

A quick SEO win for most sites is to include the top ranking keyword in the title tags that are missing them.
Think about it for a minute.
If a page is already ranking for a keyword and if that keyword is not present in its title, then that page could rank higher if we were to add that term in a natural way
If we also add keywords to meta descriptions, we could also have them highlighted in bold in the search results.
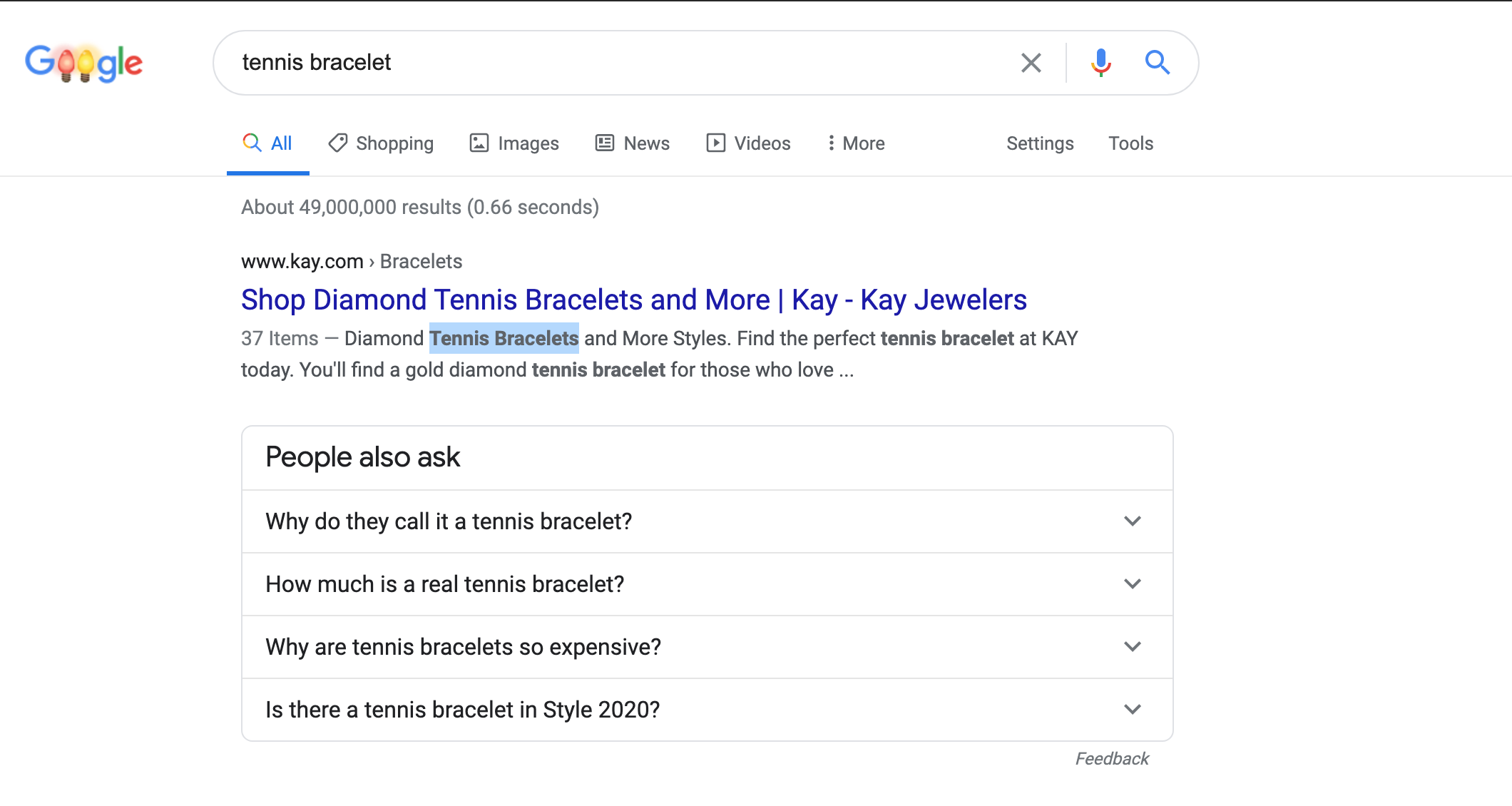
Now, if you work on a site with hundreds, thousands, or millions of pages, doing this manually can become time-consuming and prohibitively expensive pretty quickly!
