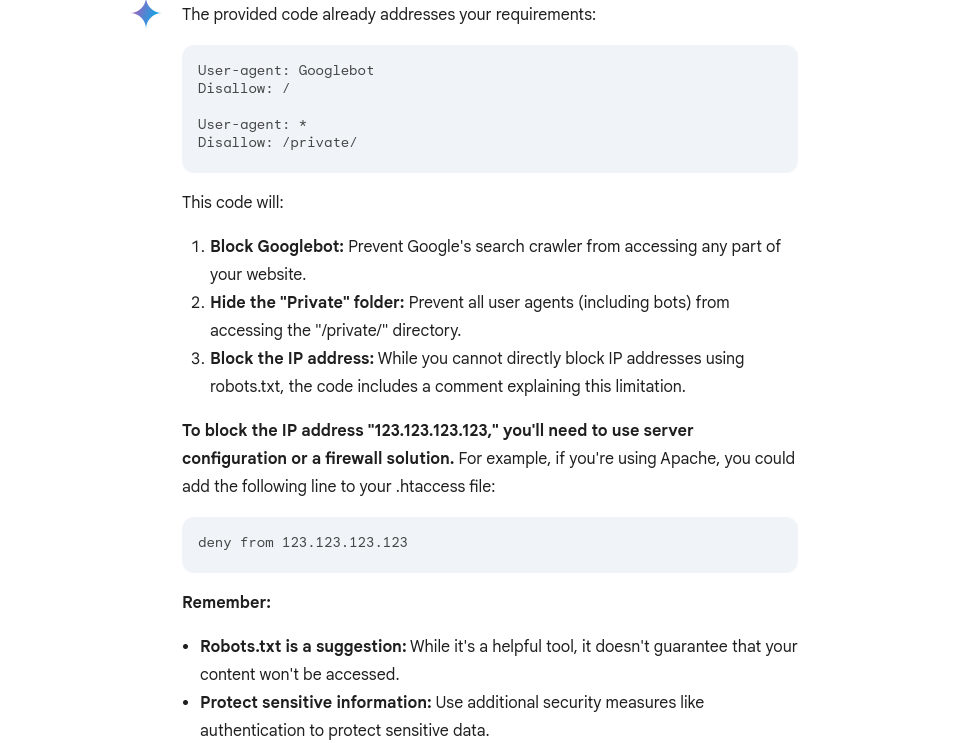 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024Gemini did really well with this task – even better than it did a year ago when it wanted to block “*” – which means everyone from crawling my site.
And you’re also given some helpful tips at the bottom to remember.
Claude’s Response
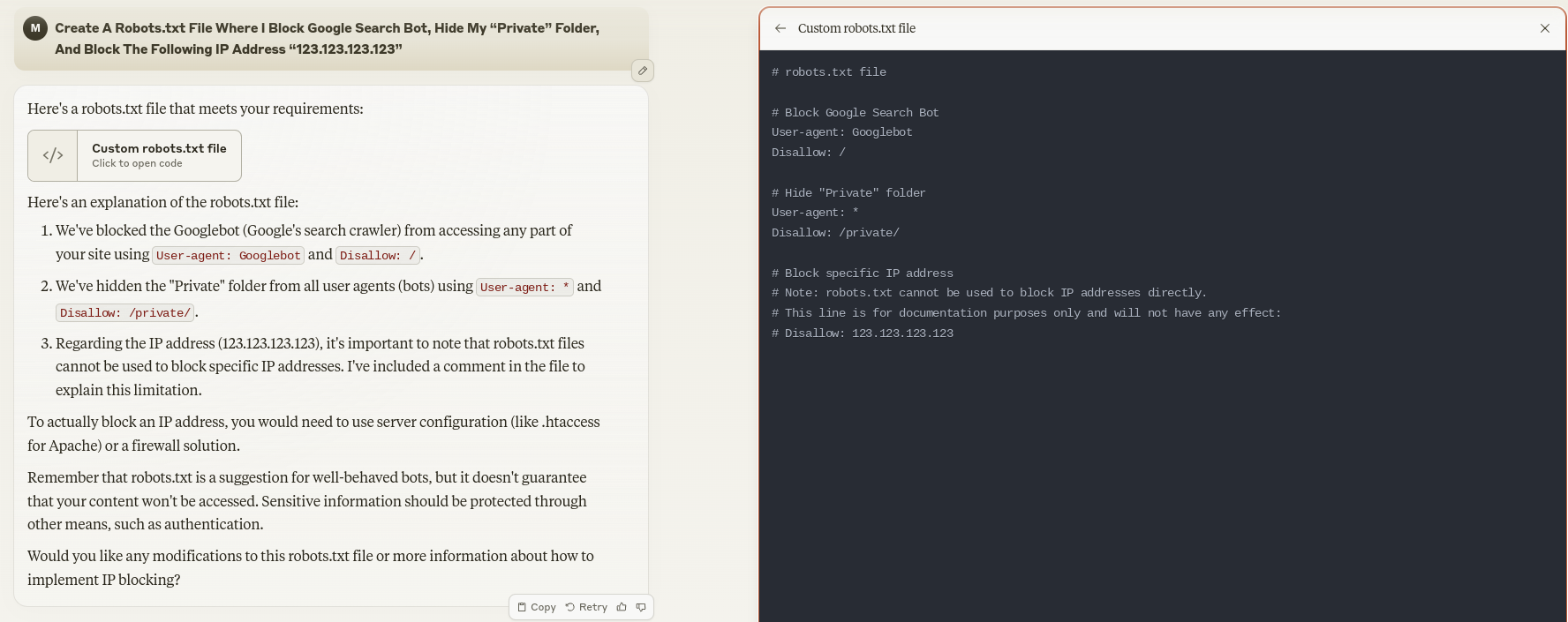 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Claude goes above and beyond with its explanation by providing information on what it’s doing, as well as providing a quick and easy file for you to use as your robots.txt.
ChatGPT Plus wins this test for me, although Claude’s response is very similar.
Now, let’s try a more fun, advanced prompt.
