

JavaScript (JS) is extremely popular in the ecommerce world because it helps create a seamless and user-friendly experience for shoppers.
Take, for instance, loading items on category pages, or dynamically updating products on the site using JS.
While this is great news for ecommerce sites, JavaScript poses several challenges for SEO pros.
Google is consistently working on improving its search engine, and a big part of its effort is dedicated to making sure its crawlers can access JavaScript content.
But, ensuring that Google seamlessly crawls JS sites isn’t easy.
In this post, I’ll share everything you need to know about JS SEO for ecommerce and how you can improve your organic performance.
Let’s begin!
How JavaScript Works For Ecommerce Sites
When building an ecommerce site, developers use HTML for content and organization, CSS for design, and JavaScript for interaction with backend servers.
JavaScript plays three prominent roles within ecommerce websites.
1. Adding Interactivity To A Web Page
The objective of adding interactivity is to allow users to see changes based on their actions, like scrolling or filling out forms.
For instance: a product image changes when the shopper hovers the mouse over it. Or hovering the mouse makes the image rotate 360 degrees, allowing the shopper to get a better view of the product.
All of this enhances user experience (UX) and helps buyers decide on their purchases.
JavaScript adds such interactivity to sites, allowing marketers to engage visitors and drive sales.
2. Connecting To Backend Servers
JavaScript allows better backend integration using Asynchronous JavaScript (AJAX) and Extensible Markup Language (XML).
It allows web applications to send and retrieve data from the server asynchronously while upholding UX.
In other words, the process doesn’t interfere with the display or behavior of the page.
Otherwise, if visitors wanted to load another page, they would have to wait for the server to respond with a new page. This is annoying and can cause shoppers to leave the site.
So, JavaScript allows dynamic, backend-supported interactions – like updating an item and seeing it updated in the cart – right away.
Similarly, it powers the ability to drag and drop elements on a web page.
3. Web Tracking And Analytics
JavaScript offers real-time tracking of page views and heatmaps that tell you how far down people are reading your content.
For instance, it can tell you where their mouse is or what they clicked (click tracking).
This is how JS powers tracking user behavior and interaction on webpages.
How Do Search Bots Process JS?
Google processes JS in three stages, namely: crawling, rendering, and indexing.
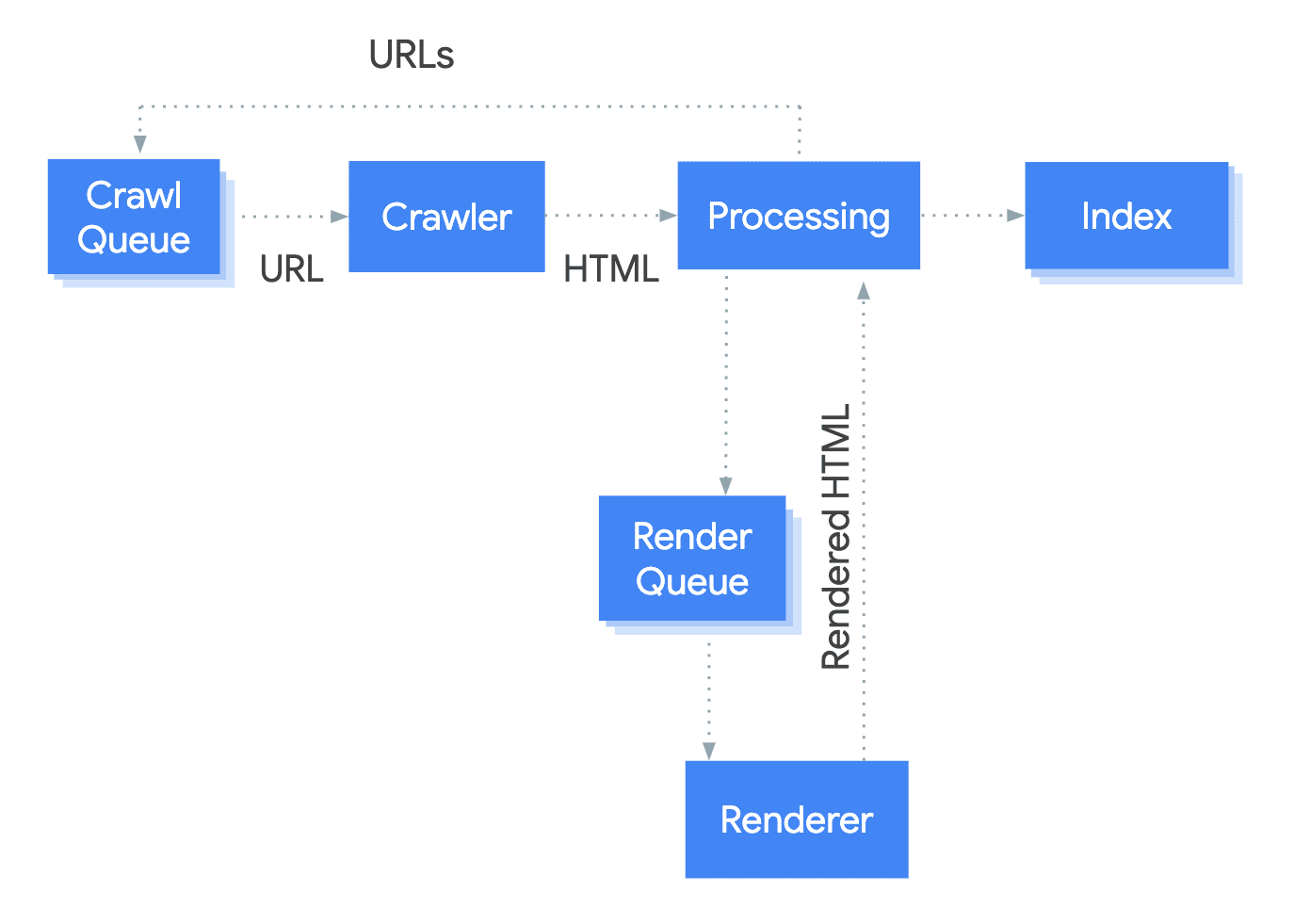
As you can see in this image, Google’s bots put the pages in the queue for crawling and rendering. During this phase, the bots scan the pages to assess new content.