Maybe this is something that we could teach a machine to do for us.
It could end up doing it even better and faster than a data entry team.
Let’s find out.
Reintroducing Uber’s Ludwig & Google’s T5
We are going to combine a couple of technologies I’ve covered in previous columns:
- Uber’s Ludwig
- Google’s T5 (Text to Text Transfer Transformer)
I first introduced Ludwig in my article Automated Intent Classification Using Deep Learning.
In summary, it is an open-source “Auto ML” tool that allows you to train cutting-edge models without writing any code.
I first introduced T5 in the article How to Produce Titles and Meta Descriptions Automatically.
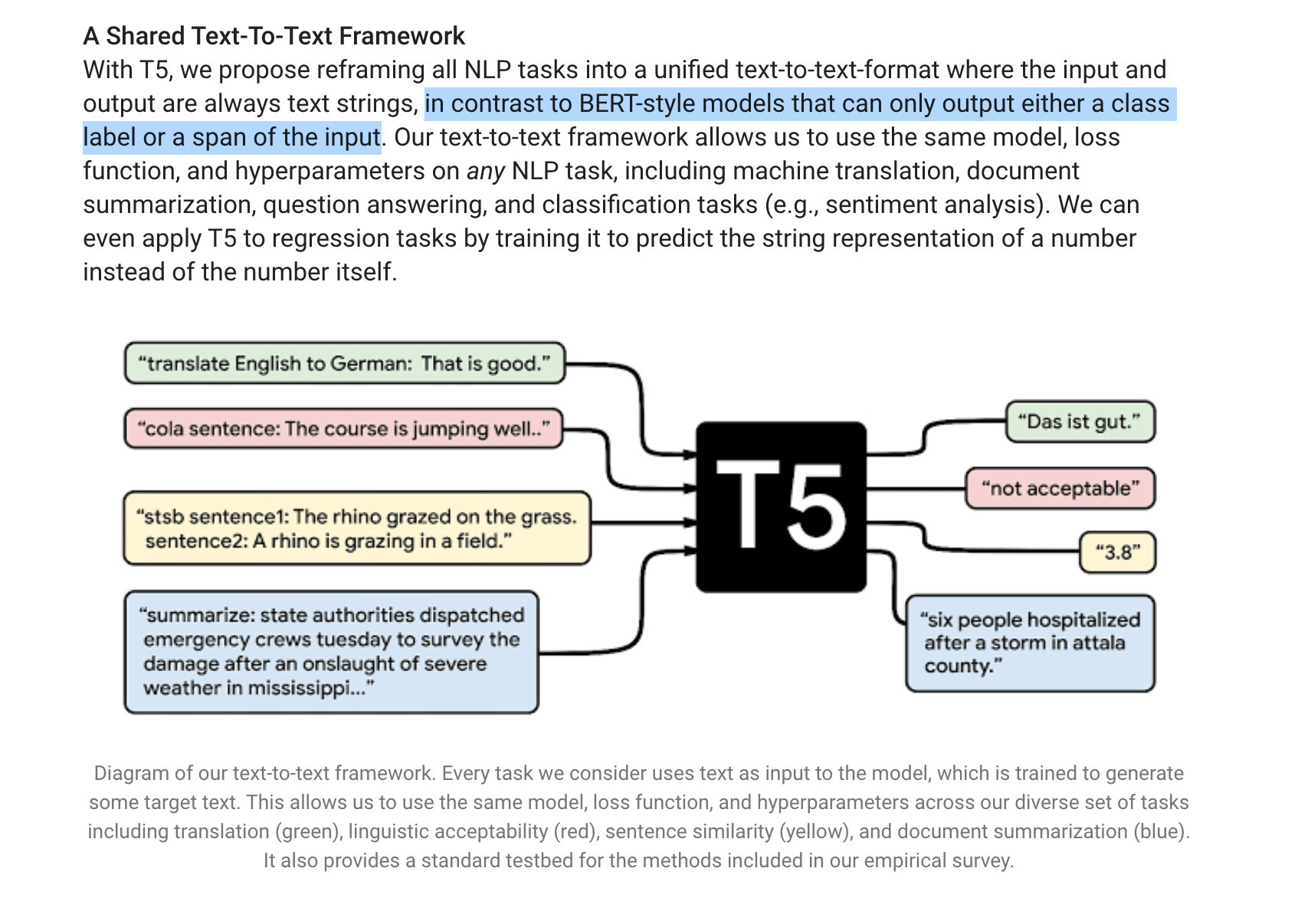
Google describes T5 as a superior version of BERT-style models.
