
My introduction to search engines came about in 1994. I’d been using the “world wide web” in email, ftp, and newsgroup form for several years by then. I was hired by a company to the write the user documentation for their search engine module.
It was offline code and used for a number of high-profile projects around the world. And there were three levels of documentation.
After nearly two years of docs – I’d been taking a break from programming – I managed to get on the then new online search engine that the company created and became the first official webmaster in 1996. The online version doesn’t exist anymore, but the company is now huge and happily selling content management systems.
While I never saw any of the inner engine code, I gained an understanding of full-text indexing and retrieval methods, as well as spider behavior, etc., and have been hooked on search ever since, despite all the inherent limitations. Fast forward eleven years. Search interfaces haven’t changed all that much, excluding “Web 2.0” engines, which I hope to talk about in the near future. Search as it exists today still sucks. Here are a few reasons why:
- Millions of non-relevant results. I.e., non-semantic.
- False results on pages that have transient content. I.e., nah nah, can’t see me.
- Can’t find stuff on the Invisible Web – though that’s changing.
- Can’t always find the latest content as opposed to the most relevant.
- Limited search paradigms.
On the other hand, Google and the other big SEs are at least making an effort to provide more access to parts of the Invisible Web. In recent years, they’ve added search capability for images, audio, and video content, as well as some text content from dynamically generated sites.
Lets not forget the all the shiny new Web 2.0 search engines – some of which are implementing new search paradigms. They’re buggy, but they’re exciting. And the semantic web (aka Web 3.0 to some) may not be here quite yet, but tools like Yahoo Pipes sure take us a ways towards extracting meaning from content – in this case web feeds.
That said, I love search. I use it daily in my resesearch, which drives me to learn more efficient ways of finding what I need quickly. SEs and feed readers are my primary source of insipiration on a daily basis. Without them, I cannot see my freelancing being all that successful.
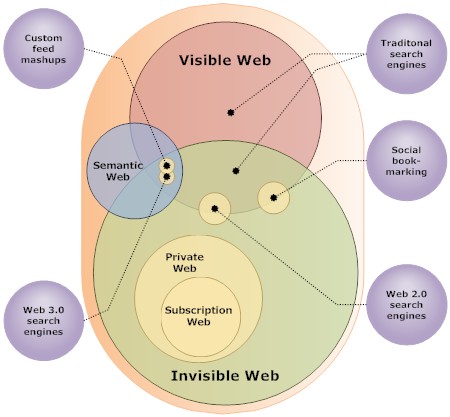
The very simplified diagram above shows the intersection of different “webs”, as well as where content is indexed. (The purple bubbles represent indexes.)
- Traditional engines give us both the Visible Web (hence it’s name) and a sliver of the Invisible Web. (As implied by the size of circles, the Invisible Web is much larger than the Visible Web.) There are manually generated indexes into the Invisible Web, but a lot of them become obsolete quickly.
- Social bookmarking sites and Web 2.0 engines give us only an intersection each of the Visible and Invisible Web, though it’s unlikely they overlap. Social bookmarking sites help expose the Invisible and this information is more persistent than older lists of “invisible” content URLs.
- Custom mashup tools like Yahoo Pipes, OpenKapow, and Teqlo give us a view of Visible, Invisible and Semantic Web. At the least, they allow us to extract a bit of meaning and thus create if not expose Semantic content. Web 3.0 / Semantic search engines are apparently in experimental stages
As far as I’m concerned, there is a lot about search to be excited about.