When a URL is retrieved from the crawl queue by sending an HTTP request, it first accesses your robots.txt file to check if you’ve permitted Google to crawl the page.
If it’s disallowed, the bots will ignore it and not send an HTTP request.
In the second stage, rendering, the HTML, CSS, and JavaScript files are processed and transformed into a format that can be easily indexed by Google.
In the final stage, indexing, the rendered content is added to Google’s index, allowing it to appear in the SERPs.
Common JavaScript SEO Challenges With Ecommerce Sites
JavaScript crawling is a lot more complex than traditional HTML sites.
The process is quicker in the case of the latter.
Check out this quick comparison.
| Traditional HTML Site Crawling | JavaScript Crawling | ||
| 1 | Bots download the HTML file | 1 | Bots download the HTML file |
| 2 | They extract the links to add them to their crawl queue | 2 | They find no link in the source code because they are only injected after JS execution |
| 3 | They download the CSS files | 3 | Bots download CSS and JS files |
| 4 | They send the downloaded resources to Caffeine, Google’s indexer | 4 | Bots use the Google Web Rendering Service (WRS) to parse and execute JS |
| 5 | Voila! The pages are indexed | 5 | WRS fetches data from the database and external APIs |
| 6 | Content is indexed | ||
| 7 | Bots can finally discover new links and add them to the crawl queue |
Thus, with JS-rich ecommerce sites, Google finds it tough to index content or discover links before the page is rendered.
In fact, in a webinar on how to migrate a website to JavaScript, Sofiia Vatulyak, a renowned JS SEO expert, shared,
“Though JavaScript offers several useful features and saves resources for the web server, not all search engines can process it. Google needs time to render and index JS pages. Thus, implementing JS while upholding SEO is challenging.”
Here are the top JS SEO challenges ecommerce marketers should be aware of.
Limited Crawl Budget
Ecommerce websites often have a massive (and growing!) volume of pages that are poorly organized.
These sites have extensive crawl budget requirements, and in the case of JS websites, the crawling process is lengthy.
Also, outdated content, such as orphan and zombie pages, can cause a huge wastage of the crawl budget.
Limited Render Budget
As mentioned earlier, to be able to see the content loaded by JS in the browser, search bots have to render it. But rendering at scale demands time and computational resources.
In other words, like a crawl budget, each website has a render budget. If that budget is spent, the bot will leave, delaying the discovery of content and consuming extra resources.
Google renders JS content in the second round of indexing.
It’s important to show your content within HTML, allowing Google to access it.
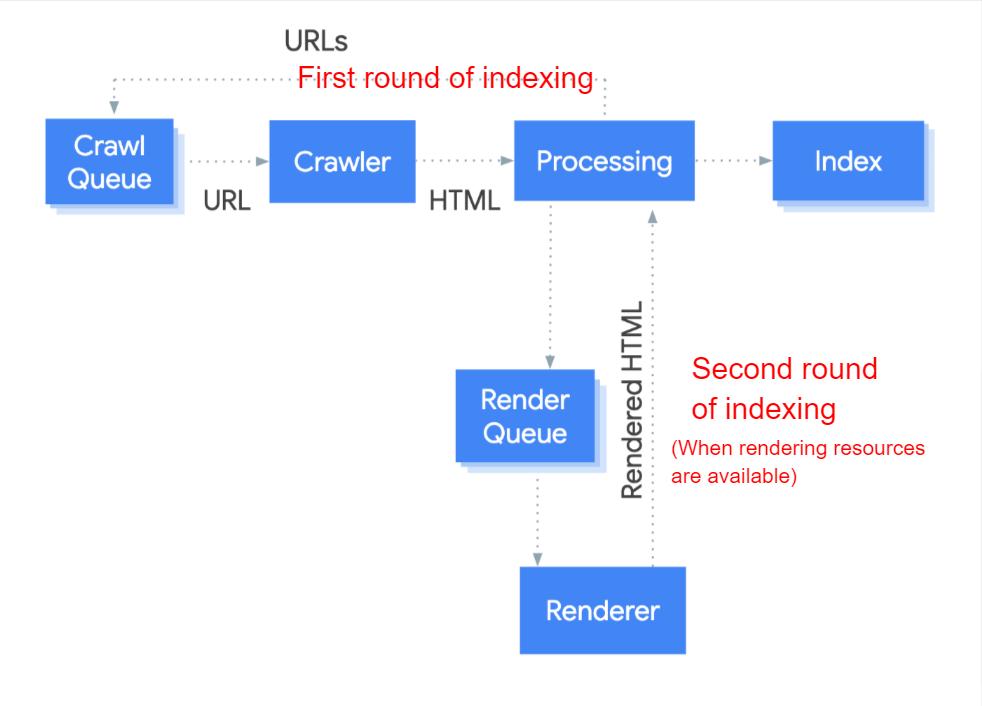
Go to the Inspect element on your page and search for some of the content. If you cannot find it there, search engines will have trouble accessing it.
Troubleshooting Issues For JavaScript Websites Is Tough
Most JS websites face crawlability and obtainability issues.
For instance, JS content limits a bot’s ability to navigate pages. This affects its indexability.
Similarly, bots cannot figure out the context of the content on a JS page, thus limiting their ability to rank the page for specific keywords.
Such issues make it tough for ecommerce marketers to determine the rendering status of their web pages.
In such a case, using an advanced crawler or log analyzer can help.
Tools like Semrush Log File Analyzer, Google Search Console Crawl Stats, and JetOctopus, among others, offer a full-suite log management solution, allowing webmasters to better understand how search bots interact with web pages.
JetOctopus, for instance, has JS rendering functionality.
Check out this GIF that shows how the tool views JS pages as a Google bot.