If you remember my article about intent classification, BERT was perfect for the task because our target output/predictions are classes/labels (the intentions).
In contrast, T5 can summarize (like I showed in my article about meta tags generation), translate, answer questions, classify (like BERT), etc.
It is a very powerful model.
Now, T5 hasn’t been trained (as far as I know) for title tag optimization.
Maybe we can do that!
We would need:
- A training dataset with an example that includes:
- Original title tags without our target keywords
- Our target keywords
- Optimized title tags with our target keywords
- T5 fine-tuning code and a tutorial to follow
- A set of titles that are not optimized that we can use to test our model
We are going to start with a dataset I already put together from SEMrush data I pulled from HootSuite. I will share instructions on how to compile a dataset like this together.
The authors of T5 generously put together a detailed Google Colab notebook that you can use to fine-tune T5.
If you run through it, you can use it to answer arbitrary trivia questions. I actually did this during my SEJ eSummit presentation back in July.
They also include a section that explains how to fine-tune it for new tasks. But when you look at the code changes and data preparation required, it looks like a lot of work to find out if our idea would actually work.
Maybe there is a simpler way!
Fortunately, Uber released Ludwig version 0.3 just a couple of months ago.
Version 0.3 of Ludwig ships with:
- A hyperparameter optimization mechanism that squeezes additional performance from models.
- Code-free integration with Hugging Face’s Transformers repository, giving users access to state-of-the-art pre-trained models like GPT-2, T5, Electra, and DistilBERT for natural language processing tasks including text classification, sentiment analysis, named entity recognition, question answering, and much more.
- A new, faster, modular and extensible backend based on TensorFlow 2.
- Support for many new data formats, including TSV, Apache Parquet, JSON and JSONL.
- Out-of-the-box k-fold cross validation capability.
- An integration with Weights and Biases for monitoring and managing multiple model training processes.
- A new vector data type that supports noisy labels for weak supervision.
The release is packed with new features, but my favorite one is the integration to the Hugging Face’s Transformers library.
I introduced Hugging Face pipelines in my article about titles and meta descriptions generation.
Pipelines are great to run predictions on models already trained and available in the model hub. But, at the moment, there are no models that do what we need, so Ludwig comes really handy here.
Fine-Tuning T5 With Ludwig
Training T5 with Ludwig is so simple, it should be illegal!
Hiring an AI engineer to do the equivalent would cost us serious $$$.
Here are the technical steps.
Open a new Google Colab notebook and change the Runtime to use GPU.
Download the HootSuite dataset that I put together by typing the following.
!wget URL https://gist.githubusercontent.com/hamletbatista/5f6718a653acf8092144c37007f0d063/raw/84d17c0460b8914f4b76a8699ba0743b3af279d5/hootsuite_titles.csv
Next, let’s install Ludwig.
!pip install ludwig
!pip install ludwig[text]
Let’s load the training dataset I downloaded into a pandas data frame to inspect it and see what it looks like.
import pandas as pd
df = pd.read_csv("data.csv")
df.head()

The bulk of the work comes down to creating a proper configuration file.
I figured out one that works by starting with the documentation for T5 and a bit of trial and error.
You can find the Python code to produce it here.
Let’s review the key changes.
input_features: - name: Original_Title type: text level: word encoder: t5 reduce_output: null - name: Keyword type: text level: word tied_weights: Original_Title encoder: t5 reduce_output: null output_features: - name: Optimized_Title type: sequence level: word decoder: generator
I define the input to the model as the Original Title (without the target keyword) and the target Keyword.
For the output/prediction, I define the optimized title and the decoder as a generator. A generator tells the model to produce a sequence. We need this to generate our beautiful titles.
Now we get to the typically hard part but made super-easy with Ludwig: training T5 on our dataset.
!ludwig train --dataset hootsuite_titles.csv --config config.yaml
You should get a printout like the one below.
