

I recently wrote about how to statistically model any given set of search results, which I hope gives marketing professionals a glimpse into how rapidly the SEO industry is currently changing in 2015. In that article, I had mentioned that the search engine model should be able to “self-calibrate”, or take its algorithms and weightings of those algorithms, and correlate the modeled data against real-world data from public search engines, to find a precise search engine modeling of any environment.
But taking thousands of parameters and trying to find the best combination of those that can curve fit search engine results is what we in computer science call a NP-Hard problem. It’s astronomically expensive in terms of computational processing. It’s really hard.
So how can we accomplish this task of self-calibrating a search engine model? Well, it turns out that we will turn to the birds — yes, birds — to solve this incredibly hard problem.
Full Disclosure: I am the CTO of MarketBrew, a company that uses artificial intelligence to develop and host a SaaS-based commercial search engine model.
Particle Swarm Optimization
I have always been a fan of huge problems. This one is no different, and it just so happens that huge problems comes with awesome solutions. I turn your attention to one such solution: Particle swarm optimization (PSO), which is an artificial intelligence (AI) technique that was first published in 1995 as a model of social behavior. The technique is actually modeled on the concept of bird flocking.
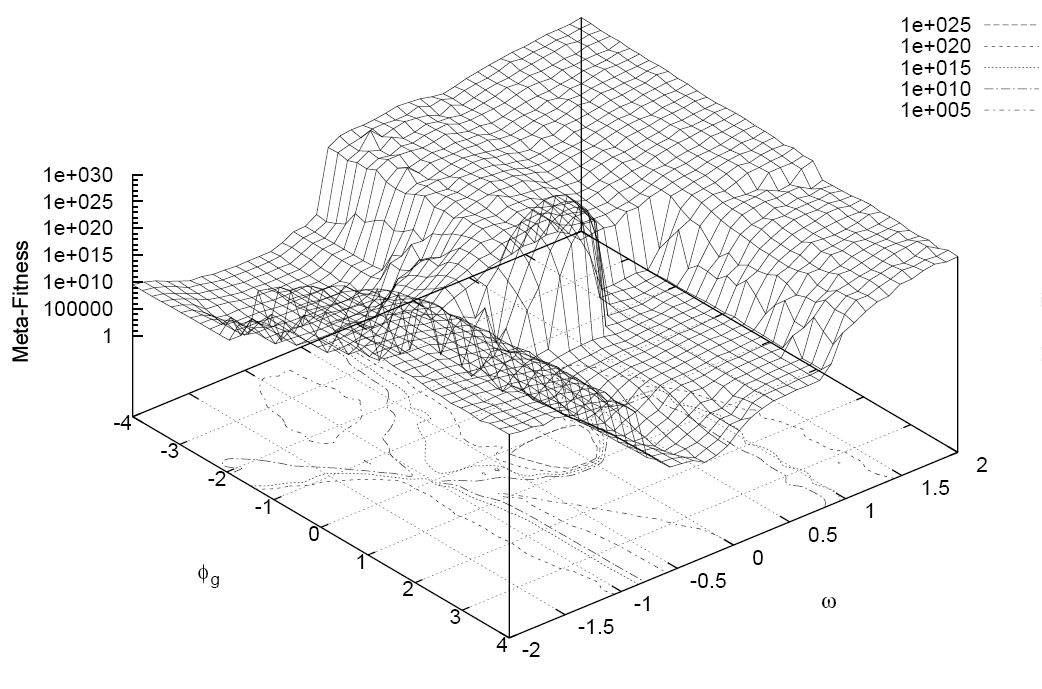
The optimization is really quite remarkable. In fact, all of our rules-based algorithms that we have invented to-date still cannot be used to find approximate solutions to extremely difficult or impossible numeric maximization and minimization problems. Yet, using a simple model of how birds flock can get you an answer within a fraction of time. We have heard the gloom and doom news about how AI might take over the world some day, but in this case, AI helps us solve a most amazing problem.
I actually have been involved with a number of Swarm Intelligence projects throughout my career. In February 1998, I worked as a communications engineer on the Millibot Project, formerly known as the Cyberscout Project, a project utilized by the United States Marines. The Cyperscout was basically a legion of tiny little robots that could be dispersed into a building and provide instant coverage throughout that building. The ability of the robots to communicate and relay information between one another, allowed the “swarm” of robots to act as one, effectively turning a very tedious task of searching an entire building into a leisurely stroll down one hallway (most of these tiny robots each had to travel a only few yards total).
Why Does It Work?
The really cool thing about PSO is that it doesn’t make any assumption about the problem you are solving. It is a cross between a rules-based algorithm that attempts to converge on a solution, and an AI-like neural network that attempts to explore the problem space. So, the algorithm is a tradeoff of exploratory behavior vs. exploitative behavior.
Without the exploratory nature of this optimization approach, the algorithm would certainly converge on what statisticians like to call a “local maxima” (a solution that appears to be optimal, but is not optimal).
