

Patents show us what strategies Google chooses to research and invest in, which in turn provides insight into how to best prepare a website for indexation by Google.
However, reading a patent can sometimes be tricky as our assumptions may not be true and the patent itself may have not been used yet.
As Gary Illyes has said, some people take Google’s patents for granted. And then, there is just pure speculation about how internal search really works.
So, with that caveat, let’s see what information we can retrieve from the patent “Optimized web domains classification based on progressive crawling with clustering” (PDF).
The Patent
This patent proposes a mechanism to process and classify URLs using different crawling methods to obtain information about them.
Rather than classify each URL individually, thematic clusters of content are created and refined, and elements such as textual analysis and similar content topics are taken into account.
Thematic content clusters can then be published as answers to search queries, using different analytic techniques to determine and improve the cluster that best matches the query’s intent, according to the patent.
For SEO professionals, this is quite interesting, as it shows how machine learning can be used to understand the content of a website, and, consequently, suggest ways to ensure that the website’s topics and purpose are correctly picked up by search engines.
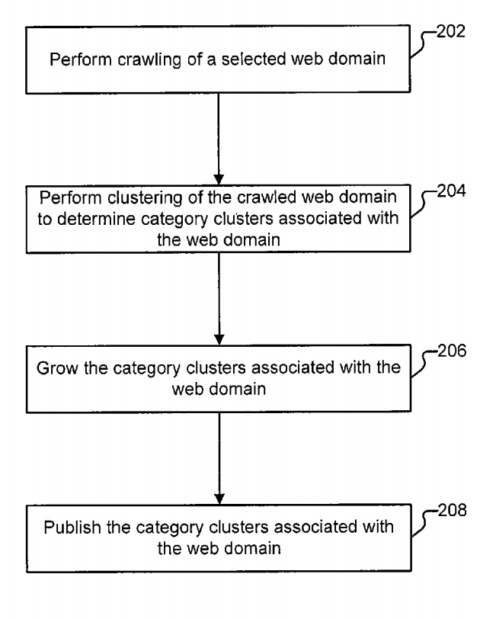 Procedure proposed by the patent
Procedure proposed by the patentThe Mechanism
The proposed URL processing mechanism is described as being composed of three parts:
- A crawler.
- A clusterizer.
- A publisher.
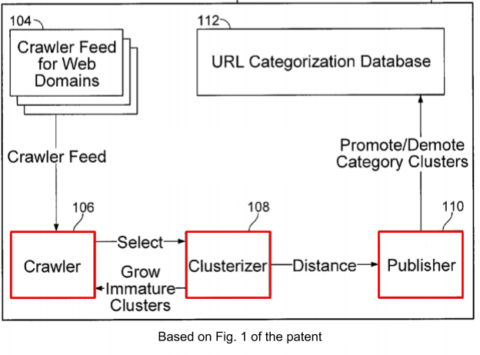 The proposed mechanism is composed of three parts
The proposed mechanism is composed of three parts1. Crawler
The crawler fetches the host (example.com), the subdomain (other.example.com), and the subdirectory (example.com/another).
We distinguish two types of crawl:
- Progressive crawling: Collects data from a subset of pages included in a cluster within a specific domain.
- Incremental crawling: Focuses on the additional pages within the known crawl frontier before fetching (as new pages can be discovered while crawling).
To avoid introducing any bias in the crawling process, the patent lists various techniques that may be used, including:
- Classifying crawled pages into one or more category clusters and then determining whether to publish those pages as results for one or more categories.
- Determining a sub entry point to randomly select the next page to be crawled using a selection algorithm that uses a knowledge base that can include past crawling data.
When no new hostnames are discovered, the crawl cycle functions like an infinite loop, constantly adjusting the probability that each classification of a page is correct.
This tells us that crawl behavior on a website serves purposes beyond the discovery of webpages. The cyclical nature of crawls required to determine the category of a page means that a page that is never revisited may not be considered by Google to be useful.