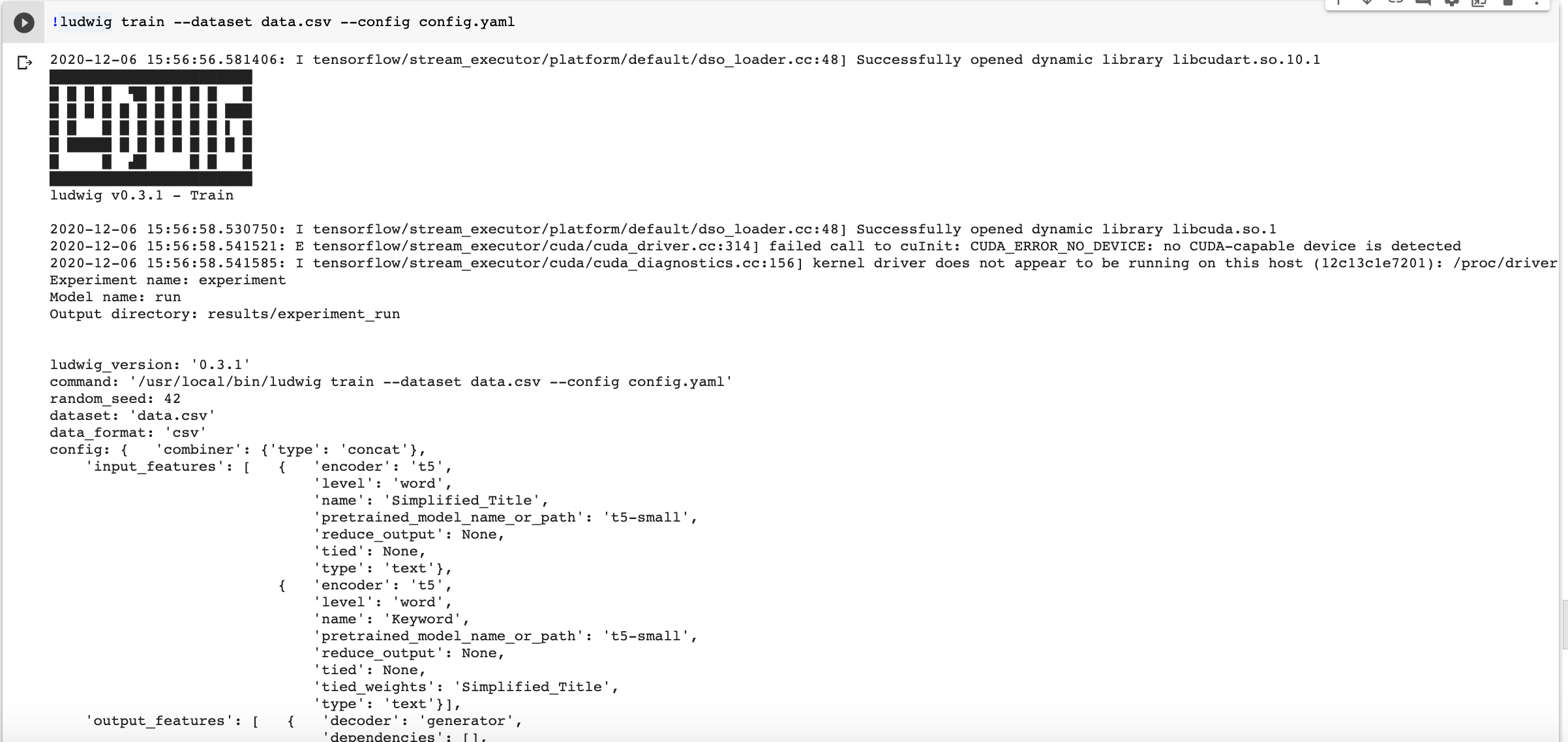
Make sure to review the input and output features dictionaries to make sure your settings are picked up correctly.
For example, you should see Ludwig using ‘t5-small’ as the model. It is easy to change it for larger T5 models in the model hub and potentially improve the generation.