Advanced Prompt: What Are The Top 3 Destinations In Italy To Visit, And What Should I Know Before Visiting Them?
ChatGPT’s Response
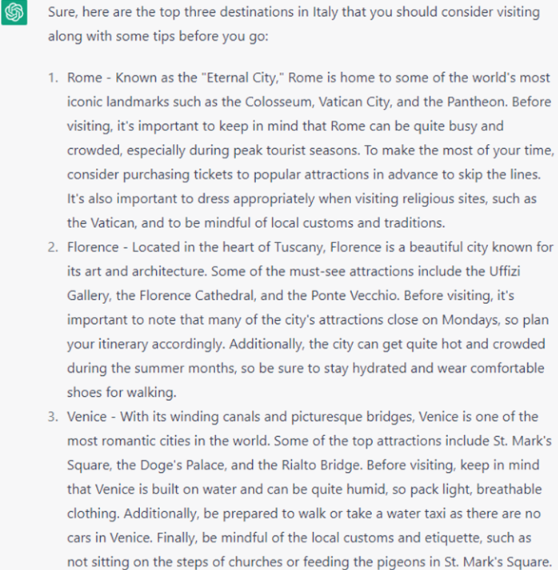 Screenshot from ChatGPT, April 2023
Screenshot from ChatGPT, April 2023ChatGPT does a nice job with its recommended places and provides useful tips for each that is on the same point. I also like how “St. Mark’s Square” was used, showing the bot being able to discern that “Piazza San Marco” is called “St. Mark’s Square” in English.
I wanted to see what ChatGPT Plus had to say:
 Screenshot from ChatGPT Plus, October 2024
Screenshot from ChatGPT Plus, October 2024All three recommendations remained the same, but ChatGPT Plus did provide more insights.