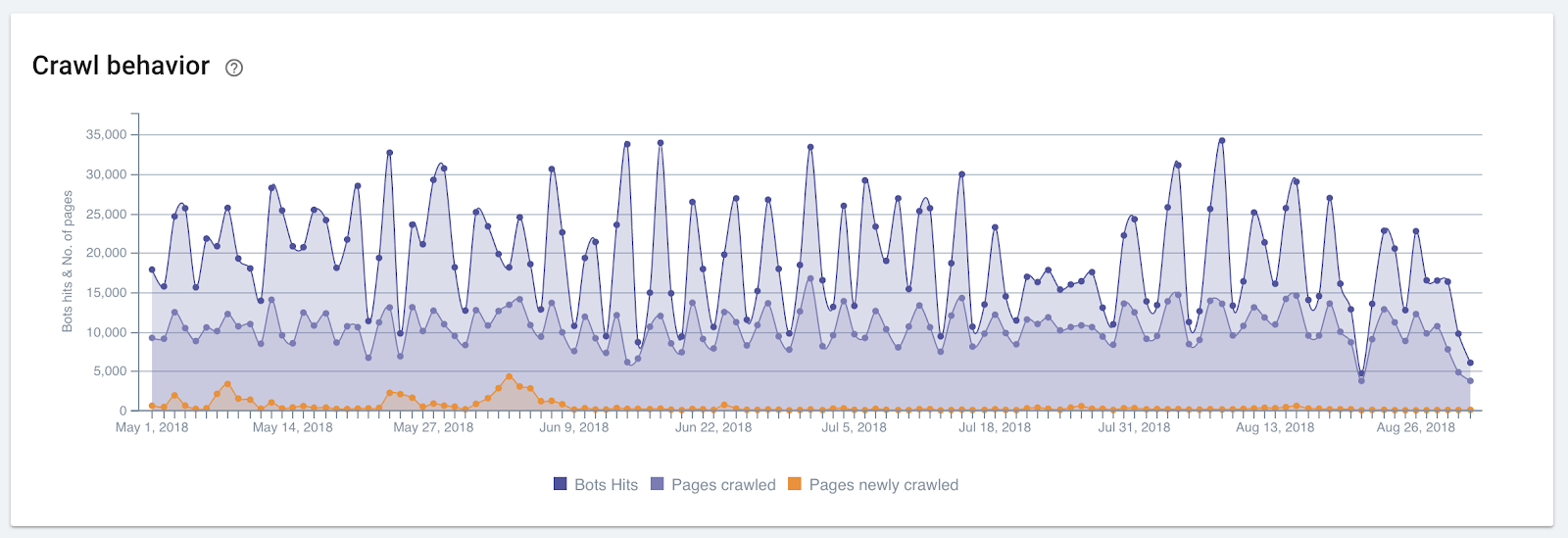 Examining crawl behavior
Examining crawl behavior2. Clusterizer
The role of the clusterizer is to add pages to clusters until the cluster is mature or until there are no new pages to classify.
- Mature clusters: A cluster is considered to be mature when the cluster’s category is reasonably certain. This can happen when certain thresholds are met, or when different clusters containing the same URL are classified identically.
- Immature clusters: A cluster is considered immature when the requirements above are not met.
The classification of a cluster as mature or immature converges when no new hostnames are discovered. This expiration period is extended with the discovery of new URLs. It is also weighted based on a confidence level derived from the cluster’s rate of growth.
The notion of clusters goes far beyond determining in which cluster a specific page may belong. Clusters correspond to website intentions, or aims. Consequently, clustering produces:
- Primary clusters: Twitter.com belongs to a social cluster, and its aim is barely known.
- Secondary clusters: The jobs section of LinkedIn is a sub-cluster belonging to a job cluster, inside the primary social cluster.
- Geographic clusters: Depending on the subscriber location, a specific clusterization can be applied depending on different variables such as the type of business, policy requirements, etc.
This means that search intent, whether informational (looking for a job), navigational (finding the website of a local business), or transactional (shopping for shoes), can play an increasingly important role: clusters and sub-clusters identify and group URLs that meet these sorts of intentional queries.
As clusters are composed of related content, an analysis of a website using algorithmic means can indicate the probability of relevant clustering on the website and help predict where additional content can encourage cluster growth and increase the number of mature clusters.
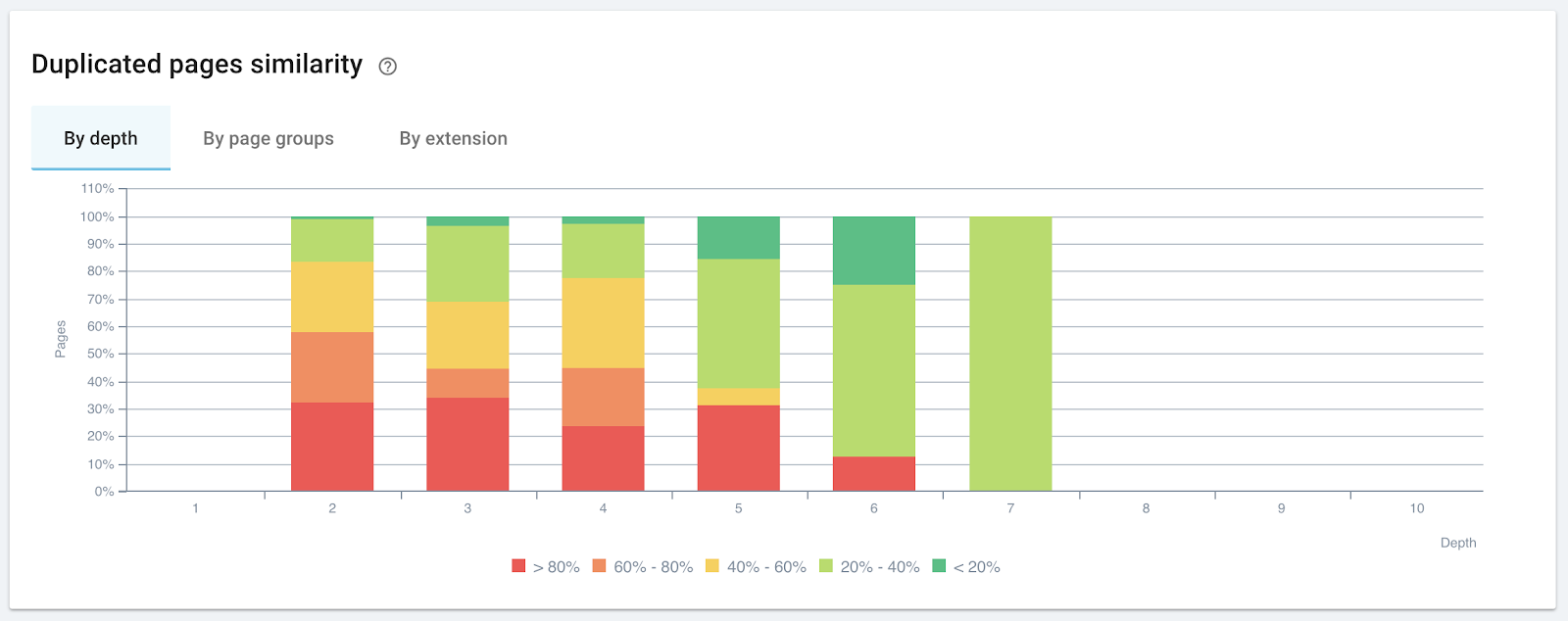 Analyzing related content: rates of similarity by page depth
Analyzing related content: rates of similarity by page depth3. Publisher
The publisher is the gateway to SERP content. “Publishing” is used to mean various techniques to approve, reject, or adjust clusters:
- K-means clustering algorithm: The aim here is to find groups that are related but have not been explicitly labeled as related in the data. In the case of content clusters, each paragraph of text will form a centroid. Every correlated centroid will then be grouped together.
- Hierarchical clustering algorithm: This refers to a similarity matrix for the different clusters. The matrix finds the closest pair of clusters to merge, so the number of clusters tends to reduce. This logic can be repeated as many times as necessary.
- Natural Language Processing (such as textual analysis): Though NLP isn’t new, this method of analysis has gotten a lot of recent attention. It consists of classifying documents using over 700 common entities.
- Bayes verifications: These refer to a method of classifying a questionable input (often a signature, but in this case a URL) as a matching or unrelated topic. Confirming a matching URL means comparing every known URL in the cluster to each other to obtain a close distribution. Unrelated means having to place the questionable new URL further from the others, to obtain different distribution. A matching result indicates a mature cluster and an unrelated result signals an immature cluster.