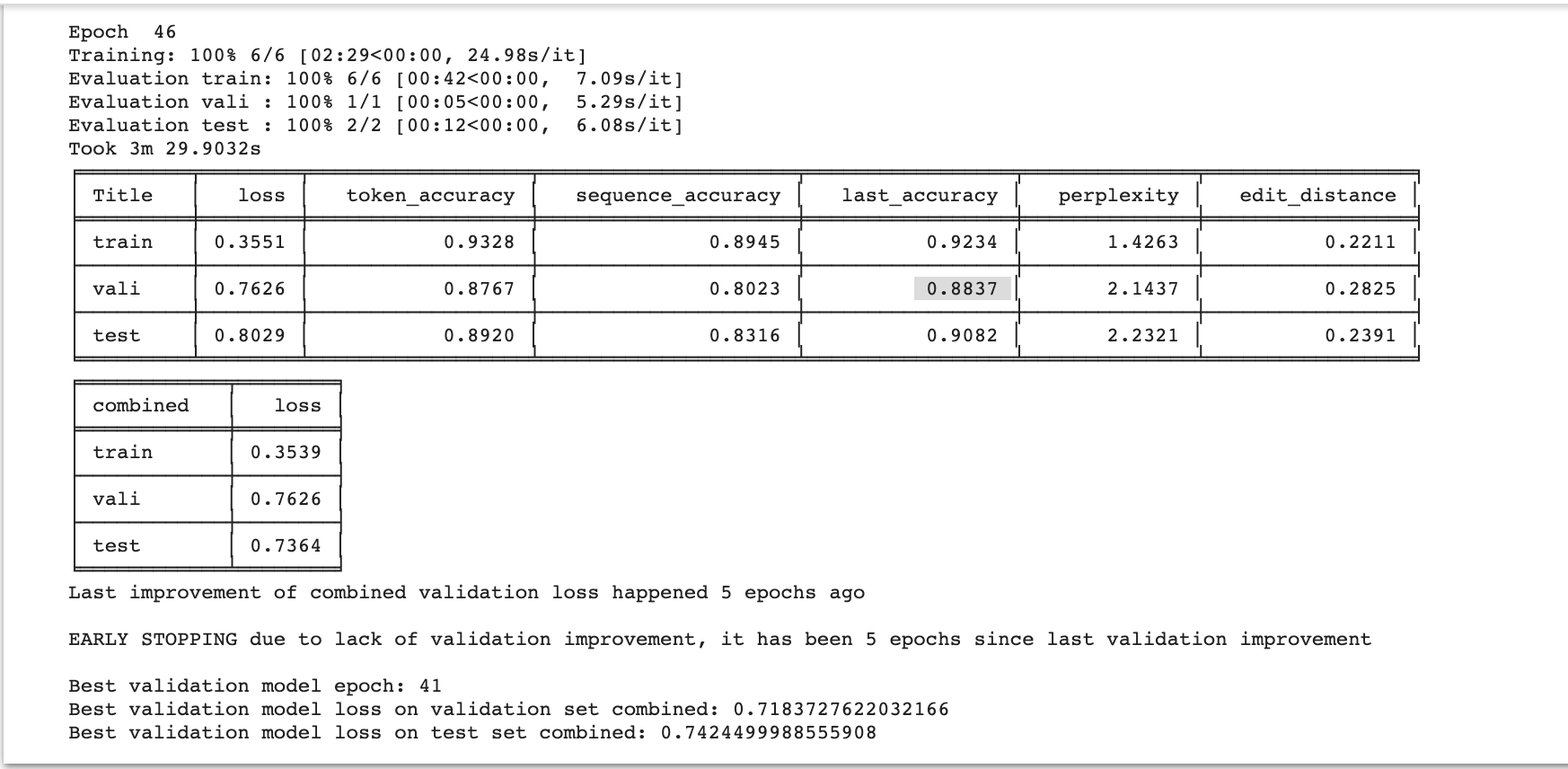
I trained the model for about 1 hour and got a very impressive validation accuracy of 0.88.
Please also note that Ludwig auto-selected other important text generation measurements: perplexity and edit distance.
They are both low numbers, which are good in our case.
Optimizing Titles With Our Trained Model
Now to the exciting part. Let’s put our model to the test!
First, download a test dataset with unoptimized HootSuite titles unseen by the model during training.
!wget URL https://gist.githubusercontent.com/hamletbatista/1c4cfc0f24f6ac9774dd18a1f6e5b020/raw/7756f21ba5fbf02c2fe9043ffda06e525a06ea34/hootsuite_titles_to_optimize.csv
You can review the dataset with this command.