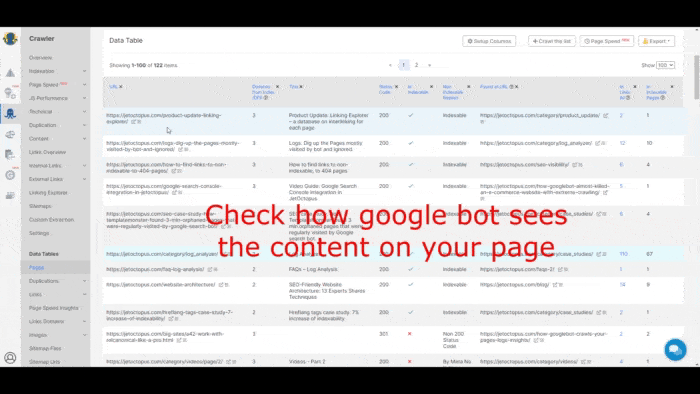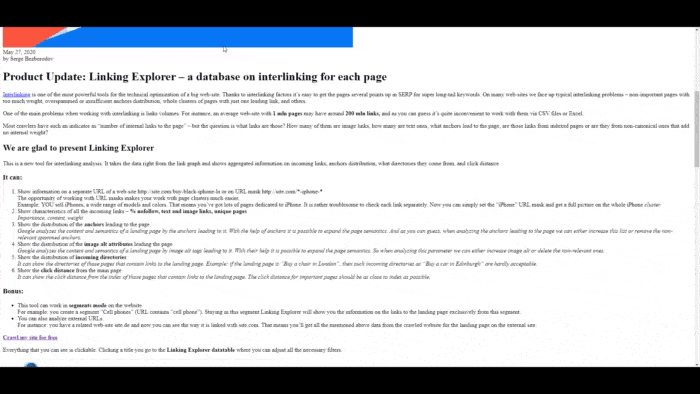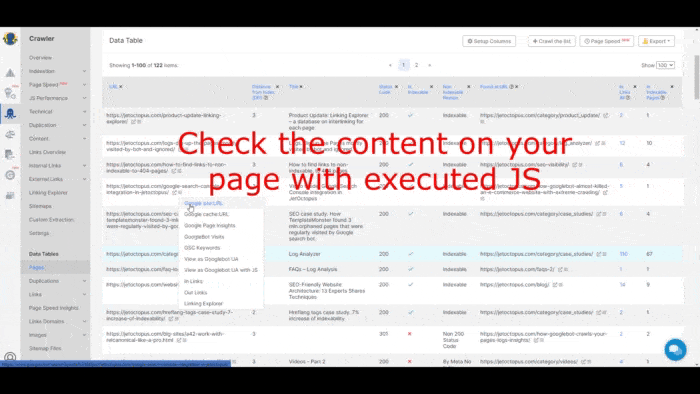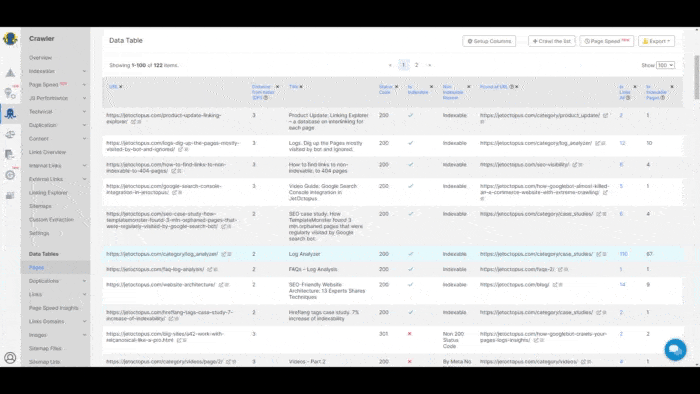
Similarly, Google Search Console Crawl Stats shares a useful overview of your site’s crawl performance.
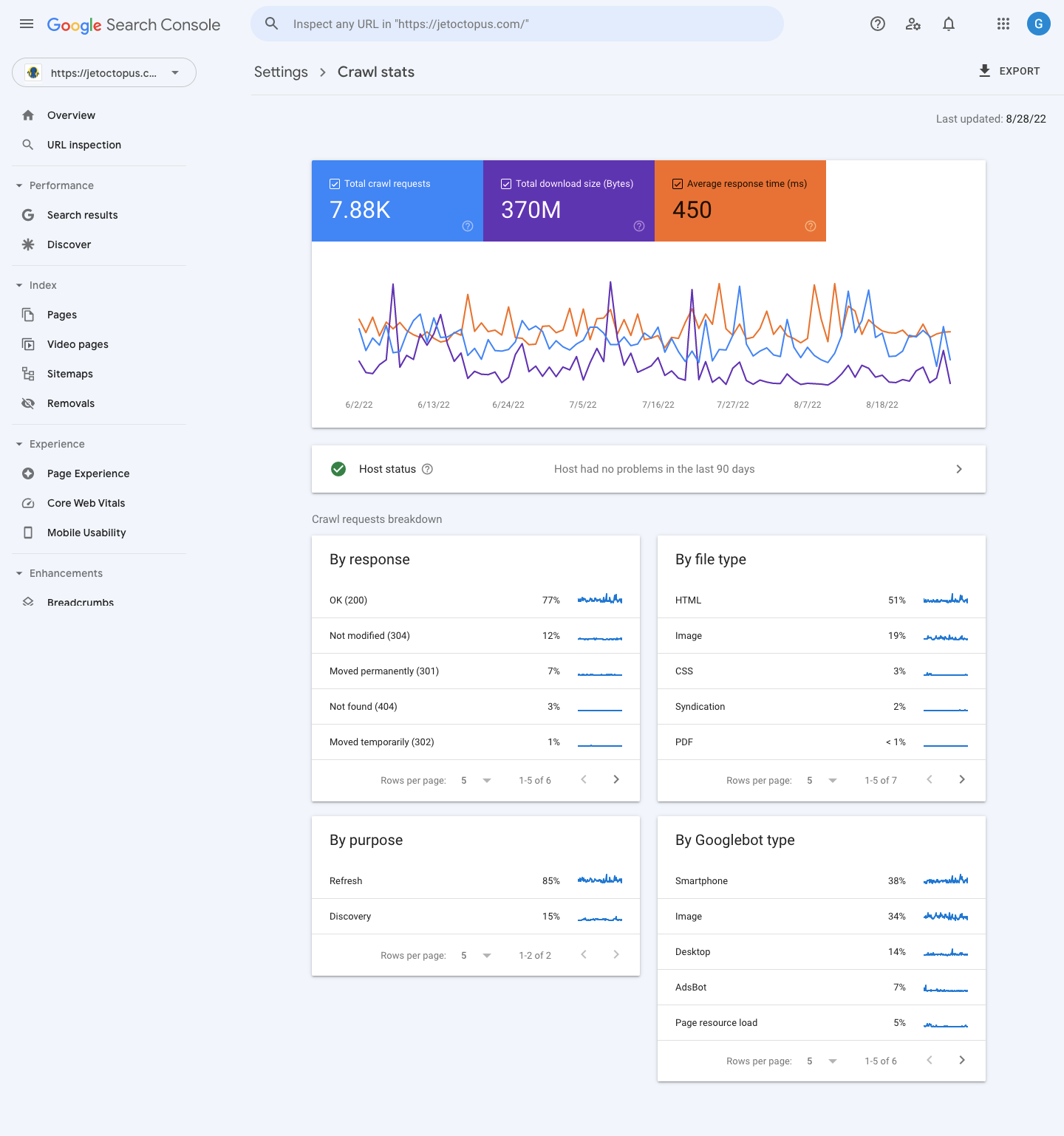
The crawl stats are sorted into:
- Kilobytes downloaded per day show the number of kilobytes bots download each time they visit the website.
- Pages crawled per day shows the number of pages the bots crawl per day (low, average, or high).
- Time spent downloading a page tells you the amount of time bots take to make an HTTP request for the crawl. Less time taken means faster crawling and indexing.
Client-Side Rendering On Default
Ecommerce sites that are built in JS frameworks like React, Angular, or Vue are, by default, set to client-side rendering (CSR).
With this setting, the bots will not be able to see what’s on the page, thus causing rendering and indexing issues.
Large And Unoptimized JS Files