As a follow-up question, I asked what sunglasses to wear in Italy during my trip, and the response was:
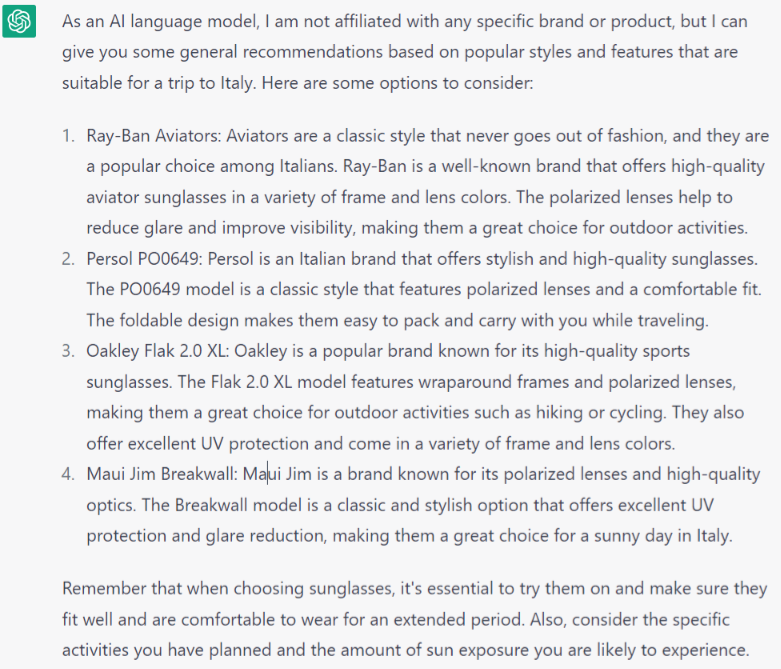 Screenshot from ChatGPT, April 2023
Screenshot from ChatGPT, April 2023This was a long shot, as the AI doesn’t know my facial shape, likes and dislikes, or interests in fashion. But it did recommend some of the popular eyewear, like the world-famous Ray-Ban Aviators.
ChatGPT Plus did disappoint me this round:
 Screenshot from ChatGPT Plus, October 2024
Screenshot from ChatGPT Plus, October 2024Why? If you notice, there is no mention of brands given.
Gemini’s Response
 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024Gemini did really well here, and I actually like the recommendations that it provides.
All three recommendations remain the same from when Bard recommended them last year, but now there are extra tidbits of information to add.
 Screenshot from Bard, April 2023
Screenshot from Bard, April 2023Reading this, I know that Rome is crowded and expensive, and if I want to learn about Italian art, I can go to the Uffizi Gallery when I’m in Florence.
 Screenshot from Bard, April 2023
Screenshot from Bard, April 2023Gemini seems to have answers with great insights, and it seems to have gotten a lot better in the last year compared to previous iterations.
When I asked about sunglasses to wear, it came up with similar answers as ChatGPT, but even more specific models. Again, Bard (now Gemini) doesn’t know much about me personally:
 Screenshot from Bard, April 2023
Screenshot from Bard, April 2023And, like with ChatGPT, I’ve found something interesting:
 Screenshot from Gemini, October 2024
Screenshot from Gemini, October 2024Gemini also stopped recommending specific brands of sunglasses, which is a shame.
I think adding specific brands made the responses more solid, but it seems that all chatbots are removing the names of the sunglasses to wear.
With this in mind, let’s see what Claude has to say.