!head hootsuite_titles_to_optimize.csv

We can generate predictions with the next command.
!ludwig predict --dataset hootsuite_titles_to_optimize.csv --model_path results/experiment_run/model/
It will run for less than a minute and save the predictions to a CSV under the results directory.
You can review the optimized titles with this command:
!cat /content/results/Title_predictions.csv | sed 's/,/ /g'
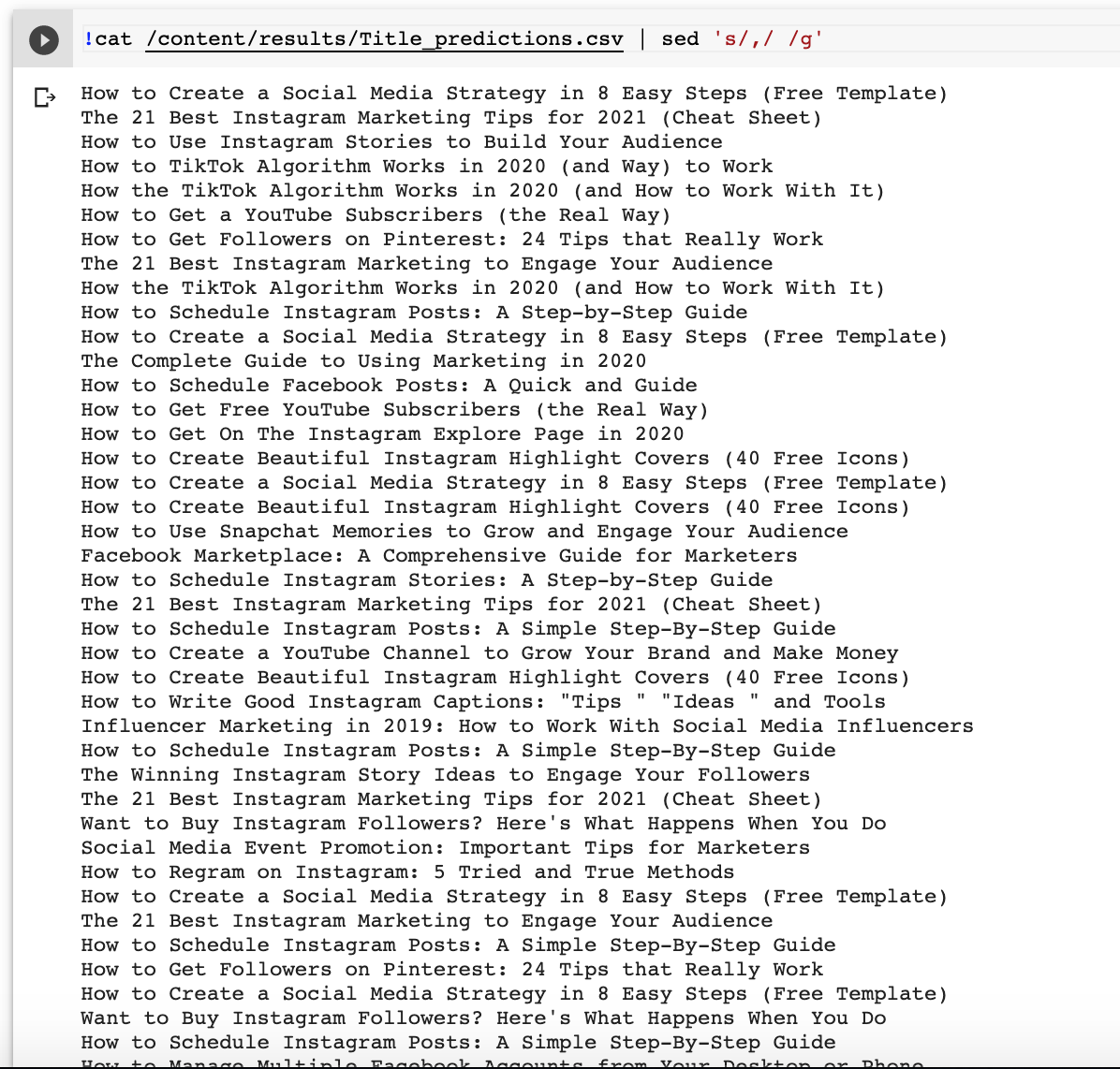
Look at how beautiful and dramatically coherent the titles are!