JS code prevents critical website resources from loading quickly. This negatively affects UX and SEO.
Top Optimization Tactics For JavaScript Ecommerce Sites
1. Check If Your JavaScript Has SEO Issues
Here are three quick tests to run on different page templates of your site, namely the homepage, category or product listing pages, product pages, blog pages, and supplementary pages.
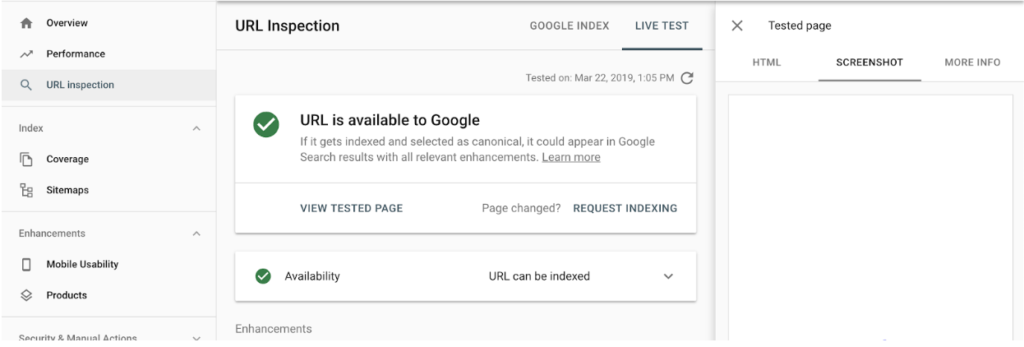
URL Inspection Tool
Access the Inspect URL report in your Google Search Console.

Enter the URL you want to test.
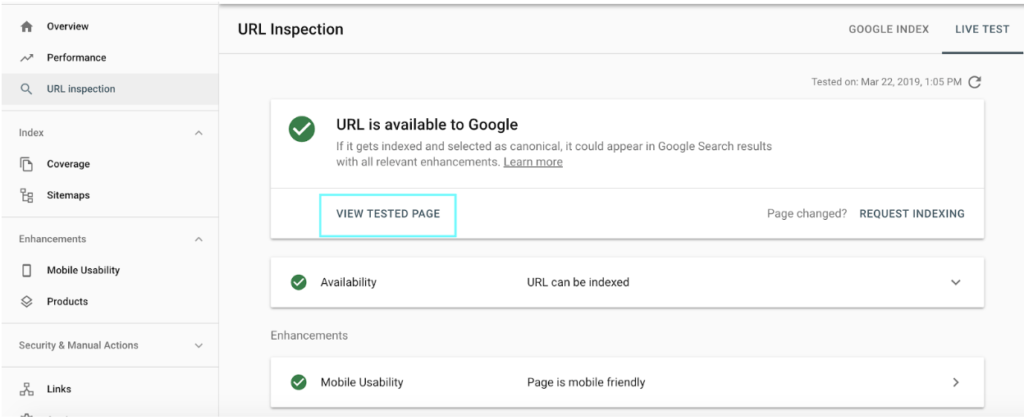
Next, press View Tested Page and move to the screenshot of the page. If you see this section blank (like in this screenshot), Google has issues rendering this page.
Repeat these steps for all of the relevant ecommerce page templates shared earlier.
Run A Google Search
Running a site search will help you determine if the URL is in Google’s index.
First, check the no-index and canonical tags. You want to ensure that your canonicals are self-referencing and there’s no index tag on the page.