First, you start with a number of “flocks” or guesses. In a search engine model, this may be the different weightings of scoring algorithms. For instance, with 7 different inputs, you would start with at least 7 guesses at these weightings. A specific guess would simply be an array of 7 different weightings.

The idea behind PSO is that each of these guesses should be spaced apart so that none of them are close to each other. Without getting into 7-dimensional calculations, you can use a number of techniques to ensure your starting points are optimal.
Then, you begin to “evolve” the guesses. The evolutionary process tries to mimic what a flock of birds would do when presented with a cache of food nearby. One of the random guesses (flocks) will be closer than the others, and other guesses will adjust their next guess based on this global information.
I’ve included a great visualization on what this process looks like (below).
[youtube https://www.youtube.com/watch?v=8Vp57FDIHiI&w=560&h=315]
A Visualization of How Particle Swarm Optimization Works
Implementation
Fortunately, there are a number of implementations out there in various coding languages. The great thing about PSO is that it is very easy to implement! There are very few tuning parameters (a good sign of a strong algorithm), and very few drawbacks.
Depending on your problem, your implementation may get trapped into a local minimum (non-optimal solution). You can easily fix this by introducing a neighborhood topology, which effectively limits the feedback loop to the best of the nearby guesses instead of the best global guess so far.
The bulk of your work will be designing the “fitness function”, or the scoring algorithm that you will use to determine how close you are to your target correlation. In our case, with SEO, we want to correlate against a known entity, like Google’s US results. You could just as easily swap this out with any version of any search engine.

Once you have your scoring system in place, your PSO algorithm will attempt to maximize that score across potentially trillions of combinations. The scoring system can be as simple as doing a pearson correlation between your search engine model and the public search results, or it can get as complex as taking those correlations and additionally assigning points to specific scenarios (e.g. 10 points for matching #1, 5 points for matching #2, etc…).
The Problem With Correlating Against A Black Box
Recently, there have been many SEOs out there trying to correlate against Google’s “black box”. I applaud this effort, but it is severely misguided. Allow me to explain.
First, correlation does not always mean causation. Especially if the inputs to your black box are not close to the outputs. Let’s show some examples. First, an example where inputs are very close to their respective outputs: an ice cream truck business. When there are warmer temperatures, people buy more ice cream. It is easy to see that one input (the temperature) is closely tied to the output (ice cream).
Unfortunately, most SEOs do not enjoy any statistical closeness between their optimzations (inputs) and their respective search engine results (outputs).
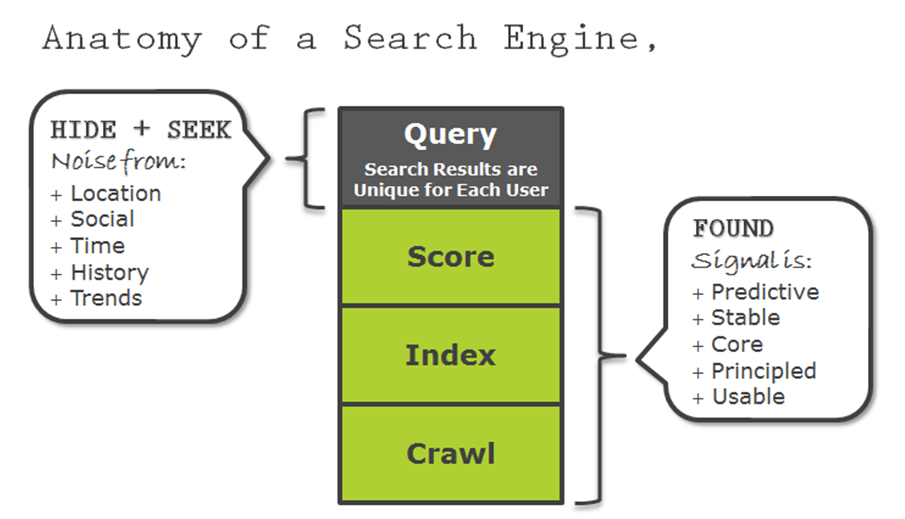
Their inputs, or optimizations, are before even the crawling components of the search engine. In fact, typical optimizations have to go through four layers: crawling, indexing, scoring, and finally the real-time query layer. Trying to correlate this way is fools gold.
In fact, Google actually introduces a significant noise factor, similar to how the U.S. government introduced noise to its GPS constellation, so civilians would not be able to get military-grade accuracy. It’s called the real-time query layer. The query layer is currently acting as a major deterrent for SEO correlation tactics.