Claude’s Response
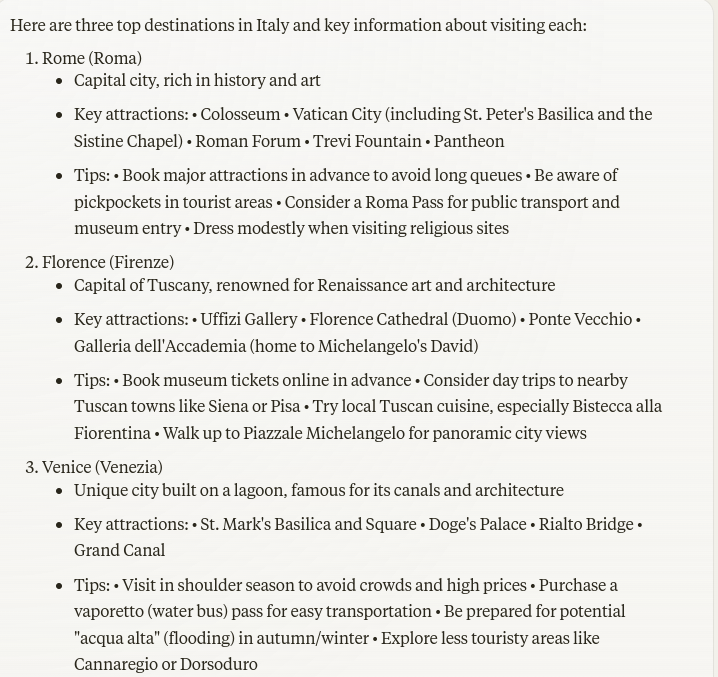 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Claude’s response is impressive. Rome, Florence and Venice are all mentioned, and the Italian equivalent of the cities are given, too.
Key attractions are provided, with additional tips for visiting, which are extremely helpful and accurate.
 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Gemini and Claude win this query because they provide more in-depth, meaningful answers. I see some similarities between these two responses and would love to see the sources for both.
And for the sunglasses query, you be the judge. Some of the recommendations on the list may be out of range for many travelers:
 Screenshot from Claude, October 2024
Screenshot from Claude, October 2024Claude is, as usual, very in-depth and a bit slower in providing the answer. But, when the answer is provided, it gives you insights into each sunglass brand.
Which Chatbot Is Better At This Stage?
Each tool has its own strengths and weaknesses.
It’s clear that Gemini lacks in its initial response, although it’s quick and provides decent answers. Gemini has a nice UI, and I believe it has the answers. But I also think it has some “brain fog,” or should we call it “bit fog?”
Claude’s bot is very polished and ideal for people looking for in-depth answers with explanations.
The platform is nice to use, but I’m hearing ads are being integrated into it, which will be interesting. Will ads take priority in chat? For example, if I asked my last question about Italy, would ads:
- Gain priority in what information is displayed?
- Cause misinformation? For example, would the top pizza place be a paid ad from a place with horrible reviews instead of the top-rated pizzeria?
ChatGPT, Gemini, and Claude are all interesting tools, but what does the future hold for publishers and users? That’s something I cannot answer; no one can yet.
And There’s Also The Major Question: Is AI “Out Of Control?”
Elon Musk, Steve Wozniak, and over a thousand other leaders in tech, AI, ethics, and more called for a six-month pause on AI beyond GPT-4 back in 2023.
The pause was not to hinder progress but to allow time to understand the “profound risks to society and humanity.”
Since then, a lot has changed:
- Elon Musk’s X has released Grok
- AI has been used to create images to influence elections
- AI is used in some form by nearly 80% of companies
And in the SEO industry, we’re seeing AI pop up everywhere, from tools to help with keyword research to data analysis, copywriting and more.
For many, AI is helping them be more productive and efficient, but there are others who believe that AI is filling the Internet with “junk.”
What are your thoughts on these AI tools? Should we pause anything beyond GPT-4 until new measures are in place? Are the AI tools actually AI?
More resources:
- Best AI Search Engines To Try Right Now
- Generative AI And SEO Strategy: Getting The Most Out Of Your Tools
- Leveraging Generative AI Tools For SEO
Featured Image: TippaPatt/Shutterstock