Next, go to Google search and enter – Site:yourdomain.com inurl:your url
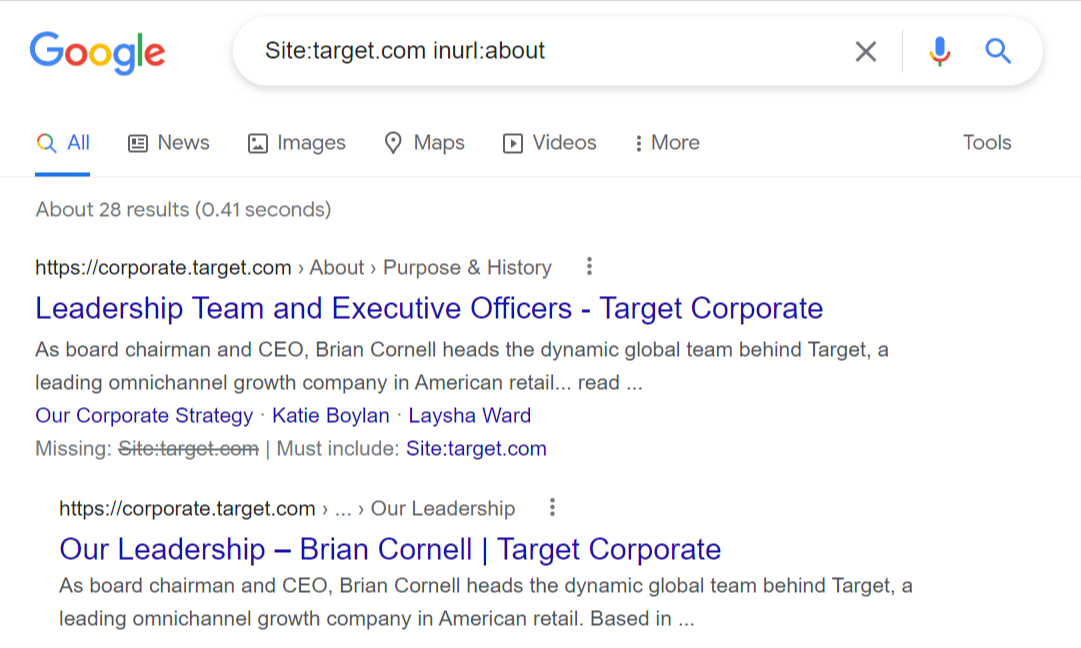
This screenshot shows that Target’s “About Us” page is indexed by Google.
If there’s some issue with your site’s JS, you’ll either not see this result or get a result that’s similar to this, but Google will not have any meta information or anything readable.
At times, Google may index pages, but the content is unreadable. This final test will help you assess if Google can read your content.
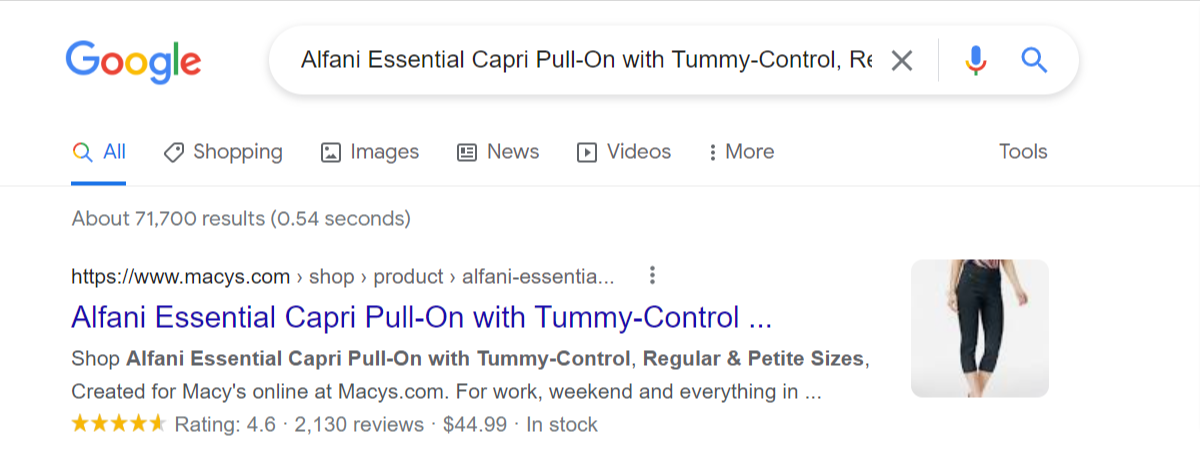
Gather a bunch of content from your page templates and enter it on Google to see the results.
Let’s take some content from Macy’s.