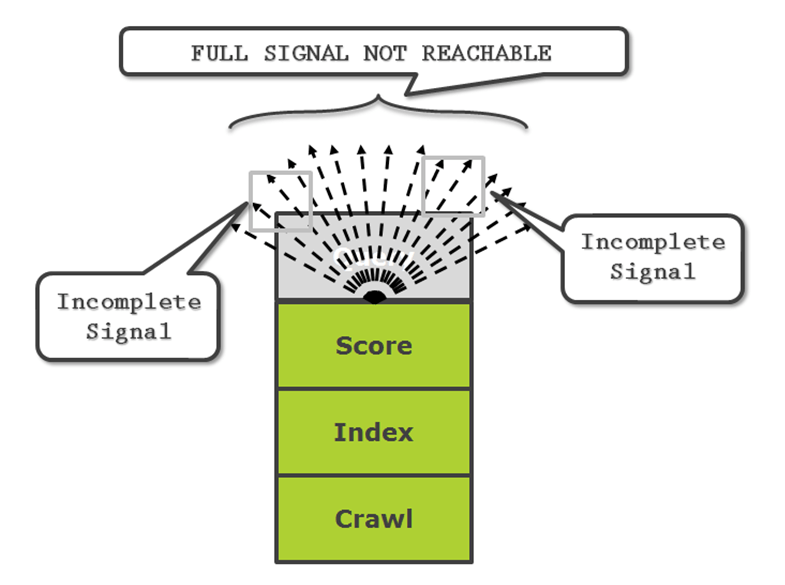
An analogy I always use is that of a garden hose. At the scoring layer of a search engine, you have the brand’s view of what is going on. The water coming out of the hose is organized and predictable — that is, you can change things and accurately predict the resulting change in water flow (search results).
In our analogy, the query layer spreads this water (search results) into millions of droplets (variations of search results), depending on the user. Most of the algorithm changes today are occurring on the query layer, in order to produce more variations of search results for the same number of users. Google’s Hummingbird algorithm is an example of one of these. Shifts in the query layer allow search engines to generate more marketplaces for their pay-per-click ads.
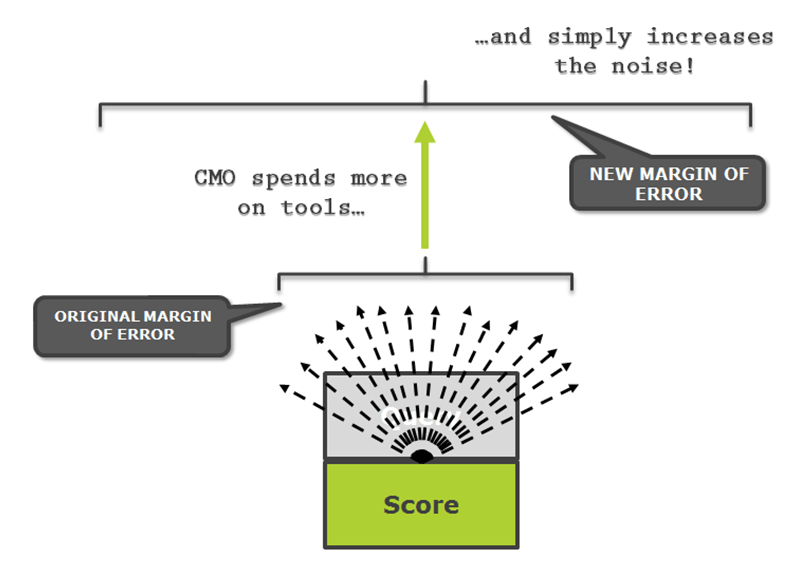
The query layer is the user’s view of what is going on, not the brand’s. Therefore, correlations found this way will very rarely mean causation. And this is assuming that you are using one tool to source and model your data. Typically, SEOs will use a number of data inputs for their modeling, which only increases this noise and decreases the chances of finding causation.
How To Find Causation In SEO
The trick to getting correlation to work for a search engine model is to tighten the inputs and outputs significantly. The inputs, or the variables, must be located at or above the scoring layer in the search engine model. How do we do this? We have to break down the search engine black box into its primary components. We have to build the search engine model from the ground up.
The outputs are even harder to optimize: we already discussed why the public search engines have a tremendous amount of noise due to the real-time query layer creating millions of variations due to the user. At a minimum, we will need to make our search engine model output results that are BEFORE the typical query layer variations. This will ensure that at least one side of the comparison is stable.
If we build the search engine model from the ground up, we would then be able to display the search results coming directly out of the scoring layer instead of the query layer, which gives us a more stable and precise relationship between these inputs and outputs that we are trying to correlate. Now, with these tight and significant relationships between inputs and outputs, correlation means causation. When we boost the importance of one input, it gives us a direct connection to the results we see. We can then do the typical SEO analysis to determine what optimizations would be beneficial in the depicted search engine model.
Summary
As a fan of artificial intelligence, I am always very excited when something so simple in nature can lead to scientific discoveries or technological breakthroughs. Having a search engine model that allows us to transparently connect scoring inputs with non-personalized search results gives us the ability to connect correlation with causation.
Add in the Particle Swarm Optimization and you have a technical breakthrough: the self-calibrating search engine model.
Image Credits
Featured Image: Willyam Bradberry via Shutterstock
Image #1: Particle Swarm Optimization Chart from Wikipedia Commons.
All other screenshots and diagrams taken from MarketBrew’s Predictive SEO system in 2015.