Very impressive what Ludwig and T5 can do with a small training set and no advanced hyperparameter tuning.
But our proper test comes down to whether it is blending our target keywords correctly.
Let’s review a few examples from the test dataset:
Row: 798
Original Title: 20 Creative Instagram News Ideas to Engage Your Followers,
Target Keyword: what to post on instagram story
T5 Optimized Title: 20 Creative Instagram Story Ideas to Engage Your Followers
Now tell me there isn’t some serious sorcery going on here! 🤓
Here’s another one.
Row: 779
Original Title: How to Create a Social Media Idea in 8 Easy Steps (Free Template)
Target Keyword: social strategy
T5 Optimized Title: How to Create a Social Media Strategy in 8 Easy Steps (Free Template)
BOOM!
And here’s another one:
Row: 773
Original Title: 20+ Creative Social Media Show Ideas and Examples,
Target Keyword: contest ideas
T5 Optimized Title: 20+ Creative Social Media Contest Ideas and Examples
You can find the full list I predicted here.
Building a Title Tag Optimization App With Streamlit
The primary users of a service like this are likely to be content writers.
Wouldn’t it be cool to package this into a simple to use app that takes very little effort to put together?
That is possible with Streamlit!
I briefly used it in my article How to Generate Structured Data Automatically Using Computer Vision.
Install it using:
!pip install streamlit
I created an app that leverages this model and you can find the code here. Download it and save it as title_optimizer.py.
You need to run it from the same place you trained the model, or download the trained model to where you plan to run the script.
You should also have a CSV file with the titles and keywords to optimize.
You can launch the app using:
streamlit run title_optimizer.py
Open your browser using the URL provided. Typically, http://localhost:8502
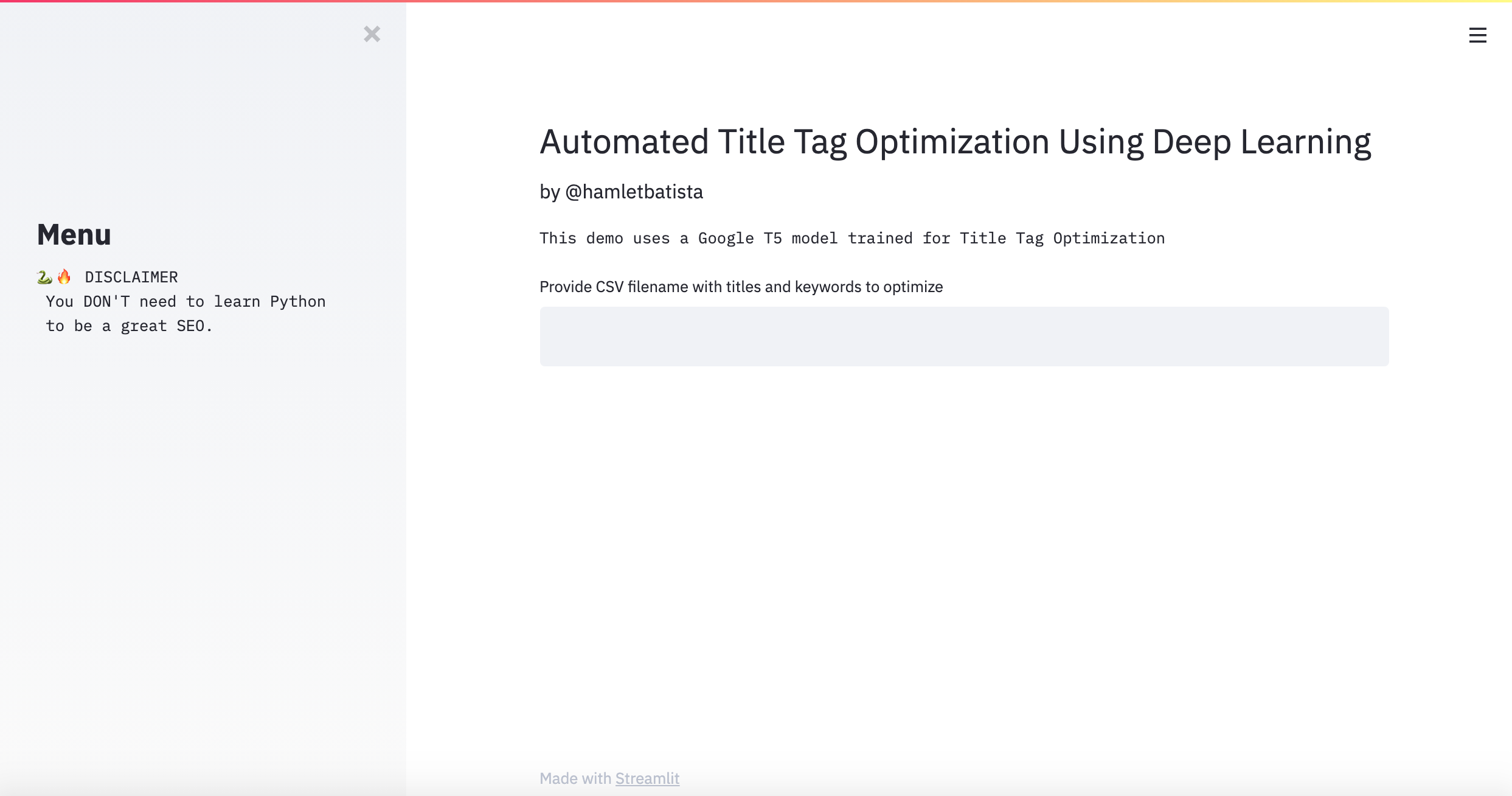
You should see a webpage like the one above.
In order to run the model, you just need to provide the path to the CSV file with the titles and keywords to optimize.
The CSV column names should match the names you used while training Ludwig. In my case, I used: Simplified_Title and Keyword. I named the optimized title Title.
The model doesn’t optimize all the titles correctly, but it does get right a decent number.
If you are still crawling your way to learning Python, I hope this gets you excited enough to start running! 🐍🔥
How to Produce Custom Datasets to Train