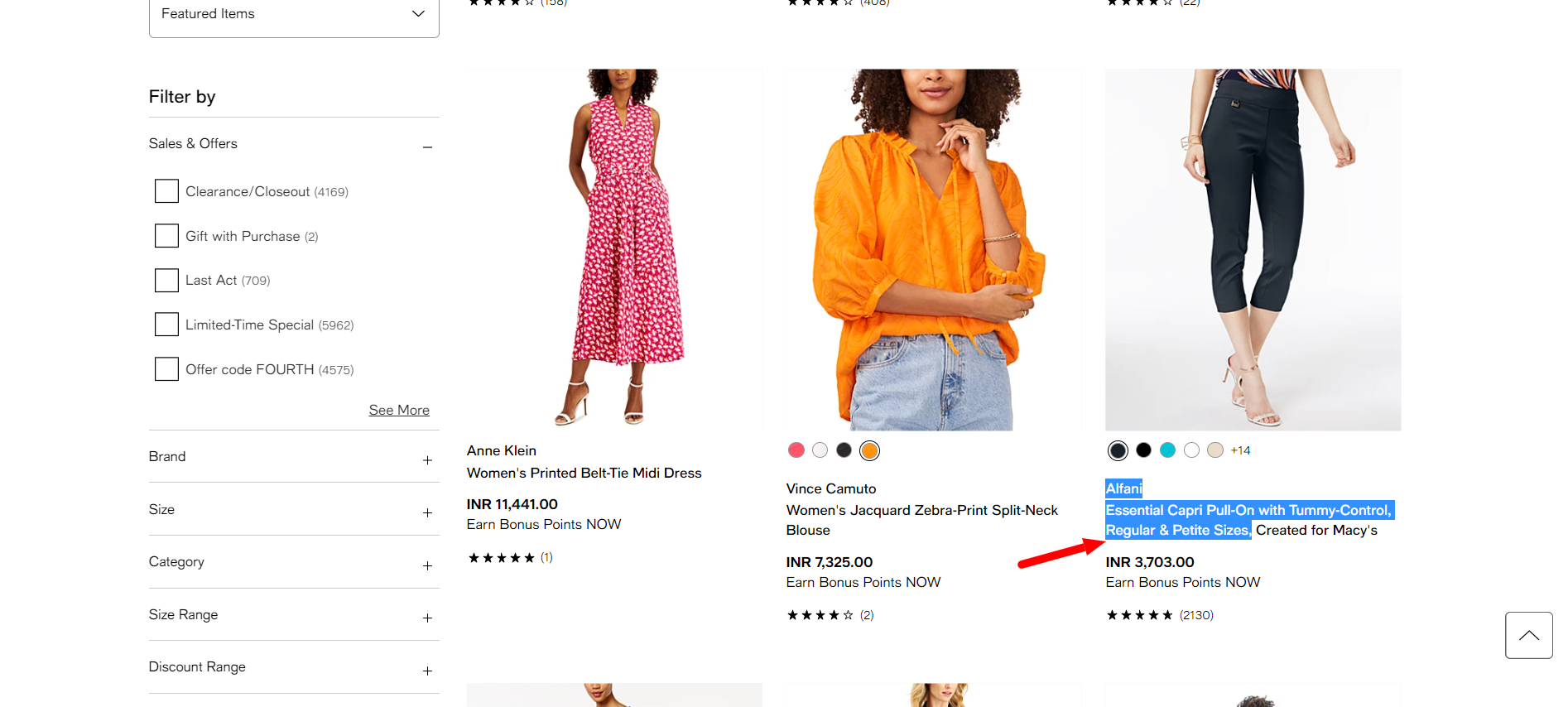
Screenshot from Macy’s, September 2022
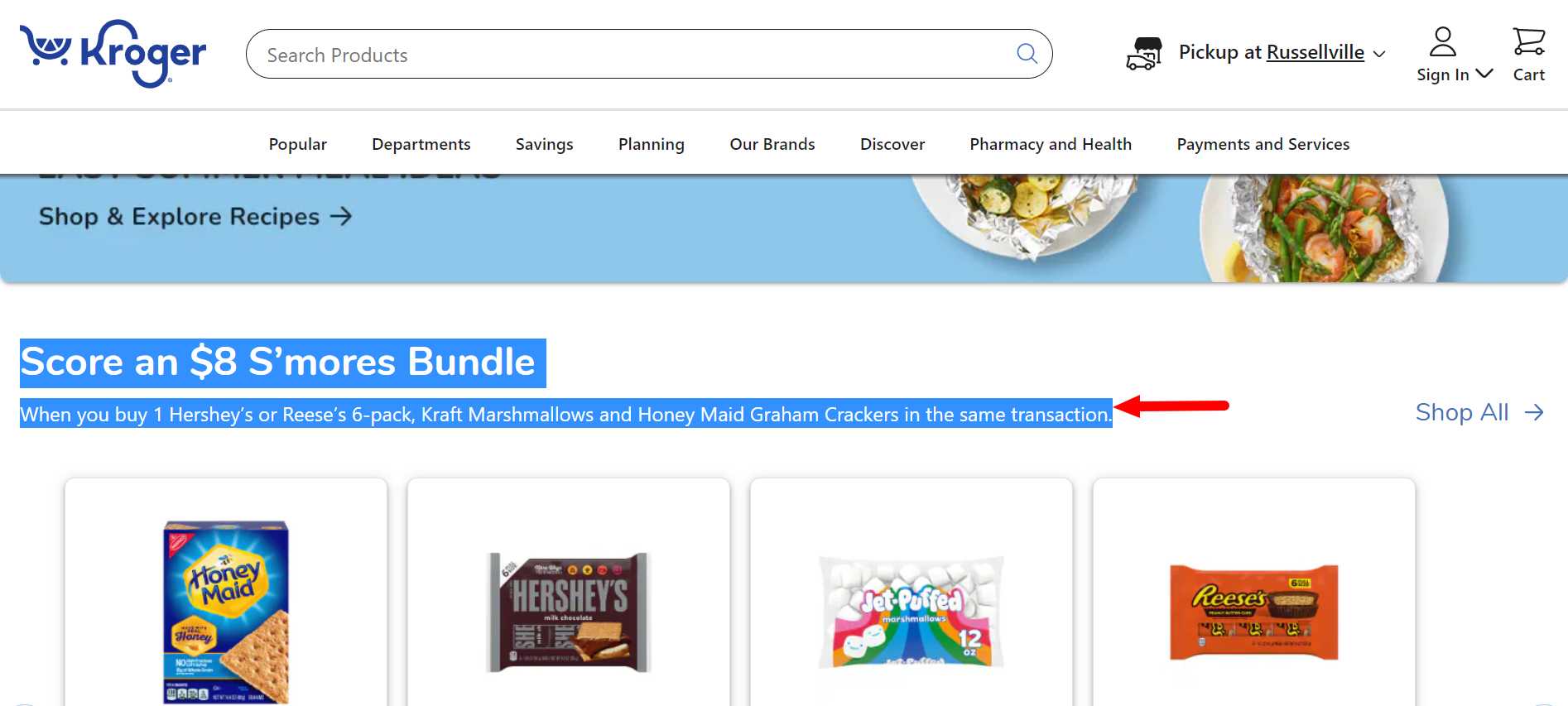
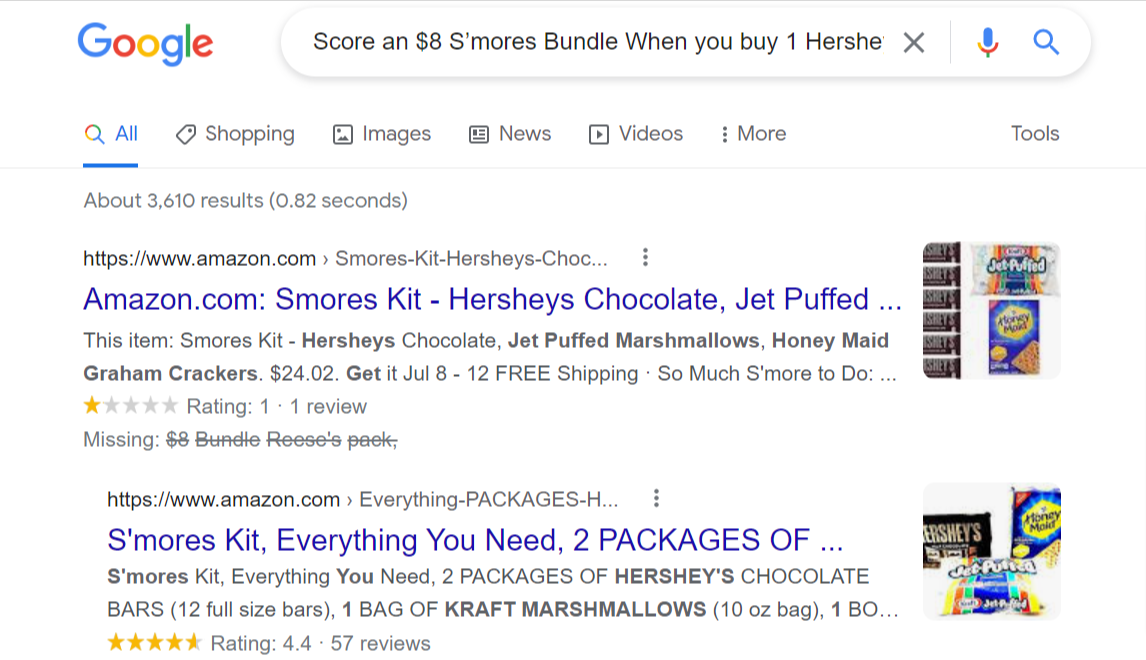
But check out what happens with this content on Kroger. It’s a nightmare!
Follow these tests with a detailed JS website audit using an SEO crawler that can help identify if your website failed when executing JS, and if some code isn’t working properly.
For instance, a few SEO crawlers have a list of features that can help you understand this in detail:
- The “JavaScript performance” report offers a list of all the errors.
- The “browser performance events” chart shows the time of lifecycle events when loading JS pages. It helps you identify the page elements that are the slowest to load.
- The “load time distribution” report shows the pages that are fast or slow. If you click on these data columns, you can further analyze the slow pages in detail.
2. Implement Dynamic Rendering
How your website renders code impacts how Google will index your JS content. Hence, you need to know how JavaScript rendering occurs.
Server-Side Rendering
In this, the rendered page (rendering of pages happens on the server) is sent to the crawler or the browser (client). Crawling and indexing are similar to HTML pages.
But implementing server-side rendering (SSR) is often challenging for developers and can increase server load.
Further, the Time to First Byte (TTFB) is slow because the server renders pages on the go.
One thing developers should remember when implementing SSR is to refrain from using functions operating directly in the DOM.
Client-Side Rendering
Here, the JavaScript is rendered by the client using the DOM. This causes several computing issues when search bots attempt to crawl, render, and index content.
A viable alternative to SSR and CSR is dynamic rendering that switches between client and server-side rendered content for specific user agents.
It allows developers to deliver the site’s content to users who access it using JS code generated in the browser.
However, it presents only a static version to the bots. Google officially supports implementing dynamic rendering.
