

When it comes to semantic analysis and how search engines deal with text, there has been a lot of theories thrown about the last while. From our long past in LSI snake-oil, to the more recent LDA fiasco, it seems SEOs are trying to get their collective heads around it.

Back in May, here on SEJ, (ooo look! I’m lyrical) I was discussing this very thing (semantic analysis) with the post; Understanding Semantic Search and SEO. What’s important to remember is that there are many ways a search engine might analyze your content.
And today we’re going to look at another one.
The Patent
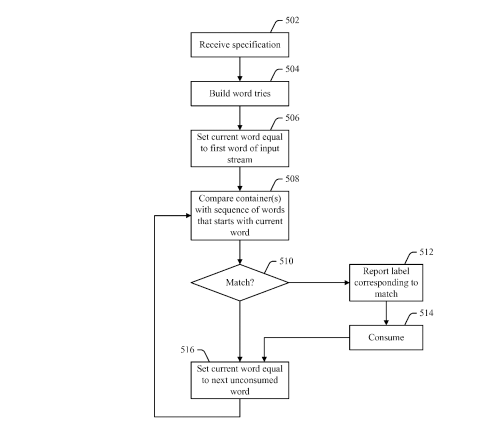
Text Analysis Using Phrase Definitions and Containers
Filed March 24th 2009 – Awarded Sept. 30Th 2010
Inventor; Umesh Madan
One of the more interesting things we come across fairly early on, was the mention of a few things;
- Using the system for both query and document analysis
- Use of synonyms (library) not as common in other approaches.
- Use in detecting/dealing with misspellings
- Feature extraction for classifying objects (e.g “Joe is a lawyer”)
- Utilizing ‘and’ ‘or’ combinations for related classifiers
Much of their approach, in this filing, seems to be quite relative to what we’ve seen in past looks at approaches such as phrase based IR (Google). Some of the points mentioned above, are what seems to be somewhat different. They seem to propose using this across a variety of purposes including search document matching, lemmatization (variants of same word), spell checking/correction and related text analysis.
They really seem to make no distinctions as to input types, which they refer to as the ‘input stream‘. This means using (for our purposes) the system to analyze both the documents in the index and the query being entered to find the information. I found this somewhat interesting as a lot of time semantic analysis, past phrase based approaches in particular, tend to be more focused on the indexing/ranking side of things.
Classifying the terms
Classifier dictionaries can include phrase specifications and words/phrases that are synonymous. They can also be used for pattern matching;
“For example, in a health search application, a pattern matching rule might specify that a pattern to be found is the name of a disease combined with the name of a drug. ”
“...data expressions 108 may contain a list of phrases that are disease names and another list of phrases that are drug names. Then code expressions 110 may include a container specifying that a pattern to be found is a sequence of words that include a term from the list of disease names and a term from the list of drug names.”
This can be used to label concepts, in this example, ‘medical condition‘ and ‘medical treatment‘. This is an interesting approach and at first glance, seems that it may be a bit problematic from the processing side of things. Unlike the Google approach, this one would have a more on-the-fly approach based from existing classifications, not an analytic approach from a given training set.
The go on to describe 3 areas;
- Phrase sets – related terms/concepts
- Map sets – misspellings
- Equivalent – common spelling variations
Why do I keep getting the feeling this is a catch-all for not only search, but word processors as well? Meh. Just paranoid.
The AND / OR connection
The also talk about using ‘containers’ that are defined as;
- “And” container seeks to find two (or more) related concepts
- “Or” container looks for one or more instances.
- “All” container matches ALL the phrases (from the input) which is more common for query analysis
- “List” container is more of an extended ‘OR’ but would search the full input, not just stopping at the first occurrence.
- Repeat” container would refine or expand other containers. Good for multiple instances of a phrase (more content analysis)
- “Switch” container can substitute semantic equivalents in line with other containers.
- “Wildcard” container can be used to classify words between the desired phrases. Ie; “Disease name” “wild card term” “Drug Name” – without the WC, the match would fail.
They also talk about creating custom containers for elements such as;
“If Found(“Drug”) and (Position(“Drug”)-Context.CurrentPosition)<5, then . . . “,
or
“if (Drug near “INDICATOR”) then . . . .”
It’s all very compartmentalized, that’s for sure. There isn’t much discussion on where the ‘dictionaries‘ are being created or what, if any, training documents are involved. I have to say, other than being about phrases, there is little in common with this approach compared to Google’s.
How does Bing stack up?
As I have already noted, it is uncertain where the data sets for the analysis are being derived. They do mention ”dictionaries”, but that seems to imply their own, not traditional ones. This is where the real meat is IMO as it is where this method lives and dies. Some other missing pieces included;
- There is no mention of user feedback
- There is no mention of (post) query analysis
- A scoring/ranking process to pull this all together
That being said, given what short time I’ve had to mull it over, I do like the proposed system of ‘containers’ if only it wasn’t bloated and process hostile in the end product. The analysis approach is most certainly an interesting one.
We can also see that they do, at times, start to mix words not only phrases into the approach. Some examples given seemed to be cobbling ‘phrases’ together from separate words in the stream. Ultimately the scoring comes from the system properly analyzing the query and then seeking out the defined terms using the container models.
When I say there is no scoring system, what I mean is beyond the obvious. Yes, this would find ‘best matches‘, but there is no real tie breaker if you will. This score could obviously just be added to other scoring mechanisms (links, meta data, geo data, contextual etc..), just seems light. But hey, maybe that’s what keeps it from getting bloated.
Google does it better
And what of ‘related phrases’? Not to harp on the Google approach, but using the system to learn more related phrases to a given concept, seems a logical approach to this under-educated beer jockey. In the past Microsoft, oddly enough, had more latent semantic papers/patents than Google ever did. Makes we wonder about the final destination for this offering.
It doesn’t seem tailored to set out to find concepts and meanings as much as it is about pure phrase matching. Is that a bad thing? No, not at all. We must never look at these in a vacuum, Microsoft has more than a few patents on semantic analysis the last while;
We can only take this for what it is. How the parts are integrated makes the end result. Maybe next time, we shall take a look how well each of them handle relevance through semantic analysis via SERP analysis. It would make for an interesting ride.
Final Analysis
At the end of the day I was left wondering if some of the major differences in approaches (from Google to Microsoft/Bing) had something to do with the seemingly varied results the two engines produce. As noted, I’ve not really done a lot of research into how they’re prducing relevance signals, but from what I have read over the years, they do seem to be taking different routes in semantic analysis, that’s for sure.
If you are seriously targeting Bing and by extension Yahoo, (worth considering), I’d try and work out a program that satisfies both approaches. In reality, Google’s seems the more complicated. A Bing happy approach seems to be one of ensuring the core concepts are clear, early in the content/page and strongly targeted at the ‘right’ user approach, in-line with KW research.
That’s just gut instinct though. I really will have to find some time to cobble together more filings to get a clearer picture. Does anyone care? If so, please do sound off in the comments.