I trained this model using HootSuite titles and it probably won’t work well for sites in other industries. It might barely work for competitors.
It is a good idea to produce your own dataset, so here are some tips to do that.
- Leverage your own data from Google Search Console or Bing Webmaster Tools.
- Alternatively, you can pull competitor data from SEMrush, Moz, Ahrefs, etc.
- Write a script to fetch title tags and split titles with and without your target keywords.
- Take the titles with keywords and replace the keywords with synonyms or use similar techniques to “deoptimize” the titles.
These steps will give you a training dataset with ground truth data that the model can use to learn from.
For your testing dataset, you can use the titles that don’t have the keywords (from step 3). Then inspect the quality of the predictions manually.
Writing the code for these steps should be fun and interesting homework.
Resources to Learn More
The adoption of Python in the community continues strong.
The best way to learn is by doing interesting and relevant work.
My team at RankSense started writing and sharing practical scripts in the form of Twitter tutorials back in July.
We call them RSTwittorials.
A couple of months ago, I asked the community to join us and share their own scripts, then get on video walkthroughs with me each week.
💥 So excited to see so many #Python #SEOs sharing their brilliant scripts and journeys in the coming weeks.
We are booked with weekly #RStwittorial sessions to March (3 slots left)! 🐍🔥#DONTWAIT fill out this form and nail down a date 🤓https://t.co/Wf2Pt6f8KV pic.twitter.com/IOsEfUMWKR
— Hamlet Batista (@hamletbatista) November 18, 2020
At first, I thought I’d do one of these, once a month and planned for my team to do the rest each week.
We are booked with amazing Twittorials and walkthroughs each week up to May (at the time of this writing)!
💥 If you are trying to learn or master #Python, share your experience with us and speedup your learning!
We have 2 slots open for #RSTwittorials and webinars for March & April 2021. Opening dates for May soon! #DONTWAIT 🐍🔥 https://t.co/rfnoZ25KPq pic.twitter.com/9gIiI4u8WX
— Hamlet Batista (@hamletbatista) December 1, 2020
So many cool tricks and learning journeys already. #DONTWAIT
More Resources:
- How to Generate Quality FAQs & FAQPage Schemas Automatically with Python
- Doing More with Less: Automated, High-Quality Content Generation
- 7 Example Projects to Get Started With Python for SEO
Image Credits
All screenshots taken by author, December 2020