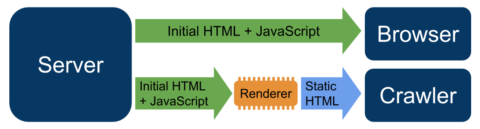
To deploy dynamic rendering, you can use tools like Prerender.io or Puppeteer.
These can help you serve a static HTML version of your Javascript website to the crawlers without any negative impact on CX.
Dynamic rendering is a great solution for ecommerce websites that usually hold lots of content that change frequently or rely on social media sharing (containing embeddable social media walls or widgets).
3. Route Your URLs Properly
JavaScript frameworks use a router to map clean URLs. Hence, it is critical to update page URLs when updating content.
For instance, JS frameworks like Angular and Vue generate URLs with a hash (#) like www.example.com/#/about-us
Such URLs are ignored by Google bots during the indexing process. So, it is not advisable to use #.
Instead, use static-looking URLs like http://www.example.com/about-us
4. Adhere To The Internal Linking Protocol
Internal links help Google efficiently crawl the site and highlight the important pages.
A poor linking structure can be harmful to SEO, especially for JS-heavy sites.
One common issue we’ve encountered is when ecommerce sites use JS for links that Google cannot crawl, such as onclick or button-type links.
Check this out:
<a href=”/important-link”onclick=”changePage(‘important-link’)”>Crawl this</a>
If you want Google bots to discover and follow your links, ensure they are plain HTML.
Google recommends interlinking pages using HTML anchor tags with href attributes and asks webmasters to avoid JS event handlers.
5. Use Pagination
Pagination is critical for JS-rich ecommerce websites with thousands of products that retailers often opt to spread across several pages for better UX.
Allowing users to scroll infinitely may be good for UX, but isn’t necessarily SEO-friendly. This is because bots don’t interact with such pages and cannot trigger events to load more content.
Eventually, Google will reach a limit (stop scrolling) and leave. So, most of your content gets ignored, resulting in a poor ranking.
Make sure you use <a href> links to allow Google to see the second page of pagination.