- Bayes classifier: This is used to minimize the risk of misclassification. The Bayes classifier determines a probability of error T. As this T function may vary according to the kind of error, the classifier determines the exchange rate.
The system uses these different techniques to adjust the clusters. It tries to understand the concept, or theme, of the pages in the cluster and then to evaluate whether the cluster may be able to answer search queries.
The number of techniques and deeper analysis make it difficult to take advantage of the system using older strategies like keyword placement and keyword stuffing.
On the other hand, classic technical SEO audits are vital to allow Google access to a maximum quantity of useable data.
 Running a technical SEO audit
Running a technical SEO auditThe Implications for SEO
Here are the main points to keep in mind:
- Pages can be part of multiple clusters, and clusters can be associated with multiple categories.
- The crawl schema can be carried out using past crawling data.
- Larger numbers of pages on a similar topic tend to mature a cluster.
- Clusters can move from one status to another as new URLs are discovered. (This patent about crawl scheduling is worth a read.)
- Several clusters will likely exist for the same domain, as a domain can contain multiple business and service aims. Clusterization is also influenced by geographic location.
- The publisher determines if a cluster can be promoted to its greatest coverage: that is, as an answer on the SERPs.
This reinforces the current understanding that search intent and the existence of multiple pages of content on a given theme can be used by Google to determine whether to present a website as a good response to a search query.
Whether or not this patent’s mechanism is used, it shows that Google researches and invests in methodologies like the ones we’ve examined here.
So, what valuable and hopefully actionable information can we retrieve from this patent?
Monitor Crawl Behavior
Google’s crawl of a URL is not just used to discover a page or to see if it has changed. It can also be used to classify URLs by intent and topic, and refine the probability that a URL is a good match for a given search. Therefore, monitoring crawl behavior can reveal correlations to search rankings.
Include Semantic Analysis
The categorization of web pages is based on the similarity between the words that form the concepts on the page.
Here, using techniques such as NLP to analyze pages can be useful for grouping pages based on their relations and entities.
Encourage Content Strategies Around Topic Hubs
Creating pages on the same topic will grow a cluster to maturity and thus help promote the pages on the SERPs.
In other words, related content on a given topic can be advantageous, because it increases the probability that a categorization is correct, and allows a cluster to be made available as an answer to search queries.
More Resources:
- What Are Entities & Why They Matter for SEO
- Google’s Site Quality Algorithm Patent
- PageRank Patent Update – How it Impacts SEO
Image Credits
In-Post Images #1-2: Screenshots taken by author, February 2019
In-Post Images #3-5: Oncrawl