For instance, use this:
<a href=”https://example.com/shoes/”>
6. Lazy Load Images
Though Google supports lazy loading, it doesn’t scroll through content when visiting a page.
It resizes the page’s virtual viewport, making it longer during the crawling process. And because the “scroll” event listener isn’t triggered, this content isn’t rendered.
Thus, if you have images below the fold, like most ecommerce websites, it’s critical to lazy load them, allowing Google to see all your content.
7. Allow Bots To Crawl JS
This may seem obvious, but on several occasions, we’ve seen ecommerce sites accidentally blocking JavaScript (.js) files from being crawled.
This will cause JS SEO issues, as the bots will not be able to render and index that code.
Check your robots.txt file to see if the JS files are open and available for crawling.
8. Audit Your JS Code
Finally, ensure you audit your JavaScript code to optimize it for the search engines.
Use tools like Google Webmaster Tools, Chrome Dev Tools, and Ahrefs and an SEO crawler like JetOctopus to run a successful JS SEO audit.
Google Search Console
This platform can help you optimize your site and monitor your organic performance. Use GSC to monitor Googlebot and WRS activity.
For JS websites, GSC allows you to see problems in rendering. It reports crawl errors and issues notifications for missing JS elements that have been blocked for crawling.
Chrome Dev Tools
These web developer tools are built into Chrome for ease of use.
The platform lets you inspect rendered HTML (or DOM) and the network activity of your web pages.
From its Network tab, you can easily identify the JS and CSS resources loaded before the DOM.
Ahrefs
Ahrefs allows you to effectively manage backlink-building, content audits, keyword research, and more. It can render web pages at scale and allows you to check for JavaScript redirects.
You can also enable JS in Site Audit crawls to unlock more insights.
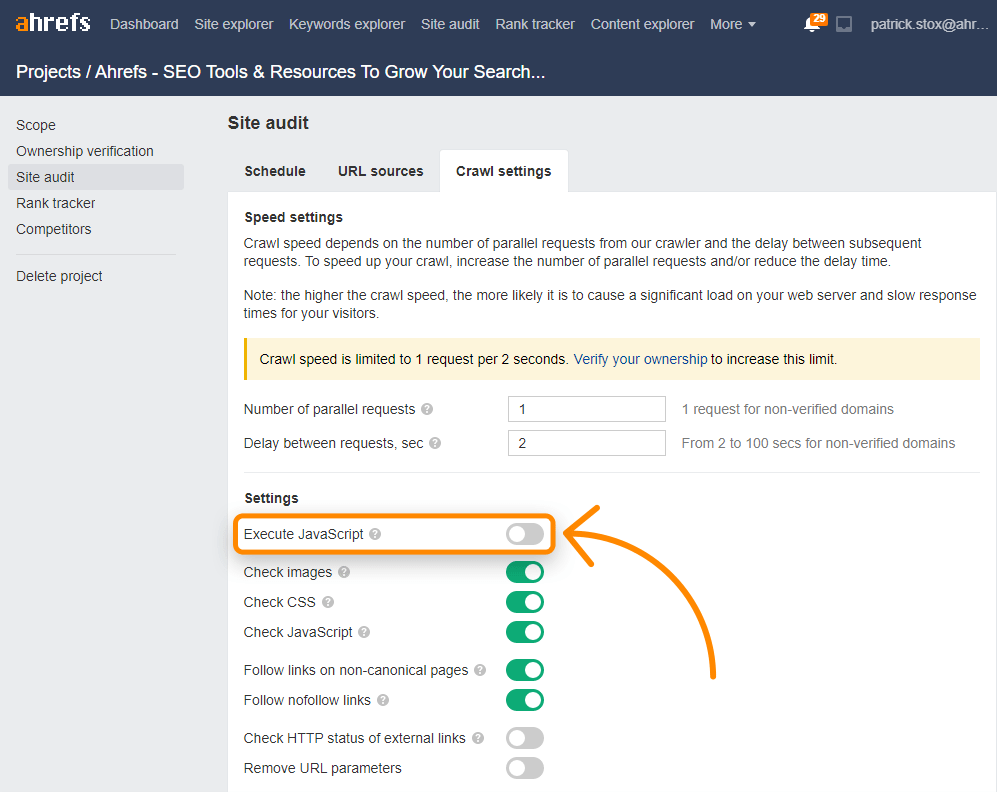
The Ahrefs Toolbar supports JavaScript and shows a comparison of HTML to rendered versions of tags.
JetOctopus SEO Crawler And Log Analyzer
JetOctopus is an SEO crawler and log analyzer that allows you to effortlessly audit common ecommerce SEO issues.
Since it can view and render JS as a Google bot, ecommerce marketers can solve JavaScript SEO issues at scale.
Its JS Performance tab offers comprehensive insights into JavaScript execution – First Paint, First Contentful Paint, and page load.
It also shares the time needed to complete all JavaScript requests with the JS errors that need immediate attention.
GSC integration with JetOctopus can help you see the complete dynamics of your site performance.
Ryte UX Tool
Ryte is another tool that’s capable of crawling and checking your javascript pages. It will render the pages and check for errors, helping you troubleshoot issues and check the usability of your dynamic pages.
seoClarity
seoClarity is an enterprise platform with many features. Like the other tools, it features dynamic rendering, letting you check how the javascript on your website performs.
Summing Up
Ecommerce sites are real-world examples of dynamic content injected using JS.
Hence, ecommerce developers rave about how JS lets them create highly interactive ecommerce pages.
On the other hand, many SEO pros dread JS because they’ve experienced declining organic traffic after their site started relying on client-side rendering.
Though both are right, the fact is that JS-reliant websites too can perform well in the SERP.
Follow the tips shared in this guide to get one step closer to leveraging JavaScript in the most effective way possible while upholding your site’s ranking in the SERP.
More resources:
- 10 Must-Know SEO Basics For Web Developers
- How To Automate Ecommerce Category Page Creation With Python
- Advanced Technical SEO: A Complete Guide
Featured Image: Visual Generation/Shutterstock
